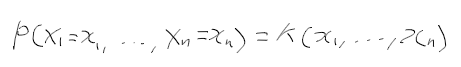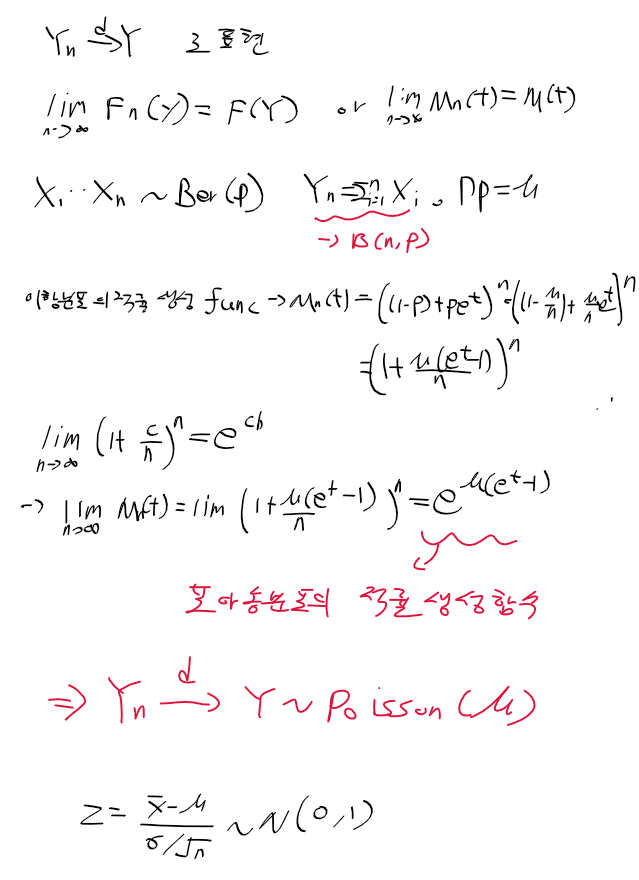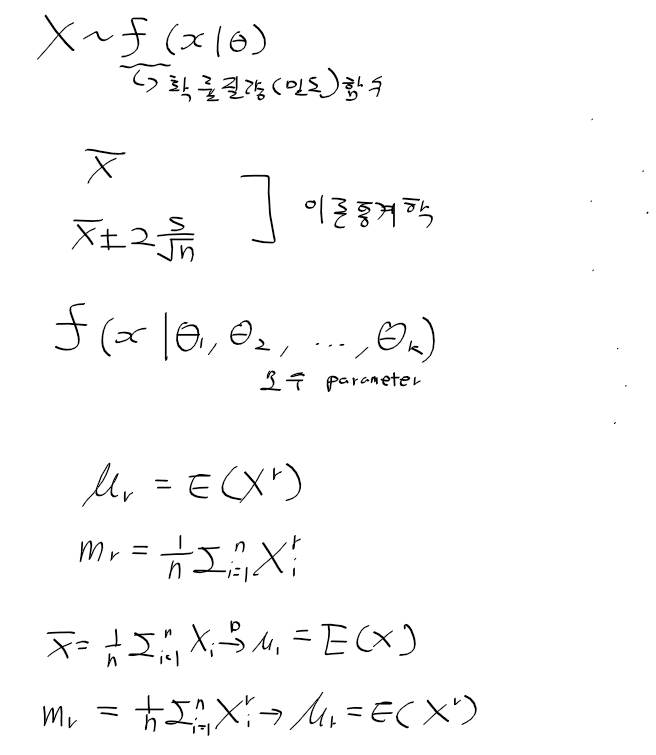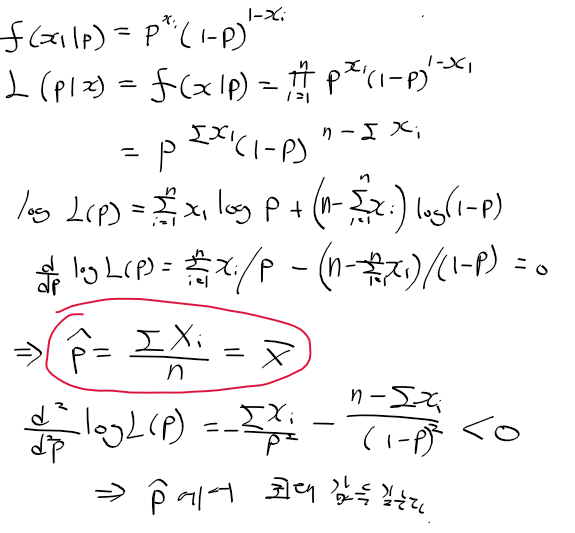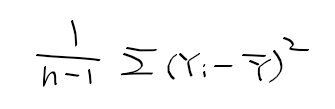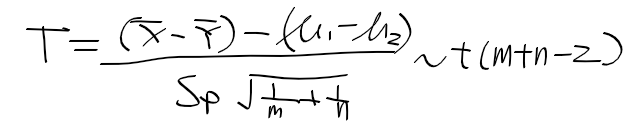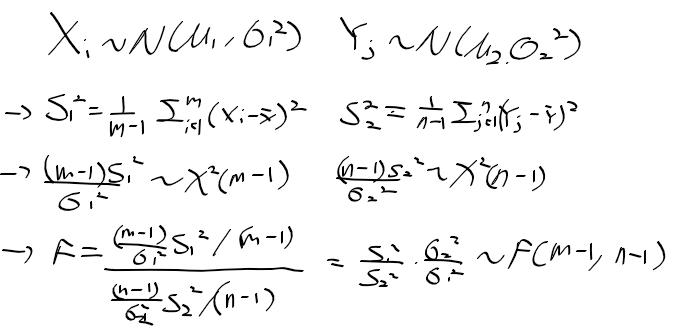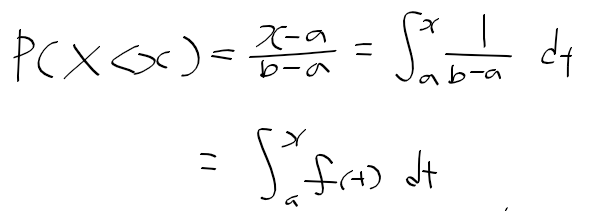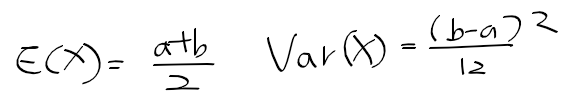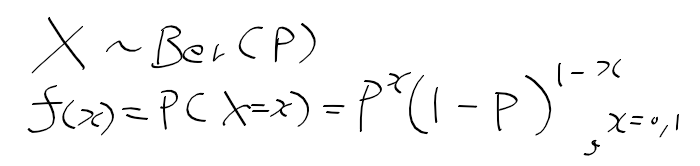용어
- 추정 : 표본으로부터 모집단에 대한 값을 구해나가는 것
- 추정량 : 모수를 추정하기위한 표본의 함수
- 모수 : 모집단에 대한 특성을 나타내는 값
- 점 추정 : 모수에 대한 추정
- 구간 추정 : 점 추정 + 정확도 추정
- 신뢰 수준 : 모수의 참값이 속할것으로 기대되는 구간안에 모수가 포함될 가능성 확률
통계적 추론
- 우리 주위에 대한 데이터 수집, 요약
- 수집한 데이터로부터 일반성을 찾음
- 불확실한 사실에 대한 결론, 예측
기술 통계학 descriptive statistics
- 데이터의 특성들을 요약, 정리
(표본 평균, 표본 분산 등)
- 판단하기 힘듬
통계적 추론 구조
- 모집단 : 알고자 하는 관측 대상 -> 모든 관측값의 집합. 전체다 알기 힘듬
- 표본 : 모집단의 일부 -> 모집단에서 임의추출하여(모집단을 잘 대표하도록) 모집단을 추측한다.
- 모집단의 변수들은 어느 확률 분포를 따름
- 확률 분포 : 몇개의 모수(평균, 분산, 첨도, 왜도, 람다 등)으로 구성된 수리적 함수
-> 이항 분포, 정규 분포 등
모집단의 파악
- 정규 분포의 모수 : 모 평균과 모분산
- 이항분포의 모수 : 모비율
- 카이제곱 분포, t분포는 자유도에 의해 결정
통계적 추론 구조
- 통계량 : 표본의 함수 -> 모수를 추정
-> 표본 평균, 표본 비율, 표본 분산 등
- 추정량 : 모수를 추정하는데 사용되는 통계량
- 추정값 : 관측된 데이터를 추정량(통계량)에 대입하여 얻은 값
추정량의 분포
- 추정량은 추출한 표본들에 따라 변화하게 됨
=> 표본 분포 sampling distribution
* 표본 분포는 추출한 샘플들에 따라 달라짐
여론조사의 분포?
- 표본들이 매번 바뀌기 때문에 표본 분포는 다름
추정과 검정
- 추정 : 표본으로부터 모집단에 대한 정보인 모수를 추측함.
- 검정 : 모집단과 관련된 주장에 대한 타당성을 표본으로 점검
-> 표본으로 얻은 증거가 우연인지 아닌지 점검
추정
- 점추정 : 모수에 대한 하나의 추정값을 구함
- 구간 추정 : 모수에 대한 추정값과 정확도를 구함
ex. 3% +- 1%
- 모수 theta에 대해 두 통계량 (L, U) : theta의 (1-alpha) x 100% 신뢰구간
P(L < theta< U) = 1 - alpha
* Lower bound 하한, Upper bound 상한
적합한 추정량
- 불편성, 일치성, 효율성
- 불편향성 : 가능한 모든 통계값의 평균이 모수가 됨
-> 표본 평균은 모평균의 불편향 추정량
- 일치성 : 표본 크기가 커질수록 추정량의 값과 모수가 더 가까워짐
-> 표본 평균의 분산은 표본크기가 커지면 0, 표본 평균은 모평균에 근점
- 효율성 : 추정량중 분산이 작은것을 의미
바람직한 추정량을 구하는 방법
- 최대가능도 추정법
- 적률 추정법
- 최소제곱 추정법
최대 가능도 추정법
- 미지의 모수를 가지는 모집단의 분포에서 확률 표본을 추출하여 추정량찾음
- 표본의 몯느 정보는 결합확률밀도함수인 가능도 함수에 있으므로 최대 가능도 추정법으로 찾음
'수학 > 통계' 카테고리의 다른 글
| 통계 - 14. 구간추정 (0) | 2020.10.27 |
|---|---|
| 통계 - 13. 통계적 가설 검정 2 (0) | 2020.10.26 |
| 통계 - 11. 통계적 가설 검정 (0) | 2020.10.26 |
| 통계 - 10. 점추정량 비교2 (0) | 2020.10.26 |
| 통계 - 9. 복습? (0) | 2020.10.26 |