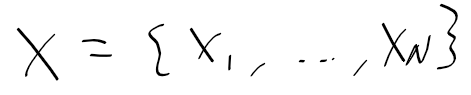수학 mathmetics
- 수학은 현실의 문제를 추상화하여 해결할수 있도록 문제를 정의할수 있는 과학의 언어
수학의 연구
- 고대 그리스 시대부터 본격적으로 연구
-> 플라톤이 기하학을 모르면 공부하러 오자말라고 할정도
- 유클리드의 "element"가 과거 수학의 교과서 역활 함
- 17세기서 페르마, 데카르트, 파스칼, 뉴턴 등의 수학자들이 나옴
뉴턴과 라이프니츠의 업적
- 미적분학 등 해석학의 발전에 기여
-> 수학은 추상화 일반화 경향이 커짐.
수학의 분류
- 순수 수학 : 추상화된 문제를 해결하기 위한 이론 세움
- 응용 수학 : 물리학, 공학, 사회과학 에서 필요
-> 순수 수학으로 얻은 이론을 현실 문제에 적용. 문제를 추상화하여 현실에 적용
쾨니히스베르크의 다리문제
- 두 섬과 육지 사이 7개 다리를 한번에 건널수 있는 길 찾기
=> 찾지 못함. NP완비와 관련
- 오일러는 이걸 한붓 그리기 문제로 단순화하여 산책로가 없음을 증명
쾨니히스베르크의 다리문제로 얻을수 있는 통찰과 수학을 이용한 문제 해결
1. 오일러는 다리 문제 추상화
2. 한붙 그리기 문제로 변환
3. 한붓 그리기가 가능한지 수학적 정리로 적용
4. 불가능함을 증명
수학을 이용한 현실 세계와 추상적 세계의 관계
- 현실 세계 -> 추상화, 문제화 -> 추상적세계
- 현실 세계 <- 해결, 적용 <- 추상적 세계
정의 theorem이란?
- 추상화된 문제는 수학자들이 발견한 중요한 결과. 수학적 정리로 해결.
- 정리 : 사전에 옳다고 정의
=> 정리는 특정 사실(가정)을 옳다고 생각하면 결론이 참이 된다라는 명제의 형태를 띔
- 명제 : P이면 Q이다.
- 대우명제 : Q가 아니면 P가 아니다와 같이 명제의 반대화된 경우를 말함
수학적 명제의 증명 방법들
1. 연역법
- 일반적으로 알려진 이론을 어떠한 현상에 대입시켜 이에 대한 결론을 도출해내는 방법
2. 귀류법
- 명제의 참을 증명하기 힘들때, 명제가 거짓이라 가정하고 그 명제가 모순됨을 보임
=> 원 명제가 참이라 할수 있음. 간접 증명법
3. 수학적 귀납법 mathmetical induction
- 특정 명제가 참임을 증명하고, 다음 명제가 참임을 보여주고, 모든 겨우에 참임을 증명하는 식
=> 이미 알려진 것을 논리적으로 다시 증명하는 방법
집합 set
- 특정 규칙을 따르는 원소들의 모임
체 or 장(field. -> ex. vector field, likelihood field)
- 실수의 기본 성질들을 만족하는 집합
구간 interval
- 구간의 양 끝점을 포함하느냐에 따라 달림
- 열린 구간 open interval : 끝점을 포함하지 않는 구간
=> 표현 : a < x < b (a, b)
- 닫힌 구간 closed interval : 끝 점을 포함하는 구간
=> 표현 : a <= x <= b [a, b]
 https://mathworld.wolfram.com/Interval.html
https://mathworld.wolfram.com/Interval.html
상항, 하한(상계, 한계)
- 상한, 상계 upper bound : x <= a에서의 a
- 하한, 한계 lower bound : a <= x에서의 a
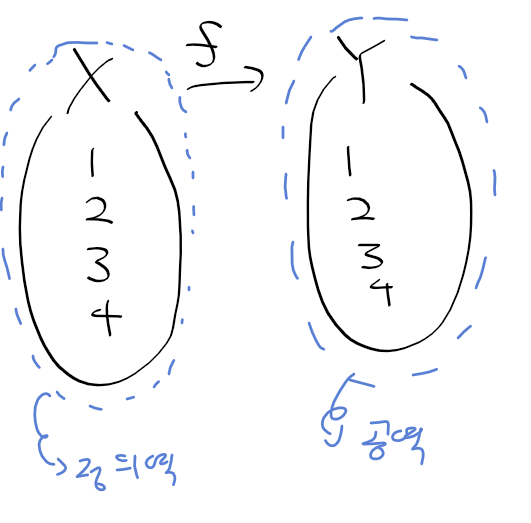
좌표계와 방정식
- 좌표계 : 수가 주어질때 수들의 순서쌍을 좌표상에 나타내는 공간
- 방정식 : x, y 수들의 대응 관계를 표현한 수식
1. 데카르트 좌표계(직교 좌표계, 카티지안 좌표계)
- 일반적으로 사용하는 x, y좌표계
- 직교 좌표계, 카티지안 좌표계라고도 하며 수학자 데카르트가 제안한 좌표계
 https://en.wikipedia.org/wiki/Cartesian_coordinate_system
https://en.wikipedia.org/wiki/Cartesian_coordinate_system
2. 방정식(그래프) equation
- 직선의 그래프(선형)
- 곡선의 그래프, 원그래프(비선형) 등 다양한 그래프들이 존재
 https://www.mathplanet.com/education/algebra-1/formulating-linear-equations/writing-linear-equations-using-the-slope-intercept-form
https://www.mathplanet.com/education/algebra-1/formulating-linear-equations/writing-linear-equations-using-the-slope-intercept-form
 https://www.mathwarehouse.com/geometry/circle/equation-of-a-circle.php
https://www.mathwarehouse.com/geometry/circle/equation-of-a-circle.php