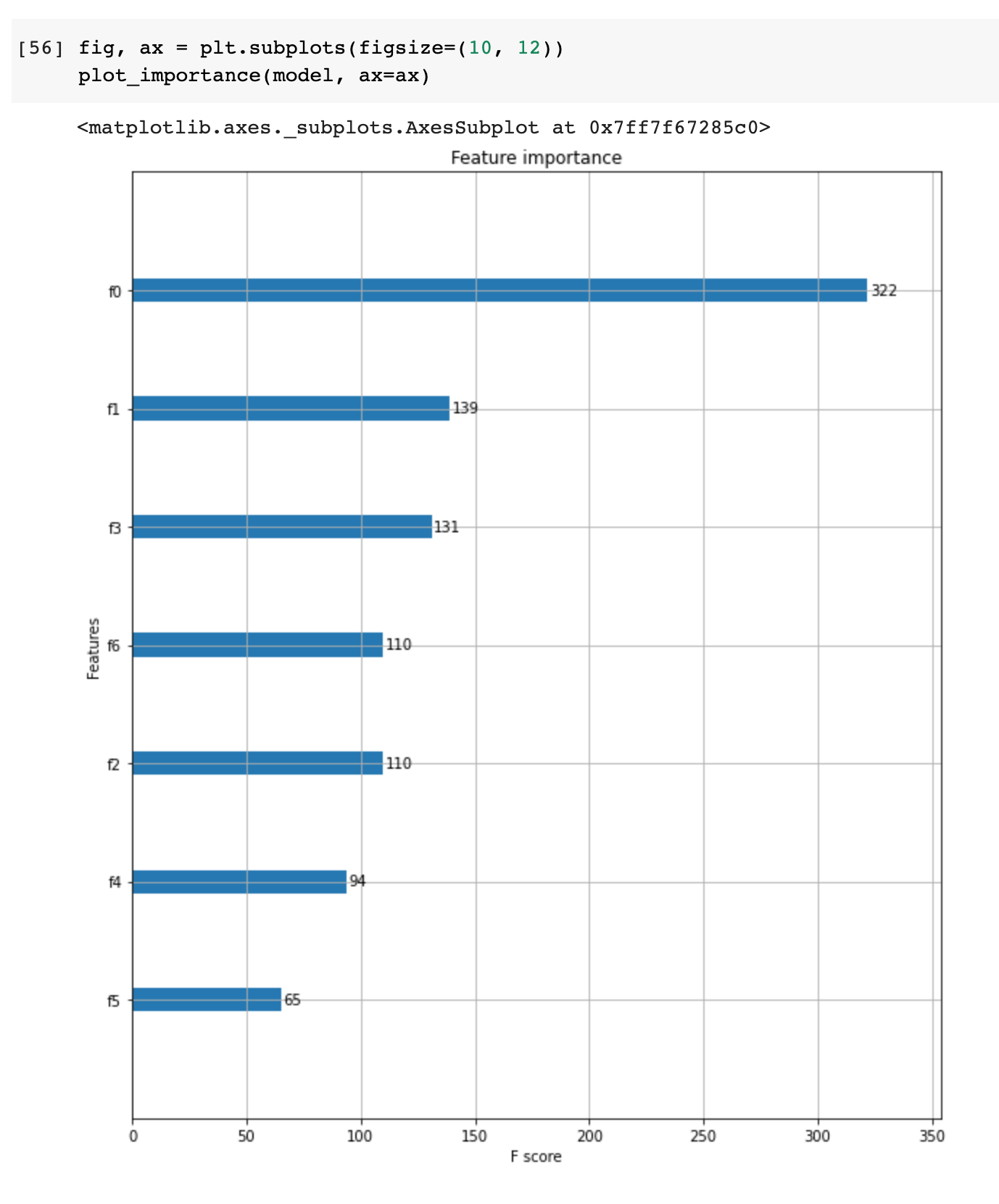
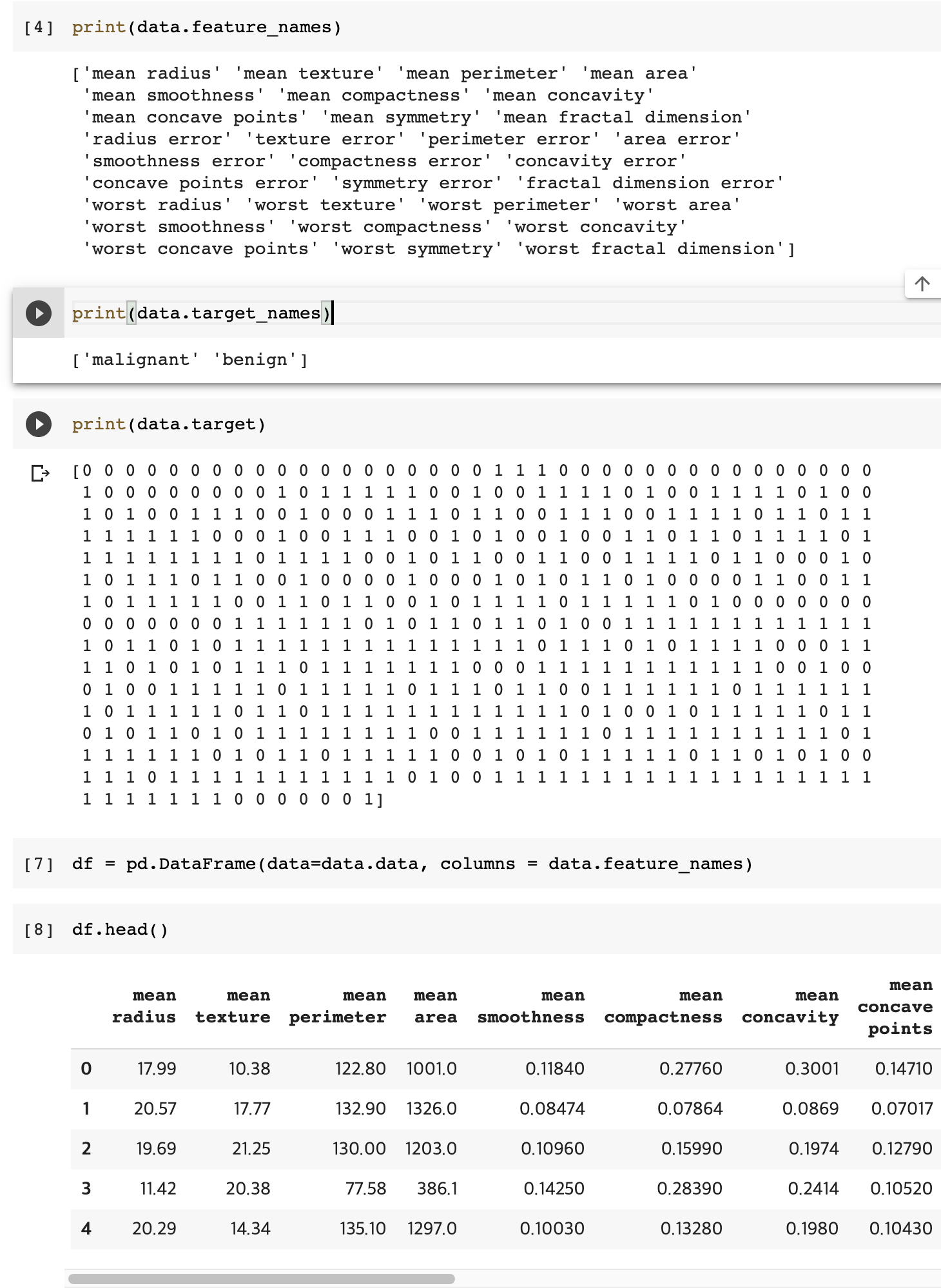
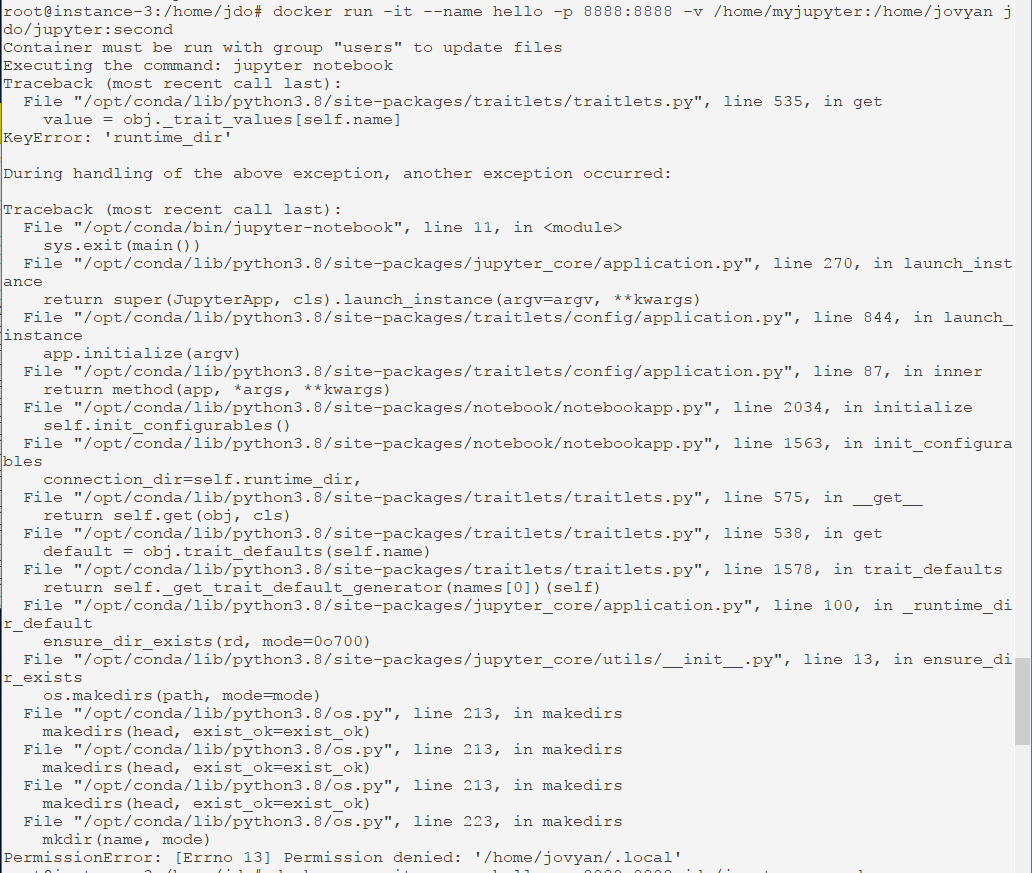
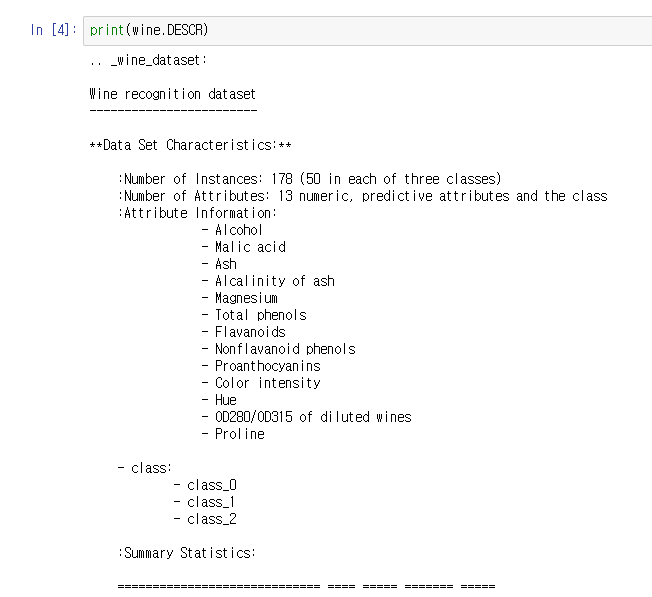
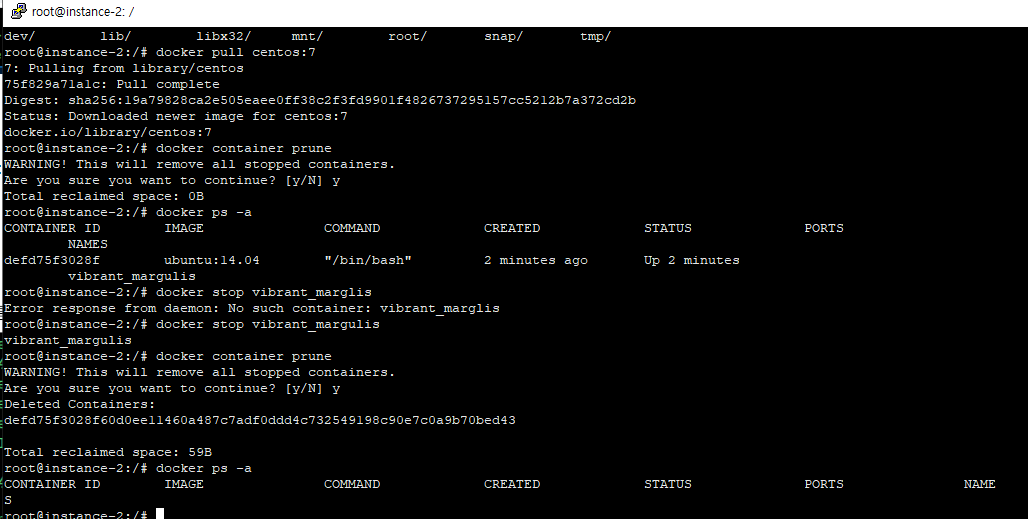
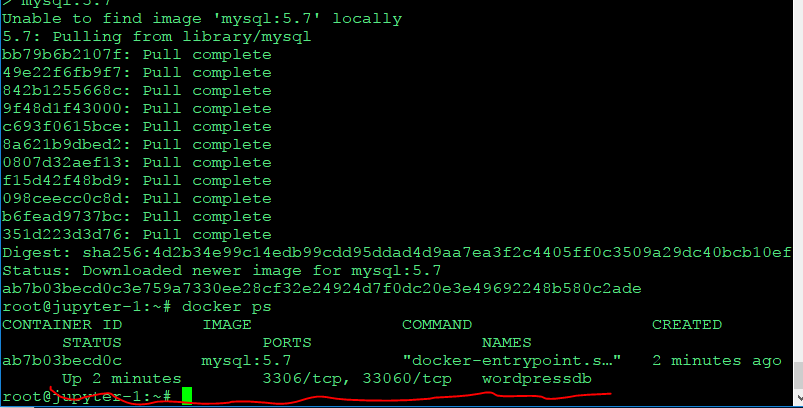
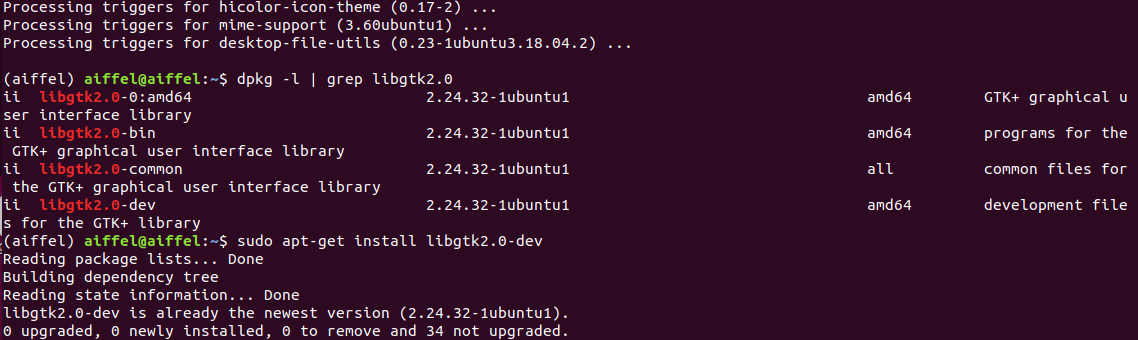
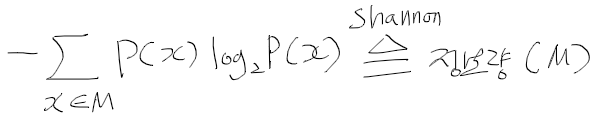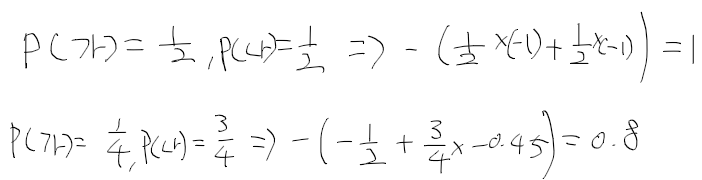sudo apt-get install libgtk2.0-dev
위 명령어로 libgtk2.0-dev를 설치하려고 하는데,
unable to correct problems you have held broken packages 에러가 발생하면서 설치가 되지 않았다.
이런 패키시 의존성 문제도 잘 이해 안되고, 이전에 aptitude를 사용한 적이 있다보니
aptitude로 무작정 설치해보았다.
잠깐 구글링 해보니 아래 링크에서도 aptitude를 사용하라고 하더라
askubuntu.com/questions/223237/unable-to-correct-problems-you-have-held-broken-packages
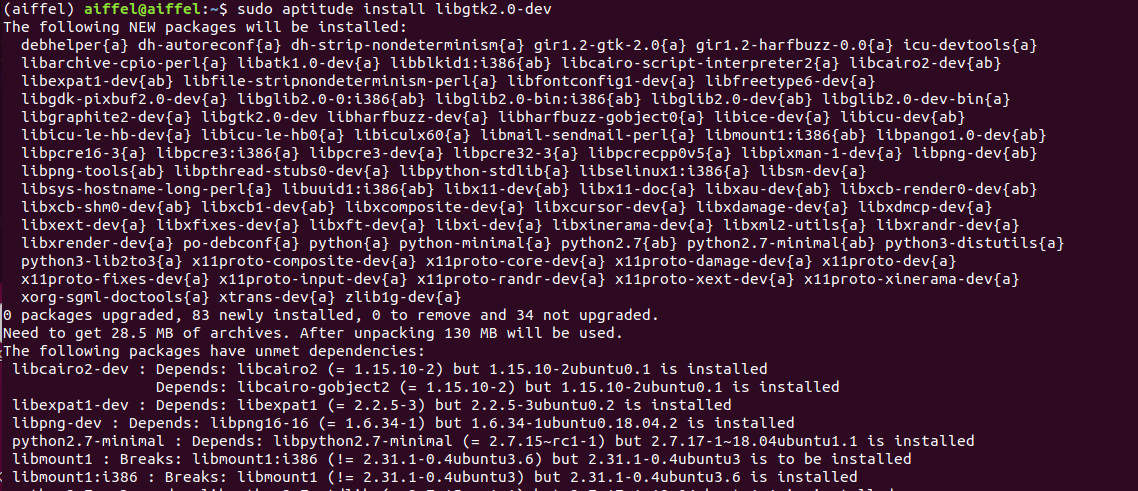
설치도 잘 됬고, dpkg로 libgtk2.0-dev가 깔린걸 확인할 수 있었다.
잠깐 그래서 검색하다보니 아래의 링크에서 apt, dpkg, aptitude 패키지 관리 툴에 대해서 잘 정리해둬서 복사해 가져왔다.
golmong.tistory.com/222tpholic.com/xe/5102649
----------------------------- 펌 내용 -----------------------------------
이번 시간에는 패키지 관리 툴들에 대해 조금~ 배워보는 시간을 갖도록 하겠습니다 ^^
우분투는 아는 사람은 알다시피... 데비안을 그 기반으로 하고 있습니다. 고로 프로그램의 설치는 .deb파일을 통해 패키지 형태로 이루어 집니다.
이런 .deb파일이나 패키지의 관리에 사용되는 툴에 대해 이해하고 이 툴들을 보다 유용하게 사용할 수 있기를 바라며 이번 강좌를 시작합니다
우분투를 설치한 후, 시스템의 사용목적이나 필요에 따라서 .deb 파일을 추가 설치 하거나 삭제 할 수 있다.
.deb 확장자 파일은 데비안 패키지 파일로써 우분투가 데비안 기반으로 한 시스템이라 소프트웨어 설치에 .deb파일을 사용하는 것이다.
이러한 패키지 들은 패키지 툴을 이용하여 설치하게 되는데 패키지 툴에는 apt, dpkg, aptitude 가 있다. 그중 몇가지를 설명하자면...
APT 는 온라인 리포지토리에서 패키지를 다운로드받고 설치하는데 사용 된다( : 예> apt-get 패키지명) 이때 보통 로컬환경(오프라인)상에서도 사용할 수 있지만 정상적으로 사용하기 위해서는 온라인 환경에서 사용하여야 한다.
dpkg 는 Cd룸이나 다른 디스크장치에 있는 .deb 파일을 제어하는 경우에 일반적으로 사용되며, dpkg명령어는 시스템 소프트웨어에 대한 설정이나 설치 및 정보를 얻는데 사용되는 옵션을 가진다
(예:> dpkg -c 데비안패키지 – 패키지가 설치한 파일 목록보기)
패키지 툴에 대한 부분은 나중에 보다 자세하게 살펴보도록 하겠다.
우분투를 설치한 후 터미널 창을 열어 다음을 입력해보자
$ apt-cache stats
그러면 다음과 같은 결과를 얻을 수 있을 것이다.
전체 꾸러미 이름 : 33052 (1322k)
일반 꾸러미: 25280
순수 가상 꾸러미: 703
단일 가상 꾸러미: 1688
혼합 가상 꾸러미: 237
빠짐: 5144
개별 버전 전체: 30120 (1566k)
...
위 에서 보듯이 전체 30000여 개가 넘는 소프트웨 패키지를 사용할 수 있다.(공짜!로 쓸 수 있는 프로그램이 이리 많다는게 놀랍지 아니한가?)
그럼 본론으로 들어가서 각 패키지 툴을 이용한 소프트웨어 관리에 대해 배워보는 시간을 갖자.
1.APT
실질적으로 APT는 dpkg와 함께 동작한다. 하지만, 필요한 소프트웨어의 검색, 다운로드, 설치, 업그레이드, 검사 등 대부분의 패키지 관리작업을 APT단독으로 가능하다.
그럼 일반적 사용법을살펴보자
*주의: 다음 명령압에 sudo가 붙는데 sudo의 경우 우분투에서 사용하는 명령어에 관리자 권한을 주는 명령이다. 이는 우분투의 경우 기본적으로 root로 로그인을 막아 놓앗고 또 계정을 활성화 시켜놓지 않고 sudo 명령으로 root권한을 실행할 수 있도록만 만들어 놓았다. 그러므로써, 안전성을 확보하고 필요시 쉽게 root권한에 접근할 수 있도록 하고 있다. - 덫붙여 우분투를 사용할 때 꼭 필요한 경우가 아니면 root계정을 활성화하지 않는게 보안에 좋다. 다르게 말해 설치후 추가적으로root 패스워드를 지정해주지 않는게 보안에 좋다는 것이다.
sudo apt-get update
: /etc/apt/sources.list를 참조로 사용할 수 있는 패키지 DB를 업데이트 한다.
apt-cache search 키워드
: 패키지 데이터베이스 중 주어진 키워드를 대소문자 구분 없이 검색하여 키워드를 포함하는 패키지명과 해당 설명을 출력한다.
sudo apt-get install 패키지명
: 패키지명을 데이터베이스에서 찾아보고 해당패키지를 다운로드 받아 설치한다. 이때, 패키지의 신뢰성을 gpg키를 사용 검증한다.
sudo apt-get -d install 패키지명
: 패키지를 설치는 하지 않고 /var/cache/apt/archives/ 디랙토리에 다운로드 받는다.
apt-cache show 패키지명
: 주어진 패키지명에 해당하는 소프트웨어에 대한 정보를 본다.
sudo apt-get upgrade
: 설치 되어있는 모든 프로그램 패키지에 대한 최신 업데이트를 검사한 후, 다운로드 받아 설치한다.
sudo apt-get dist-upgrade
: 전체 시스템을 새로운 버젼으로 업그레이드 한다. 이때 패키지 삭제도 실시된다.
단, 일반적으로 사용되는 업그레이드 방법은 아님!
sudo apt-get autoclean
: 불안전하게 다운로드된 패키지나 오래된 패키지의 삭제.
sudo apt-get clean
: 디스크 공간 확보를 위해 /var/cache/apt/archives/ 에 캐쉬된 모든 패키지 삭제
sudo apt-get 옵션 remove 패키지명
: 해당 패키지와 그 설정파일을 삭제한다. ( 옵션에 --purge 를 넣으면 설정파일을 재외하고 삭제. 옵션없을시 전부 삭제)
sudo apt-get -f install
: 깨어진 패키지를 위해 정상여부를 확인
apt-config -V
: 설치된 APT툴의 버전을 출력
sudo apt-key list
: APT가 알고 있는 gpg키 목록의 출력
apt-cache stats
: 설치된 모든 패키지에 대한 상태정보를 출력
apt-cache depends
: 패키지가 설치되어 있는지 여부에 관계 없이 그 의존성을 출력한다.
apt-cache pkgnames
: 시스템에 설치되어 있는 모든 패키지 목록을 보여준다.
이상으로 APT사용법을 대충 익혀보았다. 이제 dpkg를 알아보자
2.dpkg
이 툴의 경우 APT보다는 낮은 수준에서 작업이 수행된다. APT는 우분투의 소프트웨어를 관리하기 위해 내부적으로 이 dpkg를 이용한다. 보통 APT명령 만으로 충분하지만... 시스템에 있는 특정 파일이 어떤 패키지에 포함되는지 등의 확인 작업을 수행하기위해 dpkg 명령이 필요한 것이다.
dpkg -C .deb파일
: 주어진 .deb파일이 설치한 파일의 목록을 본다.(해당 파일이 있는 곳에서 실행하거나 파일명앞에 절대 경로를 붙여준다.)
dpkg -I .deb파일
: 주어진 .deb파일에 대한 정보를 본다.
dpkg -P 패키지명
: 패키지에 대한 정보를 보여준다.
dpkg -S 파일명
: 파일명 또는 경로가 포함된 패키지들을 검색한다.
dpkg -l
: 설치된 패키지 목록을 보여준다.
dpkg -L 패키지명
: 이 패키지로부터 설치된 모든 파일목록을 볼수 있다.
dpkg -s 패키지명
: 주어진 패키지의 상태를 본다
sudo dpkg -i .deb파일
: 주어진 파일을 설치한다.
sudo dpkg -r 패키지명
: 시스템에서 해당 패키지를 상제한다. (단, 삭제시 파일들은 남겨둔다.)
sudo dpkg -P 패키지명
: 해당 패키지와 해당 패키지의 설정파일을 모두 삭제한다.
sudo dpkg -x .deb파일 디랙토리
: 파일에 포함되어있는 파일들을 지정된 디렉토리에 풀어놓는다. 단, 주의 할점은 이명령시 해당 디렉토리를 초기화 시켜버리므로 주의하여야 한다!
3. aptitude
앞에서 배운 dpkg와 APT의 경우 제대로 사용하기 위해서는 좀더 많은 지식을 요구한다. 그에 비하여 aptitude의 경우 주요 패키지 작업 과정을 자동화하여 가능한 쉽게 작업할 수 있도록 해주므로 보다 쉽게 할 수 있다. 고로 보다 많이 사용하게 될 것이... 옳지만... 아직은 인터넷 상에서 APT나 dpkg를 사용한 패키지 설치 정보가 많다는 점에서... 장래에 많이 사용하게 될 듯하다^^
sudo aptitude
: 실행시 curses인터패이스로 시작된다. Ctrl+t를 사용하면 메뉴에 접근할 수 있으며, q키로 프로그램을 종료 시킬 수 있다.
aptitude help
: 도움말 보기
aptitude search 키워드
: 해당 키워드와 일치하는 패키지를 보여준다.
sudo aptitude update
: APT리포지트로들로부터 사용 가능한 패키지를 업데이트 한다.
sudo aptitude upgrade
: 모든 패키지를 최신으로 업그레이드 한다.
aptitude show 패키지명
: 해당 패키지의 설치 여부에 관계 없이 주어진 패키지에 대한 정보를 보여준다.
sudo aptitude download 패키지명
: 해당 패키지를 설치하지는 않고 다운로드만 받는다
sudo aptitude clean
: /var/cache/apt/archives디렉토리에 다운로드되어 있는 모든 .deb파일을 삭제한다.
sudo aptitude autoclean
: /var/cache/apt/archives디렉토리에 있는 오래된 .deb파일을 전부 삭제한다.
sudo aptitude install 패키지명
: 해당 패키지를 시스템에 설치한다.
sudo aptitude remove 패키지명
: 시스템으로부터 주어진 패키지를 삭제 한다.
sudo aptitude dist-upgrade
: 모든 패키지를 가장 최신 버전으로 업그레이드 시킨다. 이때, 필요한 경우 패키지를 삭제하거나 추가 한다.
이상으로 패키지에 대해서 수박 겉할기 식으로 나마 알아 보았고, 특히 이들 패키지를 설치하거나 관리하기 위한 몇가지 방법을 알아보았다.
참고로, 위 내용 다 넘기고 요즘 우분투의 경우 '프로그램 > 추가/제거' 메뉴나 '시스템 > 관리 > 스넵틱스관리자' 에서 쉽게 패키지를 선택하고 설치하거나 삭제 할 수 있다. 아니면 .deb파일을 받아 마우스로 클릭만 해주면 자동으로 패키지 관리자가 실행되어 설치 하게 되어있다.
참으로 편리한 세상이다...
하지만, 위 내용을 알고 있어야... 보다 깊은 단계로 나아갈 수 있고 또 보다 세부적인 관리, 추가, 삭제가 가능하기에 알아 두는게 좋다고 본다.
참고: 위에 나열된 명령어들은 터미널 환경에서 사용되는 command입니다.
참고2: 빠른 작성을 위해 경어체를 생략했습니다. 이해해주시길 바랍니다 ^^;;
조금이나마 우분투 사용에 도움이 되길 바라며 다음에 뵙겠습니다.
전 국민이 우분투등의 리눅스를 자신의 OS로 쓰는 그날까지....
'컴퓨터과학 > 기타' 카테고리의 다른 글
| 알고리즘 연습 - 1. vscode 자동 완성, 인텔리센스가 안될 때 (0) | 2020.12.15 |
|---|---|
| snu 샤논의 정보이론 강의 (0) | 2020.11.25 |
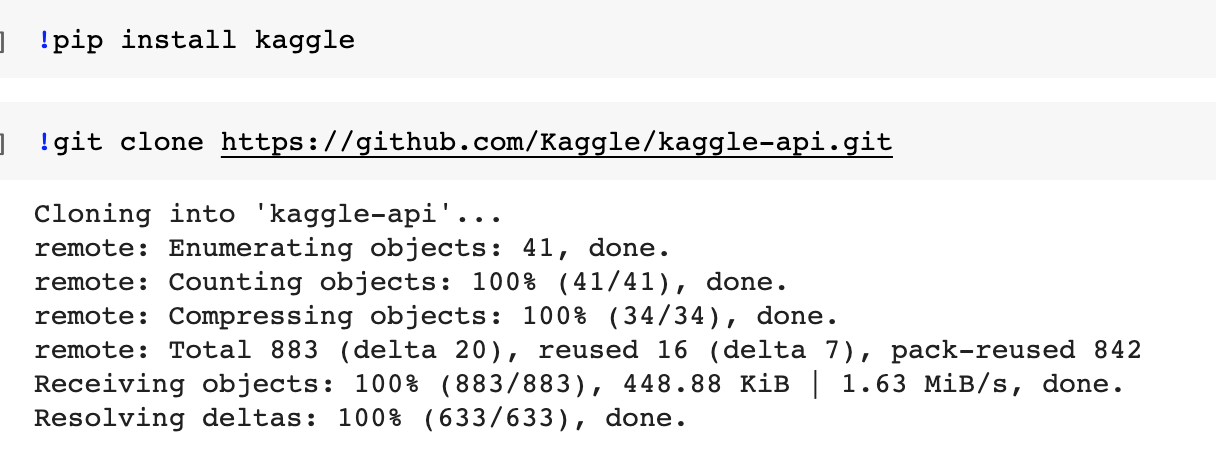
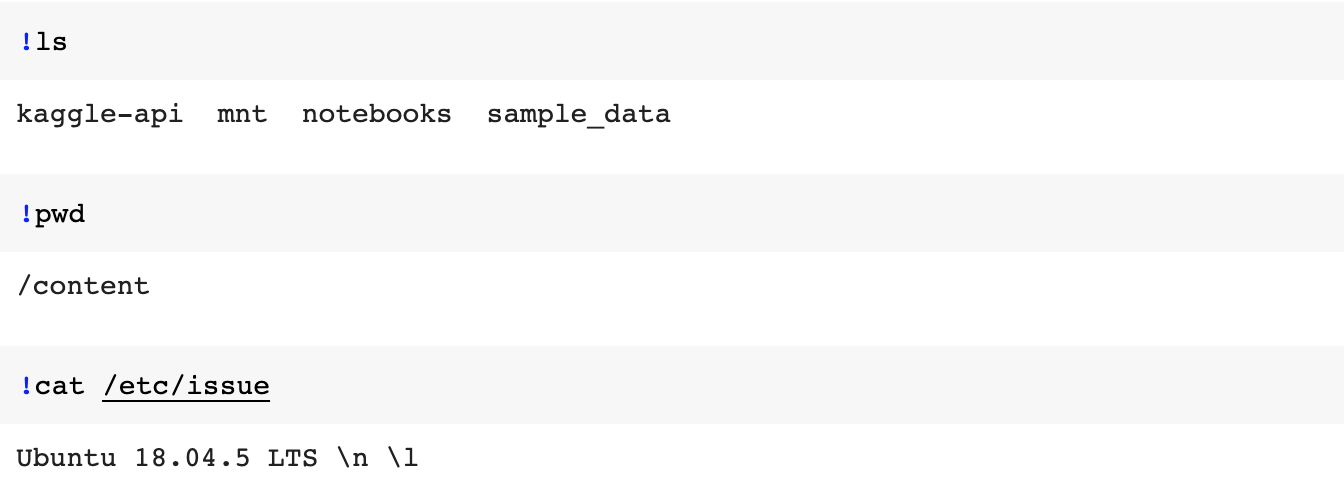
| 파이토치과정 - 6. 구글드라이브,코랩에서 kaggle-api연동 (0) | 2020.11.21 |
| 파이토치과정 - 5. 데이터셋 분리/평가 척도/앙상블 (0) | 2020.11.21 |
| 파이토치과정 - 4. 깃랩저장소와 코랩 연동, 회귀/분류 학습, 시각화까지 (0) | 2020.11.14 |