통계적 현상 statistical phenomena
- 여러번 관찰해서 법칙을 찾아낼수 있는 현상
확률 실험
- 반복 할수록 규칙성이 존재하는 행위
확률
- 특정 현상이 확실히 발생할 정도
확률 법칙
- 임의의 실험에서 사건에 확률을 배정하는 규칙
수학적 확률
- 표본 공간 S과 S를 구성하는 사건 A가 있을때, 다음의 P(A)를 수학적 확률
* 수학적 확률은 각 사건들이 일어날 가능성이 모두 동일하다고 가정
* 동전 2개를 던질때 앞면이 0개, 1개, 2개가 나올 확률을 다 동일하게 1/3, 1/3, 1/3이라고 가정하면 안됨.

통계적 확률
- 동일한 현상이 일어날지 불확실한 경우, 여러번 실험해서 얻은 사건에 대한 확률은 상대적인 횟수로 추정
- 상대적인 횟수 relative frequency는 n번 실험할때 r회 일어난 경우 r/n.
* 동전 2개를 던질때 앞면이 0개, 1개, 2개가 나올 (통계적) 확률은 1/4, 1/2, 1/4
수학적 확률과 통계적 확률의 차이
- 수학적 확률은 표본 공간을 구성하는 사건들이 동일한 확률을 가지고 있다고 생각
- 통계적 확률은 여러번 반복했을때 나온 정도(상대적 횟수)로 확률을 추정
통계적 확률 정리
- n회 실험 할때, A의 상대 횟수 r/n이 특정한 수 p에 수렴하는 경우 => 통계적 확률

- 정확한 p 값은 알수 없으나, n이 충분히 크다면 근사적으로 상대 도수를 통계적 확률로 본다.
표본 공간 sample space과 확률 공간 probability space
- 표본 공간 : 관측으로 얻은 결과 집합
- 사건 : 표본 공간의 부분 집합
- 확률 공간 : 표본 공간을 확률에 대응시킨 결과 집합

주변 확률과 조건부 확률
- 주변 확률 marginal probability : 두 사건 A, B가 존재할때, A나 B 한 가지의 사건만 일어날 확률
- 조건부 확률 conditional probability : 두 사건 A, B가 발생 했는데, B의 확률을 알때 A가 일어날 확률

전체 확률 이론 total probability thorem
- 사건 A들의 합집합이 표본 공간이고, 서로 배타적일때 사건 B는 다음의 그림과 같이 구성됨.
- 사건 B의 확률은 B와 사건 A들의 교집합들의 합

귀납적 추론과 연역적 추론
- 통계학은 대부분의 경우 표본에서 모집단을 추정
=> 귀납적 추론 inductive inference : 개발적 사건으로 일반적 법칙 유도
- 연역적 추론 deductive inference : 일반적 법칙으로 개별적인 사건 유도
베이즈 정리 bayes thorem
- 일반적인 법칙을 알수 없는 불확실한 상황에서 의사 결정 문제를 다룰때 중요하게 사용됨
- (연역적 추론 방식인) 확률로 (일반적인 법칙을 유도하는) 귀납적 추론 방식을 행하는 행위
베이즈 정리와 확률의 의미
- 기존의 확률 : 직접 확률 direct probability
- 베이즈 정리 : 역확률 inverse probability
베이즈 법칙(정리?)로 정리하기
- 표본 공간 S와 분할 영역 A들이 주어질때, B가 난 경우 A_i에서 일어날 확률이 얼마나 될까?
- 조건부 확률 conditional probability 을 전체 확률 정리 total probability thorem으로 정리하면
=> 사건 B가 발생했을때 A_i가 일어날 확률을 알고 싶으나 모르는 경우
사건 A_i가 일어났을때 B가 일어날 확률을 안다면 구할수 있다.
* 개별적 사건에 대한 확률로 일반적인 법칙을 추론해냈다?

통계적 패턴인식에서의 베이즈 정리
- 특징 벡터 x가 관측되었을때 클래스 omega_i를 찾자. P(omega_j | x) = ?
=> p(x | omega_i)를 알면 구할수 있다. (클래스가 주어질때, 특징 벡터 관측에 대한 조건부 확률)
- 베이즈 정리 : 우도를 알때 사후 확률을 구하는 정리


베이즈 정리 용어 정리
- 사전 확률 priori probability : P(omega_1). 클래스 omega_1의 확률

- 정규화 상수 : p(x), x 확률 결정에 영향을 주지않는 정규화 상수

- p(omega_1 교집합 x ) = 1/10 (임의로 정의)
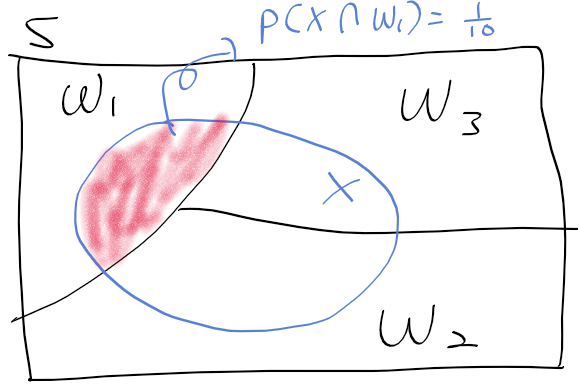
- 우도 likelihood : 클래스 omega_i가 주어질때, 관측 x이 일어날 확률

- 사후 확률 posterior probaility : 관측 x이 있을때, 클래스 omega_1에 속할 확률
=> 특징 벡터 x가 관측되었을때, 분류한 결과가 omega_1일 확률은 0.3
=> 특징 벡터 x는 30%의 확률로 omega_1로 분류된다!!