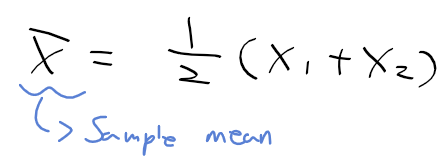데이터 분석을 하려면 가장 먼저 할 일은?
-> 데이터 수집, 로딩
데이터 출력
- header =T 옵션 없으면 age, gender, group을 열이 아닌 1행으로 인식

변수 할당시 보기
- ctrl + 변수 명 클릭

head 함수
- 상위 6개 행 출력
- 데이터 상당히 많으므로 일부 볼떄 자주 사용

names 함수
- 열이름 확인하기

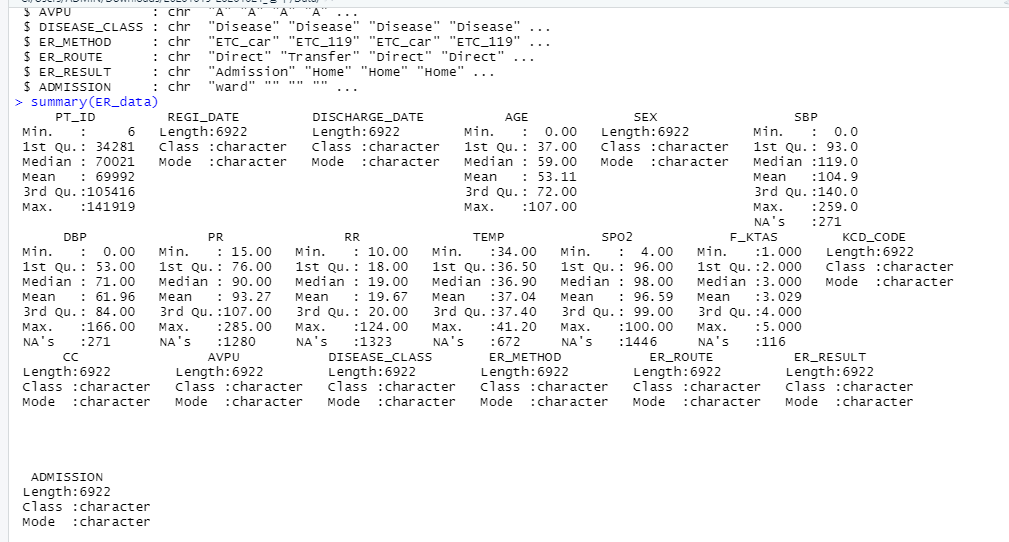
summary 함수
- 데이터 정리해서 출력

str 함수 (structure)
- 해당 데이터의 구조 출력
- 10개의 옵셔베이션, 3개의 바리어블

is.na 함수
- 결측치인지 반환
- is.na에 sum : true 가 1, false 는 0이며 true 가 없으므로 0이
colSums 함수
- 열 별로 sum 연산
- 아래의 예시는 각 열별 결측치 sum

read.csv()
- "tab" 쓰면 해당 wd의 파일 자동완성
- 다음 예시는 6922 옵셔베이션에 20개 변수 가짐


csv 데이터 훑어보기
- str() : 구조 파악
- summary() : 기초 통계 빈도에 대한 내용 반환
- names : 변수명 확인
- is.na() : 결측값 확인


데이터 형태
- 데이터 프레임 : 엑셀과 같은 데이터
- 스칼라 : 1 x 1 형 데이터
- 벡터 : 1 x N 형 데이터
- matrix : M x N 형 데이터
* c() : concatenate의 약어로 스칼라 값들을 연결하여 벡터로 만듬
=> ex. c(1,2,3,4,10)
R 패키지
- CRAN The Comprehensive R Archive Network
- git
moonBook 설치 및 사용
- 성별을 기준으로 AGE, TEMP, AVPU 데이터 분석


유용한 R 패키지들
support.rstudio.com/hc/en-us/articles/201057987-Quick-list-of-useful-R-packages
- 배워야할 필수 패키지 4개
- Dplyr
- ggplot2
- ggvis
- caret
latex
- 논문쓸떄 많이 사용하며, html형태로 결과를 만들어줌

데이터 프레임 일부분 추출
- 데이터프레임명[행, 열]
데이터프레임 특정 변수 접근
- 데이터프레임명$변수
- age에서 1~4 추출
- age가 30보다 큰 추출 -> true false 반환
- age가 30보다 큰 age들 추출
- age가 30보다 큰 행 전체 출력

문제
# 나이가 30세보다 크고
# 성별이 M인 사람을 뽑자

'수학 > 통계' 카테고리의 다른 글
| 데이터분석 - 6. R 시각화 (0) | 2020.10.20 |
|---|---|
| 데이터분석 - 5. 확률기초 (0) | 2020.10.19 |
| 데이터분석 - 4. R그래프들 (0) | 2020.10.19 |
| 데이터분석 - 3. R기초 2 (0) | 2020.10.19 |
| 데이터분석 - 1.개요 (0) | 2020.10.19 |