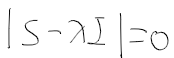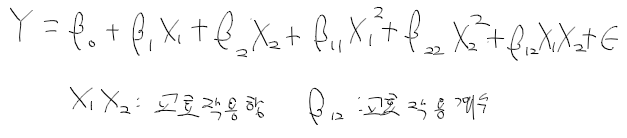- 회귀 분석 모형에서 설명 변수 p가 50인 경우. -> 설명변수, 독립변수가 너무많으면 해석하기 힘듬
- 해결방법
1. 변수 선택 방법 등 의미있는 변수들 선택하여 회귀모형을 적합
2. 선형 결합으로 몇개의 새로운 의미있는 변수들을 만들어 회귀분석 실시
-> 세 주성분 Z1, Z2, Z3을 이용한 회귀식
=> 반응 변수, 종속변수 Y를 설명하는데 별 차이가 없다고 할 수 있음.
-> 차이가 없으면 보다 간편하니 좋은 모형임.
-> p개의 설명변수 X와 동등한 효과를 같는 적은 수의 새로운 설명변수 Z를 어떻게 만들까
주성분 분석의 목적
- 여러개의 구조적 해석이 힘들며, 서로 상관관계를같는 변수들을 적절히 선형변환 시킴
=> 적은 수의 의미있는, 독립적인 주성분 유도하여 해석하기 위함.
- 다변량 변수들의 단순화, 내적 구조 분석
- 원래 변수들을 선형 결합 형식으로 주성분(서로 상관되지않은, 독립적인) 인공 변수 유도
- 각 주성분이 가지는 변이(정보)의 크기(주성분 분산)을 기준으로 중요도 순서고려
=> 먼저 구한 주성분들이 총 변이(총정보)의 상당부분을 보유하도록 하여 차원 축약
주성분 분석의 역사
- p차원 공간에 흐트러져있는 점들을 직교최소제곱 orthogonal least square 개념에 잘 적합시키는 평면을 찾기위한 기하학 최적화 문제로서 피어슨이 제기
- 호텔링은 변수간 상관구조 분석을 위해 p개의 원래 변수들의 변이를 결정하는데 더 낮은 차원의 독립적 요인을 구하여 성분이라고 함.
* 원래 변수들이 가진 총변이에 대한 각 성분 공헌도를 순차적으로 최대화 하도록 선택된 성분들을 유도하여 이용한 분석이 '주성분 분석'임.
주성분 분석의 활용
- 인자분석, 회귀 분석과 같이 일/다변량 통계적 분석 기법들과 관련을 가짐
- 차원 축약의 결과로 얻은 각 관찰개체별 주성분 점수 principal component score들은 다음 단계 통계 분석(ex. 군집분석, 회귀분석 등)에서 입력자료로 사용됨.
=> 주성분 분석은 분석 과정에서 중간 단계로 사용.
주성분 분석 모형
분산의 공분산 행렬과 상관계수 행렬
- 변수 X1, X2 평균
- 변수 X1, X2의 분산과 공분산
- 상관계수
- 공분산 행렬, 상관계수 행렬
주성분 구하기
- 자료 X를 이용한 주성분 분석은 변수의 분산 공분산 행렬 S나 상관계수 행렬 R로 실시
* 정보의 크기 = 분산의 크기
- 분산 공분산행렬 S로 주성분 구하기
1. 고유값(고유근)구하기 : 위 자료의 공분산 행렬 S는 7x7행렬로 7개의 고유값과 고유벡터 쌍을 가짐
- 고유 백터의 크기가 다음과 같을때
- 고유값은 아래의 행렬식을 만족하며, 고유벡터는 고유값에 대응
=> 주성분 분석에서 구하고자 하는 새 변수들은 7개의 고유 벡터들로 구함
2. 고유벡터 선형변환 : 고유 벡터들을 다음과 같이 직교화 orthogonalization
- 각 고유벡터의 내적이 1이고, 두벡터의 곱이 0이 되도록 고유벡터들을 선형 변환
=> 각 고유값에 대응하는 고유벡터들을 직교화시 새로운 변수, 주성분 PC1, ..., PC7를 다음과 같이 정의
=> 7개의 변수로 7개의 주성분을 만들었으나, 앞의 일부 주성분 만으로 분석을 해나갈 수 있다.
주성분 가중계수 벡터
- 위 고유벡터 a1, ..., a7를 주성분 가중계수벡터라 부름.
=> 주성분 의미를 해석하는데 사용됨.
주상분 가중 계수 벡터의 예시
- 아래는 학생들의 다섯 과목 시험 점수에 대한 표본 공분산 행렬 S
*C1 : 기술, C2 : 벡터 => closed book 시험
* O3 : 대수학, O4: 해석학, O5: 통계학 => open book 시험
- 주성분 결과
- 해석
Y1은 모든 변수에 대해서 비슷한 양의 가중 계수를 가지므로 첫 주성분은 가중 평균의 의미를 가짐.
Y2는 closed book 시험에는 양의 가중치, open book 시험에는 음의 가중치를 가지므로 두번째 주성분에서는 클로즈드 북 시험과 오픈북 시험 과목 점수들 사이 대조 관계를 보임
* 개인적 생각 : 클로즈드북 시험인 경우 시험 점수의 분포가 다양하나 오픈 북 시험은 대부분의 학생들의 점수가 비슷하게 잘 나왔기 때문에 이렇다고 보임. 기술 C1이 벡터 C2보다 변동이 큰것 같음.
각 주성분들의 분산과 공분산
- 각 주성분을 정의하는데 이용된 고유벡터들과 쌍을 이루는 고유근이 분산 크기.
=> 고유값 = 분산크기
두 주성분 사이의 공분산
- 주성분들사이 공분산은 0으로 독립임
* PC1은 제 1 주성분, PC2는 제2 주성분 이라고 부름.
양의 상관계수 갖는 이변량 정규분포를 따르는 두변수에서의 주성분
- 분산이 큰 방향이 제 1주성분, 분산이 작은 부분이 제2주성분임.
표본 상관 행렬을 이용한 주성분 분석
- 주성분 분석시 표본 상관 행렬을 많이 사용한다고함
* 변수를 표준화, 즉 측정단위에 얽매이지 않게됨.
- 주성분 분석은 표본 공분산 행렬 S의 고유값과 고유벡터를 이용하여 분산 중심 분석법.
-> 여기서 변수 분산이 1이 되도록 변수를 표준 편차로 나눔
- 표준화 후 표준화 변수 벡터 Z에 대해 분산은 1, 공분산은 상관계수가 됨.
상관계수행렬 R에 기초한 주성분
- 표본 공분산 행렬 S로부터 주성분의 기본적 성질을 그대로 유지
- 주성분 분석에서 S와 R 중 어느 행렬을 분석대상으로 하느냐에 따라 주성분이 서로 다르게 됨.
=> 원래 변수들의 선형 결합인 주성분이 의미를 가지려면 적어도 모든 변수가 동일한 단위로 측정되 필요 있음.
* 아래의 경우(주성분의 의미가 애매해지는)를 방지하기 위함.
- 고려대상의 변수가 직접 비교될 수 없는 단위로 측정된 경우, 각 변수를 표준화 시켜 주성분을 행함. 주성분 분석을 상관행렬에 기초하여 수행. 표준화 변수에 기초한 표준 상관행렬 R을 사용하는 경우 모든 변수의 분산이 똑같이 1이 되어 각 변수가 가지는 변이에서의 상대적 차이 무시
- 사회과학에서 변수는 측정단위가 자의적인 경우가 많음
-> 개별변수 변의 차이에 의미를 부여하는게 힘들 수 있음
=> 상관계수 행렬 R에 기초한 주성분이 많이 사용
주성분 분석 목적
- 기존의 p개의 변수 벡터 X에서 변이(정보)를 잃지 않는 한 작은 수의 주성분유도
=> 차원 축소와 자료 요약
주성분의 특성
1. 7개의 변수 X1, X2, ..., X7의 상관계수 r12, r23, ...., r67이 모두 1인경우
=> 7개의 변수는 하나의 변수, 즉 주성분 1개로 대표 할 수 있다.
* 고유값 lambda 1을 제외한 나머지는 0
2, 7개의 변수 중 한 변수(X7)가 나머지 6개의 변수들의 선형 결합으로 만들어 지는 경우
주성분의 중요도
- 주성분 PC1 : 가장 중요한 주성분 변수로, 변수가 7개시 PC1의 중요도는 아래와 같음.
1988년 서울 올림픽 육상 여성 7종 경기 결과에 대한 주성분 분석
1. 자료 준비
2. 자료 변환
- hurdles, run200m, run800m은 값이 작을수록 좋으므로 변형
=> 높은 점수가 좋은 점수가 되도록 최대값에서 빼줌
3. 주성분 분석 실행
- stats 라이브러리의 princomp 함수 사용
- 변수가 7개이므로, 7개의 주성분을 구하고, 각 주성분의 표준 편차 출력
4. 주성분 분석 결과
- 첫 주성분이 63.72%, 두번째 주성분이 17.06%로 두 주성분이 총 변량 80.8%정보 차지
- 각 주성분의 표준편차를 제곱하여 고유값을 구할 수 있음.
- 제 3 주성분의 고유값이 0.5로 유의미한 주성분은 2개
---- 후기 ---
이전에 주성분 분석에 대한 이야기를 처음 들었을때가
패턴 인식을 공부했을 때였다.
그 때 피처가 큰 경우 차원수를 줄일수 있도록 하기 위해 주성분 분석법을 사용한다고 설명되어 있었지만