최근 파이썬 로보틱스를 진행하면서
깃헙 소스를 돌려보기도 하지만
가능한 이론 내용도 같이 정리하고 있었다.
확률적 로봇 공학 정리를 마무리하고,
파이썬 로보틱스에서 위치 추정 문제, 지도작성, SLAM까지 진행했다.
파이썬 로보틱스에서 제공하는 소스만 클롯받아서 돌려보고 말 수도 있긴한데,
이러한 기술들이 왜 나오고, 이 기술들을 구현한 슈도 코드가
파이썬이라는 언어로 어떻게 실제로 구현되어 동작하는지 분석을 했다.
작년에 파이썬 로보틱스를 보았을때는 확장 칼만필터 위치추정과 SLAM 정도만 겨우겨우 이해했지
지도작성이나 FastSLAM 부분은 제대로 이해하지 못하고 대강 넘긴바 있으나
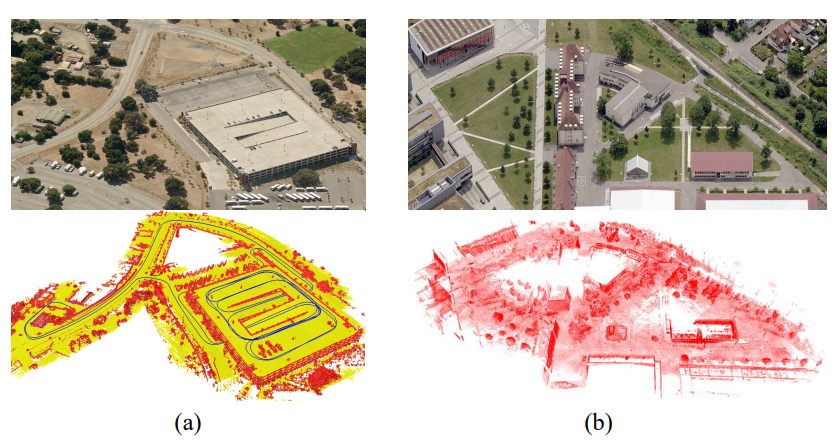
확실이 이번에 확률적 로봇공학을 다시 정리하고 나니 특히 지도작성에서 가우시안 그리드, 광선 투사 그리드 지도 작성방법 부분들까지 이해도가 많이 좋아진것 같아 뿌듯하기도 하다.
그 다음 SLAM 파트에서 EKF SLAM도보고,
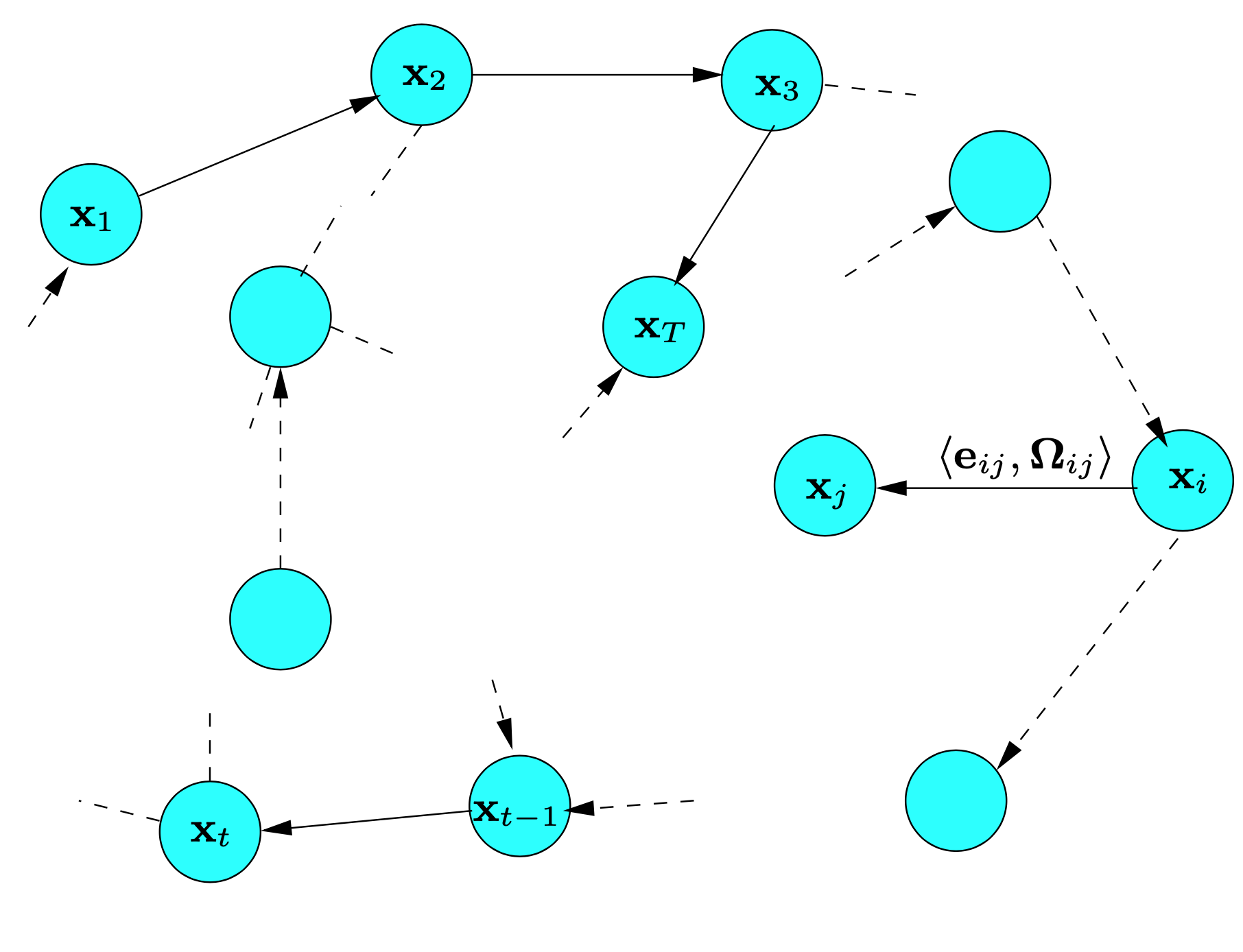
확률적 로봇 공학에서 나오지 않는 FastSLAM과 graph 기반 SLAM 튜토리얼에 대한 자료들을 정리 했다.
원래 나는 군산대 로보틱스 대회를 목표로 막연하게 아래의 순으로 공부하려고 하였지만
위치 추정 -> 지도작성 -> SLAM -> 경로 계획 -> ROS 시뮬레이션 -> 실제 구현
이렇게 공부하는 것이 맞는 건지 고민된다.
작년 중순 쯤 개인 사정으로 취업을 하려고 로봇 관련 업체나 딥러닝을 하는 곳에 지원을 한 적이 있었는데,
당시 나는 확회에서 보는 다른 대학원생처럼 기존 알고리즘을 개선하여 어떤 문제를 해결하긴 커녕
남이 만들어 놓은걸 직접 돌려보기만 하는 수준이었다보니(지금도 그렇지만)
대학원으로서 제대로 만든게 없는것 같아 자존감이 매우 낮은 상태 였었다.
영상 처리 책에 있는 번호판 인식 예제를 구현해본다던가
딥러닝/케라스/탠서플로 책같은걸 보고 신경망 구현해서 학습을 해보거나
ROS 책이나 자료보고 예제 돌려 보는 등
뭔가 나름대로는 열심히 하긴 했었지만 (내가 생각하는) 대학원생 수준이라고 하기에는 너무 창피 했다.
당시 내가 알고 있는 지식으로 SLAM을 설명한다고 하면
SLAM이란 동시적 위치 추정 및 지도작성이다. 가 끝이고 그 이상을 설명 못할 만큼 아는게 없었다.
내가 모르는게 많은건 잘알고 있었지만, 자율주행차 연구를 어쩔수 없이 하게되었을때
자율주행 오픈소스 autoware를 빌드해서 돌려야 하는데 되지를 않으니
한달 동안 울면서 빌드만 한적도 있었다...
막히는 원인과 관련되는 gcc로 어떻게 빌드하는지, 의존 관계가 어떻게 되는지, 라이브러리들 버전들이 다른지 등
빌드 관련 지식들을 잘 몰랐고 너무 급한 마음에 공부할 여유도 없었지만.
그런일만 쌓이고 쌓이니 나는 어디에 가서 연구원으로 활동하기에 많이 부족한것 같고, 좌절한 상태였었다.
그래도 취업은 해야되니 몇몇 업체에 지원을 했었는데,
대학원 생활을 (열심히 하긴 했더라도 남들보다 엉터리로 했으니) 면접 볼 기회조차 없을거라 생각했었다.
하지만 생각보다는 (아주 큰 곳은 아니었지만) 면접 볼 기회가 많았고, 여러 곳에서 합격할 수 있었다.
원래는 그렇게 일 하려고는 했었지만 주변인의 방해로 어쩔수 없이 포기하고 말았었다.
그래도 이런 일이 있으면서, 아무것도 못했다고 좌절하고 있었는데
조금은 내가 완전히 잘못하고 있는건 아니구나 싶어 약간 희망은 얻을수 있었다.
글 쓰다보니 내 취업 얘기로 빠지게 되 버렸는데
SLAM에 대해서 제대로 설명하지도 못한 1년전과 비교하면
지금은 장족의 발전을 하긴 했다.
하지만 다른 컴퓨터 공학 전공자들 처럼 전공 지식을 제대로 배우지 못한게
여전히 나의 발목을 잡고있다.
컴퓨터 과학의 응용 분야인 영상 처리나 로봇 공학, 인공 지능 등을 공부하려면
아래와 같은 이론 학문이 기반이 잘 갖추어 지고 있어야 했는데,
통계론, 확률론, 선형대수, 수치해석, 회귀분석, 다변량 분석
이산수학, 알고리즘, 계산 이론 등
나는 이런 기반 이론 없이 속아서, 아무것도 몰라서, 억지로 시켜서 다짜고짜 딥러닝,
영상처리, 로봇 공학을 하겠다고 삽질하고 다녔으니 제대로 하지 못하고 좌절할수 밖에..
내 딴에는 블로그 정리하면서 공부를 하고 있고,
4월쯤 부터 했으니 이제 3개월 정도가 되었다.
3개월이란 시간 동안 내가 뭘 했나 다시 정리해보면
4월
처음에는 만화로 쉽게 배우는 시리즈로 공학 관련 기초적인 내용들을 살펴봤었다.
- 전기/전기수학/CPU/선형대수/회귀분석(4월 중순 ~ 5월 초)
그리고 중간에 컴퓨터 아나토미라는 책으로
컴퓨터 구조에 대해서 공부하면서 대강 다음 흐름들을 파악 할 수 있었다. (4월 말)
전기 신호-> 스위치 -> 릴레이 -> 트랜지스터 -> 플립플롭 -> 메모리 -> 가산기 -> APU -> 컴퓨터 회로 -> 폰 노이만 방식/ 하버드 방식 CPU -> 기계어 -> 어셈블리어 -> 고급언어
* 이즈음 NAND2TETRIS를 해보려고 했다가 포기했었다.
5월
이후 STEP 교육이란걸 알게 되서 임베디드 시스템 관련해서 다방면으로 공부하기 시작했다. (5월 초~ 중)
ARM 임베디드 시스템 설계 - 임베디드 시스템, ARM, 부트로더, 리눅스 커널, 램디스크, 플래시 파일 시스템, 디바이스 등
펌웨어구현 환경 구축 - 펌웨어, 구현 SW/HW, 디버깅 도구, 교차 개발환경, JTAG 회로도분석, 데이터시트분석, 프로세서 구조, 매모리 맵 등
마이크로프로세서 메카트로닉스 제어 - 회로 시뮬레이션, LED, 릴레이 제어, 스위치, FND, LCD, 인터럽트 등
임베디드 SW 엔지니어링 - 개요, 하드웨어 분석, 펌웨어 분석, 커널 분석 등 ( 5월 말)
이후 제어 공학을 복습 하고, (5월 초)
제어 공학 - 동적 시스템, 질량-스프링-댐퍼, 전달함수, 상태공간, 과도/정상상태응답, 성능및 안정도, 근궤적, PID 제어, 주파수 응답 등
정보처리 기사 실기 시험을 잠시 준비하면서 이전에 학습한 내용을 복습했다. (5월 중 ~말)
네트워크 - 기본 개념, 네트워크 구조, TCP/IP 프로토콜, 주소 체계, 인터넷/라우팅/ 전송계층 프로토콜
데이터베이스 - DBMS, 모델링, SQL, 개념적/논리적 설계, 정규화 등
소프트웨어 공학 활용 - 소프트웨어 개발 라이프사이클, 개발 방법론, 모델, UML 등
기타..
6월
정처기 시험을 마무리하고, 소형 무인 비행체를 복습했었으나 (6월 초)
배경 지식이 부족하고, 더이상 진행하기가 어려워 중간에 마쳤다.
소형 무인 비행체 - 좌표계, 기구/동역학, 힘과 모멘트, 선형모델 설계, 오토파일럿 설계
그 다음에는 이론 지식들을 공부하겠다고 수치해석을 시작했다.(6월 초)
이 내용도 생각보다 이해하기 힘들어서 많이 나가지는 못했다.
수치해석 및 실습 - MATLAB, 배열, 그래프, 오차 해석, 보간다항식, 차분표, 방정식 해법
그 다음으로 이산수학과 알고리즘 (6월 초 ~ 중순)
이산 수학은 그래도 필요한 부분만 전반적으로 살펴 보기는 했으나
알고리즘의 경우 중반 까지는 그래도 이해할만 했으나 NP완비 부터는 간략하게 훑어보기만 했다.
이산수학 - 집합, 수, 관계, 그래프, 트리, 순열, 확률 등
알고리즘 - 설계 분석 기초, 점화식과 복잡도, 수열, 정렬, 선택, 자료구조, 이진 검색트리, 해시테이블, 동적 프로그래밍, 그래프 알고리즘, P와 NP문제, 근사 알고리즘, 상태 공간 트리
6월 중순까지 수치해석, 이산수학, 알고리즘에 대해서 간단하게 살펴보고 나서 로봇 공학 관련해서 복습하기 시작했다.
우선 파이썬 로보틱스의 칼만 필터 기초와 칼만, 베이즈 필터 자료에 대해서 살펴봤다.(6월 중순경)
파이썬 로보틱스 칼만 필터 기초 - 가우시안, 확률 모델, 확률 생성법칙, 조건부 확률, 베이즈 법칙/필터 와 칼만필터
칼만,베이즈 필터 - 파티클 필터, 몬테카를로 방법
확률적 로봇 공학(6월 말)
작년에 논문쓰면서 확률적 로봇 공학을 이해도가 많이 부족하긴 했지만 공부했기 때문에
파이썬 로보틱스 예제를 공부하면서 로봇 공학 전반에 대해서 살펴보려고 했었다.
하지만 기반 지식이 너무 부족해서 코드나 로직들이 이해하기 너무 어렵더라,
그래서 다시 확률적 로봇 공학을 보기 시작했다.
- 베이즈필터 -> 가우시안 필터 -> 비가우시안 필터 -> 동작 모델 -> 관측 모델 -> 칼만/격자/몬테카를로 위치 추정 -> 점유 격자지도작성 -> SLAM -> 정보 SLAM 등
작년에도 SLAM 까지 전반적으로 다 훑어보긴 했지만 관측모델이나 지도작성 등
이해하지 못한 부분들이 많았으나 이번에 다시보면서 더 확립할 수 있었고,
진도를 조건 다나아가 정보 필터를 이용한 개념들에 대해서도 완벽하지는 않지만 조금 살펴볼 수 있었다.
개념정리(6월 말)
하지만 확률적 로봇 공학을 정리하면서 힘들었던 점들이 많았는데
이번에 정리하기 이전에 회귀분석, 이산수학, 알고리즘 등 이론 내용들을 공부하면서 배경 지식을 쌓기는 했지만
이 확률적 로봇공학에서 사용하는 개념들 중에 여전히 이해가 되지 않는것들이 너무 많았다.
- 유전 알고리즘, 언덕 오르기, 휴리스틱, 분기 한정, rule of thum, 베이지안 네트워크, 우도, 휴리스틱, ad hoc hypothesis 등
이런 용어들을 어떻게 한번 훑어볼수 있을까 고민하다가. 우연히 aistudy 사이트를 다시 찾았고, 이 사이트의 내용으로 가끔가끔 보긴 했으나 제대로 공부하긴 귀찬아서 넘어가던 개념들을 얕개나마 정리할 수 있었다.