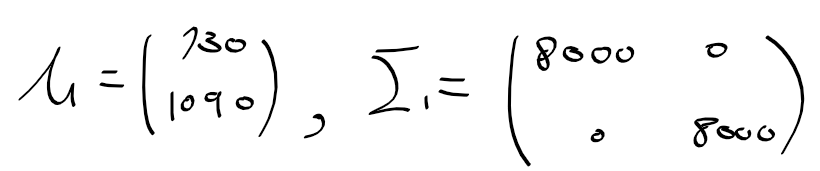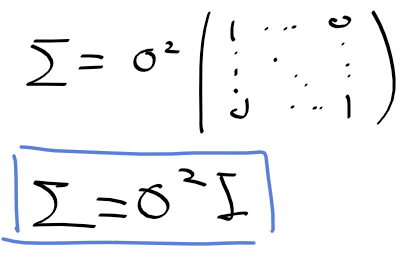베이즈 기준 bayes criterion
- 베이즈 위험을 최소화하는 LRT 결정규칙

MAP 기준
- 비용 값이 1이나 0인 zero-one 비용 함수를 사용하면 베이즈 기준이 P(omega_i | x)의 비가 됨
=> 사후확률을 최대화 시키므로 사후확률 최대화 Maximum A Posterior(MAP) 기준
* 우도비가 아니라 최대화된 사후확률이 결정 함수가 됨

ML 기준
- 사전 확률 P(omega_i)가 같고, zero-one 비용 함수인 경우
=> P(x | omega_i) 우도비로 바로 표현이 가능. 우도비를 최소화 하므로 ML Maximuum Likelihood 기준이라 함.

통계 결정이론에 대한 정리
- 먼저 우도비 검증을 통해 결정 규칙(결정 함수)를 구하는 과정에 대해서 정리.
- 오류 함수로 우도비 검증 방법이 아니라 오류 함수를 최소화 하는 방법으로 결정 규칙을 찾을수 있음을 확인.
- 그동안 사용한 확률은 잘못된 확률에 대해 동일한 가중치(비용)을 부과, 서로 다른 비용을 주고 이에 대한 기댓값이 베이즈 위험, 베이즈 위험을 최소화하도록 하면 결정 경계를 정할수 있었음.
- 이러한 베이즈 위험을 활용한 결정 규칙 방법에 대해 베이즈 기준, MAP 기준, ML 기준 등 확인함.
- 베이즈 기준은 베이즈 위험을 최소화하는 RLT 결정 규칙, MAP 기준은 제로-원 비용함수를 사용하여 사후확률 표현으로 구한 결정 규칙. ML 기준은 제로-원 비용함수를 따르고, 모든 사전확률이 같다고 가정하여 바로 우도로 나타냄.
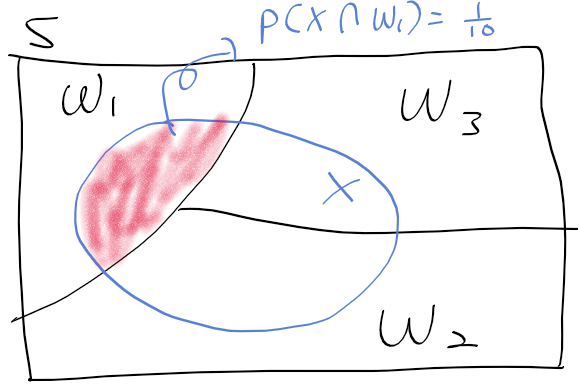
오류 확률이용한 다중 클래스 결정 규칙
- 이전에 본 결정 규칙(결정 경계, 결정 함수)에 대한 문제는 클래스가 2개인 경우만 다루었음. 하지만 다중 클래스 문제로 쉽게 일반화 가능
- 오류 확률과 옳은 확률 표현부터 시작하자
=> 오류 확률 최소화는 옭은 확률 최대화와 동일한 표현

- P(correct)를 사후확률로 표현하면

- 옳은 확률 최대화 하기 위해 적분결과인 gamma_i를 최대화 해야한다.

- 각 적분 gamma_i들 중 p(omega_i | x)를 최대로 하는 omega_i를 선정하면 그 영역 R_i가 옳은 확률 최대영역
=> 오류 확률 최소화하는 결정규칙 = 사후확률 최대화 MAP 기준

'수학 > 공업수학, 확률' 카테고리의 다른 글
| 통계 - 14. 최우추정법을 이용한 확률밀도함수 추정 (0) | 2020.08.04 |
|---|---|
| 통계 - 13. 판별함수 (0) | 2020.08.04 |
| 통계 - 11. 베이즈 위험 (0) | 2020.08.04 |
| 통계 - 10. 오류 확률 (0) | 2020.08.04 |
| 통계 - 9. 우도비 검증 개요 (0) | 2020.08.03 |