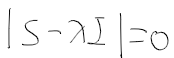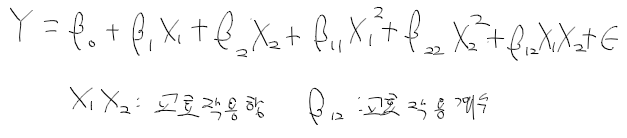19세기 과학자들의 통계적 추론에 대한 생각
- 뉴턴의 방정식 처럼 수학 방정식으로 설명가능하다고 생각
* 라플라스의 경우 모든것을 알면 과거, 현재, 미래를 설명 및 예측가능하다고 봄.
=> 관측할 때마다 방정식대로 결과가 나오지 않음. -> 관측 오차라 생각.
- 관측 성능이 좋아져도 오차가 제거되지 않음.
현대 물리학 관점
- 방정식이나 기계같지 않고 불확실함.
불확실한 세상 파악방법
- 세상이 확률 분포를 따른다 가정하고, 측정 -> 측정 결과 = 데이터
통계적 추론 statistics inference
- 불확실한 세상을 데이터 기반 추론
- 활용 범위 : 여론 조사, 이미지 인식, 문자 인식, 상품 추천 ㅡㅇ
통계적 추론의 기본 가정
- 세상은 불확실함. 불확실성을 가능성, 확률로 표현
- 세상을 완전히 알수 없음
통계적 추론 원리
- 가장 가능성 높은 결론을 구하자
- 가능성이 낮은 일은 믿지 말자
통계학 정의
- 켄들, 스튜어트 : 자연현상의 성질 측정 데이터를 다룸
- 밀러 : 데이터가 갖는 정보를 이해하는 방법
- 키핑 : 예측 불가능한 변동하는 변수를 다루는 학문
- 체르노프 : 불확실한 상호아서 의사 결정
통계학 정의 정리
1. 관심 대상에 대한 데이터 수집
2. 데이터 요약 정리
3. 불확실한 사실에 대한 결론을 이끌어내는 방법
통계 관련 용어 정리
- 모집단 : 관심 대상 전체 집단
- 표본 : 관심 대상 일부
- 확률 : 사건 발생 가능성
- 확률 분포 : 모집단, 표본을 나타내며 몇개의 모수 parameter로 나타냄.
- 확률 변수 : 관심 변수. 표본 공간의 사건을 숫자로 바꿔주는 함수.
- 통계량 statistic : 표본에 대한 함수 ex. 표본평균, 표본분산
- 표본 분포 : 표본이 확률 변수이므로, 표본에 대한 통계량도 확률 변수. 통계량에 대한 분포
- 통게적 추론 : 통계량으로 모집단의 모수 추정 혹은 검증하기 위한 이론과 방법
통계적 추론과 현실
- 통계적 추론방법은 사고 실험을통해 정립
- 실제 데이터 분석은 이론과는 맞지 않은 문제
- 모집단은 알수 없고, 관측값과 사전 정보만을 알음. 이걸로 모집단에 대해 의사결정 수행
추론이란?
- 알고 있는 것으로 결론을 도출하는 방법
- 연역적 추론 : 이미 있는 결론으로 새 결론 유도
- 귀납적 추론 : 다수 관측으로 결론 유도
- 통계적 추론 : 표본을 이용하여 모집단에 대한 결론을 구하는 귀납적 추론 방법
=> 표본의 정보(통계량)으로 모집단에 대한 모수 추정. 불완정성을 확률로 표현
통계적 추론의 단계
1. 추정 : 표본으로 모집단에 대한 결론 도출
2. 검정 : 모집단 관련 주장에 대한 타당성 점검 => 표본의 정보가 우연인지, 모집단에 존재하는것인지 검토
통계적 추론에 필요한 이론
- 확률 이론 : 모집단/표본 통계량은 어떤 분포를 따르는가. 모집단 가정하에 표본이 어떻게 분포하는가.
- 추론 이론 : 표본으로 모집단을 어떻게 추정해야 타당한지에 대한 이론.
통계적 추론 과정
- 모집단은 모수 theta를 따르는 확률 분포를 따름.
- 확률 분포는 확률 변수의 점확률(pmf, pdf f(x|theta))이 됨.
* X ~ N(mu, sigma2)로 가정
- bar{x}는 모평균 mu를 추정하기 위한 통계량.
-> 표본수가 큰경우. 중심극한정리를 따라 근사적으로 정규분포 따름
-> 표본수가 작을시. 표준화된 bar{x}는 t분포 따름.
- 추정에 필요한 통계량 -> 추론의 원리 이해 필요
ex. 가능도 원리, 충분성 원리
* 가능도 원리 liklihood principle : 표본의 joint pdf가 가능도 함수로 표본의 모수를 가지는 원리
* 충분성 원리 sufficiency principle : 표본을 요약한 통계량이 모수 정보를 안 잃으면 충분성을 가짐.
=> 추정 통계량은 충분 통계량 기반으로 설계.
- 추정량의 유용성 : 평균제곱오차를 최소화 하는 통계량이 유용하다고 봄. 것으로 모집단 모수 추정
* 평균 제곱 오차 : 손실함수(모수 - 추정량)의 기대값
- 검정 : 확률 표본으로 새로운 가설(대립가설)이 타당한지 보는 방법.
-> 귀무가설 통계량 도출. 통계량이 가정에 대해 극단적인 값을 가질 시 가정은 기각
=> p value(한계 유의 기준, 유의확률)이 alpha(유의기준)보다 작은 경우 귀무가설 기각. 대립가설 채택
- 최적 검정 : 1종 오류 기준 하에 2종 오류를 최소화
* 제 1종 오류 : 귀무 가설이 참이나 기각되는오류
* 제 2종 오류 : 대립 가서이 참이나 기각되는 오류
통계적 추론 관점에 따른 분류
- 빈도론자 frequentist와 베이지안 baysian에 의한 추론으로 분류
- 빈도론자 : 모수를 표본에 대한 통계량의 표본분포 기반으로 추정, 검정
- 베이지안. 베이즈 주이자 : 주어진 데이터와 모수의 사전 확률 기반으로 사후 확률 계산
빈도론자 vs 베이지안
- 베이지안 : 사전 분포에 의존하여 결과가 일정치 않고 계산시간, 비용이 큼
- 빈도론자 : 추정 방법, 통계량에 따라 결과가 일정치 않음 + 주어진 정보 활용 x
현대 통계적 추론
- 어떻게 주어진 데이터로 공정하게 추측할까
- 통계학자가 할일 : 불확실성을 구조화하고 계산하는 것.
- 빈도적, 베이지안 방법을 종합하여 활용해야함.
통계적 추론 역사
- 20세기 전 : 가우스와 라플라스 식으로 데이터 요약
- 20세기 초 : 적은 수의 데이터를 확률 모형으로 만들어 분석, 추론 시작
*** 칼 피어슨, 이곤 피어슨, 피셔, 고셋, 네이만 ***
- 1901 : 칼피어슨의 적합성 검정 논문 chi-square 검정
* 칼 피어슨
- 표본 자체가 확률 분포를 가진다고 봄 -> 모수 측정 불가. 측정값 산포로 유추.
- 관측 현상은 임의적인것, 확률 분포가 존재
- 평균, 분산, 왜도, 첨도로 확률 분포 파악 가능.
- 카이 제곱 검정 : 관측 값을 범주들로 분류, 해당 범주 관측값 수와 이론 분포에 나오는 기대 관측 수 차이 이용.
=> 유의성 검정에서 활용
- 1908 : 고셋의 평균에 대한 오차(t 분포: 적은 데이터 기반 검정, 추정에서 사용하는 분포)
=> 표본이 작은 경우 표본 평균이 어떤 분포를 따르는가 연구 -> 스튜던트 t의 분포.
- 이후 칼 피어슨의 업적
1. 가능도 함수와 최대 가능도 추정법 제시.
2. 유의성 검정 제안.
3. 랜덤화와 분산분석으로 실험 계획 연구 -> F분포와 F검정 고안
- 네이만과 이곤 피어슨 : 유의성 검정 방법 제안
1. 귀무 가설, 대립가설 구분
2. 검정 행위 채택, 기각 구분
3. 최적 검정이론 연구
- 1930년대 네이만 : 신뢰구간(모수 점추정에 대해 변동성이 필요하다고 봄) 제시
- 1930년대 호텔링 : 다변량 분석
- 1977년 튜키 : 탐색적 데이터 분석
'수학 > 통계' 카테고리의 다른 글
| 다변량분석 - 5. 다차원 척도법 MultiDemensional Scaling (0) | 2020.11.26 |
|---|---|
| 다변량분석 - 4. 인자 분석 (0) | 2020.11.10 |
| 다변량분석 - 3. 주성분 분석 (0) | 2020.11.09 |
| 다변량분석 - 2. 다변량 분석과 데이터 시각화 (0) | 2020.11.03 |
| 다변량분석 - 1. 다변량 분석과 R 기초 (0) | 2020.11.03 |