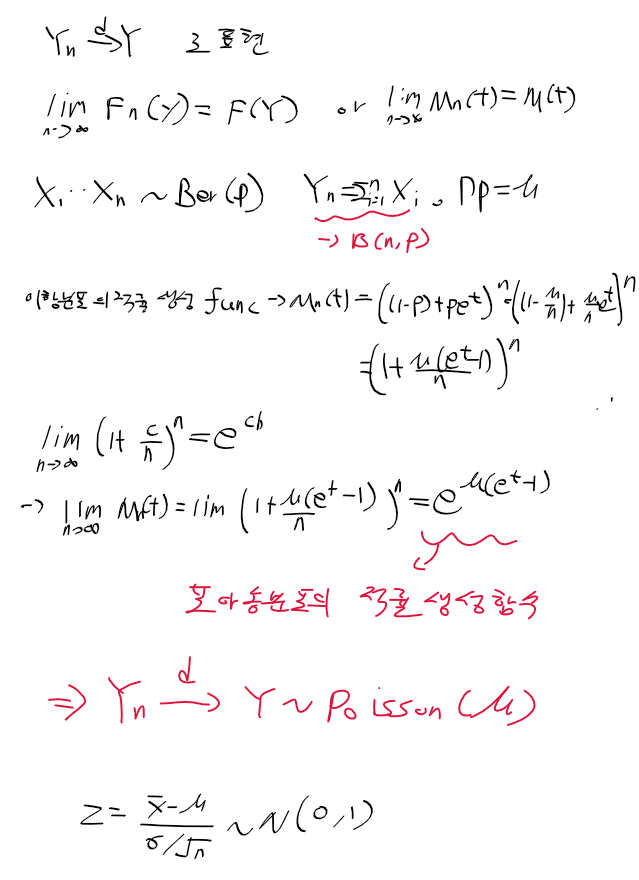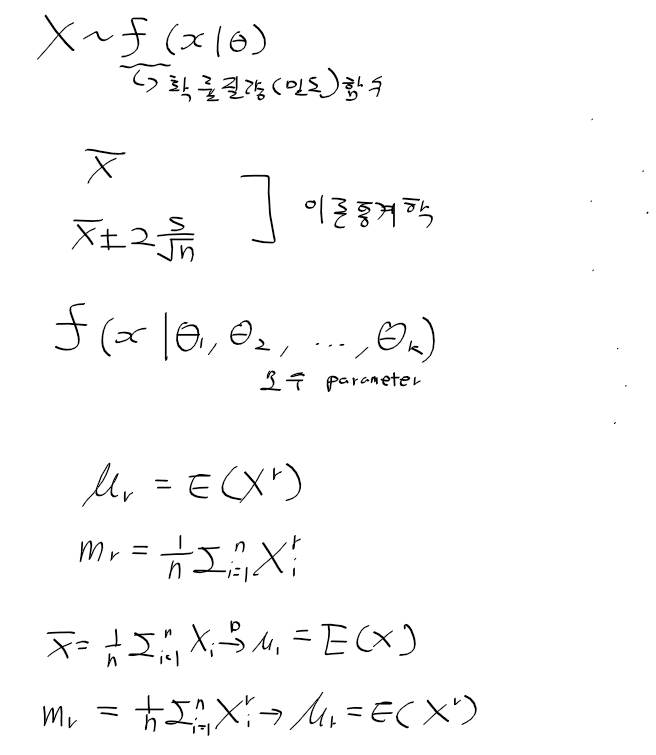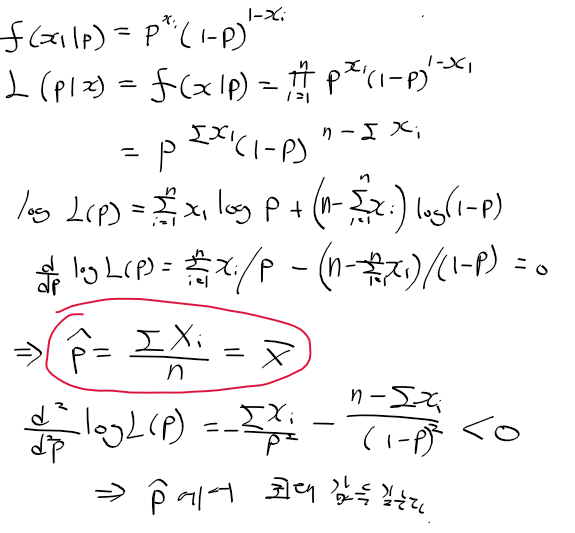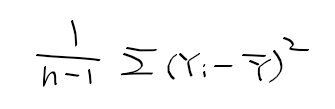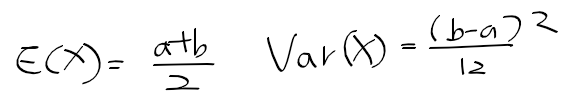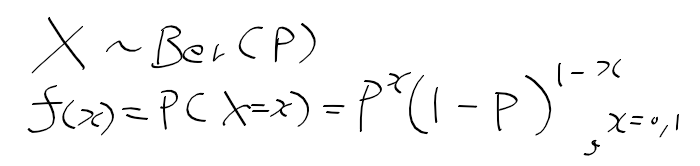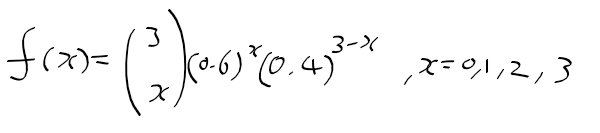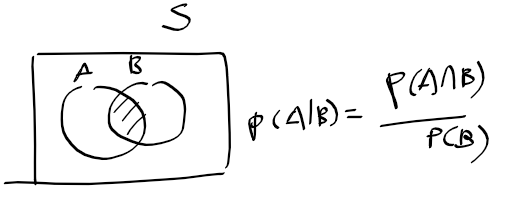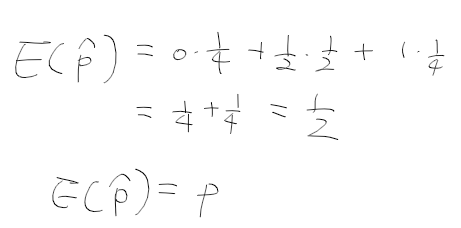적률 추정량
최대 가능도 추정량
어떤 추정량이 좋은 추정량인가?
=> 불편 추정량, 추정량 효율성, 일치추정량, 평균제곱오차를 보자
추정량 estimator
- 모수를 추정하는데 사용되는 통계량 (표본의 함수, 표본평균/표본분산)
추정값 estimate
- 데이터에 근거한 추정량 값
좋은 추정량
- 추정량의 값이 모수와 항상 일치
- 추정량 선택 기준 : 불편성, 효율성, 일치성
추정량의 성질
- 불편성 : 평균하면 모수가 되는가
=> 불편 추정량 unbiased estimator : 불편성을 가진 통계량
- 효율성 : 얼마나 밀집되어있는가
- 일치성 : 수렴한느가

불편향추정량 unbiased estimator
- 통계량 T가 다음을 만족하면 T는 불편 추정량
=> 불편향 추정량 : E(T) = theta
=> 불편향 추정량의 기대값은 모수가 됨.
편향 추정량 biased estimator
- 불편향 추정량이 되지 못하는 추정량
=> 편의 : bias(T) = E(T) - theta

불편향추정량 예제
- X1, ..., Xn ~ Poisson(lambda)를 따르는 확률표본인 경우
- T1 = bar{X}이 불편추정량임을 증명

=> E(T1) = E(bar{X}) = lambda로 모수임을 증명함
편향 추정량 예제
- 다음 추정량의 편향을 구하라

효율성 efficiency
- 분산의 역수
- 불편 추정량 hat{theta}의 효율성

효율성 예제
- X1, ..., Xn ~ N(mu, sigma^2)을 따르는 확률 표본
- S2과 hat sigma2의 효율성을 구하라


-
상대 효율성 relative efficienty
- 하나의 모수를 추정하는 2개의 불편 추정량이 있다면, 그 성능은 효율성으로 비교
- 모수 theta에 대해 불편추정량 T1, T2가 있을떄 T1에 대한 T2의 상대효율성

평균제곱오차의 필요성
- 불편 추정량과 편의 추정량 비교를 하기 위해 아까 본 예제를 다시보면

- 편향성과 효율성을 동시에 고려해야하며 기준 필요
=> MSE
평균제곱오차 Mean Sqaure Error, MSE
- 추정량 T와 모수 theta간 거리 제곱의 평균 측정값
- 통계량 T가 추정 통계량인 경우 T에 대한 평균제곱 오차는 다음과 같다.

평균 제곱 오차의 정리
- 통계량 T에 대한 평균 제곱 오차를 편향과 분산으로 나누면 다음과 같다.

평균 제곱오차 예제
- X1, .., Xn이 N(mu, sigma2)를 따르는 확률 표본인경우 추정량의 효율성과 평균제곱오차를 구해보자
- S2의 효율성과 평균 제곱오차

- sigma2 추정량의 효율성과 평균제곱오차를 구해보자

'수학 > 통계' 카테고리의 다른 글
| 통계 - 10. 점추정량 비교2 (0) | 2020.10.26 |
|---|---|
| 통계 - 9. 복습? (0) | 2020.10.26 |
| 통계 - 7. 점추정 (0) | 2020.10.25 |
| 통계 - 6. 표본분포 (0) | 2020.10.25 |
| 통계 - 5.표본분포 (0) | 2020.10.24 |