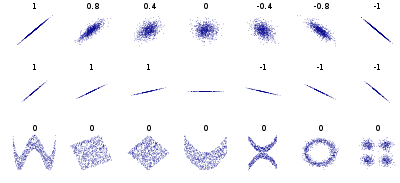
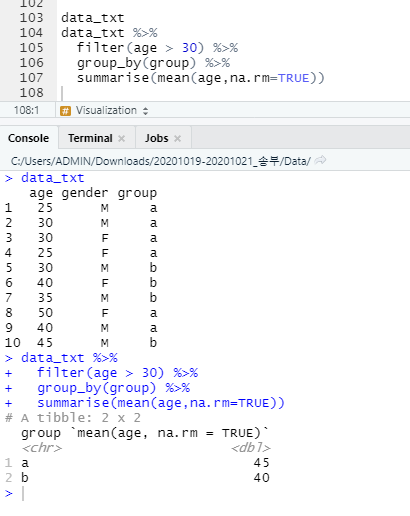
확률의 현재
- 불확실성을 다루기 위해 학문과 생활속에서 다양히 활용
배워야 할것들
- 확률 정의 definition of probabliistic
- 확률 분포 probabilistic distribution 특성과 계산하기
- 표본 분포 sample distribution와 확률 과정 stochastic process
- 시뮬레이션
확률을 진짜 이해하기 위해선
- 프로그램으로 돌려보는게 좋다.
- 가장 가능성 높은 결과를 예측하고 의사 결정에 활용
파스칼, 페르마와 주사위 도박
- 2명은 각각 32피스톨(화폐 단위)를 가진다.
- 3판을 이기면 승리.
- A가 2, B가 1판 이긴경우 배분
주사위 도박 승자 확률
- 일반적인 생각 : A에는 2/3, B는 1/3
- B는 두판을 더 이겨야 하므로 B가 이길 확률 0.5 ^2 = 0.25
- A가 이길 확률 1 - (B가 이길 확률) = 0.75
- 배분 : A는 64 x 0.75, B는 64 x 0.25가 공정
=> 기댓값 : 확률 변수 평균 개념 지표
확률의 적용 범위
- 생물학, 물리학, 경제학, 통계학, 경영학, 로봇 공학 등 현대 과학 모든 분야
확률의 수학적 정의
- 어떤 사건이 일어날 가능성 0 ~ 1의 실수
- 다양한 확률의 정의들 : 상대도수적 정의, 기하학적 정의, 고전적 정의, 공리적 정의
동전 앞면이 나올 확률
- 확률 = 앞면 나온 횟수/ 전체 시행 횟수
상대도수적 확률의 정의
- n번 시행중 사건 A가 a번 발생했을때 사건 A가 일어날 확률 P(A)
- P(A) = a/n
- 100만번 동전 던져서 앞면이 나올 확률 = 500,000/1,000,000
- 야구의 타율 타석수 250, 안타수 103 => 0.412 타율 = 103/250
- 문제점 : 같은 조건에서 통계 실험을 계속 반복하기 힘듬. => 컴퓨터 시뮬레이션으로 실험 가능해짐
기하학적 확률
- 일부의 길이 또는 면적 / 공간 전체의 길이 또는 면적 => 면적의 비율
확률 구분
- 주관주의 확률 subjectivism : 몇번 시행(경험)으로 구한 확률(느낀 확률, 믿음의 정도 degree of belief)
- 객관적 확률 : 많은 시행으로 구한 확률
정의 : 수학적 정의 확률, 상대도수적 확률, 기하학적 확률
구분 : 주관주의 확률, 객관적 확률
표본 공간과 사건, 고전적/공리적/여사건 확률에 대하여
표본 공간 : 통계적 실험 모든 가능한 결과 집합
사건 : 표본 공간의 부분 집합
고전적 확률 : 사건의 원소수를 표본 공간의 원소수로 나누어 구한 확률
공리적 확률 : 고전적 확률을 일반화 시킨 확률
집합과 원소
- 집합 set : 명확하게 구분된 원소들의 묶임
- 원소 element : 구분 가능한 요소
집합의 표현
- 원소 나열법 혹은 조건 제시법으로 표현
- 원소 나열법 : A = {1, 2, 3, 4, 5}
- 조건 제시법 : A = {n은 자연수| 1<= n <= 5}
부분 집합
- 집합 B의 모든 원소가 집합 A에 속하는 경우 부분집합
- ex) A = {1, 2, 3}, B = {1} => B는 A의 부분 집합
그외 집합
- 전체 집합 U : 표본 공간
- 공집합 : 원소가 하나도 없는 집합
- 합집합 : 두 집합의 합한 집합
- 공집합 : 두 집합의 공통된 원소로 이루어진 집합
- 여집합 : 전체 집합에는 속하지만 A에 속하지 않는 집ㅎ바
- 차집합 : A - B, A에 속하나 B에 속하지 않는 집합
표본공간 S ; sample space
- 통계적 실험시 모든 가능한 결과로 이루어진 집합
- 사건 : 표본 공간의 부분 집합
동전 던지기의 표본 공간
- 앞면 H, 뒷면 T 이라 하는 경우
- S = {H, T}
고전적 확률
- 표본공간 : S = {e1, e2, .., ei, ..., ek} => n(S) = n
- 사건 : A = {e1, ..., ei} => n(A) = k
- 확률 P(A) = 사건(사상) A의 원소 개수/ 표본 공간 S의 원소 개수
= k / n
동전 던져서 앞면이 나올 확률
- S = {H, T}
- A = {H}
- P(A) = 1/2
주사위 던져서 짝수가 나타날 확률(고전적 확률)
- S = {1, 2, 3, 4, 5, 6}
- A = {2, 4, 6}
- P(A) = 3/6 = 1/2
=> 고전적 확률 계산시에 사건 원소 개수가 중요
복원 추출
- n개 중에서 r개를 복원 추출 : n^r
비복원추출
- n개 중 r개를 비복원 추출(순서 고려) : nPr = n!/(n-r)!
- n개중 r개 비복원 추출(순서 비고려) : nCr = n!/(n-r)!r!
로또복권에서 1등에 당첨될 확률
- A = 1등 당첨
- 45C6 = 45!/6!(45-6)!
- P(A) = 1/8,145,060
공리적 확률
- 0<= P(A) <= 1
- P(S) = 1