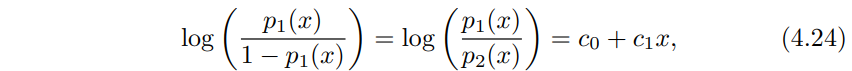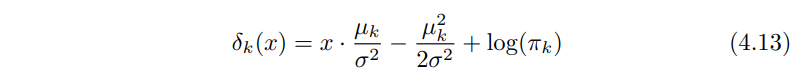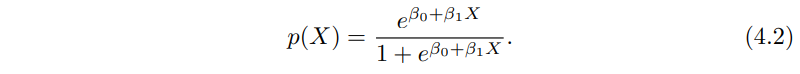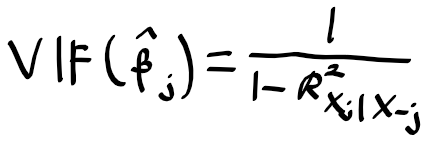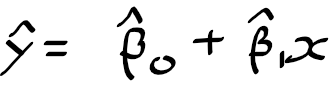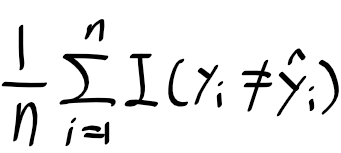5.1.3에서 언급하다시피 k < n인 k-폴드 교차검증은 LOOCV보다 계산에 있어서 이점을 가지고 있는데, 계산 이점 이외에도 LOOCV보다 테스트 에러를 더 정확하게 구할수 있다는 장점이 있습니다. 이 이유는 편향 분산 트레이드 오프와 관련이 있다.
5.1.1에서 검증셋 방법의 경우 전체 데이터셋의 절반을 훈련 셋으로 사용하고 나머지 절반을 검증 셋으로 사용하다보니 실제 테스트 에러율을 과대추정 한다고 했었다. LOOCV는 n - 1개의 데이터를 훈련셋으로 사용하다보니 테스트 에러율의 불편향적인 추정량 unbiased estimates of the test error을 구한다고 볼수 있겠다
k = 5/10인 경우의 k-폴드 교차검증을 하는 경우에는 훈련셋은 (k - 1)n/k 개로 LOOCV보다는 적지만, 검증 셋 방법에서 전체의 절반을 훈련셋으로 사용한것보다는 많다. 그러므로 편향 축소의 관점에서 본다면 LOOCV는 k-fold 교차 검증보다는 더 낫다고 볼수 있겠다.
-> LOOCV는 대부분의 학습 셋가지고 추정을 하다보니
(k - 1) n / k개를 가지고 학습하는 k-fold보다 더 정확, 더 적은 편향, 불편향 추정량을 구한다.
-> k-fold 한 모델은 LOOCV보다 적은 데이터를 가지고 학습하므로 편향적인 추정량을 구한다.
하지만 추정 과정에서는 편향 말고도 분산/변동이 얼마나 큰지도 고려하여야 한다. LOOCV는 k-폴드 교차검증보다 변동이 더 크다고 할수 있는데, 왜 그럴까? 한번 LOOCV를 수행하면 n개의 훈련된 모델들의 결과를 평균으로 구하였었는데 이 n개의 모델들은 n - 1개의 데이터로 학습하다보니 실제와 거의 동일한 데이터셋으로 훈련되었었다. 그래서 이 모델의 결과들은 매우 상관관계를 가지며/서로서로 비슷할수 밖에 없다.
하지만 k-폴드 교차검증의 경우 각 모델의 훈련셋의 겹치는 부분이 LOOCV보다는 적다보니, 각 모델들끼리 상관관계를 덜 가지는 모델들의 출력을 평균으로 구한다. 상관관계가 큰 값들로 평균을 구한 경우 덜한 경우로 평균을 구한것 보다 변동/분산이 더크다보니, LOOCV가 k-폴드 교차검증으로 테스트 에러 추정량을 구한것보다 더 큰 변동/분산을 가지게 된다.
-> LOOCV의 학습에 사용하는 데이터셋은 전체 데이터셋에 가깝다보니 변동에 잘 대처를 하지못함 -> 더 큰 분산
-> K-폴드 CV는 각 모델들의 훈련셋이 겹치는 부분이 LOOCV보다 훨씬 적음 -> 다양한 모델들 -> 더작은 분산
정리하자면 편향-분산 트레이드오프는 k-폴드 교차검증에서 k를 무엇으로 지정하느냐에 따라 달린 문제인데, 이런 것들을 고려해서 k = 5 혹은 k = 10을 지정한경우 테스트 에러율은 아주 큰 편향이나 아주 큰 분산/변동의 영향을 덜 받게 된다.
5.1.5 분류 문제에서의 교차 검증 Cross-Validation on Classification Problems
이번 장에서는 회귀 문제에서 출력 Y가 양적 변수인 경우의 교차 검증을 사용하였고, 테스터 에러의 척도로 MSE를 사용하였다. 하지만 교차 검증은 Y가 질적 변수인 분류 문제에서도 유용하게 사용할 수 있는데, 테스트 에러율을 구하는데 MSE 대신 오분류 횟수를 사용하여 측정할 수가 있겠다. 예를 들어 분류 문제에서 LOOCV 에러율은 아래와 같이 구할 수 있다.
여기서 $Err_{i}$ = I($y_{i}$ $noteq$ $\widehat{y}_{i}$) 이다. k-폴드 교차 검증의 에러율, 검증셋 에러율도 이걸 조금 고쳐서 정의할수가 있겠다.
그림 5.7 그림 2.13에서 본 이차원 분류 데이터를 로지스틱 회귀 모델로 학습한 결과. 보라색 점선이 베이즈 결정경계, 검은 선은 선형, 이차, 삼차, 사차로 추정한 로지스틱 회귀 결정 경계. 네 로지스틱 회귀 모델의 테스트 에러율은 각각 0.201, 0.197, 0.160, 0.162, 그리고 베이즈 에러율은 0.133
예를 들어 그림 2.13에서 봤던 2차원 분류 데이터를 학습하는 로지스틱회귀 모델을 사용한다고 하자. 그림 5.7의 왼쪽 위 판낼에서 검은색 선은 이 데이터를 로지스틱 회귀 모델로 학습시켜 구한 결정경계이다. 이 데이터는 시뮬레이션된 데이터이다보니 실제 테스트 에러율을 계산할수 있고, 구한 결과가 0.201인데, 베이즈 에러율인 0.133보다 크다.
기본적인 로지스틱 회귀 모델은 베이즈 결정 경계만큼 유연성을 가지지 못해 비선형 결정 경계를 가질 수 있도록 입력 변수들의 다항식에 대한 함수로 확장을 해서 회귀를 하였는데, 3.3.2장에서 이전에 했었었다. 여기서 이차 로지스틱 회귀 모델을 만든다고 하면 아래와 같이 구할수가 있다.
그림 5.7 오른쪾 위 판낼에서는 곡선의 결정 경계가 나오고 있는데 이전보다 테스트 에러율이 0.197로 약간만 증가하였다. 그림 5.7 아래 왼쪽 판낼을 보면 입력 변수에 대한 삼차적 곡선으로 로지스틱 회귀 모델을 학습하다보니 결과가 더 개선되었고, 테스트 에러율이 0.160으로 더 줄어들었다. 하지만 오른쪽 아래의 4차 다항식으로 확장시킨 경우 테스트 에러율이 약간 증가하고 말았다.
현실에서는 실제가지고 있는 데이터로는 베이즈 결정 경계와 실제 테스트 에러율을 알 수가 없다. 그러면 그림 5.7에서 본 4가지 로지스틱 회귀 모델들 중에서 어떤걸 골라야 할까? 여기서 교차 검증을 사용하면 된다.
그림 5.8 그림 5.7에서 본 2차원 분류 데이터의 테스트 에러(갈색), 훈련 에러(파랑), 10-폴드 교차검증 에러(검정). 왼쪽 : 입력 변수의 차수에 대한 함수를 사용한 로지스틱 회귀. 다항 차수는 x축에 표기됨. 우측 : 여러 K값을 사용한 KNN분류기.
그림 5.8의 왼쪽 판낼을 보면 검은색은 10-폴드 교차검증 에러율이고, 실제 테스트 에러율은 갈색, 훈련 에러율은 파란색이다. 이전에 봤다 시피 훈련 에러율은 유연성이 증가할수록 감소하는 경향을 보인다.(그림에서 볼수있다시피 테스트 에러율은 단조롭게 쭉 감소하지는 않지만 전체적으로 모델 복잡도가 증가할수록 감소하는 경향이 있다.)
이와 반대로 테스트 에러율은 U자 형태를 보이는데, 10-폴드 교차검증 에러율은 실제 테스트 에러율을 잘 근사하고 있는것을 볼 수 있다. 테스트 에러율을 약간 과소추정을 하고 있지만, 실제 테스트 에러의 경우 4차 다항식일때 최소가 되고, 교차 검증으로 구한 결과 3차 다항식을 사용한 경우 최소가 되며 실제 테스트 커브의 최소 지점과 상당히 가까운걸 알수 있겠다.
그림 5.8의 오른쪽 판낼에는 KNN 분류기를 사용한 경우의 3가지 커브를 보여주고 있다. 여기서 x축은 K를 사용했는데 CV 폴드 갯수 대신 최근접 이웃의 개수가 되겠다. 훈련 에러율은 복잡도/유연성이 증가할수록 감소하고 있으며, 훈련 에러율을 가지고 최적의 K를 찾는데 도움이 안된다고 볼수 있겠따. 교차 검증 에러 곡선의 경우 실제 테스트 에러를 과소 추정을 하고 있지만, 실제 최적의 K에 매우 가까운것을 알 수 있다.
5.2 부트스트랩 Bootstrap
부트스트랩 Boostrap은 널리 사용되며 아주 효과적인 통계적 방법으로 사용하려는 통계적 학습 기법의 추정량이 얼마나 불확실한지 uncertainty를 측정하는데 사용할 수 있다. 간단한 예를 들자면 부트스트랩은 선형 회귀 모델의 계수 표준 오차를 추정하는데 사용할 수 있는데, R 같은 통계 소프트웨어로 표준 오차같은 것들은 자동적으로 계산해주다보니 선형 회귀 모델에 대해서 이렇게는 잘 사용하지는 않지만, 부트스트랩의 강점은 통계 소프트웨어로 자동으로 계산할수 있는 출력이 아니거나 변동성을 구하기 힘든 경우를 포함하여 다양한 통계적 학습 기법에서 널리 쉽게 사용할수 있다는 점이다.
이번 장에서는 간단한 모델로 어떻게 최적의 투자를 할지 결정하는 간단한 예시에서 부트스트랩을 사용하여 보자. 5.3장에서는 선형 회귀 모델의 회귀 계수들의 변동성을 평가하기 위해 부트스트랩을 사용하겠다.
일단 고정된 소지금을 수익을 내는 두 금융 자산 X, Y에 투자한다고 하자. 여기서 X, Y은 양적 변수이다. 그리고 총 금액에 X에 투자한 비율을 $\alpha$, Y에 투자한 비율을 1 - $\alpha$라고 한다. 두 자산의 수익 사이에는 변동성이 존재하므로 투자에 전체 리스크, 분산을 최소화 하는 $\alpha$를 구하고자 한다.
다시 말하면 Var($\alpha$ X + (1 - $\alpha$) Y)를 최소화 하고자 하는것이며, 이 리스크를 최소화 하는 $\alpha$를 아래와 같이 정의할수 있다. $\sigma^{2}_{X}$ = Var(X), $\sigma^{2}_{Y}$ = Var(Y), $\sigma_{XY}$ = Cov(X, Y).
실제 $\sigma^{2}_{X}$, $\sigma^{2}_{Y}$, $\sigma_{YX}$에 대한 값은 알 수 없으므로, 이 세 값에 대한 추정치인 $\widehat{\sigma}^{2}_{X}$, $\widehat{\sigma}^{2}_{Y}$, $\widehat{\sigma}_{XY}$를 이전의 X, Y에 대한 데이터들로 계산 하여야 한다. 그러면 아래의 식으로 투자 변동성을 최소화 시키는 $\alpha$ 추정량을 아래와 같이 구할수 있겠다.
그림 5.9 각 판낼들은 X, Y 투자에 대한 100개 수익 데이터들을 보여줌. 왼쪽 위 부터 오른쪾 아래까지 알파값 추정량은 0.576, 0.532, 0.657, 0.651
그림 5.9은 시뮬레이션 데이터로 $\alpha$를 추정하는 과정을 보여주는데, 각 판낼에는 X, Y에 투자시 수익에 대한 100개의 데이터로 $\sigma^{2}_{X}$, $\sigma^{2}_{Y}$, $\sigma_{XY}$에 대한 추정량을 식 (5.7)에 대입하여 $\alpha$의 추정치를 구하였다. 각 시뮬레이션된 데이터셋으로 추정한 $\widehat^{\alpha}$는 0.532 ~ 0.657가 되겠다.
그러면 여기서 $\alpha\ 추정량이 얼마나 정확한지 측정하고 싶을텐데, $\widehat{\alpha}$의 표준 편차를 추정하기 위해서는 X, Y 쌍 100개 가지고 $\alpha$의 추정량을 계산하는 과정을 1000번 반복하면 된다. 그렇게 $\alpha$ 추정량 1000개 $\widehat{\alpha}_{1}$, . . . , $\widehat{\alpha}_{1000}$을 구하면 된다.
왼쪽 : 모 집단 true population으로부터 생성시킨 1000개의 시뮬레이션 데이터셋으로 추정한 알파값들의 히스토그램, 중앙 : 하나의 데이터셋으로부터 1000개의 부트스트랩 샘플들을 구하여 추정한 알파값들의 히스토그램, 우측 : 왼쪽과 중앙의 알파값 추정량에 대한 박스 플롯. 각 판낼에서 분홍색인 실제 알파값을 나타내고 있다.
그림 5.10의 왼쪽 판낼은 각 추정치의 히스토그램을 보여주고 있다. 여기서 사용한 시뮬레이션의 파라미터들은$\sigma^{2}_{X}$ = 1, $\sigma^{2}_{Y}$ = 1.25, $\sigma_{XY}$ = 0.5로 설정되어 있고, 실제 $\alpha$값은 0.6이다. 이 실제 알파값은 히스토그램에서 수직선으로 표시해 두었다. $\alpha$ 추정량 1000개의 평균을 구한 결과는 아래와 같으며 실제 $\alpha$ = 0.6에 가까운 결과를 얻을수가 있다.
그리고, 이 추정량의 표준편차는 아래와 같으며 $\widehat{\alpha}$ : SE($\widehat{\alpha}$) $\approx$ 0.083으로 꽤 정확한 결과를 얻었다고 볼수 있겠다.
정리하자면 모 집단으로 구한 샘플들로 추정한 결과 $\widehat{\alpha}$와 $\alpha$의 차이가 평균적으로 0.08정도 밖에 되지않는다고 볼수있다.
하지만 현실에서는 모집단으로부터 새 샘플들 그러니까 실제 데이터를 구할수 없다보니 위 SE($widehat{\alpha}$)를 추정하는 과정을 사용할 수 없다. 하지만 부트스트랩 방법을 이용해서 새로운 샘플 셋을 얻는 과정을 모방해서 계산할수가 있고, 별도로 샘플들을 생성하는 과정 없이 $\widehat{\alpha}$의 변동을 추정할수가 있다.
정리
-> 위 내용은 추정량의 불확실한 정도를 표준 편차로 계산하는 과정을 정리함
-> 모집단, 파라미터를 알고 있어 데이터를 생성하여 표준 편차, 불확실성을 계산할 수 있었슴.
-> 하지만 현실에서는 모집단을 모르는 경우가 많으며, 표준편차, 불확실성을 계산할수가 없음
=> 부트스트랩으로 여러 셋을 생성하고, 각 셋들의 추정량들의 평균으로 표준편차, 불확실성을 계산한다.
부트스트랩이란
부트스트랩은 모집단으로부터 독립적인 데이터셋을 여러번 구하는게 아니라 원본 데이터셋에서 여러번 데이터를 샘플링을 해서 서로 다른 데이터셋들을 얻는 방법이다.
그림 5.11 데이터 3개뿐인 데이터셋가지고 부트스트랩 방법을 사용하는 예시. 각 부트스트랩 데이터셋은 데이터가 3개이며, 원본 데이터셋으로부터 샘플을 뽑아 만들었다. 각 부트스트랩 데이터셋은 알파 추정값을 구하는데 사용된다.
LOOCV Leave-one-out cross-validation은 5.1.1장에서 본 검증 방법과 비슷한 방법이나 그 방법의 결점을 개선한 것으로 교차 검증셋 방법처럼 LOOCV도 전체 데이터를 두 파트로 나누지만, 어느 정도의 크기의 하부 집합으로 분할하는게 아니라 하나의 데이터 ($x_{1}$, $y_{1}$)만 검증 셋으로 사용하고 나머지 {($x_{2}$, $y_{2}$, . . ., ($x_{n}$, $y_{n}$))}은 훈련셋으로 사용하는 방법입니다. 그래서 통계적 학습 방법을 이용하여 n - 1개의 훈련 데이터들을 학습하고, 1개의 데이터 $x_{1}$으로 $\widehat{y}_{1}$을 예측하게 되요.
($x_{1}$, $y_{1}$)만 훈련 과정에서 사용되지 않다보니 $MSE_{1}$ = ($y_{1}$ - $\widehat{y}_{1}$ $)^{2}$은 불편향 추정량인 테스트 에러가 됩니다. 그리고 하나의 데이터만 가지고 테스트를 추정기에는 변동이 큰 문제가 있겠습니다. 이 과정을 ($x_{2}$, $y_{2}$)을 검증셋으로 사용하고 나머지 n - 1개를 훈련으로 사용해서$MSE_{2}$ = ($y_{2}$ - $\widehat{y}_{2}$ $)^{2}$ 를 계산할 수가 있겠습니다. 그래서 이 제곱 오차를 n번 구할수가 있고 $MSE_{1}$, $MSE_{2}$, . . . , $MSE_{n}$을 구해서 이 n 개의 테스트 에러 추정치를 평균으로하여 LOOCV 추정량을 계산 할 수가 있겠습니다.
그림 5.3 LOOCV 개요도. n개의 데이터를 가지고 데이터 1개를 검증셋(주황색), 나머지 n - 1개의 데이터들을 훈련셋으로 사용함. 테스트 에러는 n개의 MSE의 평균을 구하여 계산한다.
* LOOCV에 대한 내용은 여기까지만*
5.1.3 K-폴드 교차 검증
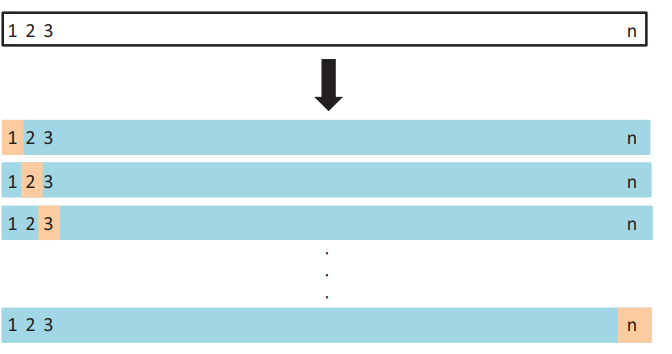
이번에 볼 LOOCV(생략)의 대안으로 사용할 수 있는 방법으로 k-fold 교차 검증 방법이 있다. 이 방법은 전체 데이터들을 동일한 사이즈를 가지는 k개의 그룹(폴드)로 무작위로 나누고 한 폴드는 검증 데이터셋 나머지 k - 1개의 폴드들은 학습하는데 사용하는 방법이다.
평균 제곱 오차 MSE는 각 폴드들은 한번은 검증 데이터셋, 나머지는 학습 셋으로 사용되도록 하여 전체 k번을 반복하며 각 k 번째 폴드의 $MSE_{1}$, $MSE_{2}$, . . ., $MSE_{k}$의 평균을 구하는 식으로 K-폴드 검증 테스트 에러를 구한다.
그림 5.5 이 그림은 5-폴드 교차검증의 개요도로. 전체 데이터들을 겹치지 않는 5개의 그룹으로 분할한다. 각 분할된 폴드(베이지)는 검증셋으로 사용되고, 그 이외는 훈련셋(파란색)으로 사용된다. 테스트 에러는 각 폴드들의 MSE를 평균으로 계산한다.
LOOCV는 K-폴드 교차검증에서 k를 n으로 설정한거라고 할수 있는데, k-폴드 교차검증에서는 k = 5 혹은 k = 10이라는 식으로 사용한다. k = n이 아닌, k = 5 또는 k = 10으로 지정해서 사용ㅇ하는 경우 이점은 어떤게 있을까? 가장 명확한 장점은 계산 성능이라고 할수 있겠다. LOOCV는 학습과정에 n번을 수행하여야 하다보니 계산 비용이 아주 클수가 있다.
하지만 교차 검증은 어떤 통계적 학습 방법이던 간에 사용할수 있는 방법이기도 한데, 일부 학습 방법의 경우 계산 비용이 아주 클수가 있고, 그래서 LOOCV는 특히 n이 큰 경우에 계산비용적으로 문제가 될수 있다.
하지만 이와 반대로 10-폴드 교차검증의 경우에는 학습 과정을 10번만 하면 되다보니, n보다는 더 계산할수 있으며, 5.1.4장에는 5-폴드 혹은 10-폴드 교차검증의 계산과 관련되지 않은 장점들 편향-분산의 트레이드오프를 보겠다.
그림 5.4 차량 데이터셋에서 마력에 대한 다항함수로 mpg를 얼마나 잘 예측하는지를 보기 위해 테스트 에러를 계산하도록 교차검증이 사용됨. 좌측 : LOOCV 곡선, 우측 : 10폴드 교차검증으로 구한 결과. 우측의 계산 결과들은 조금씩 다르게 나오고 있다.
그림 5.4의 우측 판낼은 10-폴드 교차검증으로 구한 9개의 테스트 에러 결과인데, 10폴드로 나누어서 학습하고 검증시킨 결과에 약간의 변동이 있는걸 볼수 있다. 하지만 이 변동은 그림 5.2의 오른쪽 판낼에서 볼 수 있는 검증셋 방법(홀드 아웃 방법)보다 테스트 에러에서 변동이 일반적으로는 더 작다.
실제 데이터를 사용하는 경우, 우리는 실제 테스트 MSE를 모르다보니 교차 검증의 결과가 얼마나 정확한지를 판단하기는 어려우나 시뮬레이션으로 생성한 데이터를 사용하는 경우 실제 Test MSE를 계산할수 있고 교차 검증의 결과가 얼마나 정확한지 평가할 수 있다.
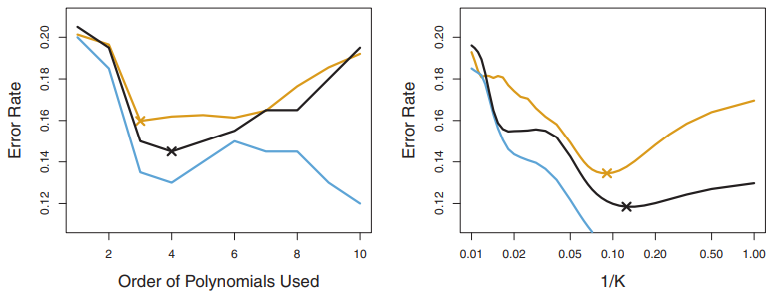
그림 5.6 그림 2.9, 2.10, 2.11에서 사용한 시뮬레이션 데이터의 실제 그리고 추정 테스트 MSE. 실제 MSE는 파란색 선이고, LOOCV로 구한 결과는 검은 점선, 10-폴드 교차 검증으로 구한 결과는 주황색이다. 그리고 X 표시된 지점은 각 MSE곡선이 최저인 지점들을 표기하였다.
그림 5.6은 2장에서 본 그림 2.9 ~ 2.11에서 사용된 시뮬레이션된 데이터를 가지고 교차 검증/실제 테스트 에러율을 보여주고 있습니다. 여기서 실제 테스트 에러율은 파란선이고, 검은 점선과 주황 선은 LOOCV와 10-폴드 교차검증 추정 MSE가 됩니다.
세 플롯들 다 두 교차 검증 추정량은 비슷하지만 그림 5.6의 오른쪽 판낼에서 실제 테스트 에러율과 교차 검증 테스트 에러율이 아주 비슷한 것을 볼 수 있습니다. 그림 5.6의 중간 판낼의 경우 두 교차 검증 곡선은 차수/유연성이 낮을때는 비슷하지만 유연성/차수가 높을때 테스트 에러율을 과대 추정하고 있습니다. 그림 5.6의 왼쪽 판낼은 교차 검증 곡선들을 형태는 올바르지만 실제 테스트 MSE를 과소 추정하고 있는걸 볼 수 있습니다.
이런 교차 검증을 사용해서 테스트 MSE 추정치를 계산을 하는게 목표가 될 수도 있고, 테스트 MSE 커브의 최소가 되는 지점을 찾는게 목표가 될수도 있겠습니다. 이 지점은 다양한 차수/복잡도를 가지는 모델을 교차검증으로 구할수가 있습니다. 그림 5.6에서처럼 어떤 경우 테스트 MSE 곡선이 실제 테스트 MSE를 과소 평가할때도 있지만, 모든 교차 검증 곡선들은 복잡도에 따라 동일한 형태를 보이며 이를 통해서 가장 작은 테스트 MSE를 찾을수가 있겠습니다.
4.5 분류 방법들의 비교 A Comparison of Classification methods
이번 장에서는 우리는 3가지 분류 방법인 로지스틱 회귀, LDA, QDA까지 살펴봤습니다. 2장에서도 KNN에 대해서 이야기 해썼는데, 몇 가지 상황에서 이런 방법들이 성능이 어떻게 나오는지 한번 살펴봅시다.
이 방법들끼리 고안된 배경은 다르지만 로지스틱회귀와 LDA 방법들은 아주 가까이 관련되어 있어요. 두 클래스를 분류하는 상황에서 입력변수 p = 1이라고 할께요. 그러면 $p_{1}$(x), $p_{2}$ = 1 - $p_{1}$(x)가 관측치 X = x가 주어질때 클래스 1 혹은 클래스 2에 속할 확률이 될거에요. LDA의 경우 식 (4.12), (4.13)을 로그 오즈를 취하면 아래와 같이 될겁니다. $c_{0}$, $c_{1}$은 $\mu_{1}$, $\mu_{2}$, $\sigma^{2}$에 대한 함수가 되겠습니다.
식 (4.4)로부터 로지스틱 회귀의 경우 아래와 같이 정리할 수 있는데
식 (4.24)와 식(4.25)둘다 x에 대한 선형 함수에요. 그래서 로지스틱 회귀와 LDA는 선형 결정 경계를 만들어 냅니다. 두 방법사이 차이점이라 하면 $\beta_{0}$, $\beta_{1}$는 최대 가능도법 maximum likelihood로 구한다는것이고, $c_{0}$, $c_{1}$는 정규 분포를 따르는 평균과 분산 추정량으로 계산한다는 점입니다. LDA와 로지스틱 회귀 사이 이런 관계가 p > 1인 다차원 데이터에서도 존재해요.
로지스틱 회귀와 LDA의 차이점이 학습하는 과정뿐이다보니 두 방법은 비슷한 결과를 보이고 있어요. 하지만 항상그렇지는 않습니다. LDA는 관측치들이 각 클래스들끼리 공통된 공분산을 가지는 가우시안 분포를 따른다고 가정하고 있어, 이 가정이 올바른 경우 로지스틱 회귀를 능가합니다. 역으로 로지스틱 회귀난 가우시안 가정이 적합하지 않은 경우 LDA보다 더 좋으성능을 보입니다.
2장에서 봤던 KNN은 이번장에서 본 분류기랑은 완전히 다른 방법인데, X = x에 대한 관측치를 예측하기 위해서, x와 가까운 K개의 관측치를 찾아야 합니다. 그리고 주위에 있는 관측치가 많이 속해있는 클래스로 분류되요. 그래서 KNN은 완어떠한 결정 경계의 형태를 가진다는 가정이 없는 완전히 비모수적인 방법이라고 할수 있습니다.
그러므로 이 방법은 LDA나 로지스틱회귀보다 결정 경계가 완전히 비선형적인경우 더 뛰어난 성능을 보인다고 할 수 있어요. 하지만 KNN은 입력 변수들이 얼마나 중요한지 알려주는게 없다보니 표 4.3과같은 계수에 대한 테이블을 만들수가 없습니다.
마지막으로 QDA는 비모수적 방법인 KNN과 선형 LDA, 로지스틱 회귀 방법들을 절충한거라고 할수 있어요. QDA는 이차 결정 경계를 가정하다보니, 선형 방법들보다 더 넓은 범위를 정확한 모델을 만들수가 있어요. 하지만 KNN만큼 유연하지는 않고, QDA는 결정 경계의 형태에 대한 가정들을 만들다 보니 데이터가 많이 있을수록 더 좋은 성능을 보여요.
이 네가지 분류 방법의 성능을 보기위해서 6가지 서로 다른 시나리오의 데이터를 생성하였습니다. 세가지 시나리오 에서는 베이즈 결정경계는 선형적이고, 나머지 시나리오에서는 비선형적이라고 하겠습니다. 각 시나리오는 훈련데이터가 100개라고 해요. 그리고 이 데이터셋들로 학습을하고, 테스트 에러율을 구해볼게요.
그림 4.10 선형적인 시나리오들의 에러율을 비교하는 박스플롯.그림 4.11 비선형적인 시나리오들에 대한 테스트에러율의 박스플롯
그림 4.10가 선형 시나리오에 대한 결과, 그림 4.11은 비선형적인 시나리오들의 테스트 에러율의 결과를 보여주고 있습니다. KNN은 K를 지정하는게 필요하니 K는 1로 지정한 경우와 5장에서 다룰 교차검증 cross validation이란 방법으로 자동적으로 찾은 K를 사용하였습니다.
이 6개의 시나리오들은 p = 2이며, 아래와 같습니다.
- 시나리오 1 : 클래스 2개에 각각 20개의 관측치가 있고, 한 클래스에 속하는 관측치들ㅈ은 서로 다른 클래스와 상관관계를 가지고 있지 않아요. 그림 4.10의 왼쪽 그림에서 LDA가 잘동작하고 있지만 KNN는 편향을 제거하여 분산이 오프셋되지않다보니 나쁜 성능을 보이고 있습니다. QDA또한 LDA보다 필요 이상으로 유연하다보니 좋은 성능이 나오지않아요. 로지스틱 회귀는 선형 결정 경계를 가정으로 하고있어 LDA보다 성능이 약간 떨어지는걸 볼수 있습니다.
- 시나리오 2 : 자세한 사항은 시나리오 1과 동일하지만 두 입력변수간에 -0.5의 상관관계를 가진다고 할께요. 그림 4.10의 중간 판낼을 보면 이전 시나리오와 비교하면 각 방법들의 성능이 약간 바뀐걸 볼수 있어요.
- 시나리오 3 : $X_{1}$과 $X_{2}$는 t분포로를 따르며, 각 클래스 당 관측치가 50개를 가져요. t 분포는 정규 분포와 비슷한 형태이지만 평균으로부터 더 멀어진 경향을 보여요. 여기서도 결정경계는 선형적이고, 로지스틱을 학습한다고 할께요. 하지만 LDA의 가정을 위반해서, 다시말하면 정규분포를 따르지않아 그림 4.10의 오른쪽 판낼에서 로지스틱이 LDA보다 더 좋은 성능을 보이고 있고, 다른 방법들보다 우수한 성능을보여요. 하지만 비정규성을 따르다보니 QDA의 성능이 상당히 떨어졌어요.
- 시나리오 4 : 데이터를 정규 분포로 생성했고 첫번쨰 클래스의 입력변수들은 0.5의 상관관계를 가지고 있고, 두번쨰 클래스의 입력 변수들은 -0.5의 상관관계를 갖는다고 할꼐요. 이 상황은 QDA의 가정을 잘 따르므로 이차 결정 경계의 형태가 나오죠. 그림 4.11의 왼쪽 패널은 QDA가 다른 방법들에 비해 큰 성능을 보이는걸 알 수 있어요.
- 시나리오 5 : 각 클래스들에 대한 관측치들은 정규분포로 생성했으며, 입력 변수 끼리 상관관계를 가지고 있지 않습니다. 하지만 반응 변수들을 $X_{1}^{2}$, $X_{2}^{2}$, $X_{1}$ x $X_{2}$를 입력변수로 하는 로지스틱 함수로부터 얻었다고 할께요. 그결과 결정 경계가 이차적으로 되다보니 그림 4.11의 중간 판낼에서 QDA가 최고의 성능을 보이고 KNN_CV가 뒤쫓아오고 있어요. 하지만 선형 방법들은 성능이 크게 떨어집니다.
- 시나리오 6 : 이전 시나리오와 동일하나 반응 값들을 더 복잡한 비선형 함수로 얻은 경우로, 결과를 보면 QDA의 이차 결정 경계는 이 데이터를 적절하게 모델링하지 못하고 있습니다. 그림 4.11의 오른쪽 판낼을 보면 QDA는 다른 선형 모델보다 약간 더 나은 성능을 보이기는 하지만 가장 유연한 KNN-CV방법이 최고의 결과를 보이고 있어요. 이 시나리오에서는 데이터가 너무 복잡한 비선형 관계를 가질때 유연성의 정도(K값)을 적절하게 지정하지 않으면 KNN같은 비모수적 방법도 여전히 성능이 뒤떨어지는걸 볼 수 있어요.
이 여섯가지 예시들을보면 모든 상황에서 최고의 성능을보이는 한가지 방법은 존재하지 않습니다. 실제 결정경계가 선형인 경우 LDA와 로지스틱 회귀가 잘 동작하는 편이었으며, 결정경계가 약간 비선형적이라면 QDA가 좋은 성능을 보였어요. 마지막에 아주 복잡한 결정 경계를 갖는 경우 KNN같은 비모수적 방법이 가장 뛰어났습니다. 하지만 비모수적 방법의 완만도(K값)을 신중하게 정해야해요. 다음 장에서는 올바른 완만도를 찾기위한 수많은 방법들을 살펴보고 최적의 방법을 골라보겠습니다.
마지막으로 3장에서 배운 내용을 다시 생각해보면, 입력 변수들을 변환을 하고 회귀를 수행해서 입력과 반응 사이 비선형적인 관계를 다룰수가 있었습니다. 비슷하게 분류에서도 그렇게 할수가 있어요. 예를들면 $X^{2}$, $X^{3}$, $X^{4}$같은 입력변수들을 추가해서 로지스틱 회귀의 유연한 버전을 만들수도 있겠습니다.
하지만 이거는 분산이 크게 증가하느냐에 따라 성능이 개선될수도 있고 안될수도 있어요. 이건 추가된 유연성이 편향을 충분히 크게 상쉐시킬지에 달렸거든요. LDA에서도 똑같이 적용할수 있겠습니다. 만약 LDA다가 이차항이나 교차항을 추가시키면, 계수 추정치가 다르더라도 QDA랑 똑같은 형태가 될수도 있을거에요. 이러한 방법들로 LDA를 QDA로, QDA를 LDA로 변화시킬수 있겠습니다.
5. 리샘플링 기법
리샘플링 기법은 현대 통계학에서 필수적인 도구입니다. 이 방법은 훈련 데이터셋으로 반복해서 샘플을 뽑고, 이렇게 뽑은 샘플로 모델을 학습시켜 전체 훈련 데이터셋을 한번에 학습시킨것과 다른 모델을 만들어 추가적인 정보를 얻을수가 있어요. 예를든다면 선형 회귀 모델의 변동성을 추정하고자 할때 훈련 데이터셋으로부터 다른 샘플들을 반복해서 뽑고 이걸 학습을 시키면, 다른 학습 모델을 만들어 추가적인 정보를 얻을수가 있습니다. 이러한 방법을 덕분에 기존 원본 훈련 데이터 샘플을 만든 모델과는 다른 정보들을 얻을수 있게 됩니다.
리샘플링 기법은 계산 비용이 꽤 클수 있는데, 훈련 데이터에서 여러 하부집합들을 뽑아 여러번 통계적인 학습을 수행할수도 있거든요. 하지만 최근 계산 성능이 좋아지면서 리샘플링 기법의 계산 비용 문제는 사라졌습니다. 이번 장에서는 가장 널리 사용되는 리샘플링 기법인 교차 검증 cross validation과 부트스트랩 boostrap 기법에 대해서 이야기 해봅시다.
이 방법 둘다 많은 통계적 학습 과정에서 매우 자주 사용되는 방법인데, 예를들어 교차 검증 같은 경우에는 우리가 만든 통계적 학습 모델의 테스트 에러율을 구하여, 모델의 성능을 보거나 적절한 유연성 정도를 찾기위해서 사용해요. 이렇게 추정한 모델의 성능을 평가하는 과정을 모델 평가 model assessment라고 부르고, 모델의 유연성 정도를 찾아내는 과ㅏ정을 모델 선택 model selection이라고 부릅니다. 부트스트랩 boostrap은 다양한 상황에서 사용되고 있는데, 가장 흔하게는 주어진 통계적 학습 방법의 파라미터 추정치가 얼마나 정확한지 측정하고자 사용되요.
5.1 교차 검증 cross-validation
2장에서 테스트 에러율 test error rate와 훈련 에러율 train error rate의 차이를 살펴봤었습니다. 테스트 에러율은 학습하지 못한 관측치를 예측할때 평균 에러율이었었어요. 데이터셋이 주어지고 테스트 에러가 낮은 통계적 학습 방법이 사용되어요. 테스트 에러는 테스트 데이터셋이 있으면 쉽게 계산할수 있지만 가끔 없는 경우도 존재합니다.
반대로 훈련 에러는 통계적 학습 모델에다가 훈련떄 사용한 관측치들을 넣어 쉽게 계산할 수 있어요. 하지만 2장에서 봤다 시피 훈련 에러율은 테스트 에러율과 꽤 다를수 있으며, 대체로 훈련 에러율은 테스트 에러율보다 크게 떨어져요.
테스트 에러율을 계산하는데 필요한 테스트 데이터셋이 없을때 가지고 있는 데이터로 이 척도를 구하는 많은 방법들이 있는데, 어떤 방법들은 훈련 에러율을 수학적인 방법으로 조정해서 테스트 에러율을 구하기도 하지만 이건 6장에서 살펴보겠습니다.
이번 장에서는 학습 과정에서 사용될수 있는 훈련 관측치들의 일부를 홀드 아웃hold out/집어와서 테스트 에러율을 계산하는 방법들을 이야기해보고, 통계적 학습 기법들에 적용해봅시다.
5.1.1 ~ 5.1.4장에서는 양적 반응을 가지는 회귀 모델을 가정하고 간단하게 살펴보고, 5.1.5장에서는 질적 변수를 다루는 분류 문제를 살펴봅시다. 질적 변수든 양적 변수든 키 컨샙은 같다고 보면 되요.
5.1.1 검증 데이터셋 방법 The Validation Set Approach
그림 5.1 검증 데이터셋 방법의 개요도 schemetic. n개의 관측치들이 있는 데이터셋을 훈련 데이터셋(파란색 부분, 7, 22, 13, 그리고 나머지)와 검증 데이터셋(베이지부분, 91, 그리고 나머지)로 분할하였습니다. 통계적 학습 기법으로 훈련 데이터셋을 학습하고 검증데이터셋으로 성능을 평가하면 되요.
한번 우리가 훈련 에러율을 구하고 싶을대, 그림 5.1의 검증 데이터셋 방법이 사용될 수 있는대 매우 간단한 방법이에요. 그냥 주어진 데이터셋을 훈련데이터셋 training set과 검증 데이터셋 validation set/ 홀드아웃데이터셋 hold-out set으로 임의로 나눠주기만 하면 되거든요. 그러면 모델은 훈련 데이터셋을 학습하고, 학습한 모델을 검증 데이터셋으로 결과를 예측해서 검증하면 되요. 그렇게 양적 반응에 대한 MSE를 계산해서 검증 데이터셋의 에러율을 구하면 그게 테스트 에러율로 보면 되겠습니다.
한번 이 검증 데이터 셋 방법을 차량 데이터셋에다가 사용해볼꼐요. 우리는 지난 3장에서 mpg와 마력 사이에 비선형 관계가 있는걸 봤었어요. 그리고 마력과 $마력^{2}$으로 mpg를 예측하는 모델을 만들어서 선형 항만 있었을때보다는 더 나은 결과를 얻을수가 있었습니다. 그렇다보니 무조건 더 높은 차수를 가지고 있으면 더 좋은 결과를 얻을수 있을까? 궁금할수 있을거에요.
3장에서 이 질문에 대해서 2차항과 더 고차 항을 사용하는 선형 회귀의 p value를 보면서 확인할수 ㅇ있었습니다. 하지만 p value말고도 검증 데이터셋을 사용해서 확인할 수도 있어요. 그러면 한번 392개의 관측치들을 196개의 훈련 데이터셋과 196개의 검증 데이터셋으로 분할시켜볼꼐요.
그림 5.2 검증 데이터셋 방법을 차량 데이터셋에 사용한 결과. 테스트 에러율은 마력에 대한 다항식으로 mpg를 예측해서 구했습니다. 좌측 : 전체 데이터셋을 훈련과 검증 데이터셋을로 나누었을때 검증 에러율. 우측 : 검증 데이터 셋 방법을 10번 반복해서, 10개의 랜덤한 훈련데이터들셋과 검증데이터셋들로 구한 결과를 보여주고 있습니다. 여기서 보이는 테스트 MSE가 이 방법의 변동성을 보여주고 있어요.
검증 데이터셋 에러율은 훈련 데이터셋으로 여러가지 복잡도/차수를 가진 모델들을 학습하고, 검증 셋으로 성능 평가해서 구할수가 있겠죠. 여기서 MSE를 검증 셋의 에러 평가 척도로 사용해서 보았고, 그 결과를 그림 5.2의 왼쪽 판낼에서 볼수 있어요.
이차 학습 모델의 검증 데이터셋 MSE는 선형적인 모델보다 상당히 줄어들었지만, 삼차항 모델같은 경우 이차 모델보다 약간 증가하였죠. 그래서 회귀 모델에서 삼차항까지 포함시킨다고해서 간단하게 이차항을 썻을때보다 예측성능이 더나아진다고 볼수는 어렵습니다.
한번 그림 5.2의 판낼처럼 만들기위해서 한번 데이터셋을 훈련 데이터셋과 검증 데이터셋으로 임의로 나눴다고 해볼깨요. 그런데 이 동작을 여러번 반복하면, 테스트 MSE도 계속 다르게 나올거에요. 이 내용이 그림 5.2의 오른쪽 판낼에서 나오는대 서로 다른 10개의 훈련데이터로 학습하고, 검증데이터셋으로 평가한 테스트 MSE를 보여주고 있어요.
모든 곡선들을 보면 이차항 까지만 포함된 모델의 경우 선형 항만 포함된 모델보다 훨씬 테스트 MSE가 적은걸 볼수 있어요. 그러므로 10가지 경우들을 보면서 3차항이나 더 고차항을 쓴다고해서 더 나은 성능을 얻을수 있지 않다는걸 알 수 있어요. 그리고 서로 다른 회귀 모델가지고 테스트 MSE를 구했으니 서로 다른 곡선들이 나오는게 당연하구요. 그렇다보니 한 모델이 가장 낮은 검증 MSE를 가진다고 하기도 힘들어요. 이런 곡선들의 변동성을 고려해서 우리가 결론 내릴수 있는건 이 데이터셋에 선형 모델이 적합하지 않다는 거구요.
검증 데이터셋 방법은 간단하며 구현하기도 쉽습니다. 하지만 다음의 두가지 결점을 가지고 있어요.
1. 그림 5.2에 보시다시피, 검증 에러율은 훈련 데이터셋과 검증 데이터셋이 임의로 만들어지는거에 크게 영향을 받아 변동이 심합니다.
2. 검증 데이터셋방법은 전체 관측치의 일부를 사용하다보니, 검증 데이터셋은 훈련 데이터셋보다 적어요. 그리고 적은 데이터로 훈련하면 성능이 떨어지다보니, 검증 데이터셋 에러율은 전체 데이터셋으로 학습한 모델의 테스트 에러율을 과소평가/ 전체 데이터셋을 학습한 모델의 테스트 에러율보다 떨어지는 경향이 있어요.
그래서 다음 장에서는 검증 데이터셋 방법이 가지고 있는 두가지 문제를 개선하고자 나온 방법인 교차 검증 cross validation에 대해서 알아봅시다.
이번에는 입력 변수가 여러개인 경우 이진 분류하는 문제를 생각해봅시다. 3장에서 본 다중 선형회귀에서 확장시켰던것처럼 식 (4.4)를 아래와 같이 일반화 시켜 나타낼수 있을 거에요.
여기서 X = ($X_{1}$, . . .,$X_{p}$)로 p는 입력 변수의 개수가 되겠죠. 그러면 이 식 4.6은 아래와 같이 정리 할수 있을거에요.
4.3.2장에서 본것 처럼 최대 가능도법을 사용해서 계수 $\beta_{0}$, . . .,$\beta_{p}$들을 추정하면 되겠습니다.
표 4.3 채무 불이행 데이터셋에서 카드 대금, 수입, 학셩 여부로 채무 불이행 확률을 예측한 로지스틱 회귀 모델의 계수 추정치들. 학생 상태는 가변수로 인코딩 되었음.
표 4.3은 카드 대금 balance와 수입 income, 학생 여부를 이용해서 채무 불이행 여부, 디폴트 여부의 확률을 예측하는 로지스틱 회귀 모델의 계수를 추정한 결과를 보여주고 있어요. 결과를 보면 카드 대금과 학생인 경우의 가변수에 대한 p value가 매우 낮으므로 이 변수들이 디폴트 확률과 연관되어 있는걸 알 수 있습니다. 하지만 학생인 경우의 계수 추정치가 - 0.6468로 음수이므로 학생이 아닌 경우보다 디폴트가 될 확률이 덜하다는 얘기가 됩니다.
이건 표 4.2에서 가변수가 양수가 나온것과는 좀 다른데, 어떻게 표 4.2에서 디폴트 확률이 증가하도록 하던게 표 4.3에서는 디폴트 확률을 줄이도록 하게 만들었을까요?
그림 4.3 혼합된 디폴트 데이터. 좌측 : 주황색은 학생인 경우 디폴트가 될 확률, 파란색은 학생이 아닌 경우 디폴트가 될 확률. 직선은 카드 대금이 주어질때 디폴트 확률에 대한 함수이며, 평행 점선은 전체에서 디폴트 비율을 나타냅니다. 우측 : 주황색은 학생인 경우 카드 대금에 대한 박스 플롯, 파란색은 학생이 아닌경우 카드 대금에대한 박스 플롯입니다.
그림 4.3의 왼쪽 판낼은 이 역설적인 상황을 그래프로 보여주고 있는데, 오랜지 색과 파란색 직선은 카드 대금이 주어질때 각각 학생과 학생이 아닌 경우의 평균적인 디폴트 비율을 보여주고 있어요.
이 다중 로지스틱 회귀 모델에서 학생에 대한 계수가 음수라는 것은 (잔금과 수입이 변하지 않았을때) 학생이 아닌 경우보다 디폴트가 될 가능성이 낮다는걸 의미 합니다.
하지만 이 플롯의 바닥 근처에 있는 평행 점선은 카드 대금과 수입 전체에서 학생과 학생이 아닌 경우의 평균적인 디폴트 비율을 보여주고 있는데, 직선과는 다르게 전체 학생의 디폴트 비율이 비학생의 디폴트 비율보다 높죠.
그래서 표 4.2의 단순 로지스틱 회귀 모델에서 학생에 대한 계수가 양수값이 되요.
그림 4.3의 오른쪽 판낼은 이 불일치한 상황에 대해 참고가 되는데, 여기서 학생과 카드 대금이 상관관계를 가지는걸 볼 수 있어요. 학생은 빚이 전반적으로 많아 디폴트가 될 확률이 더 높을거에요. 다시 말하면 학생들은 카드 대금이 클 가능성이 많아 그림 4.3의 높은 디폴트 비율이 나오게 되요.
그래서 카드 대금이 같을때 학생 개인으로 보면 비학생보다 디폴트가 될 확률이 낮지만, 학생 전체적으로 카드 대금이 많다보니 비학생보다 디폴트 비율이 높게 나오게되요.
이는 신용카드 회사에서 신용을 제공할지 여부를 판단하는데 중요한 일이라고 할수 있을 겁니다. 한 학생의 신용 카드 대금에 대한 정보가 없다면 비학생보다 학생이 더 위험할 거에요.(학생은 기본적으로 빚이 많으니) 하지만 학생과 비학생의 가드 대금이 같은 경우라면 학생이 덜 위험할 겁니다. (빚이 적은 학생이다.)
정리
- 학생 여부에 따른 디폴트 여부만 본다면 (학생이 기본적으로 빚이 많으므로) 학생이 디폴트가 될 학률이 크다.
- 학생 여부와 카드 대금을 고려 한다면 비학생보다 디폴트가 될 확률이 낮다.
이 간단한 예제를 통해서 다른 입력 변수들 끼리 연관 되어 있을때 입력 변수를 하나만 써서 회귀 모델을 사용하는 경우 생기는 위험들을 알아볼 수 있었습니다. 선형 회귀의 경우 하나의 입력 변수 만으로 얻은 결과는 (특히 입력 변수들 끼리 상관관계가 있을때) 여러개의 입력 변수를 사용한 경우와 상당히 달랐었죠. 그림 4.3에서 보았던 이런 현상을 confounding라고 하며 여기서는 혼재라고 적겟습니다.
표 4.3의 회귀 계계수 추정치를 식 (4.7)에 넣어 예측을 할수 있게 되었습니다. 만약 카드 대금이 $1,500이고, 수입이 $40,000인 학생의 경우 디폴트가 될 확률은 아래와 같을 거에요.
하지만 같은 카드 대금과 수입을 가지고 있는 비학생의 경우 디폴트가 될 확률을 추정하면 아래와 같이 구할수가 있겠습니다.
4.3.5 클래스가 2개 이상일떄 로지스틱 회귀 Logistic Regression for > 2 response classes
우리가 2개 이상의 경우를 분류해야하는 상황도 있을 겁니다. 예를들어 4.2장에서 봤던 응급실에서 질병 medical condition에 대해 3 카테고리가 있었죠. 뇌졸증 stroke, 약물 과다 복용 drug overdose, 간질 발작 epileptic seizure. 이 경우 Pr(Y = stroke | X), Pr(Y = drug overdose| X) 이 두 모델을 만들수 있을거에요 Pr(Y = epileptice seziure | X) = 1 -Pr(Y = stroke | X) - Pr(Y = drug overdose| X) 이므로.
클래스가 2개인 (Yes, No) 로지스틱 회귀 모델은 이전 장에서 다루었으니, 이걸 다중 클래스의 경우로 확장시키면 되겠습니다. 하지만 이 방법들은 잘 사용되지 않아요. 왜냐면 다음 장에서 이야기 할 판별 분석 discriminant analysis가 다중 클래스 분류에 널리 사용되고 있거든요. 그래서 로지스틱 회귀를 이용한 다중 클래스 분류에 대해서 자세히 다루지는 않겠습니다.
4.4. 선형 판별 분석 Linear Discriminant Analysis
로지스틱 회귀는 로지스틱 함수로 Pr(Y = k | X = x)를 직접적으로 설계하는 방법이었습니다. 통계적인 용어를 사용하자면 입력 변수(들)이 주어질때 반응 변수 Y에 대한 조건부 분포를 설계 했다고 할수 있어요.
(조건부 확률 분포 모델을 만들어 x가 주어질때 k=1/default인 경우에 대한 확률들을 구하였었음.)
이번에는 이를 대신하는 방법으로 확률들을 약간 간접적으로 추정하는 방법을 다뤄봅시다. 우리는 반응 변수 Y가 주어질떄 입력 X의 분포를 모델링할건데 이걸 베이즈 정리로 뒤집어 Pr(Y = k | X = x)를 추정할거에요. 여기서 확률 분포가 정규 분포라고 가정을 하면 로지스틱 회귀와 비슷한 모델이 될겁니다.
왜 로지스틱 회귀 말고 이런 방법이 필요할까요? 여기에는 다음과 같은 이유들이 있습니다.
- 클래스들이 잘 나누어져있을때, 로지스틱 회귀 모델의 파라미터 추정치는 매우 불안정해요. 선형 판별 분석은 그런 문제가 생기지가 않습니다.
- n이 작고, 각 클래스에 대한 X의 분포가 정규분포라면 선형 판별 분석이 로지스틱 회귀 모델보다 더 안정적이에요.
- 4.3.5장에서 언급했지만 클래스가 2개 이상인 경우 선형 판별 분석이 널리 사용되고 있습니다.
4.4.1 베이즈 정리를 분류에 사용해자 Using Bayes Theorem for Classification
한번 K >=2일때, K개의 클래스 중 하나로 관측치를 분류하고 싶다고 가정해봅시다. 다시 말하자면 질적 반응변수/카테고리 반응 변수 Y는 K개의 구분되고, 순서를 갖지 않는 값을 가지게 되요. $\pi_{k}$를 임의의 관측치가 k번째 클래스에 속할 확률을 사전 확률 prior probability이라고 합시다. 이 확률은 주어진 관측치가 k번쨰 카테고리에 속할 확률을 말해요.
$f_{k}$(x) $\equiv$ Pr(X = x | Y = k)는 관측치가 k번째 클래스에 속할때 X의 밀도 함수라고 합시다. 다시 말하면 $f_{k}$(x)는 k에 속하는 관측치가 X $\approx$ x일 확률이 크다면 확률 밀도 $f_{k}$(x)가 상대적으로 클것이고, k에 속하는 관측치가 X $\approx$ x일 가능성이 낮다면 적을겁니다. 이를 베이즈 정리로 나타내면 아래와 같아요.
이전에 우리가 정의한대로 $p_{k}$(X) = Pr(Y= k | X)로 사용하겠습니다. 이 방식은 4.3.1장에서 $p_{k}$(X)를 직접적으로 계산한것 대신에 추정한 사전확률 $\pi_{k}$와 밀도 함수 $f_{k}$(X)를 식 (4.10)에 대입해서 계산할수 있어요. 일반적으로 사전 확률 $\pi_{k}$는 추정하기 쉬운데, 모집단으로부터 Y의 샘플들을 가지고 있으면 k번째 클래스의 비율로 계산하면 되겠습니다. 하지만 밀도 함수 $f_{k}$(X)를 추정하는건 어떤 단순한 밀도 함수의 형태를 가정하지 않는다면 어렵습니다.
$p_{k}$(x)는 관측치 X = x가 주어질때 k번째 클래스에 속할 확률로 사전 확률 posterior probability이라고 하겠습니다. 이건 관측치의 입력 값들이 주어질때 해당 관측치가 k 클래스에 속하는 확률을 나타내요.
우린 2장에서 배이즈 분류기가 $p_{k}$(X)가 가장 큰 클래스로 관측치를 분류하는 모델로, 모든 분류기들 중에서 에러율이 가장 낮다는걸 봤었습니다. 그러므로 $f_{k}$(X)를 추정할 방법을 찾을수 있으면 우리는 베이즈 분류기에 가까운 분류기를 만들수가 있어요. 이게 이번 장에서 다룰 주제가 되겠습니다.
4.4.2 p = 1인 경우 선형 판별 분석 Linear Discriminant Analysis for p = 1
이번에는 p = 1인 경우 즉 입력 변수가 하나인 경우를 가정하여 살펴보겠습니다. 우리는 $p_{k}(x)를 예측하기 위해서 $식 (4. 10)에다가 대입시킬 $f_{k}$(x)를 추정해서 구하고자 합니다. 그러면 $p_{k}$(x)를 가장 크게 만드는 클래스 k로 분류를 하면 되요. $f_{k}$(x)를 추정하기 위해서 함수적 형태를 가정해야 합니다.
한번 $f_{k}$(x)를 정규, 가우시안 분포라고 가정할게요. 일 차원인 경우 정규 분포는 다음과 같은 형태로 $\mu_{k}$, $\sigma^{2}_{k}$는 k번쨰 클래스에 대한 평균과 분산을 나타낼 거에요. $\sigma^{2}_{1}$ = . . . = $\sigma^{2}_{K}$로 가정하면 K개의 클래스 전체가 분산을 공유한다는 뜻이며, $\sigma^{2}$로 단순화 해서 표기할께요. 이렇게 정리하여 식 (4. 11)을 식 (4.10)에다가 대입시켜 아래와 같이 정리 할 수 있겠습니다.
식 (4.12)에서 $\pi_{k}$는 관측치가 k번째 클래스에 속할 사전확률이지 $\pi$ $\approx$ 3.14159가 아닙니다. 베이즈 분류기는 관측치 X = x가 있을때 (4.12)를 최대로 하는 클래스로 분류해줍니다. (4.12)에다가 로그를 취하고 항을 정리하면 클래스 k에 속하는 확률은 아래와 같이 정리할 수 있어요.
K = 2이고 $\pi_{1}$ = $\pi_{2}$인 예시를 들어봅시다. 그러면 베이즈 분류기는 관측치를 2x($\mu_{1}$ - $\mu_{2}$) > $\mu^{2}_{1} $ - $\mu^{2}_{2}$인 경우 클래스 1로 분류할거에요. 그렇지 않으면 클래스 2로 분류 하구요. 이렇게 되면 베이즈 결정 경계 Bayes Decision boundary는 아래의 지점이 됩니다.
이 예시는 그림 4.4의 왼쪽 판낼에서 볼 수 있어요. K = 2이고, 우리는 k에 대한 확률 밀도 함수 $f_{1}$(x)와 $f_{2}$(x)가 정규 분포를 따르고, 두 정규분포를 다르는 확률 밀도 함수가 분산이 동일하다고 가정해서 위와 같은 형태가 나오게 되요. 그리고 이 두 밀도 함수의 평균과 분산 파라미터는 $\mu_{1}$ = -1.25, $\mu_{2}$ = 1.25, $\sigma^{2}_{1}$ = =$\sigma^{2}_{2}$ = 1이 됩니다.
그림 4.4 왼쪽 : 두 개의 1차원 정규 밀도 함수. 점선은 베이즈 결정 경계를 보여주고 있습니다. 우측은 두 클래스에 속하는 관측치 20개의 히스토그램을 보여주고 있어요. 베이즈 결정 경계는 수직 점선으로 나타나고 있고, 직선은 훈련 데이터셋으로 추정한 LDA 선형 판별 경계를 보여주고 있습니다.
이 두 밀도 함수에는 겹치는 부분이 존재하여 관측치가 어느 클래스에 속하는지 불확실성을 가지고 있어요. 우리가 관측치들이 각 클래스에 속할 확률들이 같다고 가정하면 - $\pi_{1}$ = $\pi_{2}$ = 0.5처럼, 베이즈 분류기는 x < 0이면 관측치를 클래스 1, 아니면 클래스 2로 분류할 수 있을거에요.
지금 경우에는 우리가 X가 각 클래스에 대한 가우시안 분포로부터 샘플링 된걸 알고있으며, 모분산에 대한 파라미터들을 알고있다보니 베이즈 분류기를 계산할 수 있었습니다.
하지만 현실에서는 샘플 X가 각 클래스에 대한 가우시안 분포로부터 샘플되었다고 가정을 하더라도, $\mu_{1}$, . . ., $\mu_{K}$, $\pi_{1}$, .. ., $\pi_{k}$, $\sigma^{2}$같은 파라미터들을 직접 추정해야해요 우리는 모 분산의 성질을 알 수 없으니까요.
선형 판별 분석 LDA은 $\pi_{k}$, $\mu{k}$, $\sigma^{2}$ 추정치들을 식 (4.13)에 대입해서 베이즈 분류기를 근사시키는 방법이에요. 이 추정치들은 주로 아래의 식으로 계산하며 n은 훈련 관측치의 총 갯수이고 $n_{k}$는 k번쨰 클래스에 속하는 관측치의 계수를 나타내요.
$\mu_{k}$ 추정량은 쉽게 k번쨰 클래스에 속하는 모든 관측치들을 평균을 해서 구할수가 있고, $\sigma^{2}$는 각 K클래스에 대한 분산들의 가중치를 고려한 평균으로 볼수 있겠습니다. 그리고 클래스에 대한 사전 지식이 있는 경우 $\pi_{1}$, . . ., $\pi_{K}$를 직접적으로 사용할 수 있어요. 이런 추가적인 정보가 없다면 LDA는 $\pi_{k}$를 k번쨰 클래스에 속하는 관측치의 비율 그러니까 아래와 같이 추정해서 쓸수도 있겠습니다.
LDA 분류기는 식 (4.15), (4.16)을 (4.13)에 대입해서, X = x가 주어질떄 확률이 최대가 되는 클래스로 분류를 해줘요.
이 분류기의 이름에서 선형이란 단어는 식 (4.17)의 판별 함수 $\widehat{\delta}_{k}$가 x에 대한 선형 함수라는 사실에서 따왔습니다.(x에 대한 복잡한 함수의 반대되는 개념)
그림 4.4의 오른쪽 판낼은 각 클래스로부터 얻은 20개의 샘플 데이터의 히스토그램을 보여주고 있어요. LDA를 구현하기 위해서 식 (4.15)와 (4.16)으로 $\pi_{k}$, $\mu_{k}$, $\sigma^{2}$를 추정하고, 그러고나면 검은 직선으로 나오는 결정 경계를 계산할 수가 있어요. 이 결정 경계는 관측치가 가장 큰 확률로 속하는 클래스에 잘 분류되도록 하는 하는 지점이에요(4.17).
이 직선의 좌측에 있는 모든 점들은 녹색 클래스이며 우측에 있는 모든 점들은 보라색 클래스라고 할께요. $n_{1}$ = $n_{2}$ = 20이고, $\widehat{\pi}_{1}$ = $\widehat{\pi}_{2}$일 때, 결정 경계는 두 클래스에 대한 샘플들의 중간 지점인 ($\widehat{\mu}_{1}$, $\widehat{\mu}_{2}$)/2 가 될거에요.
이 그림에서 선형 판별 분석 결정 경계는 최적의 베이즈 결정 경계보다 약간만 왼쪽에 가 있는데 최적의 결과인 베이즈 결정 경계가 ($\mu_{1}$ + $\mu_{2}$)/2인것과는 큰 차이가 나지 않죠. 그러면 얼마나 선형 판별 분석이 잘 수행되었을까요? 이건 시뮬레이션된 데이터이다보니 테스트 관측치를 많이 만들수가 있는데, 그 결과 베이즈 에러율과 LDA 에러율은 각각 10.6%, 11.1%가 되었습니다. 즉 LDA분류기의 에러율은 가장 작은 에러율(베이즈 분류기의 에러율)보다 0.5%밖에 크지 않다는 거에요. 그래서 LDA가 주어진 데이터에 잘 동작한다고 볼 수 있겠습니다.
다시 반복하자면 LDA 분류기는 각 클래스에 속하는 관측치들이 특정 평균 벡터와 공통의 분산 $\sigma^{2}$를 갖는 정규분포로 부터 샘플링되었다고 가정하고, 이 파라미터들을 추정하여 베이즈 분류기에 넣어 주어진 입력이 어떤 클래스에 속하는지 판단하는 방법이라 할 수 있어요. 4.4.4장에서는 k번쨰 클래스의 관측치가 클래스별 분산 $\sigma^{2}_{k}$를 가지는 것을 허용 시킴으로서 덜 견고한 가정을 사용하는 경우를 고민해봅시다.
4.4.3 p > 1인 경우 선형 판별 분석 Linear Discriminant Analysis for p > 1
이번에는 입력 변수가 여러개인 경우로 선형 판별 분석 분류기를 확장시켜봅시다 X = ($X_{1}$, $X_{2}$. . . ., $X_{p}$) 가 다변량 가우시안 분포(다변량 정규 분포)를 따른다고 가정을 하면, 평균 벡터와 공분산 행렬을 가지게 되겠죠. 한번 이 분포에 대해서 간단히 살펴봅시다.
그림 4.5 p =2 인 다변량 가우시안 밀도 함수를 모여주고 있습니다. 좌측 : 두 입력 변수가 상관관계를 갖지 않은 경우. 우측 : 두 변수가 0.7의 상관관계를 갖는 경우.
다변량 정규 분포 multivariate gaussian distribution은 각각의 입력 변수들이 일차원 정규 분포를 따른다고 가정하고 있습니다. (4.11)처럼 각 입력벼수 쌍들끼리는 상관관계를 가지고 있구요. 그림 4.5에서 p = 2인 경우 다변량 가우시안 분포의 예시를 볼 수 있는데, 한 지점의 높이는 $x_{1}$와 $x_{2}$가 해당 지점에 있을 확률을 나타냅니다. 두 판낼다 $X_{1}$ 축으로만 보던가 $X_{2}$으로만 보던간에 일차원 정규 분포 형태로 볼 수 있어요.
그림 4.5의 왼쪽 판낼은 Var($X_{1}$) = Var($X_{2}$)인 경우로 Cor($X_{1}$, $X_{2}$) = 0이 됩니다. 이 표면은 종 형태 bell shape 특성을 가지는게 되요. 하지만 두 변수간에 상관관계가 존재한다거나 분산이 같지 않으면 종 형태가 왜곡될수 있는데, 그림 4.5의 오른쪽 판낼에서 볼수 있겠습니다. 이 상황에서 종의 바닥이 원형보다는 타원 형태로 되어있어요.
p 차원 랜덤 변수 X가 다변량 가우시안 분포를 따르는 경우 이를 X ~ N($\mu$, $\Sigma$)로 적을수 있고, 여기서 E(X) = $\mu$는 X의 평균이고, Cov(X) = $\Sigma$는 확률 변수 X에 대한 p x p 개의 공분산 행렬이 됩니다. 이걸 정리하면 다변량 가우시안 밀도 함수는 아래와 같이 정의 할 수 있어요.
p > 1인 경우에 LDA 분류기는 $\mu_{k}$를 클래스별 평균 백터, $\Sigma$는 모든 클래스에 대한 공분산 행렬이라고고 할때 k번째 클래스에대한 관측치는 N($\mu_{k}$, $\Sigma$)인 다변량 가우시안 분포를 따른다고 가정을 하고 있어요. k번째 클래스에 대한 밀도 함수 $f_{k}$(X = x)를 (4.10)에 대입하여 대수적으로 정리를 하면 베이즈 분류기는 관측치 X = x를 아래 식의 결과가 가장 크게 되는 클래스에 속하게 될겁니다. 이 식은 (4.13)의 벡터/행렬 버전이라고 할 수 있어요.
그림 4.6 클래스가 3개인 예시. 각 클래스에 속하는 관측치들은 p = 2인 다변량 가우시안 분포를 따르고 있다. 좌측 : 타원들이 95%의 확률로 세 클래스에 속하는것들을 포함시키고 있다. 점선들은 베이즈 분류 경계를 나타낸다. 우측 : 각 클래스당 20개의 관측치가 만들어져서 LDA 결정 경계가 직선의 형태로 나오고 있다. 여기서도 베이즈 결정 경계가 점선으로 표현되고 있다.
그림 4.6의 왼쪽 예시를 보면 클래스가 3개인 똑같이 나눠진 그림을 보여주고 있는데, 여기서 세 타원은 세 클래스 각각에 95%확률로 속할 범위를 보여주고 있습니다. 점선은 베이즈 결정 경계이구요. 여기서 세 직선은 베이즈 결정 경계로 클래스 1과 클래스 2를 분할하는 직선 하나, 클래스 1과 클래스 3을 분할하는 직선 하나, 클래스 2와 클래스 3을 분할하는 직선 하나로 세 베이즈 결정 경계들이 입력 공간을 3영역으로 분할시켜주고, 관측치가 어느 영역에 속하는지를 보고 관측치를 분류해요.
하지만 우리는 실제로 알수 없는 파라미터들인 $\mu_{1}$, . . ., $\mu_{K}$와 $\pi_{1}$, . . ., $\pi_{K}$, $\Sigma$를 추정해내야 합니다. 이 추정치들은 (4.15)에서 일차원에서 했던것처럼 하면 되요. 그래고 새로운 관측치 X = x가 주어지면 이거를 구한 추정치들을 (4.19)에다가 넣고, $\widehat{\delta}_{k}$이 가장 커지는 클래스에다가 분류 하면 되겠습니다.
여기서 (4.19)의 $\delta_{k}$(x)가 x에 대한 선형 함수의 형태를 가지고 있다 보니 LDA 결정 규칙 decision rule은 x가 각 요소들과 선형 결합에만 의존/영향을 받아 정해지게 되요. 이런 이유로 LDA에서 선형이라는 단어가 사용되고 있습니다.
그림 4.6의 오른쪽 판낼은 세 클래스에 속하는 각각 20개의 관측치들을 보여주고 있어요. 그리고 LDA결정 경계는 직선과 같은 형태로 다오고 있는데, LDA 결정 경계들이 꽤 베이즈 결정 경계에 가까운걸 볼수 있죠. 베이즈와 LDA 분류기의테스트 에러율도 0.0746과 0.0770으로 비슷한걸 알수 있으며 LDA가 이 데이터들을 잘 분류한다고 볼 수 있겠습니다.
그러면 LDA를 채무 불이행 데이터셋에 적용시켜 본다고 할꼐요. LDA모델은 10,000개의 훈련 샘플들을 학습을 했을때 훈련 에러율이 2.75%정도가 나왔는데, 이정도면 꽤 낮다고 볼수 있지만 두가지 주의사항이 있습니다.
- 가장 먼저, 훈련 에러율인 일반적으로 테스트 에러율보다 낮습니다. 다시 말하면 이 분류기는 새로운 데이터를 예측할때 성능이 더 떨어지게 될거라는 말인데 이 이유는 훈련 데이터셋만 보고 파라미터들을 조정했기 때문이에요. 파라미터의 개수 p와 샘플 개수 n의 비율이 커질수록 오버피팅될 가능성이 더 높아 집니다. 하지만 이 경우에는 p = 2이고, n = 10, 000이다보니 그럴 문제는 없을거에요.
- 두번째로 훈련데이터의 3.3%만 채무 불이행이 되었다보니, 사람의 카드 대금이나 학생 여부를 고려하지 않더라도 디폴트가 되지않았다고 하는 널분류기또한 훈련 에러율이 3.3%가 나올거에요. 다시 말하면 널 분류기가 LDA 훈련 에러율 2.75보다 훈련 에러율 3.3으로 약간만 높게 나옵니다.
이후에는 혼동 행렬과 ROC커브 등에 나오나 시간 관계 상 생략
4.4.4 이차 판별 분석 Quadratic Discriminant Analysis
지금까지 각 관측치들이 다변량 가우시안 분포를 따른다고 가정하는 LDA에 대해서 살펴봤었습니다. 이차 판별 분석 Quadratic discriminant analysis (QDA)는 이를 대신할수 잇는 방법인데, LDA와 마찬카지로 QDA 분류기도 각 클래스에 속하는 관측치들이 가우시안 분포를 따른다고 가정을하고, 파라미터 추정치를 베이즈 정리에 대입하여 예측을 하고 있어요.
하지만 LDA와 다르게 QDA는 각 클래스가 고유의 공분산 행렬을 가지고 있다고 가정을 해서 각 클래스에대한 관측치는 X ~ N($\mu_{k}$, $\Sigma_{k}$)를 따른다고 봅니다. 여기서 $\Sigma_{k}$는 k번쨰 클래스의 공분산 행렬을 나타내요. 이 가정에 따라서 베이즈 분류기는 X = x가 아래의 $\delta_{k}$(x)를 가장 크게 하는 클래스로 분류하게 되요.
그래서 이차 판별 분석 분류기는 $\Sigma_{k}$, $\mu_{k}$, $\pi_{k}$를 추정해서 (4.23)에 대입하여 분류기를 만들고, 관측치 X =x가 가장 크게 하는 클래스로 분류를 시켜요. (4.19)와 다르게 (4.23)은 x에 대한 이차 함수의 형태로 나타나다보니 QDA가 이차 판별 분석이라는 이름을 가지게 되었습니다.
K개의 클래스가 공통 공분산을 가진다(선형 판별 분석) 혹은 가지지 않는다(이차 판별 분석)이란 가정이 왜 중요한 건가요? 다시 말하면 어쩔때 LDA가 좋고, QDA가 좋은걸가요? 이에 대한 대답은 편향 분산 길항 관계에 달려있습니다. p 개의 입력 변수들이 있을때 공분산 행렬을 추정하기 위해서는 p(p+1)/2개의 파라미터들이 필요로해요.
QDA는 각 클래스에 대해 개별적인 공분산 행렬을 추정하다보니 총 K p(p + 1) / 2개의 파라미터들이 필요하죠. 50개의 입력변수가 주어진 경우 1,275개의 아주 많은 파라미터들이 사용될거에요. 그래서 K 클래스가 같은 공분산 행렬을 공유한다고 가정 함으로서, LDA 모델은 x에 대해 선형적인 형태가 되어 추정하는데 Kp개의 선형 계수들만 사용하면 됩니다.
결과적으로 LDA는 QDA보다 덜 유연한 분류기이고, 적은 변동을 다룰수 있지만 예측 성능(여기서 말하는건 정확도보다는 속도를 말하는것 같음)를 개선할수 있지만 이건 길항 관계/상쇄 관계가 있어요. K 클래스가 공통 공분산을 가진다는 LDA의 가정이 올바르지 않은 경우에는 LDA가 편향이 심하게 나와 성능이 떨어지겠죠.
다시말하면 LDA는 훈련 관측치가 적고, 다뤄야 할 분산들을 줄이는게 중요한 경우에 LDA가 QDA보다 더 나은 선택이라고 할수 있어요. 반대로 훈련 데이터셋이 아주 크고, 분류기의 변량이 중요한 문제가 아니거나 K 클래스의 공통 공분산을 사용해서는 안되는 경우 QDA를 사용하는게 좋습니다.
그림 4.9 좌측 : 두 클래스의 분산이 동일한 베이즈(보라색 점선), LDA(검은 점선), QDA(녹색 직선) 결정 경계를 보여주고 있습니다. 그늘진 공간은 QDA 결정 규칙을 보여주고 있어요. 베이즈 선형이다보니 QDA보다 LDA가 베이즈 분류기를 더 잘 근사화 시키고 있어요. 우측 : 두 클래스의공분산이 동일하지 않다고 할때의 경우로 베이즈 결정경계가 비선형이다보니 LDA보다 QDA가 더 잘 근사시키고 있어요.
그림 4.9는 두가지 시나리오에서 LDA와 QDA의 성능을 보여주고 있습니다. 좌측 그림은 두 가우시안 클래스가 $X_{1}$, $X_{2}$ 사이에 0.7의 공통 상관관계를 가지고 있는 경우를 보여주고 있는데, 여기서는 베이즈 결정 경계가 선형이다보니 LDA 결정 경계가 더 잘 근사시키고 있어요. 하지만 QDA 결정 경계는
반대로 우측 그림은 오랜지색 클래스는 변수간의 상관 관계가 0.7이고, 파란색 클래스는 -0.7의 상관 관계를 갖는 경우를 보여주고 있는데, 여기선 베이즈 결정 경계가 이차적이다보니 QDA가 LDA보다 더 정확하게 이 경계를 근사시키고 있죠.
지난 3장에서는 선형 회귀 모델에 대해서 이야기 하였습니다. 회귀 모델에서 반응 변수 Y는 양적 변수였었죠. 하지만 반응 변수가 질적 변수인 경우도 많이 있어요. 예를들면 눈의 색깔도 질적 변수로 파란색, 갈색, 녹색같은게 있겠죠. 종종 이런 질적 변수 qualitative variaables를 카테고리 categorical이라고 부르기도 해요. 그리서 이런 용어들을 자주 사용할거고 이번 장에서는 질적 반응, 카테고리를 예측하는 방법들 즉 분류 기법에 대해서 배워봅시다.
주어진 데이터, 관측된 데이터, 입력 데이터 x를 가지고 질적 반응 변수, 카테고리를 예측하는일을 분류 라고 부릅니다. 왜냐면 주어진 데이터를 가지고 이게 어느 카테고리 혹은 클래스에 속하는지를 다루거든요. 하지만 분류를 하기 위해서 우선은 어디에 속하는지 판단하기 위해서 각 카테고리별 확률을 예측하여 봅시다. 그러면 이건 회귀적인 방법을 사용한다고 볼수 있겠죠.
질적 반응을 예측하는데 사용가능한 아주 많은 분류 기법들, 분류기들이 있는데 우선 2.1.5, 2.2.3장에서 몇가지를 살펴보려고 합니다. 이번 장에서 가장 널리 사용되는 분류기인 로지스틱 회귀 logistic regression과 선형 판별 분석 linear discriminant anlaysis 그리고 최근접 이웃 K-nearest neighbor에 대해서 이야기해봅시다. 그리고 차후 챕터에서 일반화 가산 모델 generalized additive models(7장), 트리 모델, 랜덤 포레스트, 부스팅(8장), 서포트벡터 머신(9장)과 같이 더 복잡한 방법들을 이야기해봐요.
4.1 분류 개요 An Overview of Classification
분류 문제는 어떻게 보면 회귀 문제보다 더 많이 존재한다고 할수 있을거 같아요. 예를들자면
1. 어떤 사람이 병증 때문에 응급실에 왔습니다. 3가지 의료 상태 중 하나를 줄 수 있겠는데, 예를 들면 (정상, 긴급, 사망) 같은 경우가 있다고 해요. 각자 사람의 증상/상황을 보고 어떻게 분류하여야 할까요?
2. 온라인 은행 서비스같은 경우 사용자의 주소, 이전 거래 기록, 그 이외의 정보로 현재 거래가 사기(위법)인지 아닌지 판단할수 있어야 해요.
3. 어떤 질병이 있는 혹은 없는 사람들의 DNA 시퀀스 데이터가 있다고 합시다. 그러면 생명공학자는 이 질병을 야기시키는/원인이 되는 DNA변종이 있는지 다시 말하면 이 사람이 병에 걸릴 위험이 있는지 없는지 판단할 수 있어야 해요.
회귀 상황과 마찬가지로 분류 상황에서도 훈련 데이터/관측치 observations ($x_{1}$, $y_{1}$), . . .($x_{n}$, $y_{n}$)을 가지고 있고, 이 데이터를 사용해서 분류기를 만들수가 있어요. 그리고 우리가 만든 분류기가 훈련 데이터에만 잘 동작하는게 아니라 (훈련 과정에 사용하지 않은)테스트 관측치/테스트 데이터에서도 잘 동작되야하겠죠.
그림 4.1 채무 불이행 Default 데이터셋. 왼쪽 : 연간 수입과 매달 신용카드 대금 balance. 신용카드 채무 불이행 한 사람의 경우 주황색이며, 그렇지 않은 사람들은 파란색. 중앙 : 디폴트/채무불이행여부 여부에 따른 매달 카드 대금의 박스플롯, 우측 : 디폴트 여부에 따른 수입의 박스플롯
이번 장에서는 시뮬레이션으로 만든 채무 불이행/디폴트에 관한 데이터셋을 사용하여 분류의 개념에 대해서 볼것이고, 사람들의 연간 수입과 매달 신용카드 대금 balance 등을 보고 신용카드 지출 채무 불이행 여부를 예측해봅시다. 이 데이터는 그림 4.1에서 볼수 있어요. 이 그림는 1만명의 연간 수입 income과 매달 신용카드 대금 일부를 그래프로 띄웠습니다.
그림 4.1의 왼쪽 판낼에서 채무 불이행한 사람들은 주황색, 그렇지 않은 사람은 파랑색으로 나타내고 있으며 (전반적인 체무 불이행 비율은 3%정도 됩니다.) 카드 대금이 클수록 채무 불이행이 큰것으로 나오고 있습니다. 그림 4.1의 오른쪽 판낼에서는 두 박스 플롯을 보여주고 있습니다. 첫번째 박스 플롯은 채무 불이행 여부에 따른 카드 대금 분포를, 두번째 그림에서는 채무 불이행에 따른 수입의 분포를 보여주고 있습니다.
이번 장에서는 카드 대금 $X_{1}$과 수입 $X_{2}$로 채무 불이행 여부 Y를 예측하는 모델을 만드는 방법을 배워보도록 합시다. Y는 양적 변수가 아니므로 3장에서 본 단순 선형 회귀 모델은 사용할수가 없어요.
그림 4.1에서는 입력 변수 카드 대금 balance과 반응 변수 채무 불이행 defualt이 중요한 관계를 가지고 있는걸 볼수 있겠습니다. 대부분의 현실 세계에서는 입력 변수와 반응 변수 사이에 이렇게 강한 관계를 가지고 있지는 않습니다. 하지만 이번 장에서 분류 과정을 쉽게 이야기하기위해서 입력과 반응 사이의 관계가 과장될 정도로 강한 예시를 사용해서 보겠습니다.
4.2 왜 선형 회귀가 아닐까요? Why Not Linear Regression?
반응 변수가 질적 변수인 경우 선형회귀가 적절하지 않다고 했는데 왜그럴까요? 한번 응급실에 온 환자의 증상을 보고 상태가 어떤지 진단을 해본다고 합시다. 진단 결과 다음 3가지 경우가 있다고 해요. 뇌졸증 stroke, 약물 과다복용 drug overdose, 간질 발작 epileptic seizure. 이 값들을 아래와 같이 반응 변수 Y로 인코딩을 해봅시다.
이렇게 인코딩을 하고, 최소 제곱법을 사용해서 입력 변수의 속성들 $X_{1}$, ..., $X_{p}$로 Y를 예측할 수 있도록 선형 회귀 모델을 학습해 봅시다. 하지만 이 인코딩 방식 처럼 뇌졸증 stroke와 간질 발작 epileptic seizure 사이에 약물 과다 복용 drug overdose를 넣어버리면 출력 값 사이에는 순서가 있는것이 되며, (뇌졸증 - 약물 과다복용) == (약물 과다복용 - 간질 발작) 다시 말하면 뇌졸증과 약물과다복용의 차이와 약물 과다복용과 간질 발작의 차이가 같다고 할수 있겠죠. 하지만 진단 결과들 끼리는 순서가 존재하지도 않고 2- 1 == 3 - 2가되는 관계 같은건 존재하지도 않아요.
세가지 상태 끼리 완전히 다른 관계를 가지고 있다고 본다면 그러니까 순서를 가진게 아닌 카테고리로 본다면 옳은 인코딩 방식이라고 할 수 있을거에요.
그리고 이 인코딩 각각으로 완전히 다른 선형 회귀 모델들을 만들어 테스트 입력이 주어질때 여러개의 예측값(stroke에 대한 예측, drug overdose에 대한 예측, epileptic seizure에 대한 예측)값들이 만들어 지겠죠.
만약 반응 변수 값들이 순한 mild, 중간 moderate, 센 severe처럼 순서를 가지고 있다고 보는게 자연수러운 경우에는 1, 2, 3으로 인코딩시키는게 유용할 거에요. 하지만 경우의 수가 3개 이상인 정적 반응 변수를 자연스럽게 선형 회귀 모델에서 사용가능한 양적 변수로 바꿀 방법이 없어요.
이진 양적 반응 binary qualtative response(반응 변수 값이 2개인 경우)의 경우는 간단한데, 예를들면 환자 상태가 뇌졸증 혹은 약물 과다복용 두가지 경우에 대한 확률만 있다고 할게요. 그러면 이걸 3.3.1장에서본 가변수를 사용해서 반응 변수를 아래와 같이 인코딩할수 있을거에요.
이렇게 되면 이진 반응을 선형 회귀 모델로 학습시키고, $\hat{Y}$ > 0.5이면 약물 과다복용을 아니면 뇌졸증으로 예측할 수 있을거에요. 이진 분류 문제에서는 위 인코딩을 뒤집더라도 선형 회귀 모델은 같은 예측 결과를 나오니 어렵지는 않습니다.
위와 같이 반응 변수가 0/1로 인코딩 된 경우 최소제곱을 이용한 회귀 모델에서 잘 동작하는데, 예를 들면 X$\hat{\beta}$를 Pr(약물 과다복용 | X)을 추정하도록 선형 회귀로 얻은 모델이라고 할수 있을거에요.
그림 4.2 채무 불이행 디폴트 여부 분류 데이터. 좌측 : 선형 회귀 모델로 추정한 디폴트 추정 확률. 추정 확률의 일부는 음수가 된다!. 주황색 구간은 디폴트 여부 (디폴트아님/맞음)를 0/1로 인코딩한 값을 보여주고 있어요. 우측 : 로지스틱 회귀를 사용한 디폴트 예측 확률로 모든 확률들이 0과 1사이에 있습니다.
하지만 선형 회귀를 사용한다면 그림 4.2같이 [0, 1]사이 구간 밖을 나갈수 있어 확률로 다루기는 힘들어요. 하지만 선형 회귀 모델의 예측 결과는 순차적이다 보니 처리되지 않은 확률 추정치 crude probability estimates라고 할수 있겠죠. 아무튼 이진 반응 결과를 예측하기 위해서 선형회귀를 사용하는 분류 방법을 LDA Linear Discriminant analysis라고 하는데 4.4장에서 살펴봅시다.
하지만 가변수 방법은 3개이상인 경우의 수로 확장해서 쓰기가 힘들어요. 이런 이유로 다음 장에서 나오는 방법이 이런 반응변수들을 다루는데 적합합니다.
=> 이 부분이 좀 햇갈리는데 아래와 같이 정리 할 수 있겠다.
경우의 수들을 1, 2, 3과 같이 인코딩 해버리면 결과 끼리 순서가 있는 것으로 만들어 버리는 문제가 있다.
* 라벨이 순서가 있는 경우는 괜찬으나 순서가 없는 경우는 문제가 된다.
가변수를 이용해여 0과 1로 인코딩 하는 경우 경우의 수가 2개일 때만 사용 가능하다.
4.3 로지스틱 회귀 Logistic Regression
디폴트 데이터셋을 생각해보면 디폴트 유무를 두 카테고리 Yes, No로 만들수 있을거에요. 하지만 Y를 직접 구하도록 모델링하기 보다는 로지스틱 회귀에서는 해당 카테고리에 속할 확률을 구하도록 모델링 합니다.
디폴트 데이터셋의 경우에는 로지스틱 회귀 모델은 디폴트될 확률을 구하겠죠. 예를들면 채무 잔액 밸런스 balance가 주어질때 디폴트가 될 확률은 아래와 같이 정리할수 있을거에요.
Pr(default = Yse | balance)의 값은 0, 1 사이가 될것이며 p(balance)로 축약할게요. 이 예측 값으로 디폴트 유무를 판단할수 있겠죠. 예를들어 어떤 사람이 p(balance) > 0.5이라면 이 사람은 default = Yes 라고 볼수 있겠습니다. 이걸 조금 더 수정하자면 회사가 디폴트 위험 여부를 보수적으로 판단한다면 하한 임계치를 0.1로 낮출수도 있을거에요.
4.3.1 로지스틱 모델
어떻게 p(X) = Pr(Y = 1 | X)와 X 사이 관계를 모델링 할 수 있을까요?(편의를 위해서 반응을 0과 1만 쓰겠습니다.) 4.2장에서 선형 회귀 모델을 사용해서 확률을 구할수 있다고 얘길 했었습니다.
우리가 카드 대금 balance로 default=Yes 인지 예측하기 위해서 이 방법을 사용한다면, 그림 4.2의 왼쪽 판낼 같은 모델이 만들어 질거에요. 이 그림을 보시면 이 방법의 문제가 나오는데 카드 대금이 0에 가까우면 디폴트일 확률 값이 -로 내려갑니다.. 카드 대금이 너무 크다면 1을 또 넘어갈거에요. 이런 예측 결과는 말도 안되고, 디폴트가 될 확률을 구해야하므로 카드 대금에 상관없이 0과 1사이에 속해야 합니다. 또, 이 문제는 신용 디폴트 데이터에서만 생기는게 아니구요.
하지만 아무리 직선 모델로 0/1인 반응 변수로 학습을 하던간에 p(X) < 0 또는 p (X) > 1이 되는 경우가 생길수 밖에 없습니다. 이 문제를 피하기 위해서 모든 X가 0과 1사이 값을 가지도록 하는 함수를 사용해서 p(X)를 모델링 해야 합니다. 많은 함수들이 있지만 이번에는 로지스틱 회귀를 다루므로 로지스틱 함수를 사용하겠습니다.
식 (4.2)의 로지스틱 회귀 모델을 학습하기 위해서는 다음장에서 설명할 최대 가능도법 maximum likelihood를 사용해야 합니다. 그림 4.2에서 로지스틱 회귀 모델을 디폴트 데이터에 학습 시킨 결과를 보여주고 있는데, 카드 대금이 적을수록 디폴트 확률이 0에 가까워지지만 0에는 안되고 있죠. 반대로 카드 대금이 클수록 1에 가까워지지 1이 되지는 않습니다.
로지스틱 함수는 항상 이런 S형태의 곡선을 만들며 X의 값에 상관없이 우리가 얻고자하는 확률 예측값을 얻을수가 있어요. 그리고 왼쪽 그림에서 이 로지스틱 회귀 모델이 선형 회귀 모델보다 확률 범위들을 더 잘 적합하고 있는걸 볼수 있어요. 두 모델로 구한 평균 확률은 0.0333으로 같으며, 이 데이터셋의 채무 불이행, 디폴트 한 사람의 비율과도 같아요.
식 (4.2)를 약간 변형하면 위와 같이 바꿀 수 있는데 이걸 오즈 odds라고 부르며 0 ~ 무한대 사이의 값을 가지고 있어요. 이 오즈가 0, 무한대에 가까울 수록 여기서 사용된 확률이 매우 낮거나 높다고 할수 있겠습니다. 예를 들어 평균적으로 5명중 1명이 디폴트가 된다고 하면 p(X) = 1/5 = 0.2가 되고, 0.2/(1-0.2) = 1/4, 오즈는 1/4가 됩니다. 10명 중 9명이 디폴트가 된다면 p(X) = 9/10이고 오즈는 0.9/(1 - 0.9) = 9가 될 거에요. 오즈는 확률이 작으면 작게, 크면 크게 하다보니 확률 대신에 자주 사용하고 있습니다.
위 (4.3) 양변에다가 로그를 취하면 다음의 식을 얻을수 있는데 왼쪽은 로그 오즈 log-odds 혹은 로짓 logit이라고 부르고 있어요. 결국 로지스틱 회귀 모델 (4.2)은 X에 대해 선형함수인 로짓을 가지고 있습니다.
3장에서 선형 회귀 모델을 다룰때 $\beta_{1}$은 X가 한단위 증가할때 Y가 평균적으로 변화하는 양이라고 했었는데, 이 로지스틱 회귀 모델의 경우 X가 한단위 증가할때 (4.4) 로그 오즈를 $\beta_{1}$만큼 바꾸며 (4.3)의 오즈에 $e^{\beta_{1}}$을 곱한것과 같다고 할 수 있겠습니다. 하지만 (4.2)에서 X와 p(X)의 관계는 직선이 아니다 보니 X가 한 단위 증가해도 $\beta_{1}$만큼 p(X)를 바꾸지를 못합니다.
p(X)가 변하는 크기는 현재 X의 값이 어떤지에 영향을 받습니다. 하지만 X가 어떤지간에 $\beta_{1}$이 양수인 경우 X가 증가하면 p(X)도 상승할 것이며, $\beta_{1}$이 음수인경우 X가 증가하더라도 p(X)는 감소할 것입니다. X와 p(X)사이 선형적인 관계가 존재하지 않으며, p(X)의 변화율은 현재 X의 값에 따라 정해지는 내용들은 그림 4.2의 오른쪽 판낼에서 확인할수 있겠습니다.
=> 정리
1. 회귀 모델로 확률을 예측 할 수 있다. (식 4.1)
2. 선형 모델로 확률을 예측하면 음수도 나오고 0과 1 밖을 나가버린다. (그림 4.2)
3. 선형 회귀 모델을 로지스틱 함수에 넣어 0과 1사이 확률 값만 나오게 만들었다 (식 4.2)
4. 선형 회귀 모델은 선형적으로 변하나, 로지스틱 회귀 모델은 현재 값에 따라 변함의 정도가 다르다.
- X가 한단위 증가할 떄 단순 선형 회귀 모델은 $\beta_{1}$만큼 Y가 바뀐다.
- 로지스틱 회귀 모델은 $\beta_{1}$만큼 로짓이 바뀐다. => 실제 p(X)는 X와 다르게 변한다.
4.3.2 회귀 계수 추정하기 Estimating the Regression Coefficients
식 (4.2)의 회귀 계수 $\beta_{0}$, $\beta_{1}$은 모르지만 훈련 데이터셋으로 추정해야 합니다. 3장에서는 아직 모르는 선형 회귀 계수들을 추정하기 위해 최소제곱법을 사용했지만. 식 (4.4)같은 모델도 (비선형) 최소 제곱법을 사용할 수 있기는 하지만 일반적으로는 최대 가능도 법 maximum likelihood이 잘 사용되고 있습니다.
로지스틱 회귀 모델을 학습하기 위해서 최대 가능도법을 사용하는 기본 개념은 (4.2)의 식을 사용해서 모든 사람의 예측 확률 $\hat{p}$($x_{i}$)이 실제 관측치에 가장 가깝도록 하는 계수 추정치들을 구하는 방법입니다. 다시 말하면 실제 디폴트인 사람들에 대한 확률이 1이 많이 나오도록 하는 $\widehat{\beta}_{0}$, $\widehat{\beta}_{1}$를 찾는거에요. 이 개념을 수식화 할수 있으며 이걸 가능도 함수 likelihood function이라고 부릅니다.
$\widehat{\beta}_{0}$, $\widehat{\beta}_{1}$는 이 우도 함수로 최대화 시키고자 할 계수들이구요. 최대 우도법은 이 책 전반에서 다룰 수많은 비선형 적인 방법들을 학습시키는데 널리 사용되고 있습니다. 선형 회귀에서는 최소 제곱법이 사용되었는데, 최대 가능도 법의 특수한 케이스라고 할수 있어요. 최대 가능도법에 대한 수학적으로 자세한 설명은 이책 범위 밖이지만 R 같은 통계적 소프트웨어 패키지에서 사용해서 쉽게 로지스틱 회귀나 다른 모델들을 학습시킬수가 있어요. 그러니 최대 가능도법을 이용한 학습과정의 자세한 사항들에 대해서 걱정할 필요는 없습니다.
표 4.1 디폴트 데이터, 카드 대금 데이터로 디폴트 확률을 예측하는 로지스틱 회귀 모델의 추정 계수. 대금이 한 단위 증가할때 디폴트 로그 오즈가 0.0055씩 증가한다.
표 4.1에서는 카드 대금으로 디폴트=Yes일 확률을 예측하는 로지스틱 회귀 모델 학습 결과로 회귀 계수 추정치와 관련 정보들을 보여주고 있습니다 $\widehat{\beta}_{1}$ = 0.0055는 입력이 증가할때 디폴트 증가 확률과 관련이 되어있으며, 정확하게 얘기하자면 입력이 한 단위 증가할때 디폴트의 로그 오즈가 0.0055 만큼 증가합니다.
표 4.12에서는 로지스팀 회귀 모델의 다른 결과 값들도 보여주고 있으며 3장의 결과물과 비슷합니다. 예를들어 표준 오차 를 계산하여 추정 계수의 정확도를 측정할수 있을 것이고, 표 4.1의 z통계량은 선형 회귀에서 t 통계량과 같은 역활을 하는데 페이지 68의 표 3.1에서 볼수 있습니다. $\beta_{1}$에대한 z통계량은 $\widehat{\beta}_{1}$/ SE($\widehat{\beta}_{1}$과 같으며, z통계량이 클 수록 귀무 가설 $H_{0}$ : $\beta_{1}$ = 0이다. 즉, 채무 확률은 카드 대금에 영향을 받지 않는다 상관없다 라는 귀무가설이 틀렸다고 할 수 있습니다. 카드 대금에 대한 유의확률 p value는 매우 작으므로 귀무 가설 $H_{0}$를 기각 할 수 있고, 다시말하면 카드 대금과 디폴트 확률 사이에는 유의미한 관계가 있다고 볼수있습니다. 표 4.1의 추정 절편은 중요치 않으므로 넘어가겠습니다.
=> 정리
- 로지스틱 회귀 모델의 회귀 계수는 최대 우도법으로 추정한다.
- 최대 우도법을 이용한 계수 추정은 다양한 통계 소프트웨어에서 제공하니 넘어감.
- X가 1씩 증가할때 채무 불이행 확률의 로그 오즈가 0.0055가 증가한다.
4.3.3 예측 하기 Making Predictions
회귀 계수들을 추정하면 카드 대금에 따른 디폴트 확률은 쉽게 계산할 수 있습니다. 표 4.1의 계수 추정치를 이용해서 카드 대금에 대해 X가 $1,000일 때 디폴트 확률을 아래와 같이 구할 수 있는데 아직 확률은 1%보다 낮습니다.
하지만 카드 대금이 $2,000인 경우에는 58.6%로 훨씬 커지게 되요.
3.3.1장에서 본 가변수 방법으로 로지스틱 회귀 모델을 예측할 수도 있겠는데, 예를 들면 학생 여부를 이용하여 디폴트를 판단한다고 해보겠습니다. 이 모델을 학습하기 위해선 학생인경우 1, 학생이 아닌 경우 0으로 두고 가변수를 만들어 모델을 학습하면 되요.
표 4.2 디폴트 데이터셋. 학생 여부에 따른 디폴트 확률을 예측하는 로지스틱 회귀 모델의 추정 계수. 학생 상태가 가변수로 인코딩 되었으며 1의 경우 학생, 0의 경우 학생이 아닌것으로 되어 위 표에서 학생인 경우를 보여주고 있습니다.
그러면 학생인 경우 채무 불이행할 확률에 대한 로지스틱 회귀 모델의 결과는 표 4.2에서 볼수 있겠습니다. 이 경우는 학생인 경우에 대한 계수들로 보여주고 있는데 p value가 통계적으로 유의미한 것을 볼수 있습니다. 이는 학생이 아닌 경우보다 학생일때 디폴트할 확률이 더 크다는걸 알려줘요.
An Introduction to Statistical Learning with Application in R
3.4 마케팅 전략 The Marketing Plan
이번 장 초반에 봤던 마케팅 데이터에 대한 7가지 질문들에 대해 대답들을 간단하게 정리해봅시다.
1. 광고 예산과 판매량 사이에 관계가 존재하나요?
이 질문에 대한 대답으로 (3.20)의 티비, 라디오, 신문의 판매량에 대한 다중 회귀 모델을 훈련시키고, 가설 $H_{0}$ : $\beta_{TV}$ = $\beta_{radio}$ = $\beta_{newspaper}$ = 0을 검정하여 판별할수 있겠습니다. 3.2.2에서 우리는 귀무 가설 null hypothesis를 기각할수 있는지를 판별하는 F 통계량 F statistic을 봤었고, 표 3.6에서 F통계량에 대한 유의확률 p value가 매우 낮다보니 광고와 판매량 사이에 유의미한 관계를 가지고 있음을 검증하였습니다.
* 위 귀무 가설이 기각 된다는 것은 위 계수들이 0이 아니라는 말로, 입력 변수와 반응 변수가 유의미한 관계를 가지고 있다고 볼수 있기 때문.
2. 우리가 구한 모델이 얼마나 정확하였나요?
우리는 3.1.3에서 모델의 정확도에 대한 두가지 척도를 보았습니다. 첫째는 RSE로 모 회귀 직선으로 부터 출력들의 표준 편차를 추정하는 방법이었는데, 광고 데이터에서 RSE는 1,681, 출력의 평균은 14,022로 오차의 비율이 12%정도 되는걸 알수 있었어요. 두번째 방법은 $R^{2}$ 통계량을 보는 방법으로 우리가 구한 모델이 반응 변수의 변동성을 얼마나 설명할수 있는지, 분산의 퍼센트로 표한하는 방법입니다. 그래서 판매량 데이터에서 분산의 90%까지 모델이 설명할수 있었어요. RSE와 $R^{2}$는 표 3.6에서 볼수있어요.
3, 어떤 광고 매체가 판매량에 영향을 줄까요? which media contribuete to sales?
이 질문에 대한 대답은 각 입력 변수의 t 통계량과 그에 대한 p value로 확인할수 있어요(3.1.2). 표 3.4의 다중 선형회귀 모델에선 TV와 라디오의 유의확률은 낮지만, 신문은 그렇지 않았죠. 그렇다는건 티비와 라디오만이 판매량과 관련된 변수라는 걸 알수있어요. 6장에서 더 자세하게 다뤄보겠습니다.
4. 각 매체의 판매량에 대한 영향이 얼마나 큰가요? how large is the effect of each medium on sales?
우리가 3.1.2장을 봤을때 $\widehat{\beta}_{j}$의 표준 오차는 $\beta_{j}$의 신뢰 구간을 만드는데 사용할수 있었어요. 광고 데이터의 경우 95% 신뢰구간(실제 계수가 95%의 확률로 포함될 구간)은 TV의 경우 (0.043, 0.049), 라디오의 경우 (0.172, 0.206), 그리고 신문은 (-0.0113, 0.011)이었죠. 티비와 라디오의 신뢰구간은 좁고 0과는 떨어져있다보니 이 광고 매체들이 판매량과 관련되어 있다는걸 알수 있어요. 하지만 신문의 신뢰구간은 0을 포함하고 있어 이 변수는 티비나 라디오보다 유의미한 통계량이 아니라는 걸 알려줍니다.
3.3.3장을 보면 공선성 collinearity가 표준 오차에 큰 영향을 준다고 배웠습니다. 그러면 공선성이 신문의 신뢰구간이 넓어지게 만든 원인이라 할수 있을까요? 티비와 라디오, 신문의 VIF 점수는 각각 1.005, 1.145, 1.145로 다중 공선성의 문제라고 보기는 어렵습니다.
각 매체가 판매량에 미치는 영향을 평가하기위해서 세 매채를 나누어 단순 선형 회귀를 수행할수 있겠습니다. 표 3.1과 3.3에서 그 결과를 볼수있엇죠. 여기를 보면 TV와 판매량, 그릭 라디오와 판매량이 강한 관계를 가지고 있었어요. 하지만 티비와 라디오를 무시하고 신문과 판매량을 보았을때 둘 사이에는 약한 관계를 가지고 있었죠.
5. 우리가 예측한 판매량이 얼마나 정확할까요? How accurately can we predict futuer sales?
(3.21) 모델로 출력을 예측할수 있는데, 이 추정량의 정확도는 우리가 예측한 개별 출력 Y = f(X) + $\epsilon$ 혹은 출력 f(X)(3.2.2)의 평균에 달려있다고 할수 있습니다. 전자의 경우 예측 구간 prediction interval을 사용해서 봤엇고, 후자의 경우 신뢰 구간 confidence interval의 개념을 봤었습니다. 예측 구간은 항상 신뢰구간 보다 넓었었죠. 왜냐면 예측 구간은 개별 출력을 예측하다보니 제거불가 오차 $\epsilon$에의한 불확실성을 가지고 있거든요.
6. 선형적인 관계가 존재하였나요? Is the relationship linear?
3.3.3장에서 잔차 플롯 residual plot을 비선형성이 존재하는지 파악하기 위해 사용하였습니다. 선형적인 관계가 존재한다면 잔차 플롯 상에서는 눈에 띄는 패턴이 없었어요. 광고 데이터의 경우 그림 3.5에서 비선형적인 형태를 볼수 있었고, 이 영향을 잔차 플롯 상에서도 확인할수 있었습니다. 3.3.2에서는 선형 회귀 모델이 비선형적인 관계를 다룰수있도록 예측 변수를 변환시킨 경우에 대해서 배워보았습니다.
7. 광고 매체 사이에 시너지 효과/ 교호작용이 존재하였나요? Is there synergy among the advertising media?
표준 선형 회귀 모델은 입력 변수와 출력 변수 사이에 가산 관계를 가정하고 있었습니다. 가산 모델은 각 입력의 출력에 대한 영향이 서로 다른 변수의 값에 영향을 받지 않는다라고 이해할 수 있었어요. 다시 말하면 한 변수가 변할때 다른 변수는 변하지 않는다, 다른 변수에 의한 출력에 대한 영향이 변하지 않는다고 말하면 될거같아요. 하지만 가산 가정은 어떤 데이터셋에선 비현실적이었죠.
3.3.2에서 선형 회귀 모델에 비가산적인 관계 non-additive relationship을 다룰수있도록 교호작용항을 어떻게 추가시키는지를 보았습니다. 교호작용 항에 대한 pvalue가 매우 작다는건 교호작용이 존재한다고 볼수 있습니다. 그림 3.5에서 광고 데이터가 가산적이지 않다는걸 알수 있었어요. 그래서 교호작용 항을 추가하여 기존의 $R^{2}$ 통계량이 90%에서 97%까지 크게 증가시킬수가 있었습니다.
3.5 선형 회귀 모델과 K 최근접 이웃의 비교 Comparision of Linear Regression with K-Nearest Neighbors.
2장에서 얘기를 했었지만, 선형 회귀모델은 모수적 방법 중 하나라고 할수 있습니다. 왜냐면 f(X)가 선형 함수의 형태를 갖는다고 가정하고 있거든요. 모수적 방법 parametric methods는 여러가지 이점을 가지고 있는데, 모수적 방법에서는 적은 수의 모수를 추정하면 되므로 학습하기가 쉽습니다. 선형 회귀의 경우에서 계수들은 이해하기가 쉬웠죠, 그리고 계수들의 통계적인 기여도 statistical significance를 확인하기도 쉬웠습니다. 하지만 모수적인 방법은 몇가지 단점도 가지고 있는데, 이 모델을 만들때 실제 모델, 법칙 f(X)에 가까운 모델/가정을 만들어야 한다는 점입니다.
만약 우리가 정의/가정한 함수 형태의 모델이 실제 모델/법칙과 유사하지 않다면 예측 정확도는 좋지 못할겁니다. 예를 든다면 우리가 X와 Y사이에 선형적 관계가 존재한다고 가정을 했다고해요 실제로는 선형적인 관계가 없지만, 그러면 선형적일거라는 가정을 가지고 만든 모델은 데이터를 잘 학습하지 못하고, 학습해서 만든 모델의 예측값을 신뢰하기는 어려울 거에요.
반대로 비모수적 방법 non parametric method는 f(X)에 대한 어떤 파라미터를 갖는 형태/함수적 형태를 가정하지 않고, 대신 회귀를 하는데 더 유연한 방법이라고 할수 있어요. 앞으로 우리는 이 책에서 수많은 비 모수적인 방법들을 다룰건데, 가장 간단하고, 잘 알려진 비모수적 방법의 예시로 K 최근접 이웃 회귀 모델 K-nearest neighbors regression(KNN regression)에 대해 살펴봅시다.
KNN 회귀 모델은 2장에서 다루었던 KNN분류기와 비슷하게 동작을 합니다. K에 대한 값과 그리고 예측하고자 하는 값/ 입력 값 $x_{0}$가 주어질떄 KNN 회귀모델은 $x_{0}$에 가까운 K개의 학습 관측치들을 찾을거에요. 이 이웃한 학습 관측치들을 $N_{0}$이라고 하겠습니다. 그래서 $N_{0}$에 속하는 전체 훈련 출력값들의 평균으로 f($X_{0}$)를 추정할수 있어요. 이를 아래와 같이 정리할 수 있겠습니다.
그림 3.16. 2차원의 64개 관측치 데이터(노란점) 집합으로 KNN 회귀모델을 학습해 구한 f(X)의 추정치들. 좌측 : K = 1인 경우 모델 학습 결과가 거칠/러프하게 나오고 있습니다. 우측 : K = 9로 지정한 경우 훨씬 부드러운 학습 결과를 볼 수 있습니다.
그림 3.16는 입력 변수가 두 개인 p = 2 데이터셋에 KNN 회귀 모델을 학습시킨 결과를 보여주고 있습니다. 왼쪽 판낼은 K = 1로 학습하여 나온 모델이고, 우측 판낼은 K = 9일때의 학습된 회귀 모델을 보여주고 있어요. K = 1로 한 경우, KNN 모델이 관측치들을 보간interpolate(구간 안의 값을 채우는)하고 있고, 그 결과 스탭 함수(사각형의 신호 함수)형태가 되고 잇죠. K=9인 경우, 학습된 KNN 회귀 모델은 여전히 스탭 함수 형태를 띄나 9개의 주변 관측치를 이용하여 평균을 내다보니 예측 영역이 훨신 작아졌고, 더 부드러워졌습니다.
일반적으로 최적의 K는 편향 분산 트레이드오프/길항 관계를 고려하여 고르는데, 이에 대해서 2장에서 이야기하였었습니다. K가 작을수록 학습 모델이 유연해 지지만, 편향이 작고 분산은 높았엇죠(모델의 변동정도가 크다.). 분산 값이 높게 나오는 이유는 예측 결과가 가장 가까운 값 하나만 가지고 예측해서 (완만하게 아니라 크게크게 변하므로) 그래요. 하지만 K가 크수록 더 부드러워지고, 학습한 모델이 덜 유연해 졌었씁니다. 그리고 예측 영역은 주위 여러개의 점들을 평균으로 구하여, 관측치 하나가 변할때 미치는 영향이 더 작았죠.
이 유연함때문에 편향이 생길수 있는데, 5장에서 테스트 에러율을 추정하는 방법에 대해서 다룰건데, 이 방법들로 KNN 회귀에서 최적의 K값을 찾는 데 사용할수가 있겠습니다.
최소 제곱 선형 회귀 같은 모수적 방법이 KNN같은 비모수적 방법보다 더 좋은 성능을 보일때는 어떤 경우일까요? 이에 대한 해답은 간단한데, 실제 모델 f에 가까운 파라미터 모델/함수 모델을 사용할수 있을때 모수적 방법이 비모수적 방법보다 더 잘 동작합니다.
그림 3.17 관측치가 100개인 1차원 데이터 집합에 KNN 회귀 모델을 학습하여 구한 추정 모델 f_hat(X)의 플롯들. 실제 모델은 검은색 직선입니다. 좌측 : 파란색 곡선은 K = 1일때 학습한 결과로 훈련 데이터로 추정 결과들을 보간 하고 있습니다. 우측 : 파란색 커브는 K = 9일때 학습한 결과로, 이전 모델보다 더 부드러운 학습 결과? 예측 결과를 보여줍니다.
그림 3.17은 1차원 선형 회귀 모델로 생성한 데이터들의 예시를 보여주고 있는데요. 검은색 직선 실제 모델인 f(X), 파란색 커브는 K = 1, K = 9로 설정하여 KNN 회귀 모델로 학습시킬 결과물 입니다. K=1인 경우에 예측값은 실제와 너무 멀고, K = 9로 설정한 경우에는 실제 f(X)에 더 가까운 예측결과를 얻을수 있었습니다. 하지만 이건 실제 입출력 관계가 선형적이기 때문이며, 선형 회귀 모델이 적합하지 비모수적인 방법으로는 어렵습니다. 비 모수적인 방법은 편향으로 제거할수 없수없는 분산이 있어 비용이 발생할수 있어요.
그림 3.18. 그림 3.17과 같은 데이터를 사용하고 있습니다. 좌측 : 파란색 점선은 이 데이터를 최소 제곱법으로 학습한 직선입니다. f(X)는 실제 모델을 의미하는 직선이구요(검은선), 최소 제곱 회귀선이 실제 f(X)를 잘 추정하고 있는걸 볼 수 있습니다. 우측 : 점 평행선은 최소 제곱 모델을 시험데이터셋을 사용한 MSE이고, 녹색선은 KNN 회귀 모델의 MSE로 1/K한 결과를 보여주고 있어요. 선형 회귀 모델이 KNN 회귀 모델보다 시험 MSE가 더 낮은데 이건 실제 모델 f(X)가 실제로 선형이기 떄문입니다. KNN 회귀 모델의 경우 K가 큰 값일수록 1/K은 작아지고, 더 좋은 결과를 얻을 수 있었어요.
그림 3.18의 왼쪽 판낼에서 파란색 점선은 같은 데이터 셋을 선형 회귀 모델로 학습한 결과를 보여주고 있는데, 거의 완벽하죠. 그림 3.18의 오른쪽 판낼은 이 데이터에서 선형 회귀 모델이 KNN 회귀 모델을 능가하는걸 볼수 있어요. 녹색 선은 KNN의 시험 MSE를 보여주고 있는데 x축에 1/K로 놓고 보여주고 있어요. KNN 에러는 대체로 선형 회귀 모델의 시험 MSE인 검은색 점선보다 높게 나오는걸 볼수 있습니다. KNN은 K가 클때 시험 MSE가 줄어들고, K가 작은 경우 더 나쁜 결과를 보입니다.
(위 오른쪽 그림에서 K = 1인경우 MSE가 0.15를 넘어가고, K = 2인경우 0.15 아래로 내려온다, K = 10이라면 0.1보다는 크지만 전보다 더 내려와있다.)
그림 3.19 위 왼쪽 : X와 Y사이에 약한 비선형 관계(검은색 선)를 가진 환경에서, K = 1로 KNN 모델을 학습한 경우(파란색), K = 9로 KNN 모델을 학습한 겨우(빨간색)을 보여주고 있습니다. 위 우칙 : 이 약한 비선형 관계를 가진 데이터에서, 최소 제곱 회귀 모델을 이용한 테스트 MSE(회색 평행 점선)와 다양한 K를 주었을떄(1/K) KNN의 테스트 MSE(녹색)을 보여주고 있습니다. 아래의 왼쪽 오른쪽 : 위 그림과 동일하나 X와 Y 사이에 강한 비선형 관계가 존재하고 있습니다.
현실에서 X와 Y 사이 실제 관계가 선형인 경우는 매우 드뭅니다. 그림 3.19는 X, Y 사이 관계에서 비선형적인 정도가 증가할때 최소 제곱 회귀법과 KNN 회귀법 사이 성능을 보여주는데요. 위쪽 행에서 실제 관계는 선형에 가까운 경우로 선형 회귀의 테스트 MSE가 여전히 K가 낮은 경우 KNN의 MSE보다 더 나은 결과를 내는 것을 볼수 있어요. 하지만 두번째 행에서는 비선형성이 더 강한데, 여기서는 KNN이 K가 어떤 값이던간에 선형 회귀 모델의 테스트 MSE보다 더 나은 결과를 보이고 있습니다. 하지만 선형 회귀 모델의 MSE는 크게 증가하였죠.
그래서 그림 3.18과 3.19는 KNN 모델은 실제 관계가 선형적일때 선형 회귀보다 나쁜 성능을 보이고, 비선형적인 상황에선 선형 회귀 모델보다 더 나은 성능을 보이는걸 보여주고 있습니다. 현실 세계에서는 실제 관계가 어떤지는 알수 없습니다. 하지만 KNN 모델이 실제 관계가 선형적이면 선형 회귀보다 약간 나쁠거고, 실제 관계가 비선형이라면 선형 회귀보다는 크게 더 좋은 성능이 나오기 때문에 KNN이 선형 회귀 보다는 더 잘 쓰이곤 합니다. 특히 그림 3.19과 3.19는 입력 변수가 1개 p = 1개인 상황을 다루다보니 더 높은 차원으로 간다면 KNN이 선형 회귀 모델과 나쁜 성능을 낼 수도 있어요.
그림 3.20 변수의 갯수 p가 증가할때 선형 회귀(검은색 점선)과 KNN(녹색 곡선)의 시험 MSE. 실제 함수는 그림 3.19의 아래 판낼에 나오는 걸로 비선형적이고, 다른 변수의 영향을 받지 않아요. 변수의 개수가 증가할수록 선형 회귀의 성능이 조금씩 나빠지고 있지만, KNN의 경우 p가 증가할수록 빠르게 나빠집니다.
그림 3.20은 그림 3.19의 두번째 행의 강한 비선형 적인 상황에서 고려하는건데, 대신 (출력에 연관되지는 않았으나)노이즈를 가진 변수를 추가할때 테스트 MSE를 보여주고 있습니다. p = 1 혹은 2인경우 선형 회귀보다는 KNN이 좋은 성능을 보이고 있어요. 하지만 p = 3인 경우 결과가 비슷하다가 p >= 4 일때부터 선형 회귀가 더 좋은 결과를 보이고 있어요. 차원이 증가할수록 선형회귀 모델의 시험 MSE는 약간만 나빠지게 만드나 KNN의 경우에는 훨신 성능이 나빠지는걸 볼수 있습니다. 차원 증가시에 성능이 떨어지는건 KNN에서 흔한 형상이며, 큰 차워닐수록 표본 크기, 샘플 크기가 줄어들기 때문에 그래요.
이 데이터셋에 100개의 훈련 데이터가 있다고 합시다. 그러면 p = 1인경우 f(X)를 정확하게 추정하는대 충분해요. 하지만 차원이 20인, p = 20인 100개의 데이터가 있다면 최근
An Introduction to Statistical Learning with Application in R
3. 모델이 데이터를 얼마나 잘 학습(적합)하였을까? how well does the model fit the data?
대표적인 모델의 적합도를 나타내는 수치 척도로는 RSE와$R^{2}$가 있습니다. 이들은 이 모델로 설명할수 있는 분산, 변동성 variance의 정도로 이 모델이 데이터를 얼마나 잘 표현하고있는 정도라고 이해하면 될것 같습니다. 단순 선형 회귀에서도 이런 값들을 구할수가 있습니다.
한번 단순 회귀를 떠올려보면 $R^{2}$는 입력 변수와 반응 변수의 상관 계수의 제곱이었었죠. 하지만 다변수 선형 회귀에서는 Cor(Y, $\hat{Y})^{2}$가 되는데, 학습된 선형 모델과 반응 변수 사이의 상관계수의 제곱이라 할수 있어요. 그래서 학습된 선형 모델은 가능한 모든 선형 모델들 중에서 상관 관계가 강한 모델이라 할수있겠습니다.
$R^{2}$가 1에 가깝다는것은 이 모델이 반응 변수의 변동성, 분산의 상당 부분 설명할수 있다는 것을 의미해요. 예를들자면 표 3.6의 광고 데이터에서, 세 광고 매체로 판매량을 예측햇던 모델의 결정계수 $R^{2}$가 0.8972였었죠. 반면에 TV와 라디오만으로 판매량을 예측했던 모델에서 $R^{2}$는 0.89719가 되었었습니다. 이걸 다시 말하면, 표 3.4에서 신문 광고의 유의 확률 p value가 유의미하게 크지 않았던것을 봤음에도, TV와 라디오 데이터를 학습한 모델에 신문 데이터를 추가하여 학습시킨 경우 $R^{2}$가 약간 증가하는것을 볼 수 있었습니다.
그래서 $R^{2}$는 모델에 변수가 추가될때 항상 증가한다는것을 알수 있어요. 이런 추가되는 변수가 반응/출력에 약하게 연관되어 있더라두요. 이거는 최소 제곱 방정식에 다른 변수를 추가시킴으로서 더 정확하게 훈련 데이터를 학습(과적합이 심화될 수 있다는 얘기로 보임)할수 있기 때문인데, $R^{2}$ 통계량은 훈련 데이터로만 계산되다보니 무조건 증가해버립니다.
TV와 라디오로 학습한 모델에 신문 광고를 추가시킬때 $R^{2}$가 약간만 증가했다는 사실을 보면 신문 정보는 모델에서 제외시킬수 있다고 볼수 있습니다. 특히 신문 정보는 훈련 과정을 개선시키지도 않고, 그걸 포함시켰다가 오버피팅 문제로 테스트 시 성능을 떨어트리게 만들어버릴겁니다.
반대로 TV만 입력, 독립 변수로 사용했던 모델의 경우 (표 3.2에서) $R^{2}$가 0.61이엇었는데, 요기에 라디오를 추가함으로서 $R^{2}$가 상당히 증가하였습니다. 이거는 TV와 라디오 광고 예산을 증가시키는게 TV 광고만 했을때보다 훨씬 좋다는걸 의미해요. 그리고 (라디오와 TV를 학습한 모델의) 성능이 얼마나 개선 되는지는 모델의 라디오에 대한 p-value를 보고 알 수 있어요.
TV와 라디오를 학습한 모델의 RSE는 1.681이었고, 여기에 신문을 포함시킨 경우 (표3.6) RSE가 1.686이나왔습니다. 하지만 TV만 있는 모델의 경우 3.26(표3.2)가 나왔죠. 그래서 이 티비와 라디오를 같이 이용한 모델이 티비만 사용하여 예측한 모델보다 훨씬 정확한 결과를 얻을수가 있었어요. 게다가 티비와 라디오가 있는 모델에다가 신문을 추가시켜봣자 의미가 없었는걸 알수 있었구요. 독자 분들은 아마 신문을 추가시켰는데, RSS는 줄어들지만, 왜 RSE가 증가되었는지 궁금하실거에요.
일반적으로 RSE는 위와 같이 정의됩니다. 이걸 단순 선형 회귀일 경우 (3.15)로 간단하게 고칠수가 있어요. 변수가 늘어나면서 p의 증가보다 RSS의 감소가 작다면, RSE는 더 커지게 됩니다. p가 증가하면 RSS가 적게 나눠지다보니 RSE가 증가한다. 그래서 p가 증가하는것에 따라 RSS가 줄어들어야 RSE가 커지는것을 막을수 있지만 이걸 상쇄시키지 못해 RSE가 커진다는 보인다.
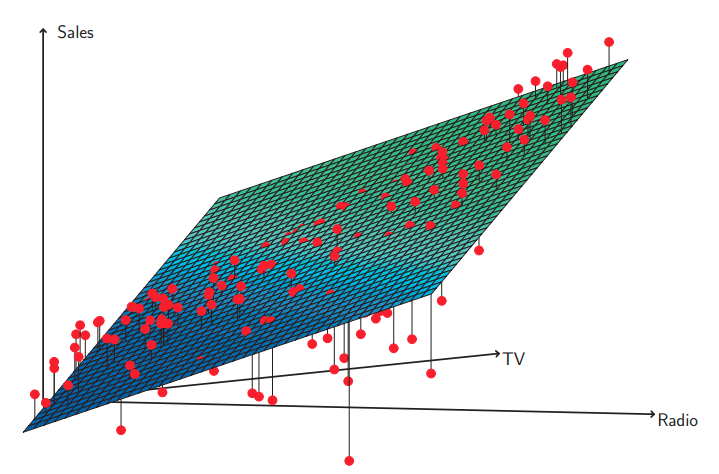
그림 3.5 광고 데이터, 티비와 라디오를 이용한 판매랑의 선형 회귀 모델. 잔차 패턴을 보면 데이터에 눈에 띄는 비선형 관계가 존재하고 있어요. 잔차가 양의 값을 갖는 경우(평면 위로 올라간 경우)는 45도로 기울어진 직선형태를 보이고 있어요. 잔차가 음의 값을 갖는 경우는(평면 아래로 내려가 상당수가 안보임) 예산이 한쪽으로 쏠린 경우로 이 직선으로 멀리 떨어지는 경향을 보여요.
그리고 RSE와 $R^{2}$ 통계량을 이해하기 위해서 데이터를 플롯해보면 좋은데, 이걸 시각화 시키면 수치 통계량으로 볼수 없는 문제들도 볼수 있어요. 예를들면 그림 3.5는 티비와 라디오 그리고 판메량에 대한 3차원 플롯을 보여주고 있습니다. 이 그림을 보시면 어떤 관측은 최소 제곱 평면의 아래에 어떤 관측들은 최소 제곱 평면의 위에 있습니다.
특히 이 선형 모델은 티비또는 라디오 중 하나에 예산을 몰아서 많이 쓴 경우 판매량 증가가 많을거라고, 과대 추정을 하고 있으며. 두 미디어에 예산을 나누는 경우 판매량이 떨어질 것으로 과소 추정하고 있습니다. 이 비선형적인 패턴은 선형 회귀 모델로 정확하게 모델링, 표현할수가 없어요. 그래서 광고 매체 사이에 시너지 synergy, 교호작용 interaction 효과가 존재하여 미디어를 같이 사용할때 판매량이 광고 매채를 하나만 한 경우보다 훨씬 증가한다는것을 보여주고 있습니다. 이 3.3.2에서 이 선형모델을 확장시켜 이런 시너지 효과를 교호작용 항을 사용해서 포함시킬것인지를 다뤄 볼 거에요.
4. 입력 데이터셋이 주어질때, 어떤 값을 예측하여야하고 예측 결과가 얼마나 정확할까요?
Given a set of predictor values, what response value should we predict, and how accurate is our prediction?
우리가 학습된 다항 회귀 모델을 가지고 있으면 $X_{1}$,$X_{2}$, . . .$X_{p}$에 대한 데이터셋으로 Y를 예측할수 있을거에요.하지만 우리가 구한 예측 결과에는 3가지 종류의 불확실성이 존재합니다.
1. 계수 추정치 $\widehat{\beta}_{0}$ ,$\widehat{\beta}_{1}$ , . . .,$\widehat{\beta}_{p}$는 $\beta_{0}$, $\beta_{1}$, . . ., $\beta_{p}$를 추정한 것이다 보니 아래의 최소 제곱 평면 least squares plane은
참 모집단 회귀 평면 true population regression plane을 추정한 것일 뿐입니다.
그렇다 보니 추정한 계수들은 불확실성을 가지고 있어 모델의 떨어지는데 이건 2장에서 이야기한 제거 가능 오차(모델 오차)라고 볼수 있을거같아요. 아무튼 우리는 $\hat{Y}$가 f(X)에 얼마나 가까이에 존재할지 결정하는 신뢰구간을 정할수가 있습니다.
2. 물론 현실에선 f(X)는 선형 모델이다! 라고 가정하는것은 현실을 선형 모델로 근사 시킨 것일 뿐이며, 현실과 모델 사이의 괴리인 모델 편향 model bias라고 부르는 제거 가능 오차가 생기게 됩니다. 그래서 우리가 선형 모델을 사용한다고 할 때, 실제 평면에 가까운 최적의 선형 근사 결과물을 추정하는것이며 여기에 존재하는 오차를 무시하더라도 선형 모델은 올바르게 동작할 거에요.
3. 우리가 f(X) 혹은 실제 계수 $\beta_{0}$,$\beta_{1}$, . . .,$\beta_{p}$를 알고있다 하더라도 출력값,반응변수의 값은 완벽하게 예측할 수 없습니다. 왜냐하면 이 모델 (3.21)은 오차항 $\epsilon$을 가지고 있거든요.
우리는 신뢰구간 confidence interval은 판매량 평균의 불확실성 정도를 측정하기 위해 사용하는 지표인데, 예를들어 TV 광고비용으로 10만달러를 쓰고, 라디오 공과에는 2만 달러를 썻다고 해요. 그러면 95% 신뢰 구간은 [10,985 11,528] 이 되는데, 이것은 실제 f(X)의 값의 평균이 95%의 정확도로 포함하고 있을 구간을 이야기 해요.
그리고 예측 구간 prediction interval은 특정 도시에서의 판매량의 불확실성 정도를 나타내는 개념인데, TV 광고 예산에 100,000달러 라디오 광고 예산에 20,000 달러를 사용한 경우 한 도시에서 예측되는 95% 예측 구간은 [7,930 14,580]이며, 실제 Y의 한 값이 95%의 확률로 포함되는 구간을 의미합니다. 보면 예측 구간은 신뢰 구간보다 훨씬 큰데, 이는 한 도시의 판매량만을 보았을 때는 모든 도시의 평균 판매량의 불확실한 정도보다 그 불확실함이 훨씬 크다고 할 수 있기 때문입니다.
3.3 회귀 모델에서 다른 고려 사항들 Other Consideration in the Regression Model
3.3.1 질적 변수를 사용할 때 Qualitative Predictors
지금까지 살펴본 내용들을 보면 선형 회귀 모델에 사용하는 모든 변수들이 양적 변수 Quantitative라고 가정하여 보았습니다. 하지만 현실에서는 일부 입력변수, 독립변수, 예측자들은 질적 변수 Qualitative인 경우도 있어요.
그림 3.6 신용 데이터 셋. 잔액, 나이, 카드 갯수, 학업기간, 수입, 한도, 신용평가점수 등의 정보가 있습니다.
예를들어 그림 3.6에 있는 신용 정보를 한번 봅시다. 여기에는 채무 잔액 balance(평균 신용 카드 채무잔액) 뿐만이 아니라 질적 변수 quantitative로 나이와 카드 cards(카드 갯수), 학업기간 education(학업기간), 수입(천달러 단위), 한도(신용 한도), 신용 평가 점수 rating등이 있습니다. 그림 3.6의 각 판낼들은 스캐터 플롯 그러니까 산점도를 보여주고 있는데, 이 스캐터 플롯은 두개의 변수들 행과 열로 보여주고 있어요.
예를들면 "balance 채무잔액"이란 글씨 바로 오른쪽에 채무잔액과 나이에 대한 산점도가 있고, "age 나이" 글씨 바로 오른쪽에는 나이와 신용카드 갯수에 대한 산점도가 있습니다. 이 외에도 4개의 양적변수로 성별, 학생여부 student, 혼인 상태 martial status, 인종 ethnicity(백인, 흑인, 아시안)가 있습니다.
두 가지 경우만 존재할때 예측하는 경우 Predictors with only two levels
한번 다른 변수들은 다 무시하고, 남성과 여성에 따른 신용 카드 채무잔액을 한번 살펴봅시다. 이렇게 남성/여성으로 질적 변수, 질적 예측자 qualitative predictor가 2가지의 경우로 나뉘는 경우는 회귀 모델에 정말 쉽게 반영시킬수가 있어요. 이 때 가 변수 dummy variable이라고 부르는 변수를 만드는데, 이 가 변수는 0또는 1 두개의 수치값가져요. 예시를 보면 우린 성별이란 변수를 가지고 있으니 이걸로 아래와 같은 형태의 새로운 가변수를 만들수가 있습니다.
그리고 이 가변수가 회귀 방정식에 입력 변수로 사용하여 아래의 모델을 만들수가 있겟죠.
그러면 $\beta_{0}$는 남성의 평균 신용카드 채무잔액이며, $\beta_{0}$ + $\beta_{1}$은 여성의 평균 신용카드 채무잔액가 되겠죠. 그리고 $\beta_{1}$은 남성과 여성사이 신용 카드 채무잔액의 평균적인 차이가 되겠습니다.
표 3.7 최소 제곱 계수 추정치. 신용 데이터셋에서 성별에 따른 채무 잔액의 회귀 모델을 만든 경우 최소 제곱 법으로 추정한 계수. (3.27)의 선형 모델을 사용하였으며, (3.26)처럼 성별을 가변수로 인코딩하였음.
표 3.7은 (3.27) 모델의 계수 추정치와 다른 정보들을 보여주고 있어요. 남성의 평균 채무잔액은 509.80이며, 여성의 경우 19.73달러가 추가되어 총 잔액가 $509.80 + $19.73 = $529.53달러가 됩니다. 하지만 가변수의 p value를 보시면 0.6690으로 엄청 높죠. 그래서 이게 성별과 신용카드 잔액 사이에는 유의미한 관계(성별에 따른 차이)가 존재하지 않는다는 통계적인 근거가 되겠습니다.
* 이전에 단순 선형 회귀에서 가설 검정을 할때를 떠올려보세요 입력 변수 X와 종속 변수 Y간에 유의미한 관계가 존재하는 경우 p value가 낮았었고, 귀무가설(X와 Y는 유의미한 관계를 갖지 않는다.)을 기각하는 대신 대립 가설(X와 Y는 유의미한 관계를 갖는다)를 채택하였엇죠.
아까 (3.27)에서 여성은 1, 남성은 0로 인코딩을 시켰지만 이건 회귀 적합에 영향을 주지는 않고 대신 계수의 해석 과정이 조금 달라질수는 있어요. 남성이 1이고, 여성이 0인 경우 $\beta_{0}$ = 529.53 그리고 $\beta_{1}$ = -19.73이 되어 남성은 $529.53 - $19.73 - $509.80이 되고, 여성은 $529.53으로 해석만 조금 달라지지 같은 결과가 나오게 됩니다.
0/1로 인코딩하는 대신에 가변수를 아래와 같이 사용할수도 있는데
이 가변수를 사용하면 회귀 방정식이 아래와 같이 바뀌겠죠.
여기서 $\beta_{0}$는 전반적인 평균 신용카드 채무잔액(성별의 영향을 무시한)이고, $\beta_{1}$은 여성일 경우 평균 보다 떨어트리고, 남성일 경우 평균보다 높이는 값일 거에요. 이 예시에서 $\beta_{0}$ 추정치는 $519.665으로 남성과 여성의 평균치가 됩니다. $\beta{1}$ 추정치는 $19.73의 절반인 9.865가 되어요.
여기서 여러분들이 알아야 할 점은 인코딩 방식이 좀 달라지더라도 남성과 여성에 대한 신용카드 채무잔액 예측치는 동일하다는 점이고, 그냥 계수를 이해하는 과정만 조금 바뀔 뿐입니다.
질적 변수가 여러 가지의 경우의 수를 갖는 경우 Qualitative Predictors with More than Two level
아까는 한 성별이라는 입력/질적 변수가 남자, 여자 2가지 경우의 값만을 가지고 있었는데, 이번에는 질적 변수가 2개 이상의 값을 가졌다고 해봅시다. 그러면 하나의 가변수(0, 1) 만으로는 모든 경우를 나타내지는못할거에요. 이런 경우 가변수를 여러개를 사용해야 합니다. 예를들어 인종 변수의 경우 2개의 가변수를 사용하여야 합니다. 첫번째는
두번째는
이 두 가변수들을 회귀 방정식에다가 적용하여 다음의 3가지 경우에 대한 모델을 만들어 낼 수가 있어요.
여기서 $\beta_{0}$는 흑인의 평균 신용 카드 채무잔액, $\beta_{1}$은 흑인과 아시안의 평균 채무잔액 차이, $\beta_{2}$는 백인과 학은의 평균 채무 차이를 나타낸다고 볼수 있을거에요. 이처럼 가변수는 경우의 수 혹은 카테고리 갯수보다 1개 적은 개수의 가변수가 필요합니다. 카테고리가 3개라면 가변수가 2개, 지금 예시처럼요. 이 예제에서 가변수가 존재하지 않은 흑인이 베이스라인이라고 할수 있겠습니다.
표 3.8 최소 제곱 추정 계수들. 신용 카드 데이터셋의 인종에 따른 채무 잔액에 대한 회귀 모델. (3.30)의 회귀 모델이며, 인종이 (3.28)과 (3.29)의 두 가변수로 인코딩 되었습니다.
표 3.8을 보시면 흑인의 채무잔액 추정치가 베이스라인이(절편 intercept에 있는데) $531달러인것을 볼수 있어요. 그리고 아시안인 경우 흑인 보다 $18.69 달러가 적다고 추정하고 있으며, 백인의 경우 흑인보다 $12.50$달러 적다고 나오고 있습니다. 하지만 두 계수 추정치의 p value가 상당히 높게 나오고 있어요. 그러므로 인종은 신용 카드 채무잔액을 추정하는데 (관계성을 가지는) 유의미한 변수가 아니라고 판단할 수 있겠습니다. 인종에 따라 구한 채무잔액 예측을 해도 거의 같다? 혹은 인종이 상관없이 비슷한 채무잔액 예측치가 나온다는 얘기입니다.
하지만 이 계수와 pvalue들은 가변수의 어떤 카테고리에 속해있느냐에 따라 영향을 받고 있다보니, 이보다는 귀무 가설 $H_{0}$ : $\beta_{1}$ = $\beta_{2}$ = 0을 F검정으로 검정을 하면, $\beta_{1}$과 $\beta_{2}$가 0이다 즉 영향이 존재하지 않는다는 것을 귀무가설로 가설 검증을 하는것으로 볼 수 있는데, 이 경우 유의 확률이 0.96가 되어 인종과 채무잔액 사이에 관계가 존재하지 않는다는 귀무가설을 채택할 수 있습니다.
* 표 3.8은 각 카테고리별 계수와 p value를 구하다 보니 좀 다르지만, 이걸 합쳐 $\beta_{1}$ = $\beta_{2}$ = 0을 귀무가설로 가설 검증할때는 유의 확률 p value가 0.96으로 또 바뀜.
질적 변수랑 양적 변수를 둘다 사용할때도 가변수는 쉽게 사용할수 있어요. 예를 들자면 채무잔액을 수입이란 양적 변수와 학생 여부에 대한 질적 변수로 회귀, 추정할때 그저 수입 변수에다가 학생에 대한 가변수만 추가시키고 다변수 회귀 모델을 사용하면 되요.
가변수 말고도 질적변수를 코딩하는 많은 방법들이 있지만, 모든 방법들은 다 모델 학습 결과는 똑같고 모델을 어떻게 이해하면 될지만 조금씩 달라집니다.
3.3.2 선형 모델의 확장 Extensions of the Linear Model
기본 선형 회귀 모델 (3.19)는 이해하기 쉽고 다양한 형실 세계 문제들에서도 잘 동작하고 있습니다. 하지만 이 선형 모델에는 현실 세계를 종종 무시하는 강한 가정들이 존재하는데, 가장 중요한 두 가정으로 입력과 출력 사이의 관계가 선형 linear적이고, 가산적 additive이어야 한다는 가정이 있습니다.
가산 가정 additive assuption은 입력 $X_{j}$가 변할때 반응 변수 Y에 주는 영향력이 다른 입력변수의 값에 독립적이어야 한다는 가정입니다. 다시 말하면, $X_{j}$에 의한 Y의 변화량은 다른 변수의 영향과는 상관없어야 한다는 얘기에요. 다음으로 선형 가정 liear assumption은 $X_{j}$가 바뀔때 Y도 상수배 만큼 변해야 한다는 말로, 입력 변수와 종속 변수 간에 직선, 그러니까 선형적인 관계를 가져야 한다는 가정입니다. 이 자료에서 이 두가정들을 완화시키는 방법들을 볼건데, 우선 선형 모델을 확장시킨 고전적인 방법들 부터 살펴봅시다.
가산 가정을 완화시키기 Removing the Additive Assuption
이전에 광고 데이터를 보면서 우리는 티비와 라디오 광고가 판매량과 연관성을 가지고 있다고 결론을 내렸어요. 선형 모델은 이 결론을 가지고 만들어 지는데, 한 매체의 광고 예산을 증가시켜 판매량을 늘린 영향이 다른 매체의 광고비용에 독립, 영향을 받지 않는다고 가정합니다. 예를 들면 (3.20)의 선형 모델을 보면 TV가 1 만큼 증가할때 판매량에 미치는 평균적인 영향이 $\beta_{1}$인걸 보여주고 있어요. 라디오 광고 예산과는 상관없이요. 뒤집어 말하면 라디오 광고 예산이 얼마던 간에 TV 광고 비가 1이 오르면 판매량이 $\beta_{1}$이 늘어난다고 할수 있을거같네요.
하지만 이 가정은 잘못되었습니다. 라디오 광고를 늘리면 TV 광고 효과도 증가해서(교호작용 혹은 시너지 효과) 라디오에 의한 계수, 기울기 항 베타가 증가할때 TV의 기울기 항 beta도 증가하거든요. 100,000달러의 예산이 주어졌고, 우리가 라디오에 절반, 티비에 절반 놓고 광고를 했다고 합시다. 그러면 TV나 라디오 둘중 하나에 10만 달러 광고를 한것 보다 더 큰 판매 효과를 얻을수가 있어요.
시장에선 이걸 시너지 효과 synergy effect라 부르고, 통계학에서는 이것을 교호작용 interaction effect라고 부릅니다. 그림 3.5는 광고 데이터 셋에서 교호 작용이 어떻게 일어나를 볼수 있었어요. TV나 라디오 둘 중 하나의 광고 비용이 낮았다면 실제 판매량은 선형 모델이 예측한 것 보다 낮았었죠.(다중 선형 회귀 평면 아래에 실제 관측치가 존재함) 하지만 두 매체로 나눠서 광고 할때는 실제 판매량이 더 높은데 모델은 낮게 판매하는 과소 추정하는 경향이 있었습니다.(판매량 관측치, 빨간점보다 다중 선형 회귀 평면이 아래에 있었음)
아래와 같이 두 변수가 주어진 표준 선형 회귀 모델이 주어질때,
이 모델에 따르면 $X_{1}$을 한단위 혹은 1을 증가시키는 경우 Y는 $\beta_{1}$만큼 증가하게 될겁니다. 하지만 $X_{2}$는 무슨 값이 오더라도 Y가 변하는데 추가적인 영향을 주지 못해요. 그래서 교호 작용을 반영하도록 이 모델을 확장시키는 방법은 3번째 입력 변수로 교호작용 항 interaction term을 추가시키는 것입니다. 이 항은 $X_{1}$과 $X_{2}$의 곱으로 계산할 수 있어요. 그러면 이 모델은 아래와 같이 정리 할수 있겠죠.
그러면 이 교호작용향을 추가시킬때 가산 가정을 얼마나 완화시킬수 있을까요? 위 식 (3.31)을 아래와 같이 $\widetilde{\beta}_{1}$ = $\beta_{1}$ + $\beta_{3}$ X 로 하여 고칠수가 있어요.
여기서 $\widetilde{\beta}_{1}$는 $X_{2}$에 의해 변할수 있기 때문에 $X_{1}$이 Y에 미치는 영향이 더 이상은 (직선의 기울기 처럼)상수가 아닌 변수로 영향을 주게 됩니다. 그러면 $X_{2}$를 조절시킴으로서 $X_{1}$이 Y에 주는 영향력을 바꿀수가 있어요.
한번 제품을 생산한느 공장의 예시를 들어 볼게요. 우리는 직원의 수와 생산 라인의 수로 생산할수 있는 제품 양을 예측하고 싶다고 합시다. 아마 생산 라인은 직원의 수에 의존한다고 볼수 있을 겁니다. 왜냐면 직원들이 없으면 생산 라인을 돌릴수가 없잔아요. 그래서 생산 라인의 수만을 늘린다고해서 제품 생산이 늘어나지는 않을 거에요.
이를 고려하면 선형 모델에는 생산 라인과 직원 수 사이에 교호작용을 나타내는 항을 추가를 해야 선형 모델이 생산량을 더 잘 예측할수 있을거에요. 그렇게 모델을 학습시켜 아래의 식을 얻었습니다.
다시 정리하자면 생산 라인을 늘리면 '3.4 + 1.4 x 직원의 수'만큼 생산량이 증가하게 될거에요. 이렇게 정리하면 우리가 직원을 더 많이 고용하고 있을수록 생산라인의 제품 생산량도 더 많아지겠죠.
그러면 우리가 계속 보던 광고 예시로 돌아갑시다. 라디오와 티비로만 있던 선형모델에 두 매체의 교호 작용 향을 추가하여 판매량을 예측한다면 아래의 형태가 되겟죠.
그러면 역서 $\beta_{3}$을 TV 광고를 늘릴떄 라디오 광고를 늘리는 효과 혹은 그 반대로도 볼수 있겠죠. 식 (3.33)의 모델을 학습한 결과는 표 3.9에서 볼수 있겠습니다.
표 3.9 티비와 라디오가 주어질때 판매량에 대한 회귀 모델의 최소 제곱 추정 계수. 식 (3.33)의 교호작용향을 포함하고 있습니다.
표 3.9의 결과를 보면 교호 작용을 포함 시킨 모델이 그렇지 않은 모델보다 더 뛰어나다는것을 알 수 있어요. 교호 작용 항 TV x 라디오의 p value가 엄청 낮은데, 이건 대립 가설 $H_{a}$ : $\beta_{3}$ $\neq$ 0이라는 강한 통계적 증거이죠.($beta_{3}$은 판매량과 큰 관계를 가지고 있다.) 즉, 다시 말하자면 입력 변수와 판매량 사이의 실제 관계, 실제 모델은 가산적이지는 않다는 얘기이죠.
식 (3.33) 모델의 $R^{2}$는 96.8%인데, 교호작용없이 티비와 라디오만으로 판매량을 예측한 모델이 89.7%였던것에 비해 데이터의 설명력이 커졌다는것을 알수 있습니다. 이것은 (96.8 - 89.7)/(100 - 89.7)= 69%, 가산 모델만을 학습하였을때 판매량에 대한 변동성의 69%를 교호 작용 항을 추가시킴으로서 설명할수 있게 되었다는 얘기입니다. * 교호작용이 기존 가산 모델이 설명 못하던 부분의 상당 부분을 설명할수 있게 만들었습니다.
표 3.9에서 추정한 계수들을 보면 TV 광고 예산 1000달러가 증가할때 ($\widehat{\beta}_{1}$ + $\widehat{\beta}_{3}$
x 라디오) x 1,000 = 19 + 1.1 x radio만큼 판매량이 증가하게 됩니다. 라디오 광고 예산이 1000달러 증가하는 경우 ($\widehat{\beta}_{2}$ + $\widehat{\beta}_{3}$ x TV) x 1,000 = 29 + 1.1 x TV만큼 판매량이 증가하게 되구요.
이 예시에서 TV, 라디오, 교호작용 항에 대한 p value는 (표 3.9) 모두 통계적으로 유의미한 값을 가지고 있어, 이 세 변수들이 모두 모델에 포함되어있어야 한다고볼수 있습니다. 하지만 교호작용 항의 p value가 매우 작은데, 주 변수들(지금의 경우는 TV와 라디오)의 p value가 작지 않은 경우도 존재합니다.
계층적 원칙 hierachical principle에 따르면 모델에 교호작용 항을 포함시킨다면, 주 변수들의 p value가 낮아 유의미 하지 않더라도, 당연히 주 변수들도 포함시켜야 합니다. 다시 말하자면, $X_{1}$가 $X_{2}$의 교호작용 항이 중요한 경우 $X_{1}$, $X_{2}$의 계수 추정치가 유의미 하지 않더라도 둘다 모델에 포함시켜야 한다는 이야기 입니다.
이 이론적인 원칙의 근거는 $X_{1}$ x $X_{2}$가 반응에 영향을 준다면, $X_{1}$ 또는 $X_{2}$의 계수가 0이더라도 상관없기 때문입니다. $X_{1}$ x $X_{2}$는 $X_{1}$과 $X_{2}$사이에 상관관계가 존재한다는걸 의미하다보니 이 영향을 없앤다면 상호작용의 효과가 사라지게 될겁니다.
이전 예시에서 둘다 질적 변수인 TV와 라디오 사이의 교호작용, 상호작용에 대해 이야기 했는데, 상호작용의 개념은 질적 변수와 양적 변수 사이에도 존재합니다. 질적 변수와 양적 변수의 상호작용은 이해하기 쉬운데, 3.3.1에서 봤던 신용카드 데이터셋으로 양적 변수인 수입과 질적 변수인 학생 여부 두 변수를 사용하여 카드 채무잔액 balance를 예측하여 봅시다.
교호작용 항이 없는 경우 이 모델은 아래의 형태가 되겠죠.
위를 보시면 카드 채무잔액이 학생인 경우와 학생이 아닌 경우 두 경우로 데이터를 학습하고 있는게 보이는데, 학생인 경우와 학생이 아닌 경우는 $\beta_{0}$ + $\beta_{2}$와 $\beta_{0}$로 서로 다른 절편 intercept을 가지고 있습니다. 하지만 같은 기울기 slope $\beta_{1}$을 가지고 있죠.
그림 3.7 신용카드 데이터를 이용한 학생과 학생이 아는 사람들의 수입으로 카드 채무 잔액을 예측한 최소제곱직선. 좌측은 (3.34)를 적합한 모델로 여기에는 수입과 학생여부에 대한 교호작용이 존재하지 않습니다. 우측은 (3.35)모델을 학습시킨것으로 수입과 학생여부 사이에 교호작용항을 추가시켰습니다.
이걸 그림 3.7의 왼쪽 판낼에서 볼 수 있어요. 두 직선이 평행한 이유는 수입이 증가함에 따라 채무잔액의 변화 정도가 학생 여부에 상관없이 동일하기 때문입니다(쉽게 말하면 기울기가 같다). 하지만 실제로는 수입에 변화가 생기면 학생과 학생이 아닌 경우의 신용 잔액에 영향을 미칠수 있기 때문에 이 모델은 한계가 있다고 볼수 있어요.
이 한계를 (수입과 학생에 대한 가변수를 곱함으로서 모델에 반영시키는) 교호작용 변수를 추가하여 모델에서 고려할수 있게 되는데, 그려면 기존의 모델은 아래와 같이 바뀌게 될 거에요.
그러면 학생인 경우와 학생이 아닌 경우 다른 회귀직선이 만들어 졌습니다. 두 회귀 직선은 서로 다른 절편 $\beta_{0}$ +$\beta_{2}$와$\beta_{0}$을 가지고 있고, 또 서로 다른 기울기 $\beta_{1}$ + $\beta_{3}$ 과 $\beta_{1}$을가지게되요. 이렇게 하여 학생과 학생이 아닌 경우 수입의 변화가 신용 카드 채무잔액에 어떻게 영향을 미치는지를 반영시킬수가 있게 되었습니다.
그림 3.7의 오른쪽 판낼이 모델 (3.35)의 학생 여부에 따른 수입과 채무잔액 사이의 추정한 관계를 보여주고 있습니다. 이 그림을 보면 학생의 기울기가 학생이 아닌 사람들의 것보다 낮은데, 이걸 보면 학생들은 소득이 증가한다고 해도 학생이 아닌사람들 보다는 채무 잔액이 덜 증가한다는 의미가 되겠습니다.
비선형 관계 Non Linear Relationhips
이전에도 이야기 한거지만 (3.19)의 선형 회귀 모델은 입력과 출력 사이에 선형 관계를 가진다고 가정을 하고 있습니다. 하지만 입력과 출력 사이의 실제 관계 true relationship가 비선형일 수도 있습니다. 하지만 선형 회귀를 확장시켜 비선형 관계를 다룰수 있는 간단한 방법으로 다항 회귀 polynomial regression가 있습니다. 차후에는 더 일반적인 환경, 상황에서 비선형 학습이 가능한 복잡한 방법들을 봅시다.
그림 3.8 차량 데이터셋. 다양한 차량들의 mpg(1갤런당 마일)과 마력을 보여주고 있어요. 주황색 직선이 선형 회귀 직선이고, 파란색 커브는 마력의 제곱 항을 모델에 추가하여 선형 회귀 학습한 모델이며, 녹생 커브는 마력의 5제곱을 추가하여 선형 회귀를 한 결과를 보여주고 있습니다.
그림 3.8은 차량 데이터셋에서 구한 차량들의 mpg(1갤런당 마일)와 마력 정보들을 보여주고 있어요. 주황색 적선은 선형 회귀 모델인데, mpg와 마력에는 선형 보다는 복잡한 비선형 관계가 있는걸로 보이내요. 그래서인지 데이터가 커브드 된 형태로 보이고 있습니다. 비선형성을 선형 모델에 반영시키는 간단한 방법은 입력 변수의 변형을 모델에다가 추가시키면 됩니다.
예를 들어 그림 3.8의 점들이 이차적인 quadratic 형태를 보이다보니 이 모델의 형태를 아래와 같이 만들면 더 적합할 거에요.
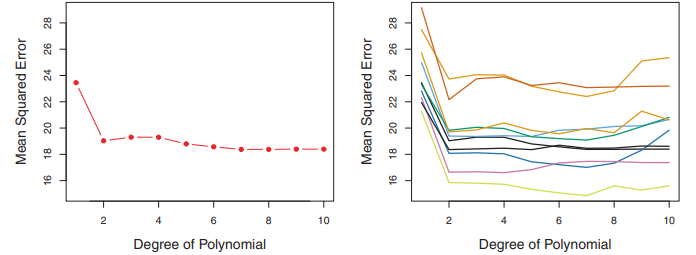
식 3.36은 마력에 대한 비선형 함수로 mpg를 예측하고 있어요. 하지만 이건 여전히 선형 모델입니다! 식 (3.36)은 간단하게 말하자면 $X_{1}$ = 마력, $X_{2}$ = $마력^{2}$인 다중 선형 회귀 모델이라고 할 수 있거든요. 그림 3.8의 파란색 커브는 데이터를 이차적으로 이차 모델로, 적합/학습시킨 결과라고 볼 수 있겠습니다.
그래서 선형 항만 사용하여 학습했을때보다 이차 항을 포함하여 학습했을때 훨씬 좋아질수 있었습니다. 이차 적합 모델의 $R^{2}$는 0.688이고, 선형 학습 모델의 경우 0.606이되며, 유의확률은 표 3.10에서 볼수 있는데, 이차 항의 p value를 보면 이차항이 상당히 유의미하다는 걸 알수 있어요.
표 3.10 자동차 데이터셋. 마력과 마력의 제곱의 mpg에 대한 회귀 모델. 최소 제곱 계수를 추정한 결과
그림 3.8의 녹색 커브는 모델 (3.36)을 5차 다항식까지 차수를 올려 학습시킨 결과인데, 학습 결과가 너무 과하게 데이터와 가까워져 있는것을 볼수 있습니다. 그래서 항상 항을 추가시킨다고 해서 데이터를 학습하는데 도움이된다고는 할순 없습니다.
이런식으로 선형 모델을 비선형적인 관계도 다룰 수 있도록 확장시키는 방법을 다항 회귀 polynomial regression이라 부릅니다. 회귀 모델의 입력 변수로 다항식을 만들었기 때문이거든요. 이 방법과 다른 선형 모델을 확장판들을 7장에서 보겠습니다.
3.3.3 잠재적으로 존재하는 문제들 Potential Problems
우리가 특정한 데이터셋에 선형 회귀 모델을 학습시킨다고 할때, 많은 문제가 발생 할 수가 있어요. 가장 흔한 문제들로 아래의 것들이 있습니다.
1. 입력과 출력사이 비선형 관계
2. 오차항의 상관관계 correlation of error terms
3. 오차항의 상수가 아닌 분산 non constant variance of error terms
4. 아웃라이어 outlier
5. 아주 강한 데이터들(모델이 학습하는 과정에 큰 영향력을 준다고 해석하여 이렇게 적음) High leverage point
6. 공선성 collinearity
현실에서는 이런 문제들이 존재하는지를 찾아내고 극복하는것이 과학의 예술이라 할수 있으며 수많은 책들이 이 주제들을 다루어 왔어요. 선형 회귀 모델은 우리가 다루고자하는 핵심은 아니다보니 중요한 내용들을 간단하게만 보겠습니다.
1. 데이터의 비선형성 Non linearity of the Data
선형 회귀 모델은 입력과 출력 사이에 직선/선형적인 관계를 갖는다고 가정하고 있습니다. 하지만 실제 모델, 실제 관계가 선형이 아닌 경우, 학습한 모델로 구한 모든 예측치/결론들이 잘못되지 않았는가 의심하여야 합니다. 게다가 이 모델의 추정 정확도는 크게 떨어질거에요.
잔차 Residual(실제 측정값 - 예측/추정한 값) 플롯은 비선형성이 존재하는지를 확인하는데 좋은 시작적인 도구입니다. 단순 선형 회귀 모델이 주어지면, 입력 $x_{i}$에 대한 잔차 $e_{i}$ = $y_{i}$ - $\widehat{y}_{i}$를 그려낼수가 있어요. 또 다중 회귀 모델의 경우에는 입력 변수가 다양하다 보니 잔차 플롯에서 입력과 잔차를 사용하는 대신 예측값 $\widehat{y}_{i}$과 잔차를 이용하여 플롯 시킵니다. 이상적으로 모델이 현실과 동일하다면 잔차(실제와모델의 예측의 차이) 플롯에서는 눈에띄는 패턴이 존재하지 않을것입니다. 하지만 패턴이 존재한다면 선형 모델이 어떤 점에서 문제를 가지고 있다는 얘기가 되겠죠.
그림 3.9 잔차플롯 : 자동차 데이터 셋의 잔차와 예측 값을 이용한 그래프. 각 그래프의 빨간 선은 잔처를 학습 시킨 것으로 데이터의 트랜드를 확인하는데 편합니다. 좌측 : 마력에 의한 mpg의 선형 회귀 모델로 잔차가 크다는 것을 보면 이 데이터에 비선형성이 존재한다는 사실을 알 수 있습니다. 우측 : 마력과 마력의 제곱에 대한 mpg를 선형회귀한 모델의 경우로 잔차가 대체로 크지 않은 경향을 보입니다.
그림 3.9의 왼쪽 판낼에서는 차량 데이터셋에서 마력으로 mpg를 선형 회귀한 모델로 만든 잔차 플롯을 보여주고 있습니다. 빨간 선은 잔차를 학습한 것으로 데이터의 트랜드를 더 쉽게 파악하는데 도움이 되는데, 잔차들이 명확하게 U 형태로 존재하는걸 보면 데이터에 강한 비선형성이 있다는것을 알 수 있습니다. 반면에 그림 3.9의 우측 판낼은 이차항이 들어간 모델 (3.36)으로 만든 잔차 플롯이다 보니 잔차가 크지않은 패턴을 보이고 있으며, 이는 이차 항 덕분에 데이터의 학습이 개선되었다는 걸 알 수 있어요.
잔차 플롯으로 데이터에 비선형적인 관계가 존재하는것을 확인했다면, 간단한 방법은 입력 변수를 log X, $\sqrt{X}$, $X^{2}$ 비선형으로 변환하여 사용하면 반영 시킬 수 있습니다. 차후에는 더 개선된 다른 비선형 방법들도 배워봅시다.
2. 오차항의 상관관계 Correlation of Error terms
선형 회귀 모델에서 중요한 가정은 오차항 $\epsilon_{1}$, $\epsilon_{2}$, . . ., $\epsilon_{n}$는 상관관계가 존재하지 않는다는 것입니다. 이게 무슨 소리일까요? 예를 들면 오차가 서로 상관관계가 없다면 오차 항 $\epsilon_{i}$는 다음 오차 $\epsilon_{i+1}$에 대해 아무런 정보를 주지않는다는 말입니다. 표준 오차는 추정된 회귀 계수나 오차항의 비상관성을 따르는 학습 값으로 계산 할 수 있습니다.
하지만 오차항에 상관관계가 존재한다면, 추정된 표준 오차는 실제 표준 오차를 과소추정하는 경향을 가지게 됩니다. 그 결과 계수와 예측 사이의 간격은 더 넓어지게 될거에요. 다시 정리하면 오차 간에 상관관계가 존재할 경우, 오차끼리의 영향으로 오차가 더 강해질 것이고 실제 오차보다 큰 오차가 생기겠죠(실제 오차가 추정 오차보다 훨씬 작아진다). 그래서 추정된 표준 오차가 실제 표준 오차를 과소 추정한다는 말로 보여요.
예를 들어 현실에서 95%의 신뢰 구간을가지고 있어나 실제 값을 그 구간 안에 가질 확률이 95%보다 떨어질 수 있습니다. 게다가 모델의 p value는 기존의 것보다 더 떨어지게 될거에요. 이는 통계적으로 유의미함을 판단하는데 에러를 야기시킬수가 있어요. 정리하자면 오차항이 서로 상관관계를 가질때 우리가 만든 모델을 신뢰할수 없게 됩니다.
구체적인 예를 들면 우리가 가지고 있는데이터가 사고로 2배가 되었다고 해봅시다. 관측과 오차항은 동일하구요. 하지만 이 사실을 무시하여 복사된 데이터의 관측치와 오차항이 동일하지 않다고 하면, 표준 오차를 계산시에 샘플 수가 2n인것 처럼 될것입니다. 또, 이 데이터로 구한 모델의 파라미터 추정치는 2n개의 샘플로 구한것과 n개의 샘플로 구한것이 동일하나 신뢰 구간은 $\sqrt{2}$의 배수(by a factor of)만큼 좁아지게 됩니다
오차항 사이에 왜 상관관계가 발생할까요? 상관 관계가 자주 발생하는 경우가 시계열 time series 데이터인데, 이산적인 시간 간격으로 얻은 관측치들로 이루어져 있습니다. 많은 경우 인접한 시간때 구한 관측치들이 양의 상관관계를 갖는 오차들을 가지게 됩니다.
주어진 데이터셋에서 오차 항에 상관관계가 존재하는지를 판단하기 위해서는 시간 변화에 대한 모델의 잔차를 플롯시켜보면 됩니다. 오차가 상관관계를 갖지 않는 경우 눈에 띄는 패턴이 발생하지 않을 겁니다. 하지만 오차항이 양의 상관 관계를 갖는다면, 잔차 상으로 추적해갈수 있는 무언가가 보이게 되는데, 그게 인접 잔차 adjacent residual로 비슷한 값을 가지고 있을거에요.
다시 말하면 오차가 상관관계를 갖는 경우 시계열 데이터 잔차 플롯 상에서, 오차가 서로 상관되다보니 서로 비슷한 값을 보이는 인접 잔차들이 존재함. 오차항이 상관되지 않다면 인접 잔차가 비슷한것끼리 뭉치지 않고 들쑥날쑥 하겠죠!
그림 3.10 시계열 데이터를 이용한 잔차 플롯. 인접한 시간 데이터의 오차항 상관관계 rho를 서로 다르게 주어 만든 데이터입니다.
그림 3.10의 그림을 보시면 가장 위의 판낼의 경우 상관관계가 존재하지 않는 오차 데이터를 선형 회귀 모델로 학습시킨 경우의 잔차들을 보여주고 있어요. 이 잔차들에는 시간 관련된 어떠한 추세도 보이지를 않습니다. 하지만 바닥의 판낼 잔차들은 인접한 오차들끼리 상관 계수가 0.9 정도 있죠. 그리고, 오차항의 상관 계수가 클수록, 인접 잔차들끼리 비슷한 값을 가지는걸 볼 수 있어요. 마지막으로 중앙의 판낼을 보시면 오차 상관계수가 0.5로 완만한 경우인데, 여기에도 눈에 띄지만 패턴이 덜한걸 볼수 있습니다.
시계열 데이터에 존재하는 오차항의 상관관계를 다루는 많은 방법들이 개발되어 있지만 오차항 사이의 상관관계는 당연히 시계열 데이터 이외에도 존재하죠. 예를 들면 개인의 키로 그 사람의 몸무게를 추정하는 연구를 한다고 해봅시다. 만약 연구에 참여하는 사람들이 서로 같은 가족이거나 식단이 같거나, 같은 환경적인 요소에 노출된다고 하면 오차항끼리 상관관계를 갖지 않는다는 가정이 위반될 수 있겠죠.
일반적으로 오차는 상관관계를 갖지 않는다는 가정은 선형 회귀나 다른 통계적 학습 방법에서 매우 종요하며, 좋은 실험적 설계하기 위해서는 이런 상관관계의 위험을 제거시키는게 중요합니다.
3. 오차 항의 분산이 고정 되지 않았을 때(상수가 아닐때) Non constant Variance of Error Term
선형 회귀 모델에서 다른 중요한 가정은 오차 항은 상수값인 분산 Var($\epsilon_{i}$ = $\sigmia^{2}$)을 가져야 합니다. 선형 모델과 관련있는 표준 오차, 신뢰도 구간, 가설 검정들은 모두 이 가정을 따르고 있어요.
불행히도 오차항의 분산이 변하는 경우도 있습니다. 예를 들면 반응 변수의 값과 함께 오차 항의 분산이 증가하는 경우도 존재합니다. 한 경우에서는 오차들의 분산이 고정되지 않은 경향, 잔차 플롯에서 깔대기 모양으로 보이는 이분산성을 볼수가 있어요.
그림 3.11 잔차 플롯. 각 플롯에서 빨간 선은 잔차를 학습 시킨 것으로 추세를 쉽게 파악하기 위한 선입니다. 파란 선은 잔차의 외부 분위수 outer quantile을 파악하기 위한 선으로 패턴을 강조하고 있어요. 좌측 : 잔차들이 깔대기 funnel 모양으로 있으며 이분산성 hetroscedasticity을 보여주고 있습니다. 우측 : 로그 변환된 출력을 보여주고 있으며 더이상 이분산성이 존재하지 않습니다.
그림 3.11의 왼쪽 그림의 예시를 보시면 잔차들의 크기가 점점 증가하고 있는것을 볼수가 있어요. 이 문제를 만날때 한가지 해결 방법은 출력 Y를 log Y 나 $\sqrt{Y}$같은 함수로 변환시키면 됩니다. 이런 변환을 수행하면 Y의 값이 크게 줄어들어 등분산성을 줄일수가 있어요. 그림 3.11의 우측이 log Y 함수로 출력을 변한시켜 구한 잔차 플롯이에요. 이제서야 상수 분산 constanct variance 혹은 잔차의 분산이 변하지 않는걸 볼수가 있어요.
각 반응, 출력의 분산을 다루는 좋은 방법들이 몇가지가 또 있는데, 예를 들어 i번째 반응, 츌력이 가공하지 않은 관측치 $n_i$의 평균이라고 해요. 각각의 가공되지 않은 관측치들이 분샨 $sigma^{2}$이며 상관 관계를 갖지 않는다고 합시다. 그러면 이들의 평균, 즉 i번째 반응, 출력의 분산은 $\sigma^{2}_{i}$ = $\sigma^{2}$/ $n_i$가 되어 변할수 있죠(상수가 아니다).
이 문제를 해결할수 있는 간단한 방법은 가중화된 최소 제곱법 weighted least squares을 사용하여 모델을 학습 시키면 됩니다. 여기서 가중치를 역분산에 비례하도록 $w_{i}$ = $n_{i}$로 지정하면, 반응 변수의 분산 변동 상쉐되어 사라지게 되겠죠. 그리고 대부분의 선형 회귀 소프트웨어에서 이런 관측치에 대한 가중을 사용할수가 있습니다.
4. 아웃라이어 outliers
아웃 라이어는 예측한 모델로부터 아주 멀리 떨어진 $y_{i}$를 말합니다. 아웃라이어는 다양한 이유로 발생하는데, 데이터 관측 기록이 잘못됫다거나 심각한 노이즈가 발생하거나 그런 이유루요.
그림 3.12 왼쪽 : 이 빨간 직선은 아웃라이어를 포함한 회귀 직선이고, 파란건 아웃라이어를 제거한 뒤 구한 회귀 점선입니다. 중앙 : 아웃라이어를 식별하기 명확한 잔차 플롯입니다. 우측 : 아웃라이어는 스튜던트화된 잔차 studentized residual값으로 6을 가집니다. 이 플롯을 보면서 대채로 값들이 모델로부터 -3과 3범위 사이에 존재하는걸 알수 있어요.
그림 3.12의 왼쪽 판낼의 빨간점(관측 20)이 전형적인 아웃라이엉요. 여기에 최소제곱 회귀로 구한 빨간 직선이 있는데, 파란 점선은 이 아웃라이어를 제거한 후에 구한 선이에요. 아웃라이어를 제거한 경우에는 최소 제곱 직선이 약간 변한걸 볼 수가 있는데, 경사도 크게 변하지 않고, 절편도 약간 줄어들었습니다. 이 경우는 아웃라이어가 최소 제곱법을 이용한 학습 과정에 큰 영향을 주지않는 경우에요.
하지만 아웃라이어가 최소 제곱 학습과정에서 큰 영향을 주지 않더라도, 다른 문제를 발생시킬수도 있습니다. 예를들어 아웃라이어가 회귀 모델에 포함되어있을때 RSE는 1.09가 되며, 제거된 경우에는 0.77밖에 되지 않습니다. 이는 RSE가 모든 신뢰 구간과 p value 등을 고려하여 계산하기 때문인데 하나의 데이터 만으로도 큰 상승이 발생하고, 학습 결과를 분석하는데 영향을 줄수가 있어요. 비슷하게 $R^{2}$도 0.892에서 0.805으로 줄어들었습니다.
잔차 플롯을 이용하면 아웃라이어를 쉽게 식별할수 있습니다. 예를 들면 그림 3.12의 중간 판낼에서 잔차 플롯을 쉽게 볼수 있어요. 하지만 현실에서는 한 점을 아웃라이어로 판단하기 전에 얼마나 많은 잔차들이 필요할지부터 정하는것 부터 어려워요. 이 문제를 해결하기 위해 잔차들을 그대롤 플로팅하기 보다는, 스튜던트화된 잔차를 플롯시킬수 있습니다. 이 스튜던트화된 잔차 값들은 각 잔차 $e_{i}$를 추정된 표준 오차로 나눠서 계산할수 있어요. 스튜던트화된 잔차들의 관측치가 3보다 크다면, 아웃라이어로 볼수 있게 됩니다. 그림 3.12의 우측 판낼을 보면 아웃라이어의 경우 스튜던트화된 잔차가 6을 넘기고 있죠. 반면에 다른 관측치들은 -2와 2사이에 있습니다.
우리들이 아웃라이어가 데이터 수집이나 측정과정에서의 에러 때문에 발생한다고 생각하면, 해당 관측치를 제거하면되니 해결하기는 쉽습니다. 하지만 입력 변수 중 하나로 모델링하지 못해 놓쳣거나, 모델의 부족한 부분을 알려주는 값들일수 있다보니 조심히 다루어야 합니다.
5. 아주 강한/래버리지가 큰 데이터들 High leverage point
방금 $x_{i}$가 주어질때 나오는 흔치 않은 출력 $y_{i}$인 아웃라이어를 봤습니다. 하지만 아웃라이어 말고도 특이한 값을 가지는 래버리지가 큰(모델을 크게 바꿀수 있는) 관측치도 존재해요.
그림 3.13 좌측 : 41번 관측치는 래버리지가 큰 데이터지만, 20번은 아니에요. 빨간선은 모든 데이터릃 학습한 직선이고, 파란색 선은 관측치 41번을 제거한 후 학습한 결과입니다. 중앙 : 빨간색 관측치는 X1이나 X2로 흔한 데이터는 아니지만 데이터들로부터 떨어져있죠. 그래서 래버리지가 큰 데이터가 됩니다. 우측 : 관측치 41번은 래버리지가 크고, 큰 잔차를 가집니다.
예를들어 그림 3.13의 좌측 패널에서 관측치 41번은 매우 큰 래버리지를 가지고 있습니다. (그림 3.13의 데이터들은 그림 3.12의 것과 동일하지만 래버리지가 큰 관측치 하나만 추가하였습니다.) 빨간 직선은 최소제곱법으로 학습한 것이고, 파란색 점선은 41번 관측치를 제거한 후 모델을 보여주고 있습니다. 그림 3.12와 그림 3.13의 좌측 모델을 비교해보면 래버리지가 큰 관측치를 제거하는게 아웃라이어보다 큰 영향을 주는걸 확인할 수 있어요.
래버리지가 큰 관측치는 추정 회귀선에 많은 영향을 끼치는데, 최소 제곱 직선이 이런 관측치들의 영향을 크게 받는다면 일부 데이터때문에 전체 학습이 엉망이 될수 있어 주의하여야 합니다. 그렇다보니 래버리지가 큰 관측치를 찾는게 중요한 일이에요.
단순 선형 회귀에서 래버리지가 큰 데이터는 찾기 쉽습니다. 그저 일반적인 관측치 범위 밖에 있는지 확인하면 되거든요. 하지만 다중 선형 회귀에선 입력 변수가 많다보니 래버리지가 큰 관측치가 개별 입력 변수의 값 범위에는 잘 들어가더라도 데이터셋 전체적으로는 그렇지 않을수도 있습니다.
예를 들면 그림 3.13의 중앙 판낼을 봅시다. 입력 변수가 2개인경우인데, 대부분의 관측된 입력값들이 파란색 점 타원 안에 들어가요. 하지만 빨간색 관측치는 이 범위 밖에 나와있습니다. 하지만 $X_{1}$에도 $X_{2}$에도 속하지 않아요. 만약 여러분이 $X_{1}$혹은 $X_{2}$ 한쪽으로만 봤다면, 이게 래버리지가 높은 데이터인지 찾지 못했을 거에요. 이게 입력 변수가 많은 다중 회귀일 수록 더 어려워 집니다. 데이터의 모든 차원을 동시에 플롯 시킬 쉬운 방법이 없거든요.
그래서 관측치의 래버리지 정도를 수치화하기 위한 방법으로 래버리지 통계량 leverage statistic을 계산하면 됩니다. 이 통계량의 값이 크다면 해당 관측치는 래버리지가 크다는 얘기겠죠. 단순 선형 회귀 모델은 아래와 같아요,
$h_{i}$는 $x_{i}$가 $\bar{x}$로부터 멀면 멀수록 증가하니까 이 방정식을 보면 명확하죠. 그리고 이 $h_{i}$를 입력 변수가 여러개인 경우로 확장한 예시도 있는데, 여기다가 공식은 안올릴게요. 일단 레버리지 통계량 $h_{i}$는 항상 1/n ~ 1사이의 값이 되고, 모든 관측치의 평균 래버리지는 (p + 1)/n가 됩니다. 그래서 주어진 관측치의 래버리지 통계량이 (p + 1)/n을 초과한다면, 래버리지가 큰 데이터가 아닌지 의심해야 합니다.
그림 3.13의 우측 판낼은 좌측 판낼의 데이터로부터 스튜던트화된 잔차와 $h_{i}$의 플롯을 보여주고 있어요.41번 관측치가 큰 래버리지 통계량을 가질 뿐만아니라 높은 스튜던트화 잔차도 가지고 있죠. 다시 말하자면 이 관측치는 아웃라이어인데다가 래버리지가 큰 데이터입니다. 그래서 이 데이터를 포함시키는건 위험할 수 있어요. 그리고 이 그림을 보면 관측치 20번이 래버리지가 낮다보니 최소제곱 적합에 큰 영향을 주지않는걸 알수 있겠습니다.
6. 공선성 collinearity
그림 3.14 신용 데이터셋 관측치 산점도. 좌측 : 나이와 한도의 산점도, 두 변수는 상관관계가 존재하지 않습니다. 우측 : 신용 평가와 한도. 이 두 변수는 강한 상관관계를 가지고 있어요.
공선성은 두 입력 변수가 서로 강하게 상관관계를 가지고 있는 경우를 말합니다. 그림 3.14의 신용카드 데이터셋에서 공선성의 개념을 볼수 있는데, 그림 3.14의 두 입력변수 나이와 한도에는 명확한 관계가 존재하지 않습니다. 하지만 우측 판낼에서는 한도와 신용 평가 사이에 강한 상관관계가 존재하는것을 볼수있는데 이게 다중공선성을 가지고있다고 할수있겠습니다.
공선성은 회귀 시에 문제를 발생시키는데 왜냐면 공선성을 가진 변수들을 따로따로 분리해내기가 힘들거든요. 다시말하면 평가와 한도는 같이 증가하거나 같이 감소하다보니, 따로따로 출력 변수 채무 잔액에 얼마나 연관성을 가지고있는지 판별하기가 어렵습니다.
그림 3.15. 신용카드 데이터셋 회귀 모델의 파라미터 beta에 따른 RSS 윤곽선플롯. 각 플롯의 검은 점이 RSS가 최소가 되는 지점의 계수를 보여주고 있어요. 좌측 : 나이와 한도에 대한 채무 잔액의 회귀모델의 RSS 컨투어플롯을 보여주고 있습니다. 여기서 최저점이 잘 보이고있죠. 우측 : 신용 평가와 한도에 대한 채무 잔액의 RSS 윤곽선 플롯으로 다중공선성으로 인해 RSS값이 비슷한 beta_limit와 beta_rating의 쌍들이 너무 많아요.
그림 3.15는 공선성으로 발생할수있는 어려운 점들을 보여주고 있어요. 그림 3.15의 왼쪽 판낼에는 한도와 나이 사이의 채무 잔액에 대한 회귀 계수 추정들과 이 계수에 대한 (3.22) RSS를 윤곽선 플롯으로 보여주고 있어요. 각 타원들은 해당 계수일때 같은 RSS 값을 가진다는 의미이고, 중앙에 가까운 타원일수록 RSS가 작아지고 있습니다. 검은 점과 이 점에 대한 점선은 RSS가 최저가 되는 계수 추정치를 나타내고 있어요.
한도와 나이에 대한 축은 표준 오차를 고려하여 최소 제곱 추정으로 나올수 있는 추정량들로, 이 플롯이 모두 계수가 될수 있는 값의 경우를 포함시키고 있다고 봐도 되요. 지금 보시는 경우에는 실제 한도 계수가 0.15와 0.20 사이에 있다고볼수 있겠죠.
하지만 그림 3.15의 오른쪽 판낼에는 (강한 공선성을 가진) 한도와 신용 평가 사이 채무 잔액에 대한 회귀 모델의 가능한 계수 추정량들과 그에대한 RSS를 보여주고 있습니다. 윤곽선이 아주 좁은 계곡 처럼 생겼는데, 계수 추장치로 구한 RSS 값의 범위가 매우 넓은걸 볼수 있어요. 그래서 이 데이터가 조금만 변하더라도 계수 추정량이 이 계곡의 어딘가로 이동하게 될겁니다. 그 결과 계수 추정에서 불확실성이 커지게 되요. 여기를 보시면 한도 계수가 -0.2에서 0.2까지 스케일이 나오고 있는데, 한도와 나이제한 모델에서 한도의 계수보다 10배 이상 증가한 샘이죠.
놀랍게도 한도와 신용 평가 계수가 더 큰 불확실성을 가지고 있더라도, 추정한 계수들이 이 계곡의 어딘가 있다는 점이에요. 따로 따로 보면 각 계수가 옳더라도 이 윤곽선 플롯에 따라 우리는 실제 한도 -0.1 그리고 신용 평가 계수가 1은 인 경우는 존재하지 않는다고 볼수 있습니다.
그림 3.11 신용 카드 데이터셋의 다중 회귀 모델의 결과. 모델 1은 나이와 한도를 이용한 채무 잔액 회귀 모델. 모델 2는 신용 평가와 한도를 이용한 채무 잔액 회귀 모델. beta_limit 추정량의 표준 오차는 2번쨰 모델에서 공선성 때문에 12배 정도가 됩니다.
공선성이 회귀 계수 추정량의 정확도를 떨어트리기 때문에 $\widehat{\beta}_{j}$의 표준 오차가 커지게 됩니다. 한번 각 변수의 t통계량이 $\widehat{\beta}_{j}$를 표준오차로 나눠서 구했던걸 떠올려봅시다. 표준 오차가 커지는 만큼 t 통계량은 줄어들갰죠. 그 결과 공선성의 존재로 인해 귀무 가설 $H_{0}$ : $\beta_{j}$ = 0이라는 귀무가설을 기각하지 못하게 될수 있습니다. 이는 가설 검정의 검증력 the power of the hypothesis test(올바르게 0이 아닌 계수를 추정할 확률)가 다중공선성때문에 떨어진다고 볼 수 있어요.
표 3.11은 두 다중 회귀 모델로 얻은 계수 추정량을 비교하고 있습니다. 첫번째 모델은 나이와 한도에 대한 채무 잔액의 회귀 모델이고, 둘째는 신용 평가와 한도에 대한 채무 잔액의 회귀 모델이에요. 첫째 회귀 모델에서는 나이와 한도 둘다 p value가 매우 낮아 유의미한 변수로 보고 있어요.
둘때 모델의 경우 한도와 신영 평가사이 다중공선성이 존재하여 한도 계수 추정량의 표준 오차가 (모델 1 한도의 표준 오차보다)12배 정도 증가하였고, p value는 0.701로 증가하였습니다. 다시 말하자면 한도 변수의 중요도가 다중공선성 때문에 가려지게 됩니다(maked). 그래서 이 상황을 피하기 위해서 모델을 학습하는 중에 공선성 문제가 잠재적으로 존재하는지 파악하고 이를 다루어야 합니다.
공선성을 찾아내는 쉬운 방법은 입력 변수의 상관계수 행렬을 보면 되요. 이 행렬의 한 원소 값이 항당히 크다면 해당 변수들은 강한 상관관계를 가지고 있다고 볼수 있습니다. 불행이도 공선성은 상관계수 행렬만으로는 전부 파악하기는 어렵습니다. 왜냐면 두 변수의 쌍이 높은 상관관계를 갖지 않더라도 3개 혹은 그이상의 변수들사이에 존재할수도 있거든요. 이걸 다중공선성 collinearity이라고 부릅니다.
그래서 상관 계수 행렬을 보기보다 다중공선성을 파악하는 더 나은 방법은 분산 팽창 지수 Varaicne Inflation Factor(VIF)를 계산하면 됩니다. VIF는 $\widehat{\beta}_{j}$의 분산의 비율이며 VIF에서 가장 낮은 값은 1로, 이 경우 다중 공선성이 존재하지 않게 되요. 하지만 현실에서 입력변수들은 약간씩의 공선성을 가지고 있어요. 원칙적으로 VIF가 5 ~ 10을 넘는다면 공선성의 위험이 있다고 볼수 있겠습니다.
각 변수에 대한 VIF는 아래의 공식으로 구할 수 있어요.
여기서 $R^{2}_{X_{j} | X_{-j}}$는 다른 모든 입력 변수로 $X_{j}$를 회귀 시킨 모델의 $R^{2}$인데, $R^{2}_{X_{j} | X_{-j}}$가 1에 가깝다면 공선성이 존재하게 되는 것이고, VIF는 엄청 커지겟죠.
신용 카드 데이터셋에서 나이, 신용평가, 한도의 채무 잔액에 대한 회귀 모델을 구하면 VIF는 1.01, 160.67, 160.59로 이 데이터에 상당히 큰 공선성이 존재하는걸 알 수 있어요.
이런 공선성 문제가 생길때 간단한 해결방법으로 두가지가 있습니다. 첫째는 문제가 발생하는 변수를 회귀 모델에서 제거하면 됩니다. 어짜피 공선성을 가진 다른 변수가 제거한 변수의 정보를 가지고 있기 때문에 크게 고민하지 않고 제거해도 괜찬아요.
예를들면 신용 평가에 대한 변수 없이 나이와 신용 평가의 채무 한도에 대한 회귀 모델을 만든다면 VIF는 1에 가까워 지고, $R^{2}$는 0.754에서 0.75까지 떨어질거에요. 신용 평가 변수를 제거하는것으로 공선성을 효과적으로 제거할수 있겠습니다.
An Introduction to Statistical Learning with Application in R
3.2 다중 선형 회귀 Multiple Linear Regression
단순 선형 회귀는 단일 입력 변수에 대한 반응, 출력을 예측하는대 유용한 방법입니다. 하지만 실제 환경에서는 입력 변수가 한개인 경우보다는 여러 개인 경우가 많겠죠. 예를들면 광고 데이터에서 우리는 TV 광고 예산과 판매량 사이의 관계만을 다루었지만, 라디오와 신문 광고 예산에 대한 데이터도 가지고 있습니다. 그래서 이 나머지 데이터와 판매량 사이 관계를 알고 싶을수도 있어요. 어떻게 두 반응 변수를 추가하여 분석을 할수 있을까요?
표 3.3 광고 데이터에 대한 단순 선형 회귀 모델들. 단순 선형 회귀 모델들의 계수들이 있어요. 위 표 : 라디오 광고 예산과 판매량 사이의 관계, 아래의 표 : 신문 광고 예산과 판매량 사이의 관계를 보여주고 있습니다. 라디오 광고비를 1000달러 올릴 경우 판매량이 203개가 증가하였고, 신문의 광고 예산이 그만큼 증가한경우 판매량이 55개가 올랐습니다. 여기서 판매량은 1당 1000개를 의미하고 있습니다. 달러의 경우 1당 1000달러구요.
한가지 방법은 단순 선형 회귀를 3개로 나누어서 각각 할수도 있겠습니다. 예를 들자면 라디오 광고비에 따른 판매량을 예측하는 선형 회귀 모델을 적합 할 수있겠죠, 그 결과는 표 3.3의 위에 표에서 볼수 있습니다. 라디오 광고비를 1000달러 증가시킨 결과 판매량이 203개가 증가하였습니다. 표 3.3의 아래 표에는 신문 광고 예산으로 판매량을 추정하는 단순 선형 회귀 모델의 최소 제곱법으로 구한 계수들을 보여주고 있습니다. 신문의 경우 광고 예산이 1000달러가 증가할때 판매량이 약 55개 정도가 증가하였죠.
하지만 각 입력 변수 마다 나누어서 단순 회귀 모델을 학습시키는 방법은 만족스럽지는 않습니다. 우선 보면 각각의 광고 예산들을 각각의 회귀 모델과 연관되어있다보니. 세 광고 매채 비용이 주어질때 단일한 판매량을 예측하는 방법이 명확해 보이지가 않습니다. 두번째는, 각각의 회귀 방정식들은 다른 두 미디어를 무시하고 회귀 계수를 추정하였습니다. 만약 매체 광고 예산이 서로 상관관계가 있다면, 각 미디어들의 영향력으로 인해 판매량에 대한 추정량을 잘못 구해질 수도 있을 겁니다.
그래서 개별적인 단순 회귀 모델로 학습하는게 아니라, 더 나은 방법은 식 (3.5)의 단순 회귀 모델을 확장시켜 여러개의 입력 변수를 다룰수 있는 다중 회귀 모델로 확장하는것입니다. 우리는 그냥 단일 선형 회귀 모델에다가 각 입력 변수와 기울기 계수들을 각각 추가하면 만들수 있어요. 일반적으로 p개의 서로 구분되는 입력변수가 있다고 가정할때 다중 선형 회귀 모델 multiple linear regression model은 아래의 형태가 된다고 할수 있겠습니다.
여기서 $X_{j}$는 j번째 입력 변수, $\beta_{j}$는 해당 변수와 반응 변수 사이의 연관성 정도를 나타냅니다. 우리는 $\beta_{j}$를 (다른 모든 입력 변수들이 고정되었다고 할때) $X_{j}$가 한 단위 증가할때 Y에 대한 평균적인 영향정도로 생각하면 됩니다. 그러면 광고 예시는 식 (3.19)를 이용해서 아래와 같이 정리 할 수 있어요.
3.2.1 회귀 계수들을 추정해보자 Estimating the Regression Coefficients
단순 회귀 모델을 다루었을때 처럼, 식 (3.19)에서의 회귀 계수 $\beta_{0}$, . . . , $\beta_{p}$들도 알수 없다보니 이 값들을 추정해 내야 합니다. 그래서 추정값들 $\widehat{\beta}_{0}$, . . ., $\widehat{\beta}_{p}$이 주어진다면 아래의 식을 이용해서 반응 변수의 예측치를 만들수가 있어요.
위 파라미터는 단순 선형 회귀에서 봤던것 처럼 똑같이 최소 제곱법으로 추정을 하는데, 우리는 제곱 잔차 합 sum of squared residuals를 최소화 시키는$\beta_{0}$, . . . ,$\beta_{p}$들을 구하면 되겠습니다.
식 (3.22)를 최소화 시키는 $\beta_{0}$, . . . ,$\beta_{p}$들은 최소 제곱법으로 구한 다중 선형 회귀 모델의 추정 계수값들이라고 할수 있어요. 식 (3.4)에서 본 단순 선형 회귀 추정량들과는 다르게, 다중 회귀 계수 추정량들은 조금 복잡한 형태를 가지고 있어, 행렬 대수 matrix algebra 그러니까 행렬 표현을 사용하여 좀더 간편하게, 쉽게 나타낼수가 있어요. 복잡하다보니 여기다가는 적지 않을거고, 다른 통계적 소프트웨어 패키지들은 이런 계수 추정치들을 계산할 수 있으니 이 챕터 뒤에 R로 어떻게 되는지 한번 봅시다.
그림 3.4 2개의 입력 변수(특징)과 1개의 반응변수(출력)이 주어지는 3차원 환경에서, 최소 제곱법으로 구하던 회귀 직선이 여기선 평면으로 되었습니다. 이 평면은 각각의 관측치(빨간 점)과 이 평면 사이의 제곱 수직 거리의 합을 최소화 시키는 평면이에요.
그림 3.4는 p = 2 인경우 ( 입력 혹은 특징이 2개인 경우) 토이 데이터셋, 연습용 데이터셋을 최소 제곱법으로 학습 시킨 예제를 보여주고 있습니다.
표 3.4 광고 데이터에서의 최소 제곱법을 이용한 다중 회귀 모델의 계수 추정량들. 라디오, 티비, 신문 광고 예산에 따른 판매량 변화.
표 3.4는 다중 회귀 모델의 계수 추정량들을 보여주고 있습니다. 이 회귀 모델은 광고 데이터를 사용해서 제품 판매량을 추정하는데 쓸수 있어요. 이 결과를 다음과 같이 해석할수 있겠습니다. TV, 신문 의 광고 비가 정해지고, 라디오 광고 예산을 1000달러 늘릴때, 판매량이 약 189개 정도 증가한다고 합니다.
표 3.1과 3.3에서 본 계수 추정량들을 비교해봅시다. 그러면 우리는 다중 회귀 계수 추정량들이 TV와 라디오는 단순 선형 회귀 모델에서 했던것과 거의 비슷한걸 알수 있어요. 하지만 신문에 대한 회귀 계수 추정량은 표 3.3에서는 0에 덜 가까운 편이었으나 다중 회귀 모델에서 신문의 회귀 계수 추정량을 보면 0에 가까워진것을 볼수 있으며 p-value가 0.8599로 더이상 의미없는 값이 되었습니다.
------
*가설 검정과 p value
가설 검정은 통계학에 나오는 내용으로 제가 아는 정도로 정리하겠습니다. 우선 p-value는 유의 확률 = 한계 유의 수준으로 귀무 가설을 대립할지 기각할지 여부를 결정할때 사용하는 값입니다. p value가 낮은 경우 귀무가설 $H_{0}$을 기각하고, 대립가설을 채택하는데 이 상황에서 대립가설은 입력 변수 X와 출력 변수 Y는 서로 상관 관계가 존재한다는게 대립가설이었어요. 보통 p value가 0.05?인가 이 정도를 기준으로 이보다 작으면 귀무 가설을 기각하고, 아닌 경우 귀무가설을 채택하게 됩니다.
신문을 제외한 다른 변수들의 경우 p value가 매우 작으므로 귀무 가설(각 입력 변수와 Y는 상관관계를 갖지 않는다)을 기각하여, 상관 관계가 있음을 검정하였습니다. 하지만 신문의 경우 유의 확률이 매우 크므로 귀무가설을 채택하게 됩니다. 세 입력을 사용하는 경우 신문은 Y를 추정하는데 유의미한 영향을 주지않는다고 볼수 있어요.
--------
이것은 단순 선형 회귀 계수와 다중 회귀 계수가 달라질수 있다는걸 보여주고 있어요. 이 차이점은 단순 회귀에선 TV와 라디오 같은 다른 입력 변수를 무시한채, 기울기항이 신문 광고 예산을 1000 증가시킬때의 평균적인 효과의 정도를 나타낸다는 사실에서 비롯되었습니다. 반대로 다중 회귀에서는 신문의 계수는 TV와 라디오를 고정 시킨 상태에서 신문의 광고 비용을 증가시킬때 평균 영향을 나타내고 있어요. (정리하면 단순 회귀에서는 타 항의 영향력이 존재하지 않아 0이아닌 값이 나왔지만, 다중 회귀에서는 타 항의 영향을 받아 0에 가까운 값이 나왔다는 소린것 같습니다.)
표 3.5 TV, 광고 데이터에서의 라디오, 신문, 그리고 판매량 사이의 상관계수 행렬
다중 회귀 문제에서 판매량과 신문 사이에 아무런 상관관계가 없다는 것이 말이 되는것일까요? 단순 회귀문제에서는 상관 관계가 있었음에두요. 표 3.5에 있는 세 입력 변수와 반응 변수의 상관계수 행렬 correlation matrix를 생각해봅시다. 여기서 라디오와 신문의 상관계수가 0.35인것을 볼수 있어요. 이것으로 라디오 광고 예산을 늘리는 시장에서 더 많이 신문 광고를 하는것을 보여줍니다.
이번에는 다중 선형 회귀 모델이 올바르게 만들어 졌고, 신몬 광고가 판매량에 영향을 주지 않는다고 해봅시다. 하지만 라디오 판매량은 여전히 증가하고 있어요. 라디오 광고 예산을 더 많이 할수록 판매량은 더 증가하게 될것이고, 공분산 행렬은 우리가 신문 광고 또한 더 많이 하는 경향이 있는 것을 보여줘요.
그래서 신문 광고가 실제 판매량에 영향을 주지 않았음에도 신문과 판매량만 보는 단순 선형회귀에서는, 신문과 판매량이 큰 상관 관계를 가지는것 처럼 보이게 된거죠. 그래서 신문 광고에 따른 판매량은 라디오 광고에 따른 판매량의 일부가 되어, 신문은 라디오에 의한 영향이 판정받습니다.
* 좀 정리하기가 이상한데, 라디오에 의한 판매량이 증가함에 따라, 신문에 의한 판매량도 증가함. 그래서 신문 자체에 의해 판매량이 증가하는건 크지 않음. 으로 이해가 된다. 억지스럽긴한데
이 사소한 직관에 어긋나는 결과는 실제 상황에서 매우 흔하게 일어납니다. 한번 어의없는 예시로 생각해봅시다. 일정 기간 동안 해변가에서 상어의 공격과 아이스크림 판매량 사이 회귀 모델을 만들었는데, 이 모델이 양의 상관관계를 보일수도 있습니다. 신문 광고 예산과 판매량 사이 관계를 봤던것 처럼요. 하지만 상어들의 공격을 줄이기 위해 아이스크림을 금지해야한다는 사람은 아직까지는 없습니다.
현실에선 날이 더우면 사람들이 해변에 방문하게 만들고, 이것 때문에 아이스크림 판매량이 늘고, 상어의 공격이 늘어나는 것임에두요. 상여의 공격과 아이스크림 판매량 그리고 온도에 대한 다중 회귀를 이용하면, 온도, 이전의 입력 변수 상어의 공격이 크게 중요하지 않다는것을 알수 있게 되요.
3.2.2 중요한 질문들
그러면 우리가 다중 선형 회귀를 할때 다음의 질문들을 할수 있을것 같아요.
1. 반응을 예측하는데 유용한 입력 변수, 특징들 $X_{1}$, $X_{2}$, . . .,$X_{p}$가 적어도 1개는 존재하나요?
2. 모든 입력 변수가 Y를 설명하는데 사용할수 있나요? 아니면 유용한 입력 변수 일부만 사용할 수 있나요?
3. 다중 선형 회귀 모델이 데이터를 얼마나 잘 적합하고 있나요?
4. 입력 값딜이 주어질때, 우리가 예측해야하는 반응값은 무엇이고, 예측치는 얼마나 정밀해야하나요?
각 질문들을 생각해봅시다.
질문 1 : 입력 변수와 반응 변수 사이 관계가 존재하나요?
단순 선형회귀를 다시 생각해봅시다. 여기서는 입력 변수와 반응 변수 사이에 관계가 존재하는지 아닌지 알기위해, $\beta_{1}$ = 0인지 확인하였었습니다. 다중 회귀 문제의 경우 p개의 입력변수가 있으니 우리는 모든 회귀 계수들이 0인지 $\beta_{1}$ = $\beta_{2}$ = . . . = $\beta_{p}$ = 0확인하면 됩니다. 가장 간단한 선형 회귀 모델에서는 우리는 가설 검정 hypothesis test를 사용하여 이 질문(가정)에 대한 답을 구하였는데요. 다음의 귀무 가설 null과
아래의 대립 가설 alternative를 사용하여 검정하겠습니다.
이 가설 검정은 F 통계량 F-statistic으로 할수 있어요.
만약 선형 모델의 가정이 옳다면,
주어진 귀무가설 $H_{0}$이 참인 경우 아래가 성립합니다.
하지만 반응 변수와 입력 변수간에 상관관계가 존재하지 않을때는 F 통계량은 1에 가까운 값이 됩니다. 반대로 $H_{a}$ 가 참인 경우에는(입력 변수들과 반응 변수 간에 상관관계가 존재하는 경우), E{(TSS - RSS)/p} = $\sigma^{2}$가 되며, F는 1보다 큰 값이 됩니다.
F 통계량은 표 3.6에서 라디오, TV, 신문으로 판매량을 회귀하는 다중 선형 회귀 모델로 구할수 있습니다. 여기서 F-통계량은 570으로, 이 값은 1보다 훨씬 크기 때문에, 귀무가설 $H_{0}$는 기각하게 되요. F 통계량이 아주 크게 나왔다는것은 적어도 광고 매체들 중 적어도 1개는 판매량과 관계를 가진다는것을 보여주고 있습니다.
하지만 왜 F 통계량이 1에 가까워져야하나요? 그리고 $H_{0}$를 기각하여 관계가 있는지 결론짓기전에 F 통계량은 얼마나 커야 할까요? 이것에 대한 대답은 관측치의 갯수 n과 입력 변수의 갯수 p에 달려 있습니다. n이 클떄는 F는 1보다 약간 커다보니 $H_{0}$을 채택하게 될 수도 있습니다. 그래서 귀무가설 $H_{0}$을 기각하기 위해선 아주큰 F 통계량이 필요하며 n은 작아야 합니다.
표 3.6 광고 데이터에서 TV, 뉴스, 라디오 광고 예산과 판매량에 대한 회귀 모델의 추가적인 정보들. 이 모델에 관한 다른 정보는 표 3.4에 있다.
$H_{0}$가 참이고, 오차항 $\epsilon_{i}$가 정규 분포를 따를때 F 통계량은 F 분포를 따르게 됩니다. 어느 n과 p 값이 주어질때 통계 소프트웨어 패키지로 F 분포를 사용하여 F통계량과 관련된 p value를 계산할 수 있습니다. 우리는 이 p value를 이용하여 귀무 가설을 기각할지 말지를 정하는데, 광고 데이터의 경우 표 3.6에서 F통계량과 연괸된 p value는 반드시 0이 되어야 하며, 적어도 매체 중 하나가 판매량 증가에 영향력을 가진다는 사실을 강하게 증명 할 수 있습니다.
[F 통계량에 관한 추가적인 내용은 생략]
2. 중요한 변수들을 선택하자
이전 섹션에서 예기했다시피 다중 회귀 분석에서 첫 번째로 할 일은 F통계량을 계산하고 p value를 확인하는것입니다. p value를 통해서 적어도 하나의 입력 변수가 반응 변수와 연관성이 있는것을 검증하였다면, 그 다음으로 할 일은 그 변수가 어느것인지 찾아내야겠습니다. 표 3.4에서 각각의 p value들을 확인할수도 있습니다. 하지만 얘기했던 데로, p(p value가 아니라 특징, 입력개수 p)가 크다면 잘못된 발견을 할수도 있습니다.
모든 입력 변수들이 반응 변수와 연관되는게 가능하지만 입력 변수 중 일부에만 반응 변수가 연관되는 경우가 더 많습니다. 단일 모델에 다른 변수들을 포함하여 학습 할수 있도록, 반응 변수에 연관되는 입력 변수를 찾는 것을 변수 선택 variable selection이라고 부릅니다. 변수 선택 문제는 6장에서 깊이 다룰것이므로 여기서는 고전적인 방법으로 간단하게만 보겠습니다.
이상적로, 서로 다른 입력 변수들로 이루어진 다양한 모델로 변수 선택을 할수도 있습니다. 예를 들어 p = 2라면 다음의 4 모델의 경우를 생각해볼수 있어요. (1) 모델이 입력 변수를 갖지 않는다. (2) 모델이 $X_{1}$만 갖는다. (3) 모델이 $X_{2}$만 갖는다. (4) 모델이 $X_{1}$, $X_{2}$ 둘다 갖는다.
그러면 어떻게 어떤 모델이 최고인지 알수 있을까요? 다양한 통계량들이 모델의 품질을 판단하는데 사용할수 있겠습니다. 이런 것들로 말로우의 $C_{p}$, 아카이케 정보 기준(Akaike information criterion; AIC), 베이지안 정보 기준(Bayesian information Criterion), 그리고 조정된 결졍계수 $R^{2}$가 있습니다. 이들에 대해서는 6장에서 자세히 다룰것이고, 다양한 모델들을 직접 그려서 결정할 수도 있겠습니다.
불행히도 p개의 변수들을 가지고 있는 경우, 총 모델은 $2^{p}$가 있다보니, 모든 가능한 입력 변수들의 부분집합 모델들을 사용할수 없습니다. 예를들어 p = 2인 경우 $2^{2}$ = 4로 해볼수는 있겠지만 p = 30인 경우 $2^{30}$ = 1,073,743,824개의 모델들을 고려해야합니다! 이건 정말 실용적이지 못한것이니 p가 너무 작은게 아니라면 $2^{p}$개의 모델을 고려해볼수가 없습니다. 대신 적은 입력변수로 이루어진 모델을 구하는 효율적이고, 자동화된 방법이 필요합니다. 이를 위한 3가지 고전적인 방법들이 있어요.
- 전진 선택법 Forward Selection : 널 모델 null model에서 시작합니다. 널 모델은 입력 변수 없이 절편만 가지고 있어요. 그리고 p개의 단순 선형 회귀를 해보고, 그 중에서 RSS가 가장 낮은 변수를 널 모델에다가 추가 합니다. 그다음 변수를 반복해서 추가하는 식이에요. 어느 기준에 도달할떄까지 반복하게 됩니다.
- 후진 선택법 backward selection : 우선 모든 변수를 가진 모델에서 시작하는데, 가장 큰 p value를 가진 변수를 제거해요. 가장 큰 p value를 갖는 변수는 통계적으로 덜 중요한 변수겟죠. 그 다음 변수가 (p - 1)개인 모델을 학습하고 가장 큰 p value를 제거합니다. 이를 지정한 기준까지 반복하게 됩니다.
- 혼합 선택법 mixed selection : 전진 선택법과 후진 선택법을 혼합한 방법으로, 전진 선택법처럼 처음에는 변수가 없는 모델에서 시작하고, 최적의 변수를 추가합니다. 이를 한 번 한번씩 추가해나가요. 그러다가 새 변수가 모델에 추가되었을때 p value가 커질수 있는데 이때 임계치를 넘은 경우 모델에서 제거합니다. 이런 전진과 후진을 모델이 p value가 낮은 변수들로만 이루어질떄까지 계속합니다.
후진 선택법은 p > n 경우에사용 할수 없고, 전진 선택법은 항상 사용할 수 있습니다. 그리고 전진 선택법은 탐욕적 방법 greedy approach로 처음에 포함시킨 변수가 후에 필요없어 질수도 있습니다. 그래서 혼합 방법이 이 문제를 개선해 줍니다.
그림 2.1 광고 판매량 데이터셋. 이 그래프에서는 TV, 라디오, 신문 광고 예산을 썻을때 판매량을 보여주고 있습니다. 각 그래프에서 보여주고 있는 직선은 판매량을 이용하여 최소 제곱법으로 적합시켜 구한 것인데요. 이 내용은 3장에서 다뤄보겠으나 파란 직선들은 각 매채 광고비를 입력으로 주었을때, 판매량을 예측하는 간단한 모델입니다.
An Introduction to Statistical Learning with Application in R
3. 선형 회귀 Linear Regression
이번 장에서는 지도 학습 중 한 방법인 선형 회귀 Linear Regression에 대해서 배워보겠습니다. 선형 회귀는 양적 반응을 구하는데 유용한 도구라고 할수 있는데요. 오랫 동안 사용되기도 했고 수많은 책들의 주제로 다루어져 왔습니다. 이 방법이 이후 챕터에서 다룰 다른 현대적인 통계적 학습 기법과 비교해서 좀 지루할 수도 있겠지만, 이 방법은 여전히 유용하며 통개적 학습 기법에서 널리 사용되고 있습니다. 게다가 이 방법에 기반해서 더 나은 방법들이 나오고 있어요. 차후에 선형 회귀를 개선한 다른 통계적 학습 기법을 보게 되실겁니다.
결과적으로 더 복잡한 학습 방법을 배우기 전에 선형 회귀를 이해하는것은 매우 중요한 일이라고 볼수 있겠습니다. 이번 장에서는 선형 회귀 모델의 핵심 아이디어와 이 모델을 학습시키는데 사용되는 최소제곱법 least square에 대해서 배워봅시다.
한번 2장의 광고 데이터를 다시 떠올려봅시다. 그림 2.1에서는 TV, 라디오, 신문 매체의 광고 예산에 따른 특정 제품의 판매량을 보여주고 있었죠. 우리가 통계 분석가라고 생각해보고, 이 데이터를 이용하여 어떻게 내년에 광고를 하면 더 많은 제품을 판매할 수 있는지 생각해봅시다. 그러면 어떤 정보들이 판매량을 높이는데 도움이 될가요? 한번 이런 질문을 해봅시다.
1. 광고 예산과 판매량 사이에 어떤 관계가 있을까요?
우리의 첫번째 목표는 주어진 데이터, 광고 예산과 판매량 사이 상관관계가 존재하는지 알아내어야 합니다. 이 관계가 약하다면 광고할 필요는 없겟죠!
2. 광고 예산과 판매량 사이에는 얼마나 강한 관계가 있을가요?
광고 예산과 판매량 사이에 관계가 있다고 해봅시다. 그리고 여러분들은 이 관계가 강한지 알고싶다고 해요. 특정한 정도의 광고 예산이 주어질때 우리들은 판매량이 어떻게 될지 정확하게 예측 할수 있다면? 광고 예산과 판매량 사이에 강한 관계가 있다고 할 수 있을겁니다. 광고 지출에 따른 판매량 예측 값이 그냥 임의로 추정한 판매량과 큰 차이가 없다면? 이 경우에는 관계가 약하다고 불수 있겠습니다.
3, 판매량에 영향을 주는 매체는 어떤게 있을까요?
세 광고 매채, TV, 라디오, 신문이 판매량에 영향을 줄까요? 아니면 하나 혹은 두개의 매체만 영향을 미칠까요? 이 질문에 대한 대답을 구하기 위해선, 우리는 각 매체의 영향력을 나누어서 보아야 합니다.
4. 우리가 추정한 각 매체의 판매량에 대한 영향력이 얼마나 정확할까요?
특정 매체로 광고 비용이 증가할수록, 판매량이 얼마나 증가하게 될까요? 우리가 예측한 대로 판매량이 정확하게 증가되었나요?
5. 얼마나 정확하게 미래 판매량을 예측할수 있습니까?
특정한 정도의 TV, 라디오, 신문 광고 예산이 주어질때 판매량을 예측할수 있을까요? 그러면 그 예측이 얼마나 정확합니까
6. 매체와 판매량 사이 관계가 선형적인가요?
각 매채별 광고 지출과 판매량 사에 선형적인 관계가 있다면, 선형 회귀가 좋은 도구로 사용될 수 있습니다. 그렇지 않다면 선형 회귀를 사용 가능하도록 입력이나 출력의 현태를 변환 시킬 수도 있습니다. (* 저스틴 존슨 교수님의 컴퓨터 비전 5강 신경망에서 공간 변환을 통해 선형 분리를 하는 내용이 있었는데, 선형적 관계가 아닌 데이터를 변환을 통해 선형적인 관계로 구할수 있다는 의미로 보임)
7. 광고 매체 사이에 시너지 효과가 있었나요? 다른말로 하자면 서로 영향을 주는게 있었나요?
한번 탤래비전에 5만 달러, 라디오에 5만 달러를 쓴 결가 10만 달러 이상의 판매량을 얻었다고 합시다. 티비 광고만 5만 달러, 라디오 광고만 5만 달러치 한것 보다 더 큰 판매량을 얻을수 있었어요. 이 경우를 시너지 synergy 효과라고 할수 있으며, 통계학에서는 상호작용 interaction이라고 부릅니다.
3.1 단순 선형 회귀 Simple Linear Regression
단순 선형 회귀는 이름 그대로를 의미합니다. 입력 변수 X가 주어질때 양적인 반응 변수 Y를 추정하기 위한 매우 직관적인 방법이에요. X와 Y 사이에 선형적인 관계가 있다고 가정해봅시다. 그러면 수학적으로 이 선형적인 관계를 아래와 같이 정리 할 수 있어요.
여기서 $\approx$라는 표기는 우항을 좌항으로 근사시켰다? 좌항은 우항의 근사화된 모델? 우항과 좌항이 비슷하다? 정도의 의미를 가지고 있습니다. 위 (3.1)의 식을 X를 이용해서 Y를 회귀했다고 부르겠습니다. (regression Y on X, Y onto X) 예를 들어 X가 TV 광고 비용이고 Y를 판매량이라고 한다면, 학습된 모델을 통해서 TV 광고 비용으로 판매량을 회귀(양적 변수를 추측)할수 있겠죠.
식 3.1에서 $\beta_{0}$, $\beta_{1}$는 정해지지 않은 상수로, 선형 모델에서 절편(intercept, ex: y절편이라고 부르던 그거)과 기울기(slope)라고 부릅니다. 또 이들을 모델의 계수 coefficient 혹은 파라미터라고 부르기도 해요. 우리가 할 일은 주어진 훈련 데이터를 이용해서 모델의 계수인 $\widehat{\beta}_{0}$, $\widehat{\beta}_{1}$ 추정치를 구하는 것이고, 이 추정된 계수 값으로 TV 광고 예산 값이 주어질때 이 식을 이용해서 예측 판매량을 계산할 수가 있겠습니다.
위 식에서 $\hat{y}$는 X= x가 주어질때, Y의 예측치를 의미해요. 여기서 x, y, z 같은 기호 위에 모자 hat ^을 씌워주는데, 이들은 알수 없는 파라미터, 계수를 추정하여 구한 값을 의미하고 있어요. $\hat_{y}$는 추정한 반응/ 출력 값이라고 할수 있구요.
3.1.1 계수들을 추정해보자 Estimating the Coefficients
현실에서는 $\beta_{0}$, $\beta_{1}$을 알수 없습니다. 그래서 예측 값을 구하려구 식 (3.1)을 쓰기 전에 반드시 주어진 데이터로 이 계수들을 추정해내야 해요. 한번 n개의 쌍으로된 관측치 observation pairs들이 있다고 해봅시다. 각 관측치들 obervations은 X의 측정값(measurement of X(과 Y의 측정값(measurement of Y)으로 이루어져 있어요.
* 측정값 measurement의 경우, 한 변수의 실제 값 $x_{1}$, $y_{1}$같은 변수들의 실제 값이라고 하겠습니다.
* 관측치와 측정 값의 차이는 관측치는 한번 관측을 했을때 얻은 X 측정값들, 혹은 X와 Y의 측정값들의 모음입니다.
다시 광고 예시로 돌아갑시다. 이 데이터는 n = 200(관측치가 200개), 200개의 시장에서의 TV 광고 예산과 그에 따른 제품 판매량으로 이루어져 있어요.(이 데이터들은 그림 2.1에 있는데 이 글 맨 위에 추가해두었습니다!) 우리들의 목표는 $\widehat{\beta}_{0}$,$\widehat{\beta}_{1}$을 구하는 것이 되겠습니다. 식 (3.1)의 선형 모델이 주어진 데이터들을 학습해서 얻은 계수들이요. 그래서 아마 $y_{i}$ $\approx$ $\widehat{\beta}_{0}$ +$\widehat{\beta}_{1}$$x_{i}$, i = 1, . . ., n의 형태로 정리할수 있겠죠.
정리하자면 우리는 200개의 데이터 점에 가능한 가장 가까운 close직선의 절편 $\widehat{\beta}_{0}$와 기울기$\widehat{\beta}_{1}$를 찾는다고 생각하면 되겠습니다. 열마나 가까운지 측정하는 많은 방법들이 있는데, 그중에서 가장 많이 사용하는게 최소제곱법을 이용하여 오차제곱합이 최소화시키는 방법을 사용합니다. 이 방법을 이 장에서 사용해보고 다른 방법들은 6장에서 볼게요.
그림 3.1 위는 광고 데이터, TV 광고비용에 따른 판매량의 회귀모델로 최소 제곱법으로 학습/적합하여 만들었습니다. 이 학습 방법은 오차 제곱합을 최소화시키는 계수를 찾는것입니다. 각 회색 선은 오차를 보여주고 있으며, 학습된/적합된 모델이 오차 제곱의 평균에 위치하고 있습니다. 이 그래프는 다소 결점이 존재하기는 하지만, 선형 모델이 데이터에 관계성이 존재하는 것을 보여주고 있습니다.
그러면 $\widehat{\y}_{i}$ = $\widehat{\beta}_{0}$ + $\widehat{\beta}_{1}$ $x_i$가 X의 i번째 값을 이용해서 Y의 값을 추정한다고 합시다. 그러면 $e_{i}$ = $y_{i}$ - $\widehat{\y}_{i}$ 는 i번째의 잔차(residual)를 의미하며, 여기서 잔차란 i번째 관측된 반응 변수(실제 Y)와 우리가 구한 모델로 예측한 i번째 반응 변수(예측 Y)의 차이를 말합니다. 그러면 잔차 제곱합(RSS; residual sum of squares)를 아래와 같이 정의 할 수 있어요.
그리고 이 식은 아래와 동등하다(equivalent)고 할 수 있습니다.
최소 제곱 방법은 RSS를 최소화 시키는 $\widehat{\beta}_{0}$, $\widehat{\beta}_{1}$를 구하는 방법이에요. 여기서 미분을 사용하면, 이 RSS를 최소화 시키는 두 추정치는 아래와 같이 정리 할 수 있어요.
여기서 \bar{y} \equiv \frac{1}{n} \sum_{n}^{i=1} y_{i}이고, \bar{x} \equiv \frac{1}{n} \sum_{n}^{i=1} x_{i} 으로 샘플들(데이터들)의 평균을 의미합니다. 이를 정리하자면 (3.4)은 단순 선형 모델의 최소 제곱 계수 추정갑 least sqaure coefficient estimate 라고 부릅니다.
그림 3.1은 광고 데이터를 단순 회귀 모델로 적합/학습(fit) 시킨 것으로 , 그 결과 $\widehat{\beta}_{0}$ = 7.03, $\widehat{\beta}_{1}$ = 0.0475가 나오게 되었어요. 이 학습한 모델, 근사 식으로부터 TV 광고비가 1000달러를 씩 증가할 수록, 47.5 정도 제품 판매량이 증가한다는걸 보여주고 있습니다.
그림 3.2 광고 데이터에서 TV 광고비가 입력, 판매량이 Y일때, RSS에 대한 윤곽선 플롯과 3차원 플롯,. 단순 선형 모델의 절편과 기울기 변화에 따른 RSS의 편화를 보여주고 있다.
그림 3.2는 TV 광고비를 입력으로, 판매량을 출력으로 하는 광고 데이터를 사용하여 $\beta_{0}$, $\beta_{1}$의 값 변화에 따라 RSS가 어떻게 되는지 계산한 것을 보여주고 있어요. 두 그래프에서 빨간점은 RSS가 최소가 되는 지점으로 식 (3.4)로 구한 ($\widehat{\beta}_{0}$,$\widehat{\beta}_{1}$)를 의미합니다.
3.1.2 계수 추정치가 얼마나 정확한지 평가해보자 Assessing the accuracy of the coefficient estimates
X와 Y의 실제 관계를 나타내는 식 (2.1) 생각해 봅시다. 이 식은 Y = f(x) + $\epsilon$이었는데, 여기서 f는 우리가 알지 못하는 실제 함수/모델이고, $\epsilon$은 평균이 0인 오차항이었습니다. 그럼 f를 선형 함수/모델로 추정을 했으면 이 식을 아래와 같이 고칠수가 있어요.
전에도 얘기했다시피 $\widehat{\beta}_{0}$은 절편 항, X = 0일때 Y의 기댓값/예측값이 되겠죠, 그리고 $\widehat{\beta}_{1}$는기울기로 X가 커질때 Y가 얼마나 증가하는지를 나타낼겁니다. 오차 항은 이 단순한 모델이 놓치는 모든 것을 나타내요. 실제 함수 모델에서, 실제 관계는 아마 선형이 아닐거고 Y에 변동을 일으키는 다른 영향력들, 혹은 변수같은게 있을거에요. 그게 오차 에러($\epsilon$)로 측정이되어 Y에 반영이 될수 있죠. 그래서 일반적으로 오차 항을 X에 독립이라고 가정하여 식을 새웁니다.
식 (3.5)의 모델을 population regression line 모집단 회귀선이라고 부르고, X와 Y의 실제 관계를 나타내는 최적의 선형 근사 식을 의미합니다. 식 (3.4)의 최소 제곱 회귀 계수 추정값들은 식 (3.2)의 최소 제곱 직선의 특성을 나타낸다고 할 수 있어요. 한번 그림 3.3의 우측 그래프를 보시면, 단순 시뮬레이션된 데이터들을 나타내는 두 개의 직선이 있는걸 볼 수 있어요. 임의로 100개의 샘플 데이터 X들을 생성시켰고, 아래의 모델에 입력하여 각 X에 대한 Y값들도 만들어 내었습니다.
요기서 $\epsilon$은 평균이 0인 정규분포로부터 생성된 오차항, 오차값이라구 할게요. 좌측 그림의 빨간선은 실제 관계 true relationship, 실제 모델인 f(X) = 2 + 3X를 보여주고 있습니다. 반면에 파란색 선은 관측된 데이터를 이용하여 최소제곱법으로 추정해서 구한 선이에요. 실제 함수, 모델, 관계는 보통 알려져 있지 않지만, 최소 제곱선은 식 (3.4)을 따라서 계수 추정치를 구하여 만들수는 있겠죠.
그림 3.3 시뮬레이션 데이터셋. 왼쪽 그림 : 빨간 선은 실제 관계, 모델, 함수 f(X) = 2 + 3X로 모집단 회귀 직선을 보여주고 있습니다. 파란선은 최소제곱선으로 관측된 데이터로 f(X)를 최소제곱 추정한 직선이에요. 우측 그림 : 모집단 회귀선은 빨간색으로 그대로 있고, 다른 최소 제곱 직선들은 다양한 색들로 보여주고 있습니다. 여기서 10개의 최소 제곱 직선이 있는데, 각 직선들은 서로 다른 관측 데이터셋으로 구한 직선들이에요. 이 직선들은 다르지만 평균적으로는 모집단 회귀선에 거의 가깞다고 할수 있겠죠.
이를 정리하자면 실제 상황에서 우리는 관측치 데이터로 최소 제곱 직선을 구할수가 있어요. 하지만 모집단 회귀선은 관측할수는 없겠죠. 그림 3.3의 오른쪽 그림은 식 (3.6)에서 데이터 셋을 10번 샌성 시키고, 이 서로 다른 데이터셋으로 추정한 최소 제곱 직선을 그린것을 보여주고 있습니다. 같은 실제 모델로부터 생성되었지만 서로 다른 데이터셋이 만들어지다보니, 조금씩 다른 최소 제곱 직선들이 만들어 졌어요. 하지만 모집단 전체는 무수히 많고 관측할 수 없다보니 모집단 회귀선은 변하지 않아요.
얼핏 보기엔 모집단 회귀 직선과 최소 제곱 직선 사이 차이가 별로 없어 보이기는 한데, 데이터셋이 하나만 있다고 해 봅시다. 실제 모델의 직선과 데이터셋으로 추정한 직선이 있을것이고, 이 두 직선은 무엇을 의미하는 것일까요? 이 두 직선 중 추정하여 구한 모델은 샘플로 얻은 정보로 큰 모집단의 특성들(모집단 직선)을 추정하는 표준 통계적 방법을 보여준다고 할수 있을것 같습니다.
예를들어봅시다. 여러분들이 임의의 확률 변수 Y의 모평균 $\mu$를 알고싶다고 할때, $\mu$는 모르고, Y로 부터 n개의 관측치 $y_{1}$, . . ., $y_{n}$이 있다고 해 봅시다. 그러면 이걸로 모평균 $\mu$를 추정할 수 있겠죠. 그러면 가장 가능성이 큰 추정량은 $\hat{\mu}$ = $\bar{y}$이며, \bar{y} \equiv \frac{1}{n} \sum_{n}^{i=1} y_{i}는표본평균을의미합니다.
표본 평균 sample mean과 모 평균 population mean은 다릅니다, 하지만 일반적으로는 표본 평균이 모 평균을 잘 추정한 값으로 생각할 수 있습니다. 같은 방식으로 선형 회귀에서 알수 없는 계수인 $\beta_{0}$, $\beta_{1}$로 모평균 직선을 그릴수가 있지만, 이 계수는 알수 없으니 식 (3.4)로 $\widehat{\beta}_{0}$, $\widehat{\beta}_{1}$를 추정하면 되고, 이 추정한 계수로 최소 제곱 직선을 정의할수 있겠습니다.
선형 회귀와 확률 변수의 평균을 이용한 추정 사이에 비슷한 건 이들이 편향 bias라는 개념을 기반으로 한다는 점입니다. $\mu$를 추정하기 위해서 $\hat{\mu}$를 한다고 해봅시다. 이 추정량이 편향되어있지 않다면(unbiased), $\mu$는 $\mu$와 동일하다고 볼 수 있습니다. 이게 뭘 의미하냐면, $y_{1}$, . . .,$y_{n}$로 구한 $\hat{\mu}$가 $\mu$보다 크게 추정될 수도 있고, 다른 관측치를 사용한 경우 표본 평균이 모 평균보다 낮게 추정될수도 있습니다. 하지만 아주 많은 관측치로 다양한 추정치들을 얻고, 이들을 평균을 낼수 있으면 모평균과 가까워 지겠죠. 그래서 불편향 추정량 unbiased estimator은 실제 파라미터를 과소, 혹은 과대 추정을 하지 않습니다.
불편성의 성질이 식 (3.4)로 구하는 최소 제곱 추정량에도 적용 되고 있습니다. 우리가 특정 데이터셋로 $\beta_{0}$과 $\beta_{1}$을 추정한다면, 아마 $\beta_{0}$가 $\beta_{1}$에 정확한 추정값을 구하지는 못할 겁니다. 하지만 크고 다양한 데이터셋으로부터 추정값들을 평균을 낸다면, 정확한 값을 구할 수 있겟죠. 그림 3.3의 오른쪽 그래프에서 수 많은 최소 제곱 직선의 평균으로, 서로 다른 데이터셋으로 추정해서 만든, 이 평균이 실제 모 회귀 직선에 아주 가까운 것을 확인하실 수 있겠습니다.
(*지금 보고 있는 내용들은 통계학에서 점추정 관련 내용으로 이전에 관련 내용을 부족하게나마 정리한 적 있음)
임의의 확률 변수 Y의 모평균 $\mu$를 추정하는 문제를 계속 다뤄봅시다. 여기서 이런 질문을 할수 있겠죠? $\mu$를 추정한 $\hat{\mu}$가 얼마나 정확한가요? 우린 조금전에 아주 많은 데이터셋으로 $\hat{\mu}$를 구하고 이들의 평균이 $\mu$에 아주 가깝다는것을 봣엇습니다. 하지만 추정량 $\hat{\mu}$하나 만으로는 모 평균을 $\mu$ 과하거나 과소하게 추정할수 있을겁니다. 그러면 이 추정량 $\hat{\mu}$는 모평균과 얼마나 멀까요? 일반적으로 이 질문에 대한 대답은 $\mu$의 표준 오차 standard error로 구할 수 있습니다. SE($\hat{\mu}$)로 표기하며, 이 식은 아래와 같아요.
위 식에서 $\sigma$는 각 $y_{i}$들에 대한 표준 편차를 의미합니다. 편하게 말하면, 표준 오차 Standard Error는 실제 모평균 $\mu$과 추정량 $\hat{\mu}$가 평균적으로 다른 정도, 다른 크기를 알려준다고 할수 있어요.(표준 오차는 분산의 평균) 식 3.7은 표준 평차가 n에 따라서 얼마나 줄어드는지, 관측치가 많아 질수록, $\hat{\mu}$의 표준 오차가 작아지는것을 알수 있겠습니다.
비슷하게 $\widehat{\beta}_{0}$,$\widehat{\beta}_{1}$이 얼마나 실제 $\beta_{0}$와 $\beta_{1}$과 가까운지 궁금할수 있겠는데, $\widehat{\beta}_{0}$,$\widehat{\beta}_{1}$의 표준 오차는 아래의 식으로 구할수 있겠습니다. 여기서 $\simga^{2}$ = Var($\epsilon$)을 의미해요.
이 공식들이 유효해지려면 각 관측에 대한 오차 $\epsilon_{i}$는 공통 분산 common variance $\sigma^{2}$와 상관관계를 갖지 않는다고 가정하여야 합니다.(공통 분산은 잠시 검색 해봤는데, 인자 분석 관련 용어이긴하지만 이해하기는 힘들어 자세한 내용은 패스).
그림 3.1 TV 광고비용에 따른 판매량의 회귀모델.
그림 3.1에서는 이 가정이 유효하지 않지만(오차도 상관관계에 영향을 주므로), 여전히 잘 추정하는것을 볼 수 있습니다. $x_{i}$가 크게 퍼지면 퍼질수록 표준 오차는 커져야 하겠지만 이 공식에서 SE($\widehat{\beta}_{1}$)는 작아지며,기울기를 추정하는데 더 큰 영향력을 주게 됩니다.
(제가 이해한 바로는 오차가 커질수록 기울기에 대한 표준 오차가 더 커져야 하지만, 위 식에서는 반대로 표준오차가 크게 줄어들어 정확한 기울기를 추정한다는 의미로 보임.)
$\bar{x}$가 0이라면($\widehat{\beta}_{0}$은 $\bar{y}$와 같아질 것임), $SE($\widehat{\beta}_{0}$)는 SE($\hat{\mu}$)와 같아지는 것을 볼수 있습니다. 일반 적으로, 공통 분산 $\sigma^{2}$는 알 수 없지만 주어진 데이터로 부터 추정은 할수 있어요 $\sigma$를 추정한 값을 잔차 표준 오차 residual standard error라고 부르는데, 이 RSE = $\sqrt{RSS/(n - 2}$로 구할 수가 있습니다.
표준 오차는 신뢰구간 confidence interval을 구하는데도 사용되요. 95% 신뢰구간은 실제 파라미터의 값이 95%의 확률로 속한다고 생각되는 값의 범위를 의미합니다. 이 범위는 샘플 데이터로 하한과 상항을 계산해서 구할수 있는데, 선형 회귀의 경우 $\beta_{1}$의 95% 신뢰구간은 아래의 형태를 가지며,
실제 값 $\beta_{1}$을 95%의 확률로 가질 신뢰 구간은 아래와 같습니다.
비슷하게 $\beta_{0}$의 신뢰 구간을 다음의 형태를 가지게 됩니다.
광고 데이터 예시를 보면 $\beta_{0}$의 95% 신뢰 구간은 [6.130, 7.935]이고, $\beta_{1}$의 95% 신뢰 구간은 [0.042, 0.053]이 된다고 할수 있어요. 그러므로 광고를 하지 않는 경우에 판매량이 6,130 ~ 7,940까지 떨어진다고 추정 할 수 있겠습니다. 하지만 텔레비전 광고 비용을 1000달러씩 증가시킨다면, TV 판매량이 평균적으로 42 ~ 53씩 증가하게 될겁니다.
표준 오차는 가설 검정 hypothesis test를 하는데도 사용되고 있어요. 가장 자주 사용하는 검정에서 귀무 가설로 null hypothesis로
음.. 생각하다보니 가설 검정 부분은 다시 복습도 필요하고, 해야될 내용이 많다보니 여기서 생략하겠습니다.
3.1.3 모델 정확도 평가하기 Assessing the Accuracy of the Model
3.12의 귀무 가설을 기각한다면(대립 가설을 채택한다면), 그러니까 X와 Y 사이에 상관 관계가 존재한다면 이 모델이 얼마나 데이터를 잘 적합시키는지 정도를 정량화 하고 싶을 겁니다. 선형 회귀 모델의 적합 성능은 잔차 표준 오차 Residual Standard Error(RES)와 상관계수 $R^{2}$ 통계량으로 평가할 수 있습니다.
표 3.2 최소 제곱법으로 구한 모델에 대한 추가 정보들(TV 광고와 판매량 데이터)
표 3.2에서는 (TV 광고와 판매량 데이터에 대한) 선형 회귀 모델의 RES와 $R^{2}$ 통계량, 그리고 F 통계량(3.2.2에서 설명함)을 보여주고 있어요.
잔차 표준 오차 Residual Standard Error
식 (3.5)의 모델로 돌아가서 생각해봅시다. 거기에는 오차항 $\epsilon$이 있엇죠. 그리고 이 오차항 때문에, 실제 회귀 직선을 알고 있어도, X가 있어도 완벽하게 정확한 Y를 구할수는 없었어요. RSE는 오차항 $\epsilon$의 표준편차 추정량이라고 할 수 있습니다.
실제 회귀 직선을 이용하여 구하는 평균 값이라고 할수 있는데, 아래의 식으로 계산 할 수 있어요.
식 3.1.1에서 RSS를 정의했었는데, 이를 다음의 식으로 줄수 있겠습니다.
광고 데이터 예시에서, 표 3.2를 보면 RSE가 3.26이었죠. 이는 실제 회귀 직선으로부터 각 마켓당 판매량의 차이가 평균적으로 3,260개 정도된다는 뜻이 됩니다. 다른 방법으로 생각해봅시다. 모델은 정확하고, 모델의 계수 $\beta_{0}$, $\beta_{1}$이 뭔지 안다고 해볼 게요. 그렇더라도 TV 광고 시 판매량 예측 치는 평균적으로 약 3,260개가 차이가 나게 될겁니다. 3,260개의 예측 오차가 받아들일만한지 아닌지는 이 문제의 상황에 따라 달라지겠죠. 이 광고 데이터셋의 경우 전체 시장에서의 판매량 평균은 14,000개 정도가 되니 오차 퍼센트가 3,260/14,000 = 23%나 됩니다.
RSE는 식 (3.5) 모델이 데이터에 잘 적합했는지 아닌지 적합 결함 정도를 측정하는데 사용할 수 있습니다. 이 모델로 구한 예측치가 실제 출력값과 매우 가깝다면 $\widehat{\y}_{i}$ $\approx$ $y_{i}$, i = 1, . . ., n 이라면 (3.15)는 아주 작아질것이고, 모델이 아주 잘 학습/적합했다고 할수 있겠습니다. 하지만 $\widehat{\y}_{i}$가 실제 $y_{i}$랑 멀다면, 그것도 여러 관측치에서 그러면 RSE는 큰 값이 나올것이고, 모델이 잘 학습했다고 할수 없을 거에요.
$R^{2}$ 통계량 $R^{2}$ Statistic
RSE는 모델이 적합 결함 정도의 절댓값을 알려주는데 absolute measure of lack of fit, 조금 고쳐서 적자면, 적합이 부족한 정도 알려준다. 하지만 항상 RSE가 좋은 건아니에요. $R^{2}$ 통계량도 잘 적합되었는징를 알려주는데, 비율의 형태로 설명할수 있는 분산의 정도 the proportaion of variacne explained를 알려주며, 0 ~ 1사이의 값을 가지고 Y의 스케일에 독립이라고 할수 있습니다.
$R^{2}$ 값은 아래의 식으로 계산할 수 있어요.
위 식에서 TSS = \sum ($y_{i}$ - $\bar{y}$ $)^2$으로 총 제곱합 Total sum of squares이고, RSS는 식 (3.16)에 정의하였습니다. TSS는 반응 변수 Y의 총 변동 Total Variance을 측정한 갑으로, 데이터들이 가지고 있는 변동성의 크기라고 할수 있어요. 반대로 RSS는 회귀를 한 후에 남은 설명 할 수 없는 변동의 크기를 의미합니다. 그래서 TSS - RSS는 (총 변동) - (설명 불가 변동) = (설명 가능 변동)으로, $R^{2}$는 입력 변수 X로 Y를 얼마나 설명할수 있는 비율을 측정하는 지표라고 할 수 있습니다. 여기서 설명력 amount of variability/explainability이란 회귀 모델가 실제 모델을 추정할수 있는 정도라고 할수 있을것같아요.
$R^{2}$ 통계량이 1에 가깝다면 회귀로 설명 할 수 있는 비율이 크다 -> 회귀 모델로 값을 잘 추정할 수 있다는 이야기이고, 반대로 0에 가깝다면 회귀 모델이 변동성을 잘 설명 할 수 없다 -> 값을 잘 추정하지 못한다고 할수 있겠습니다. 이런 경우는 선형 모델이 잘못 만들어지거나, 가지고 있는 오차가 너무 큰 경우에 생길수 있어요. 표 3.2에서 $R^{2}$는 0.61로 TV 광고비에 대한 선형 회귀 모델이 판매량에 대해서 2/3정도의 변동을 설명할수 있다고 할 수 있겠습니다.
식 (3.17)의 $R^{2}$ 통계량은 0 ~ 1사이 값으로 나타내다보니 식 (3.15)의 RSE보다 이해하기 쉽다는 장점이 있습니다. 하지만 무엇이 좋은 $R^{2}$인지 찾아내는건 쉽지 않은 일입니다. 사용하는 상황에 따라 달라질 수도 있거든요. 예를들어 물리학 문제에서 잔차가 작은 선형 회귀모델에서 데이터를 얻었다고 해봅시다. 이 경우에는 $R^{2}$ 값이 1에 아주 가깝겟지요. 하지만 $R_{2}$가 엄청 작다면 실험에 무슨 문제가 있다는걸로 볼수도 있어요,
식 (3.5)의 선형 모델은 데이터를 러프하게 근사시키는데 최고이지만, 측정되지 못한 인자/요소들 때문에 잔차 오차가 매우 커질수도 있습니다. 이 경우에는 변동의 아주 작은 일부분만 설명할수 있을 것이고 $R^{2}$는 0.1이하로 떨어 질수도 있어요.
$R^{2}$ 통계량은 X와 Y의 선형적인 관계를 측정하는 값으로 이를 상관계수 Correlation이라고도 부르며 아래와 같이 정의합니다.
$R^{2}$ 대신에 r = Cor(X, y)로 쓸수도 있고, 단순 선형 회귀 문제에서는 $R^{2}$ = $r^{2}$을 사용하기도 합니다. 정리하자면 상관 계수의 제곱은 $R^{2}$ 통계량과 동일하다고 볼수 있어요. 하지만 다음 섹션에서 다중 선형 회귀 문제를 다룰건데, 여기서는 여러 입력 변수들을 동시에 사용하여 반응 변수를 예측할겁니다. 상관계수는 수많은 변수들 사이의 연관성이 아니라 한 쌍의 변수끼리의 연관성을 다루기 때문에, 입력 변수와 반응 변수 사이의 상관관계라는 개념로 확장해서 다룰수는 어렵습니다. 차후 $R^{2}$가 어떻게 이 역활을 하는지 봅시다.
An Introduction to Statistical Learning with Application in R
2.1.5 회귀 문제와 분류 문제 Regression versus Classification Problems
우리가 사용하는 변수들은 양적 변수 quantitative variable 혹은 질적 변수 qualitative 변수(카테고리 변수)로 나눌수가 있겠습니다. 여기서 양적 변수는 사람의 나이, 몸무게, 수입, 집의 가치, 주가 같이 수치 값을 가지는 변수들을 말합니다. 반대로 질적 변수의 경우 K개의 클래스 혹은 카테고리중 하나를 나타내는 변수로 성별(남과 여), 제품 브랜드(A브랜드, B브랜드, C브랜드), 암 진단 결과 여부(음성, 양성)과 같은 예시가 있겠습니다.
이런 양적인 반응 변수를 다루는 문제를 회귀 문제 regression problem이라 무르고, 질적인 반응을 변수로 다루는 문제를 분류 문제 classification라고 부릅니다. 하지만 항상 이런 구분이 명확하다고 할수는 없는데, 최소 제곱법을 이용한 선형 회귀 모델(3장)에서 질적인 변수를 사용할 수도 있고, 로지스틱 회귀(4장)의 경우 2개의 클래스로 분할하다보니 질적인 변수를 사용하게 됩니다.
이런 경우들이 분류 문제에도 있습니다. 예를 들어 분류 문제에서 어느 클래스에 속할 확률들을 추정할때, 이 확률을 구하기 위해 회귀 방법을 사용합니다. 그리고 K 최근접 이웃이나 부스팅 기법 같은 통계적인 방법들에서는 질적, 양적 변수들을 구분없이 사용하기도 합니다.
우선은 반응 변수가 질적 변수이냐 양적 변수이냐에 따라 통계적 학습 방법을 선택할 수 있으며, 반응 변수가 질적 변수인 경우 로지스틱 회귀, 양적 변수인 경우 선형 회귀를 사용할 수도 있겠습니다. 그래서 입력 변수/특징들이 질적이냐는 덜 중요한 문제이고, 이 책에서는 앞으로 다루는 대부분의 통계적 학습 방법들은 입력 변수의 타입과는 상관없이 사용가능하다고 보시면 될것 같습니다.
2.2 모델 정확도 평가 Access Model Accuracy
이 책의 목표 중 하나는 독자분들에게 기본적인 선형 회귀 방법을 뛰어넘는 다양한 통계적 학습 모델을 소개하려고 합니다. 그런데 왜 한 개의 최고의 방법보다 여러 개의 통계적 접근방법들을 아는 것이 중요한가요? 그 이유는 한가지 방법 만으로 모든 데이터셋을 완벽하게 다룰수 없기 때문입니다. 어떤 데이터셋이 있고, 가장 잘 돌아가는 방법이 있다고 합시다. 하지만 이 데이터셋이 조금 달라졌을때는 다른 방법이 더 좋은 성능이 나올수도 있습니다. 그래서, 주어진 데이터셋이 있을때 최적의 성능을 구하는 방법을 찾는것이 매우 중요한 일이며, 최적의 방법을 찾는 것은 통계적 학습을 수행하는데 있어서 가장 큰 도전과제라고 할 수 있겠습니다.
이번 장에서는 특정한 데이터셋이 주어질때 통계적 학습 방법 선정에 관한 중요한 개념들을 살펴보겠습니다. 이 책을 보면서, 어떻게 이런 컨샙들 개념들이 실제로 사용되는지 설명하겠습니다.
2.2.1 학습을 얼마나 잘했는지 한번 측정하자 Measuring the Quality of Fit
주어진 데이터로 통게적 학습이 얼마나 잘 되었는지 평가 하기 위해서는 우리가 예측한 값과 실제 관측된 값이 얼마나 잘 맞는지 평가하기 위한 방법들이 필요합니다. 다시 말하면 주어진 관측치 (X, Y)가 있을때 X를 입력으로 하여 우리 모델로 추정한 값 $\hat{Y}$이 실제 반응 변수인 Y에 얼마나 가까운지 측정함으로서 잘 학습되었는지 평가 할 수 있습니다. 회귀 문제의 경우 가장 자주 사용되는 측정 방법으로는 최소 제곱 오차 Mean Squared Error MSE가 있습니다.
여기서 $\hat{f}(X_{i})$는 i번째 관측치의 입력 변수 $x_{i}$를 추정한 모델 $\hat{f}$에 대입하여 구한 예측치라고 할 수 있겠습니다. 우리가 만든 모델의 예측값이 실제 반응에 가까울 수록 MSE는 작아질 것이고, 예측치와 실제 값이 다르다면 커지게 될것입니다.
위의 MSE에 대한 식은 훈련 데이터로 모델을 학습시키는 과정에서 계산되는데, 이를 정확하게 부르자면 훈련 MSE training MSE라 부를수 있겠습니다. 하지만 보통, 우리가 사용한 학습 방법이 훈련 데이터에 얼마나 잘 동작하는지 보다는, 학습에 사용하지 않은 시험 데이터를 우리가 추정한 모델에 넣어 구한 추정치가 실제 값과 차이가 큰지 다른말로 얼마나 정확한지에 관심을 가져야 합니다.
왜 우리가 이런걸 신경써야 할까요? 이전의 주가 데이터들을 이용해서 주가를 예측하는 알고리즘을 개발한다고 합시다. 하지만 우리의 예측치가 지난주 주가를 얼마나 잘 예측하는지는 상관없고, 우리에게는 내일이나 다음달의 주가가 어떻게 될지 예측하는게 중요하겠죠.
비슷한 예시로 우리가 환자들의 의료기록(무게, 혈압, 키, 나이, 가족의 질병)들과 이 환자가 당뇨병의 유무에 대한 정보를 가지고 있다고 해봅시다. 우리는 통계적 학습 기법을 사용하면, 새로운 환자의 의료 기록을 가지고 당뇨병 위험도를 예측할 수가 있겠습니다. 여기서 중요한 건 우리는 훈련에 사용한 환자들의 당뇨병 위험도를 얼마나 정확하게 예측하였느냐가, 새로운 환자 새로운 데이터를 정확하게 예측하는데 관심을 가져야 합니다.
조금 더 수학적으로 접근하자면, 훈련 데이터셋 {($x_{1}, y_{1}$, $x_{2}, y_{2}$, , , , $x_{n}, y_{n}$)}으로 어떤 모델을 학습시켜 추정된 함수/모델인 $\hat{f}$를 구하였다고 해봅시다. 그러면 $\hat{f}(x_{1})$, $\hat{f}(x_{2})$, . . ., $\hat{f}(x_{1})$을 계산할 수 있고, 훈련 MSE가 작다면 이렇게 예측한 값들은 아마 $y_{1}, y_{2}, . . ., y_{n}$에 가까울 겁니다.
하지만 우리가 알아야 하는 부분인 $\hat{f}(x_{i}) \approx y_{i}$가 아니라 훈련 과정에 사용하지 않은 모르는 데이터 ($x_{0}, y_{0}$)을 추정한 함수에 대입하여 $\hat{f}(x_{0})$가 $y_{0}$와 거의 같은지를 알아야 합니다. 그래서 우리는 훈련 MSE가 가장 낮은 학습 방법을 쓰는게 아니라 테스트 MSE가 가장 적게 나오는 학습 방법을 선택하여야 합니다. 이를 정리하면 테스트 관측치가 많이 있다고 할때 다음의 테스트 관측치 $(x_{0}, y_{0})$에 대한 평균 제곱 오차를 구할수가 있겠습니다.
그러면 어떻게 해야 테스트 MSE를 최소화 시키는 방법을 찾을수 있을까요? 몇 가지 가정을 해봅시다. 우리는 테스트 데이터 셋을 가지고 있고, 이 데이터들은 훈련 과정에 사용하지 않을겁니다. 이 테스트 데이터는 위의 식으로 쉽게 평가 할수 있어요. 그러니 테스트 MSE가 가장 적은 학습 방법을 선택하면 됩니다.
하지만 우리가 쓸수 있는 시험 데이터가 없다면 어떻게 해야할까요? 이럴 때에는 훈련 MSE를 최소화 시키는 학습 방법을 고를수도 있겠습니다. 훈련 MSE와 테스트 MSE는 서로 크게 연관 되어 있으니까요. 하지만 이 방법은 근본적인 문제점이 있는데, 가장 낮은 훈련 MSE를 얻을 수 있는 학습 방법, 모델이라고 해서 가장 낮은 시험 MSE를 얻을수 있다고 보장할수 없거든요. 이렇게 하는 경우 우리가 추정한 모델이 너무 훈련 셋의 MSE를 최소화 시키는 방향으로 계수들을 추정하다 보니, 과적합 문제로 시험 MSE가 커질수도 있습니다.
그림 2.9 좌측 그림 : 검은 색으로 그려진 함수 f로 생성한 데이터들과 함수 f를 추정한 3가지 모델을 보여주고 있습니다. 주황색 곡선은 선형 회귀 모델, 파란색과 녹색은 스플라인 학습 모델을 보여주고 있습니다. 우측 그림 : 회색 커브는 훈련 MSE를 보여주고, 빨간 커브는 시험 MSE를 보여주고 있습니다. 모든 방법을 사용해서 도달 가능한 시험 MSE의 최저점은 회색 직선으로 그려져있습니다. 그리고 사각형의 점이 있는데 좌측 그림에 나오는 3 모델의 훈련/시험 MSE를 의미합니다.
그림 2.9는 과적합 문제를 보여주고 있습니다. 그림 2.9의 좌측면에서는 실제 함수 f(검은 곡선)로 생성시킨 데이터, 관측치들이 있습니다. 주황색과 파란색, 녹색 커브는 실제 함수 f를 추정한 모델들로 유연성, 복잡도를 증가시킨 차이가 있겠습니다. 주황색 선은 선형 회귀 모델을 나ㅏ내며 다른 모델에 비해 덜 유연한 편입니다. 파란과 녹색 커브는 7장에서 볼 스플라인으로 학습한 모델인데, 다른 복잡도를 가지고 있습니다. 복잡도가 증가 할수록 곡선이 데이터에 더 가까워져 있는것을 볼수 있겠습니다. 녹색 커브는 가장 복잡하고 데이터에 너무 가깝다보니 실제 함수 f를 잘 학습하였다고 할수는 없습니다. 이런식으로 스플라인 모델의 복잡도를 조정해서 학습하면, 이 데이터에 대한 다양한 모델을 얻을수가 있겠습니다.
이제 그림 2.9의 우측을 살펴봅시다. 여기서 회색 커브는 모델의 유연성, 자유도 degree of freedom, 스플라인의 완곡도?에 따른 훈련 MSE를 보여주고 있습니다. 주황색, 파란색, 녹색 사각형들은 좌측 그림의 커브의 MSE를 의미하는데, 커브가 부드러울 수록 자유도가 낮다고 할수있습니다. 선형 회귀 모델은 자유도가 2로 가장 굳은 모델이라 할수 있는데, 훈련 MSE를 보면 유연성 flexibility, 복잡도가 커짐에 따라 MSE가 주렁드는 것을 보실수 있습니다.
실제 함수 f가 비선형인 이 예제에서는 주황색 선형 회귀 모델은 실제 함수 f를 가장 잘 설명한다고 하기는 어렵습니다. 녹색 선의 경우 너무 데이터들에 맞춰져있다보니 가장 낮은 훈련 MSE를 가지게 됩니다.
현실에서는 훈련 MSE를 계산하는건 쉽지만 시험 MSE를 구하는건 데이터가 없을 수도 있다보니 어렵다고 할수 있습니다. 조금전에 본 예시들 처럼 모델의 복잡도에 따라 최소 훈련 MSE가 크게 바뀔수도 있습니다. 그래서 앞으로 이 책에서는 이 최저점을 찾는 좋은 방법들을 배울것인데, 가장 대표적으로 교차 검증(5장)이 있는데, 훈련 데이터를 훈련셋과 검증셋으로 나누어 검증MSE를 평가하는 방법입니다.
그림 2.10 선형에 가까운 함수 f로 생성한 데이터와 이를 적합한 모델들. 모델들의 복잡도와 MSE. 선형 회귀 모델이 주어진 데이터를 잘 적합하고 있다.
2.2.2 편향 분산 트레이드 오프 The Bias Variance Trade Off
시험 MSE 곡선의 U자 형태가 통계적 학습 방법들의 복잡도에 의한 특성임을 살펴봤습니다. 수학적 증명은 이 책의 범위를 넘어가지만, $x_{0}$가 주어질때 예상/기대 되는 시험 MSE expected training MSE를 세 항의 합으로 나누어서 볼수 있겠습니다. 이 세 항으로 $\hat{f}(x_{0})$의 분산, $\hat{f}(x_{0})$의 제곱 편향, 오차항 $\epsilon$의 분산이 있습니다.
여기서 E$(y_{0} - \hat{f}(x_{0}))^{2}$을 기대 시험 MSE expected training mean squared error라고 부르는데, 이 식은 시험 MSE를 훈련 데이터로 f를 학습하고, 시험 데이터로 구합니다. 이전의 MSE와 차이점은 학습된 모델에 시험 데이터를 넣어 구한것이라고 할 수 있을것 같아요.
위 식은 기대 시험 오차를 줄이기 위한 것으로 이 오차를 줄이려면, 분산이 작고, 편향도 작은 통계적 학습 모델을 골라야 합니다. 분산은 0이 음수가 될 수 없고, 제곱 편향 또한 음수가 될 수 없다보니 이전에본 제거 불가 오차이다 보니 기대 시험 MSE은 Var($\epsilon$)보다 작아질 수는 없습니다.
그러면 통계적 학습 방법, 모델에서 편향과 분산이 무엇을 의미하나요? 분산은 학습한 모델 $\hat{f}$가 얼마나 크게 변할수 있는 양, 정도를 의미한다고 할수 있습니다. 다른 훈련 데이터셋을 학습시킨다면 서로 다른 $\hat{f}$가 나오겠죠. 이상적으로 생각해보면 f를 추정한 모델은 훈련 데이터셋에 따라 달라져서는 안되지만 훈련 데이터셋에 약간의 변화로 인해 추정한 모델 $\hat{f}$가 크게 바뀔수도 있습니다. 일반적으로 복잡도가 큰 모델일수록 더 큰 분산을 가지게 되요.
한번 위의 그림 2.9의 녹색과 주황색 커브를 생각해보면, 녹색 커브는 데이터에 매우 가까이 있는데, 데이터 하나가 바뀐다면 이 모델 자체는 크게 바뀌다 보니 분산, 변동성이 큰 편입니다. 반대롤 주황색 최소 제곱법으로 구한 직선의 경우 덜 유연한 모델이며, 관측치 하나가 바뀐다해도 직선이 조금만 움직이면 되니 분산 정도가 작다고 할수 있겠습니다.
편향을 예를 들어 소개하자면 선형 회귀 문제에서 Y와 $X_{1}, X_{2}, , , ,, X_{p}$는 선형 관계를 가지고 있다고 가정하고 있습니다. 하지만 현실에서는 그렇게 단순한 선형 관계를 가진 경우가 잘 없다 보니 선형 회귀에서는 어쩔수 없이 편향이 생기게 됩니다.
그림 2.11 다른 함수 f로 복잡도와 MSE를 살펴봅시다. 여기서 선형 모델은 실제 함수 f와 많이 다르며, 데이터들을 잘 적합하지 못하고 있습니다.
함수 f는 비선형 함수로 훈련 데이터가 얼마나 많던지 간에, 선형 회귀로는 정확한 모델을 만들수가 없습니다. 정리하자면 선형 회귀에서는 큰 편향이 생기게 됩니다. 하지만 그림 2.10에서 실제 함수 f는 주어진 선형에 가까우며 주어진 데이터도 그럴때, 선형 회귀로 정확한 모델을 구하는게 가능합니다. 일반적으로 더 복잡한 모델일수록 적은 편향을 가지게 되요.
지금까지 한걸 정리해보면 복잡한 모델을 사용할때 분산은 커지고, 편향은 줄어드는것을 봤습니다. 이 값들의 변화가 시험 MSE가 증가할지 감소할지를 결정하게 되요. 만약 우리가 모델 복잡도를 늘린다면, 편향은 감소할것고, 분산은 증가하게 될겁니다. 그러면 시험 MSE는 줄어들겠죠.
하지만 모델의 유연성/복잡도를 증가시킨다는게, 편향에는 적게 영향을 준다하더라도 분산에는 큰 영향을 줄수도 있습니다. 이 떄 MSE가 크게 증가하게 되요. 이미 시험 MSE가 줄어들다가 증가하는 패턴들을 지금까지 그림 2.9 - 2.11에서 계속 봐왔습니다.
그림 2.12 위 그래프들은 그림 2.9-2.11에서 사용한 세 데이터셋들의 제곱 편향(파란 곡선), 분산(주황 곡선), 오차항 분산(점선), 시험 MSE(빨간 곡선)입니다. 수직 점선은 최소 시험 MSE의 복잡도를 나타냅니다.
그림 2.12에서 세 그림은 그림 2.9- 2.11 데이터를 이용하여 기대 시험 MSE의 값들을 보여주고 있습니다. 파란 곡선은 복잡도에 따른 제곱편향을, 주황색 곡선은 분산을, 수평방향의 점선은 제거 불가 오차인 오차항 분산을 보여주고 있습니다. 마지막으로 빨간 곡선은 시험 데이터셋의 MSE로 세 값의 합이 되겠습니다.
모든 경우 복잡도가 증가할수록 분산이 증가하고, 편향이 줄어들고 있습니다. 하지만 최적 시험 MSE에서의 복잡도 정도가 데이터셋에 따라 크게 다른데, 각 데이터 셋에 따라 제곱 편향과 분산 변화율이 다르기 때문입니다. 왼쪽 그래프에서는 편향이 처음에 빠르게 감소하여 시험 MSE가 크게 줄어든느것을 볼수 있습니다.
반면에 중간 그래프의 경우 시험 f가 선형에 가깝다보니, 복잡도가 증가해도 편향이 크게 감소하하지 않으며 시험 MSE가 분산이 크게 증가하기 전까지 약간씩 감소하는것을 볼수 있습니다. 마지막으로 오른쪽 그림은 복잡도가 증가할때 편향이크게 감소하는데, 실제 함수 f가 비선형이기 때문이며, 복잡도가 증가해도 분산의 증가가 크지 않고 결과적으로 시험 MSE는 분산이 증가하기 전까지는 감소하는것을 볼 수 있겠습니다.
2.2.3 분류 문제
으아 지금까지 회귀 문제에서 모델 정확도를 어떻게 늘릴수 있는가를 위주로 봤는데, 우리가 보아왔던 편향, 분산 트레이드오프 같은 개념들이 분류 문제에서도 동일하게 적용됩니다. 분류 문제에서 다른점은 $y_{i}$는 수치데이터가 아니라는 점이죠.
다음의 훈련 데이터가 주어질때 {$(x_{1}, y_{1})$, ($x_{2}$, $y_{2}$), . . ., ($x_{n}$, $y_{n}$)}로 실제 함수 f를 추정해 봅시다. 그런데 여기서 $y_{1}$, . . ., $y_{n}$은 질적 변수에요. 분류 문제에서 우리가 추정한 모델 $\hat{f}$의 정확도를 정량화 시키는 가장 일반적인 방법은 훈련 에러율 training error rate인데, 이 값은 훈련 데이터를 우리가 추정한 모델 $\hat{f}$에 넣었을때 잘못 예측한 비율을 말하며 아래와 같이 식을 정리할수가 있어요.
위 식에서 $\hat{y_{i}}$는 i번째 관측치에 대한 예측 라벨로 I($y_{i} \neq \hat{y_{i}}$)는 $y_{i}\neq \hat{y_{i}}$인 경우 1, $y_{i} = \hat{y_{i}}인 경우(예측 라벨과 실제 라벨이 같을때 => 올바르게 예측한 경우) 0이 되는 지시 변수 indicator variable라고 합니다. 그래서 I($y_{i}\neq \hat{y_{i}}$) = 0이라면 i 번째의 관측치가 올바르게 분류된 것이고, 그렇지 않다면 잘못 분류되었다고 볼수있어요. 위의 식은 오분류 비율을 계산한다고 할 수 있겠습니다.
그리고 위 식을 훈련 에러율이라고 부르는 이유는 우리가 학습 시킨 분류기를 사용해서 계산하기 때문입니다. 또 회귀 문제의 경우에서처럼 우리는 학습시킨 분류기가 테스트 데이터를 분류했을때 에러율도 매우 중요한데, 이를 테스트 에러율 test error rate는 시험 데이터가 ($x_{0}, y_{0}$)과 같은 형테로 주어질때 아래의 식으로 구할수가 있겠습니다.
여기서 $\hat{y_{0}}$는 테스트 관측치의 $x_{0}$를 주었을때 얻은 예측 라벨로 좋은 분류기의 경우 에러율이 낮겠죠.
베이즈 분류기 The Bayes Classifier
각 관측치에 가장 가능성 높은 클래스로 분류하는 단순한 분류기를 사용하면 위에서 본 훈련 에러율이 어떻게 최소화 되는지를 볼수 있습니다. 이걸 보려면 테스트 관측치 $x_{0}$가 주어질때, 가장 가능성이 높은 카테고리 j를 주어야 합니다.
위 식을 조건부 확률 conditional probability라고 부르는데, 입력 벡터 $x_{0}$가 주어질때, Y = j일 확률을 의미합니다. 이 간단한 분류기를 베이즈 분류기 Bayes Classifier라고 불러요. 한번 반응 변수의 값이 2개인 그러니까 클래스 1, 클래스 2로 분류되는 이진 분류 문제를 예를 든다면, 베이즈 분류기는 Pr(Y=1 | X= $x_{0}$) >= 0.5라면 클래스 1로 판단하고, 아닌 경우 클래스 2로 판단한다고 할 수 있겠습니다.
그림 2.13 두 그룹에 대한 100개의 관측치 데이터셋으로, 파란색과 주황색으로 어디에 속하는지 나타내고 있습니다. 보라색 점선은 베이즈 분류기 경계를 나타내며, 주황색 배경은 시험 관측치가 주황색 클래스로 할당하는 영역이고, 테스트 관측치가 파란색 그리드 배경에 속하는 경우 파란색 클래스로 판단하게 됩니다.
그림 2.13은 $X_{1}, X_{2}$로 이루어진 2차원 공간에서의 예시를 보여주고 있는데, 주황색, 파란색 원은 서로 다른 클래스에 속하는 관측치들을 의미하고 있습니다. $X_{1}, X_{2}$의 값들은 주황색에 속하는지 파란색에 속하는지에 대한 서로 다른 확률을 가지고 있습니다. 이 데이터들은 시뮬레이션 한거다 보니 어떻게 생성되었는지 알 수 있고, $X_{1}$, $X_{2}$에 대한 조건부 확률들을 계산할 수가 있습니다.
주황색 배경 영역은 Pr(Y = 주황색 | X) = 50%인 데이터들을 반영한 곳이고, 파란색 배경 영역은 X가 주어질때 Y=주황색일 확률이 50%보다 낮은 공간을 의미합니다. 여기서 보라색 점선이 정확하게 50%가 될 확률을 이 됩니다. 이 선을 베이즈 결정 경계 bayes decision boundary라고 부르며, 베이즈 분류기의 분류 예측은 베이즈 결정 경계로 수행되겠습니다. 관측 치가 주황색쪽에 속한다면 주황색 클래스로 판별할 것이고, 파란색 공간에 속한다면 파란색 클래스로 판별 할 것입니다.
베이즈 분류기로 베이즈 에러율 Bayes error rate라고 부르는 가능한 가장 낮은 시험 에러율을 구할 수 있는데, 베이즈 분류기는 가장 큰 확률을 가진 클래스를 선택하기 때문에 X = $x_{0}$에서의 에러율은 1 - $max_{j}$ Pr(Y=j|X=$x_{0}$)이 됩니다. 일반적으로 베이즈 에러율은 아래의 식으로 구하는데, X가 주어질때 확률이 가장 큰 모든 경우들의 평균으로 구해지게 되비다.
여기서 사용한 시뮬레이션 데이터의 경우 베이즈 에러율은 0.1304로 0보다 크게 되는데, 실제 분포 데이터들을 보면 일부 클래스들이 겹쳐 있다보니, 이런 일부 데이터 $x_0$들은 $max_{j}$Pr(Y=j|X=$x_0$) < 1이 되기 때문입니다.
K 최근접 이웃 K Nearest Neighbors
이론 적으로는 베이즈 분류기로 질적 반응변수, 그냥 카테고리 변수라고 할께요. 카테고리를 예측 할수 잇었지만, 실제 데이터의 경우 X가 주어질때 Y의 확률에 대한 조건부 확률 분포를 모릅니다. 그래서 베이즈 분류기를 사용하는게 불가능 해요. 그래서 베이즈 분류기는 실제로 사용하기는 힘드나 다른 방법들의 기본 틀로서 사용되고 있습니다. 이 경우 사용하는 다른 방법들은 X가 주어질때 Y에 대한 조건부 확률 분포를 추정해내고, 그 다음 주어진 관측 데이터가 어디에 속하는지 확률로 분류하게 되요.
그러한 방법중 하나로 최근접 이웃 분류기 K nearest neighbors classifier가 있습니다. 양의 K 값과 시험 관측치 $x_{0}$가 주어질 때, KNN 분류기는 우선 $x_{0}$에 가장 가까운 훈련데이터셋에서 K개의 점들을 찾아냅니다. 이 점들을 $N_{0}$이라고 할게요. 그리고 $N_{0}$ 중에 클래스 j에 속하는 비율로, 그러니까 입력 데이터에 최근접인 K개의 점들이 클래스 j에 얼마나 속하는지로 클래스 j에 대한 조건부 확률을 추정해요. 이를 식으로 표현하면 아래와 같습니다. KNN에 베이즈 정리를 이용하여 관측 데이터 $X_{0}$를 가장 큰 확률에 속하는 클래스로 분류하게 됩니다.
그림 2.14 K = 3인경우의 KNN. 6개의 파란 데이터와 6개의 주황색 데이터가 있는 공간. 좌측 그림 : 테스트 데이터는 검은색 원 안에 속한 데이터로 클래스 라벨을 예측합니다. 테스트 데이터에 가장 가까운 세 점을 보고 이 데이터가 어디에 속하는지를 판단하는데 이 경우 파란색 데이터가 많으므로 파란색으로 판단하게 됩니다. 우측 그림 : 이 예제의 KNN 결정 경계를 검은 선으로 보여주고 있습니다. 파란 그리드 공간은 테스트 데이터가 파란색 클래스로 판단되는 공간이며, 주황색 그리드는 오랜지색 클래스로 분류도ㅚ는 공간입니다.
그림 2.14는 KNN 방법의 KNN에 대한 예시를 보여주고 있습니다. 왼쪽 그림에서는 6개의 파란, 6개의 주황색 훈련 데이터 셋을 보여주고 있습니다. 여기서 우리들의 목표는 검은 원안에 있는 점이 어디에 속하는지 예측하는 것인데요. K =3으로 가정을 하면 KNN 알고리즘은 테스트 관측치/데이터 $x_{0}$에 가장 가까운 세점을 찾습니다. 그래서 이 이웃점들이 원안에 들어있어요.
이 원을 보면 2개의 파란색 점과 한개의 주황색 점이 있는데, 이걸로 확률을 추정하면 그러면 파란 클래스에 속할 확률은 2/3, 주황색 클래스에 속할 확률은 1/3이 됩니다. 그림 2.14의 오른쪽을 보면 K = 3인 경우 KNN의 결정 경계들을 보여주고 있습니다.
그림 2..15 (그림 2.15)의 데이터와 K=10일 때 KNN 알고리즘의 결정 경계를 검은색 커브로 그렸습니다. 여기서 베이즈 결정 경계는 분홍색 점선입니다. KNN과 베이즈 결정 경계 둘다 매우 비슷한 형태를 띄고 있는걸 볼수 있겠습니다.
이 방법은 매우 단순하지만 KNN은 최적의 베이즈 분류기라고 할수 있겠으며, 그림 2.15에서는 그림 2.13의 데이터셋을 이용하여 K = 10인 경우의 KNN 결정 경계를 보여주고 있습니다. 실제 분포 true distribution을 모르더라도 KNN 분류기로, 베이즈 분류기에 거의 가까운 KNN 결정 경계를 구할수 있는걸 볼수 있어요. KNN을 사용하였을때 시험 에러율도 0.1363으로 베이즈 에러율 0.1304에 매우 가까웠습니다.
KNN 분류기의 성능은 K를 어떻게 설정하느냐에 따라 달리는데 이 내용까지 정리하기는 힘들고 이번 주 정리는 요기까지