이번에 프로젝트로 위성 사진을 시멘틱 분할하는 어플리케이션을 준비하게 되었다. 베이스라인 모델로 U-Net 같은 것들을 사용하면 된다고 하더라. 일단 이전에 시멘틱 분할 모델인 FCN이나 U-Net 같은 모델 논문을 잠깐 간단히 보기는 했지만 그렇게 잘 와닿지는 않았다.
아무튼 지금나는 시멘틱 세그먼테이션을 하기 위해서 저런 모델을 사용한다는 사실만 알고, 데이터셋을 어떻게 준비하는 지 모델을 만들어서 준비한 데이터셋으로 학습하고 돌리는지 까지는 잘 모르는 상태였다. 그래서 잠깐 구글링으로 U-Net으로 별도의 데이터셋을 훈련하는 방법, 프로젝트에 관해서 검색 해보았는데 자세히 보지는 못했지만 Palliwi라는 분이 잘 정리해서 미디움에다가 올려놓으셨더라.
Semantic segmentation with U-Net- train, and test on your custom data in Keras
What is semantic segmentation?
pallawi-ds.medium.com
주의 깊게 본다면 이해할 수 있을것 같긴한데 내용 앞부분을 보면서 잠시 FCN, U-Net 모델에 대해서 조금 더 깊이 이해할 필요성을 느꼈다. 이전에 여러번 초록 정도는 보고, 이해하려고 뭔가 속시원하게 파악하지는 못하다보니 이번에 다시 FCN 부터 다양한 국내 블로그 정리 글을 찾아보았는데 가장 먼저 라온 피플에서 작성한 글을 보았다. 보면서 나도 이렇게 잘 좀 정리하고 싶은데 왜 이렇게 힘들까 ㅠㅜ. 지난번에 ResNet도 깔끔하게 정리해봐야지 해놓고 계속 미뤄두네 ;;
m.blog.naver.com/laonple/220958109081
[Part Ⅶ. Semantic Segmentation] 3. FCN [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic Segmentat...
blog.naver.com
라온 피플의 FCN에 대한 설명 1
이 글에서는 우선 FCN이 언제 나오고 얼마나 열광 받고 있는지 부터 시작하고 있다. 그리고 분류, 검출, 시멘틱 세그먼테이션과 같이 컴퓨터 비전 분야의 문제들을 소개하면서 각각 문제 모델의 특징들을 알려주는데, 이런 내용은 여러번 보았고 알곤 있었지만 뭔가 허전함? 깔끔하게 정리가 잘 안됬는데 이런 내용들 처럼 잘 정리하고싶다 ㅜㅜ
아무튼 FCN의 Fully Convollution layer/ 1 x 1 Convolution의 장점에 대해서 소개하는데 이 방법이 나는 FCN에서 처음으로 사용된 것인줄 알았지만 이전에 잠깐 있다고만 들었던 OverFeat 모델에서 사용되었다고 하더라. 하지만 OverFeat에서는 분류, 검출에서만 사용했다 하고, FCN이 시멘틱 세그먼테이션 용도로 1 x 1 conv가 사용된 경우라고 한다.
여기서 말하는 1 x 1 Convolution의 장점으로는 기존의 분류 모델이나 검출 모델에서는 뒤에 고정 크기의 벡터를 만드는 완전 연결 레이어가 존재하여 입력 크기의 제한을 받는다고 한다. 아마 입력 크기가 클수록 고정 크기의 입력 벡터로 정리하려고 많은 정보들을 정리할 수 없고, 완전 연결 계층에서 연산을 하기 위해 Flatten 할 필요가 없어지니 기존의 공간적 정보가 사라지는 것을 방지 한다는 점에서 영상 제한이 사라진다고 하는것 처럼 보인다.
이 다음으로는 디컨볼루션을 이용한 업샘플링에 대해서 설명해주고 있다. 업샘플링을 하는 이유는 여러 레이어들을 거쳐가면서 피쳐맵의 공간적 크기가 줄어드는데 이를 기존의 입력 크기와 동일하게 맞춰주기 위함인데, 간단하게 업샘플링을 한다면 opencv의 resize함수처럼 양선형 보간법을 사용하면 되겠지만, 여기서는 end-to-end 학습을 통해 구하며 backward convolution(deconvolution)을 사용한다고 말한다.
하지만 마지막 레이어에서 너무 작아진 피쳐맵만 가지고 deconv로 크기를 키우면 중간에 존재하던 디테일한 정보들이 사라지기 때문에 중간 레이어로부터 스킵커넥션을 통해 보강시킨다고 한다. 이걸 tf로 어떻게 표현하는지는 잘 모르겠지만 skip layer를 추가시킬수록 더 정교한 예측을 만드는 것으로 이 글이 마쳤다. 라온 피플에서 FCN 모델에 대해 추가적인 설명을 하니 다음 글도 봐야겠다.
'인공지능' 카테고리의 다른 글
| AINIZE를 활용한 ML 프로젝트 배포 (0) | 2021.03.26 |
|---|---|
| [인공지능및기계학습]02.4 엔트로피와 정보 이론 (0) | 2021.01.14 |
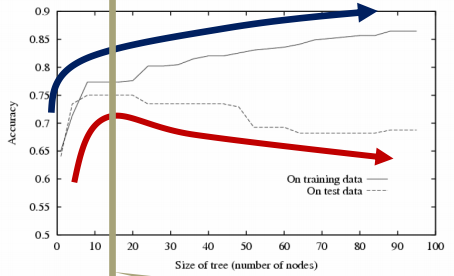
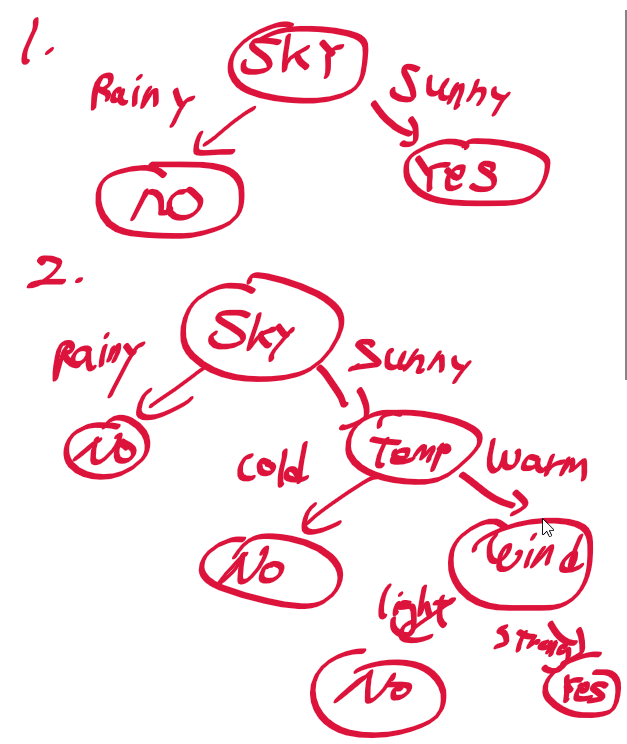
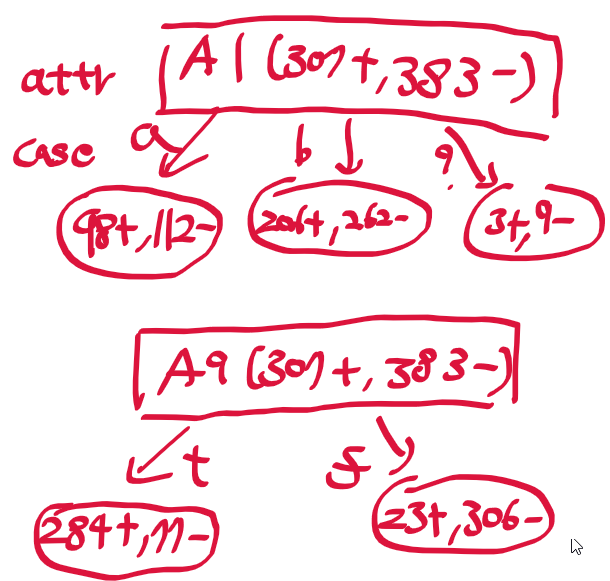
| [인공지능및기계학습]02.3 결정 트리 개요 (0) | 2021.01.13 |
| [인공지능및기계학습]02.머신러닝의 기반들 (0) | 2021.01.08 |
| [인공지능및기계학습]01.동기부여 및 기초 (0) | 2021.01.07 |
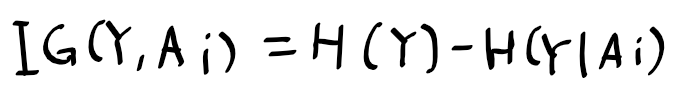



{kind=link}