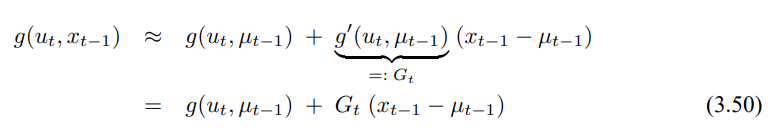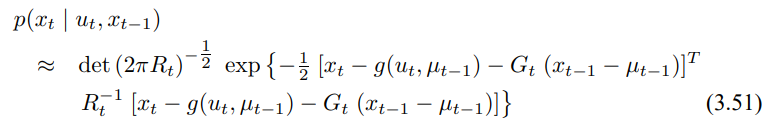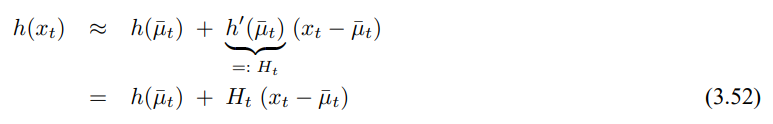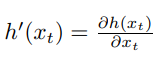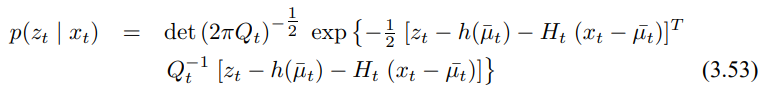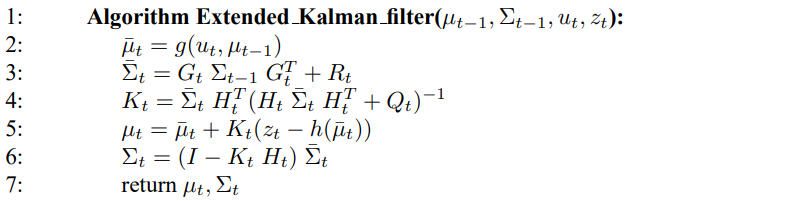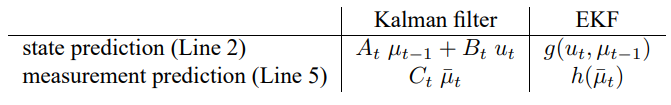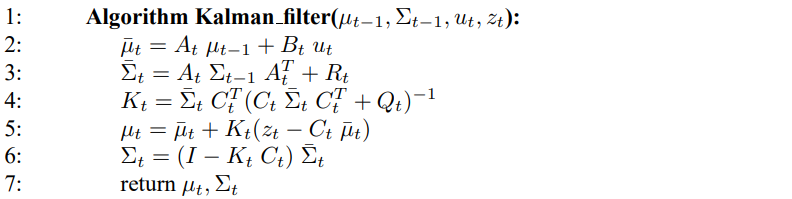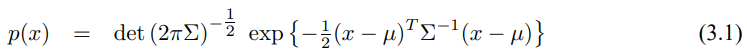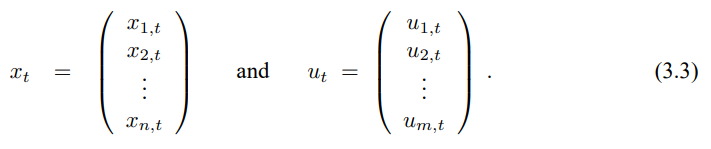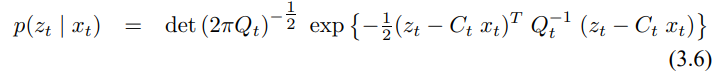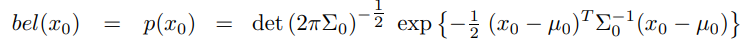4.2.1장의 파티클 필터에서는 $x_t$, $u_t$, $x_{t-1}$를 계산하는 대신 모션 모델 p($x_t$ | $u_t$, $x_{t-1}$)로 샘플링을 해도 충분했었습니다. 이 조건부 밀도 확률로 샘플링하는건 밀도 확률을 계산하는것과 다른데, 샘플링에서는 $u_t$, $x_{t-1}$이 주어질때 동작 모델 p($x_t$ | $u_t$, $x_{t-1}$)에 대해서 임의의 $x_t$를 생성하게 됩니다. 하지만 밀도 함수를 계산시에 다른 평균으로부터 구한 $x_t$가 주어지면 p($x_t$ | $u_t$, $x_{t-1}$)를 따르는 $x_t$의 확률을 계산합니다.
표 5.3. 자세 샘플 알고리즘
- 위는 자세 $x_{t-1}$ = (x y $\theta$$)^T$와 제어 $u_t$ = (v $\omega$$)^T$로부터 샘플 자세 $x_t$ = (x' y' $\theta$'$)^T$를 구하는 알고리즘으로, 추가적인 임의의 값 $\hat{\gamma}$로 마지막의 방위가 동요됩니다. 여기서 $\alpha$ 1 ~ $\alpha$ 6까지는 동작 노이즈의 파리미터들이며, 샘플(b) 함수는 분포 b의 영평균으로부터 구한 샘플을 생성시킵니다. 이 함수는 표 5.4와 같습니다.
표 5.4 영평균, 분산 b를 따르는 근사 정규/삼각 분포로부터 샘플링 하는 알고리즘
- 여기서 함수 rand(x, y)는 구간 [x, y]에서 균일 분포를 따르는 난수 생성기가 됩니다.
표 5.3의 샘플 동작 모델 속도 sample motion model velocity는 p($x_t$ | $u_t$, $x_{t-1}$)로부터 $u_t$와 $x_{t-1}$을 사용하여 임의의 샘플을 생성합니다. 여기서 $x_{t-1}$, $u_t$를 입력으로 하여 분포 p($x_t$ | $u_t$, $x_{t-1}$)를 따르는 임의의 자세 $x_t$를 만드는데, 2~4번째 줄은 동작 모델 기구학 에러 파라미터로 나타내는 노이즈로 인해 제어 파라미터를 동요시키게 되는데 이 노이즈 값들은 5 ~ 7줄에서 샘플의 새 자세를 만드는데 영향을 줍니다. 그래서 샘플링 과정은 예측 시에 제어 노이즈를 합치도록 물리적인 로봇의 동작 모델을 만들게 됩니다.
그림 5.4는 샘플링 루틴의 결과로 여기서 샘플 동작 모델 속도로 500개의 샘플을 생성한 것을 볼 수 있습니다. 그림 5.3의 밀도와 한번 비교해서 보세요.
그동안 많은 경우들에서 $x_t$가 주어질때 밀도를 계산하기 보다 $x_t$를 샘플링하는게 쉽다는 것을 볼 수 있었습니다. 이는 샘플이 물리적인 동작 모델의 전방향 시뮬레이션을 요구하기 때문인데, 가정 자세에 대한 확률을 계싼하기 위해서 물리적 동작 모델의 역을 계산하는게 필요하기 때문입니다. 파티클 필터는 점을 이용하여 구현함으로서 더 쉽게 수행할 수 있습니다.
속도 동작 모델은 로봇을 2개의 속도 회전과 평행이동 속도로 제어한다고 가정하며, 대부분의 상업 로봇들이 속도를 이용한 제어 인터페이스를 제공하고 있습니다. 기차 구동 시에는 차동 구동, 애커맨 구동, 동기 구동, 다른 홀로노믹 구동 등의 방법들로 제어되며, 구동 시스템은 논 홀로노믹 제약 없이 이 모델을 적용시킬수가 없게 됩니다.
이제 평행이동 속도를 $v_t$라 하고, 회전 속도를 $\omega_t$라 할때 다음 식을 얻을 수 있습니다.
여기서 양의 회전 속도 $\omega_t$는 시계 반대 방향으로 (왼쪽으로)회전을 하며, 양의 평행이동 속도 $v_t$는 전진 운동을 수행합니다.
5.3.1 닫힌 폼 계산 closed form calculation
확률 p($x_t$ | $u_t$, $x_{t-1}$)을 계산하기 위한 알고리즘은 표 5.1과 같습니다.입력으로 초기 위치 $x_{t-1}$ = (x y $\theta$ $)^T$와 제어 $u_t$ = (v, $\omega$ $)^T$, 가정 자세 hypothesized successor pose $x_t$ =($x^'$ $y^'$ $\theta^'$ $)^T가 됩니다. 이 알고리즘의 출력은 상태 $x_{t-1}$에서 제어 $u_t$를 수행한 후에 $x_t$로 확률 p($x_t$ | $u_t$, $x_{t-1}$)가 됩니다. 여기서 파라미터 $\alpha_1$ ~ $\alpha_6$은 로봇의 동작 에러 파라미터이며, $\hat{v}$, $\hat{\omega}$로 다루겠습니다.
표 5.1 속도 정보를 이용하여 p($x_t$ $u_t$, $x_{t-1}$) 계산 알고리즘
- 여기서 $x_{t-1}$은 벡터 (x y $\theta$ $)^T이고 $x_t$는 ($x^'$ $y^'$ $\theta^'$ $)^T, 제어 $u_t$ = (v, $\omega$ $)^T$입니다. 함수 prob(a, b)는 분산이 b인 0평균 분포를 따르는 a의 확률을 계산하며 이를 표 5.2로 계산할 수 있습니다.
표 5.2 분산 b를 이용하여 0 평균 정규분포와 삼각 분포 함수 계산하는 알고리즘
함수 prob(x, b)는 모션 에러를 나타내는데, 분포가 b인 0 평균 확률변수로 x의 확률을 나타냅니다. 두 가지 구현 예시는 표 5.2에서 보여주며 에러 변수들은 각각 정규분포와 삼각 분포를 따르게 됩니다.
그림 5.3 노이즈 파라미터 설정이 다를때 속도 모션 모델
그림 5.3은 이 속도 모델의 예시로 x-y 공간 상에 사영되었는데, 이 모든 경우에 로봇은 같은 평행 각속도를 설정하였습니다. 그림 5.3a는 기존 에러 파라미터$\alpha_1$ ~ $\alpha_6$가 주어질때 결과 분포이며, 그림 5.3b의 분포는 각 속도 에러(파라미터 $\alpha_3$, $\alpha_4$)가 더 작고, 평행이동 에러가 더 큰 경우(파라미터 $\alpha_1$, $\alpha_2$) 경우나오는 분포가 됩니다. 그림 5.3c는 각 에러가 크고 평행이동 에러가 작은 경우의 분포가 됩니다.
이번과 다음 자에서는 필터 알고리즘 구현에 사용되는 두가지 요소들인 동작과 측정 모델을 살펴보겠습니다. 이번 장에서는 동작 모델 motion model을 중심으로 다루겠습니다. 여기에는 실제 로봇 공학 구현에 사용되는 확률적 동작 모델의 예시들도 있습니다. 이런 모델들은 상태 전이 확률 p($x_t$ | $u_t$, $x_{t-1}$)로 이루어 지며 이는 베이즈 필터의 예측 단계에서 필수적으로 사용되고 있습니다. 이후 장에서는 센처 측정의 확률적 모델 p($z_t$ | $x_t$)를 다룰것인데 이는 관측 갱신 단계에서 사용됩니다. 이 내용들은 모든 장에서 사용될겁니다.
이번 장의 핵심 주제인 로봇 기구학은 수십년간 연구되어온 분야로 하지만 대부분 결정론적 형태로 다루어져 왔습니다. 학률적 로봇 공학은 기구학 방정식을 제어시 노이즈와 모델링되지 못한 영향이 있으므로 제어의 결과가 불확실하다는 사실에 따라 일반화 시킵니다. 이 책은 확률적으로 다루어 왔으므로 제어의 결과는 사후 확률 분포로 나타낼 겁니다. 그렇게 하여 결과 모델은 이전 장에서 설명한 확률적 상태 추정 기술들에 사용될수 있습니다.
평면 공간에서 동작하는 이동로봇의 기구학에 대해 살펴보겠습니다. 이 방법은 동시대의 기구학보다 명확하며 매니퓰레이터 기구학 모델이 사용되지는 않을것입니다. 확률과 같은 최신 기술들은 이동 로봇에서 널리 사용되고 있으며 이러한 확률 모델(로봇 동역학의 확률 모델)은 여전히 알려지지 않은 점들도 많습니다.
이론적으로 확률 모델의 목표는 로봇의 구동과 인지시 발생하는 불확실 성들을 정확하게 모델링 하는 것이나, 현실적으로는 모델의 형태는 발생하는 불확실성보다 절 중요하게 다루어 집니다. 현실적인 응용분야에서 성공적으로 증명되어온 수많은 모델들이 불확실성을 과도 추정을 하게 되어 결과 알고리즘들은 마르코브 가정 위반에 더 강인해 집니다. 이에 대해서는 확률 적 로봇 공학 알고리즘의 실제 구현시에 더 다루어 보겠습니다.
5.2 서두 preliminaries
5.2.1 기구학 설정 kinematic configuration
기구학은 로봇의 형태에 따라 제어 동작시의 영향을 나타냅니다. 강체 이동로봇의 형태는 6자유도로 설명할 수 있는데, 이는 외부 좌표계에 대해 3차원 카티지안 좌표계와 3개의 오일러 각으로 이루어져 있습니다. 이 책에서 설명하는 내용들은 표면 환경에서 이동 로봇의 동작을 가정하며 여기서의 기구학적 상태로 자세 pose는 3가지의 변수로 이루어 집니다. 이는 그림 5.1에서 보여주는데, 로봇의 자세는 외부 좌표계에 대한 2차원 표면 좌표와 방위로 이루어집니다. 전자를 x, y라 하며, 후자를 $\theta$로 로봇의 자세는 다음의 벡터로 나타내게 됩니다.
그림 5.1 전역 좌표계 상 로봇의 자세
로봇의 방위를 베어링 bearing 이나 해딩각 heading direction이라 부르기도 하며 그림 5.1에서 보여주며 이 로봇이 x축 방향을 향할때 방위 $\theta$ = 0이라고 할 수 있습니다. 로봇의 방위 $\theta$ = 0.5$\pi$인 경우 y축 방향을 가리키게 됩니다.
방위를 제외한 자세를 위치 location이라 하며, 이는 다음 장에서 로봇이 주변 환경을 인지하기 위해 관측할때 중요하게 다루겠습니다. 단순하게보면 이책에서 위치는 다음의 2차원 벡터로 물체의 x-y좌표를 의미합니다.
5.2.2 확률적 기구학 probabilistic kinematics
확률적 기구학 모델(혹은 동작 모델)은 이동 로봇 공학에서 상태 전이 모델로 사용됩니다. 이 모델은 친근한 조건부 밀도로 아래와 같습니다.
여기서 $x_t$, $x_{t-1}$은 (x좌표계 값이 아니라) 로봇의 자세이며, $u_t$는 동작 입력이 되어, 이 모델은 로봇의 자세가 $x_{t-1}에서 $동작 명령 $u_t$가 수행 될때 기구학에 대한 사후확률 분포를 나타냅니다. 구현 중에 $u_t$는 종종 로봇의 오도메트리로 주어지기도 하는데 일단 개념적인 이유로 $u_t$를 제어 입력으로 부르겠습니다.
그림 5.2 동작 모델: 실선에 따라 동장 명령 수행 후 로봇 자세의 사후확률 분포.
- 검은색 공간은 로봇이 존재할 것같은 위치로 2D상에 사영됨. 실제 밀도는 3차원으로 로봇의 해딩 $\theta$도 포함됨.
그림 5.2는 평면 환경에서 강체 이동로봇의 기구학 모델의 2가지 예시를 보여주고 있습니다. 두가지 경우다 로봇의 초기 위치는 $x_{t-1}$이 됩니다 분포 p($x_t$ | $u_t$, $x_{t-1}$)은 회색 그림자친 공간으로 그려지는데 자세가 더 어두울수록 더 존재할 가능성이 큰곳이 됩니다. 이 그림에서는 로봇의 방위에 대한 1차원이 부족한데, 그림 5.2a에서 로봇은 직진 운동을 하면서 평행이동과 회전 오차가 누적된 것을 볼수 있습니다. 그림 5.2b는 더 복잡한 제어 입력의 결과 분포로 더 넓은 불확실성을 가지고 있습니다.
이번 장에서는 평면에서 이동하는 두가지 경우의 확률적 동작 모델에 대해서 상세히 살펴보겠씁니다. 두 모델 다 동작 정보 처리시에 약간의 이점을 가지고 있습니다. 첫번째 모델은 동작 데이터 $u_t$를 로봇 모터에 주는 속도 명령으로 대부분의 상업용 로봇은(차동 구동differential drive, 동기 구동 synchro drive)는 이러한 방식으로 구동됩니다. 두번째 모델은 오도메트리 정보가 주어지는걸로 많은 상업용 몸체는 기구학 정보를 사용하는 오도메트리를 제공하고 있습니다. 이 정보를 합침으로서 얻는 확률적 모델은 속도 모델의 것보다 약간 다릅니다.
현실적으로 오도메트리 모델이 속도 모델보다 정확한데 이 이유는 단순하게 대부분의 상업 로봇들이 로봇 바퀴 회전 속도를 측정해서 얻을수 있는 정확한 속도 명령을 사용하지 않기 때문입니다. 하지만 오도메트리는 탈-사실 post-the-fact에만 사용되므로, 동작 계획 motion planning에서 사용될수 없습니다. 충돌 회피와 같은 계획 알고리즘은 동작의 영향을 예측해야 하는데 오도메트리 모델은 추정시에 사용되고, 속도 모델은 확률적은 동작 계획시에 사용됩니다.
(b) f에서 바로 샘플링하는 대신 다른 밀도 함수 g로부터 샘플들을 생성시킵니다. 이 샘플들은 이 다이어그램의 바닥에 표시되고 있습니다.
(c) f의 샘플은 각각의 샘플 x에 대해 가중치 f(x)/g(x)로 구하며, 파티클 필터에서 f는 신뢰도 bel($x_t$)와 같고, g는 $\bar{bel}(x_t)$가 됩니다.
4.2.2 중요도 샘플링 Importance Sampling
파티클 필터를 구하기 위해서 리샘플링 단계를 자세히 살펴봅시다. 그림 4.2가 리샘플링 단계를 보여주고 있습니다. 그림 4.2a는 목표 분포 target distribution인 확률 분포 f의 밀도 함수를 보여주고 있습니다. 우리는 f의 샘플을 구하여야 합니다. 하지만 f로부터 바로 샘플링을 수행하는것은 불가능 하고, 이와 관련된 밀도 함수로부터 파티클들을 만들어 낼 수 있는데 이 밀도 함수는 그림 4.2b의 g가 됩니다. g를 따르는 는 확률 분포를 제안 분포 proposal distribution이라 부릅니다. f(x) > 0, g(x) > 0ㅇ므로 g로부터 생성한 파티클들은 0이 아닌 확률들이며, 결과적인 파티클 집합은 4.2b의 바닥과 같으며 g를 따르게 됩니다.
구간 interval A $\subseteq$ range(X)일 때, A에 부합하는 파티클의 수들은 A에서 g의 적분으로 모여들게 됩니다.
f와 g사이의 차이를 상쇄시키기 위해 파티클 $x^{[m]}$이 가중되어 집니다.
이는 그림 4.2c에서 보여주고 있는데 이 그림의 수직 바가 중요성 가중치의 크기를 보여주고 있습니다. 중요성 가중치는 각각의 파티클에 대해 정규화 되지 않은 확률 질량이됩니다. 아래의 첫번째 항이 모든 중요성 가중치에 대한 정규화자로 사용되는 식을 구할 수가 있습니다.
정리하자면 g로부터 파티클들을 생성시키더라도 f에 따라 파티클들의 가중치가 주어집니다.
이는 집합 A에 대한 적분을 포함하고 있으며, 여기 예제에서 f는 연속적이지만 파티클 집합은 이산 분포를 보여주고 있습니다. 이 때문에 파티클과 관련된 밀도는 존재하지 않게 됩니다. 집합은 그래서 f에 대한 누적 분포 함수가 됩니다.
파티클 필터에서 밀도 f는 목표 신뢰도 $bel(x_t)$가 되며, $\chi_{t-1}$에서 파티클은 bel($x_{t-1}$에 따라 분포한다고 할때 밀도 g는 아래의 곱 분포가 됩니다.
이 분포를 제안 분포 proposal distribution라 부릅니다.
4.2.4 파티클 필터 성질
생략
4.3 정리
이번 장에서는 두 비모수적 베이지안 필터인 히스토그램 필터와 파티클 필터를 살펴보았씁니다. 비 모수적 필터는 유한개의 값으로 사후 확률을 근사화를 하며 사후확률의 형테와 시스템 모델에 대해 약한 가정을 하며, 필터 두가지 사후확률을 나타내기 위해 사용되는 값의 수가 무한대가 될수록 근사 에러가 균일하게 0이 되는 성질을 가지고 있습니다.
- 히스토그램 필터는 상태 공간을 유한개의 공간으로 분해하며,각각의 영역을 단일 값으로 사누적 사후 확률 분포를 나타냅니다.
- 로봇 공학에서는 수많은 분해 기슬이 있는데 낱알 모양의 분해 granularity of a decomposition는 환경 구조에 따라 사용될수도 사용되지 않을수도 있습니다. 환경 구조에 따라 하는 경우 이러한 알고리즘을 위상학이라고 부릅니다.
- 분해 기술은 정적과 동적으로 나눌수 있는데 정적은 일찍이 만들어졌으며 신뢰도의 형태를 무시합니다. 동적 분해는 상태 공간을 분해할 때 로봇의 신뢰도에 따라 수행되며 사후 확률에 비례하여 해상도가 증가하게 됩니다. 동적 분해는 더 나은 결과를 보여주지만 구현하기에는 더 어렵습니다.
- 비모수적 방법의 대안으로 파티클 필터가 있는데, 파티클 필터는 사후 확률로부터 구한 상태에 대한 임의의 샘플들로 사후확률을 표현하게 됩니다. 이러한 샘플들을 파티클이라 부르며 파티클 필터는 구현하기 쉽고, 이 책에서 보여주는 모든 베이즈 필터 중 가장 유용합니다.
- 파티클 필터에서 에러를 줄이기 위한 방법으로 가장 많이 사용되는 것은 알고리즘에 의해 발생하는 근사치의 분포를 줄이는 것으로 이는 사후확률의 복잡도에 따라 파티클수를 적용시키도록 수행합니다.
이번과 이전에 살펴본 필터 알고리즘은 대부분의 확률적 로봇 공학 알고리즘의 기반 기술로 여기서 살펴본 기술은 오늘날 사용되는 상당히 많은 알고리즘들에서 볼 수 있습니다.
파티클 필터는 배이즈 필터의 비모수적 구현으로 히스토 그램처럼 유한 개의 파라미터로 사후 확률을 근사화 시키지만 상태 공간 상에서 파라미터를 생성시키는 방법이 다릅니다. 파티클 필터의 키 아이디어는 사후 확률 bel($x_t$)를 이 사후 확률로부터 생성한 임의의 상태 샘플 집합으로 나타내는것입니다.
그림 4.3 파티클 필터를 이용한 파티클 표현
- 우측 아래 그림은 가우시안 확률 변수 X로 샘플을 생성한 그래프로 이 샘플들은 우측 위 비선형 함수에 적용되어 결과 샘플들은 확률 변수 Y에 대해 분포됨.
그림 4.3은 가우시안을 이용한 이 개념에 대해 설명하고 있습니다. 모수적 형태의 분포를 사용하는 대신 파티클 필터는 이 분포로부터 샘플 집합을 생성하여 이 분포를 표현합니다. 이러한 표현법은 근사화 된것이나 비모수적이고, 가우시안보다 넓은 분포 공간에서 나타낼 수 있습니다.
파티클 필터에서 사후확률 분포의 샘플들을 파티클 particles이라 부르며 다음과 같이 적습니다.
각각의 파티클 $x_{t}^{[m]}$ (1 <= m <= M)은 시간 t에 대한 상태의 인스턴스로 실제 상태에 대한 가정이 됩니다. 여기서 M은 파티클 집합 $\chi_t$에서 파티클의 개수로 보통 M = 1000이 됩니다.
파티클 필터는 파티클 집합 $\chi_t$의 집합으로 신뢰도 bel($x_t$)를 근사화 시키며, 파티클 집합 $\chi_t$에 존재하는 상태 가정 $x_t$의 우도는 베이즈 필터의 사후 확률 bel($x_t$)에 비례하게 됩니다.
(4.23)에 따라 상태 공간의 하부 영역이 샘플들로 밀집될수록 이 공간이 실제 상태에 가깝게 되어집니다. 유한한 M에 따라서 파티클들은 조금씩 다르게 분포될수 있지만, 파티클의 수가 너무 적지 않으면(M >= 100)은 이 차이는 무시해도 됩니다.
표 4.3 파티클 필터 알고리즘. 가중치 샘플링에 기반한 베이즈 필터의 변형
이전에 살펴본 다른 베이즈 필터와 달리 파티클 필터 알고리즘은 신뢰도 bel($x_t$)를 이전 신뢰도 bel($x_{t-1}$)로부터 재귀적으로 만들며, 신뢰도들은 파티클의 집합으로 나타내기 때문에 이는 파티클 필터가 이전 집합 $\chi_{t-1}$로부터 재귀적으로 파티클 집합 $\chi_t$를 만든다고 할 수 있습니다. 파티클 필터의 기본 알고리즘은 표 4.3과 같습니다.
이 알고리즘의 입력은 파트클 집합 $\chi_t-1$와 입력 $u_t$, 관측 $z_t$을 사용합니다. 처음에는 $\bar{bel}(X_t)$에 대응하는 임시 파티클 집합 $\bar{\chi}$를 생성합니다. 이는 입력 파티클 집합 $\chi_{t-1}$에서 각각의 파티클 $x_{t-1}^{[m]}$을 아래의 과정처럼 처리하여 수행됩니다.
1. 4번째 줄에서는 파티클 $x_{t-1}^{[m]}$과 제어 $u_t$로 시간 t에 대한 상태 가정 $x_{t}^{[m]}$을 생성합니다. 결과 샘플은 m으로 인덱싱하는데, $\chi_{t-1}$의 m번째 파티클에서 만들어 졌음을 나타냅니다. 이 단계에서 상태 전이 확률 p($x_t$ | $u_t$, $x_{t-1}$)으로 샘플링을 포함하므로 이 단계를 구현하기 위해 p($x_t$ | $u_t$, $x_{t-1}$)에서의 샘플링이 되어야 합니다. 상태 전이 확률로 부터 샘플링 시에는 p($x_t$ | $u_t$, $x_{t-1}$)만 사용되는 것은 아니며 이 책에서의 많은 분포들이 샘플 생성을 위해 효율적인 알고리즘들을 가지고 있습니다. 이 과정들이 M번 반복이 되어만든 파티클 집합이 이 필터의 $\bar{bel}(x_t)$가 됩니다.
2. 5번째 줄에서는 각각의 파티클 $x_{t}^{[m]}$의 가중치 요소 $w_{t}^{[m]}$ importance factor을 계산합니다. 가중치 요소는 측정 $z_t$를 파티클 집합에 적용시킬때 사용되는데, 이는 파티클 $x_{t}^{[m]}$에 대한 측정 $z_t$의 확률로 $w_{t}$ = p($z_t$ | $x_{t}^{[m]}$)이 됩니다. $w_{t}$를 파티클의 가중치로 본다면 가중치가 적용된 파티클들의 집합은 베이즈 필터 사후확률 bel($x_t$)라고 볼수 있습니다.
3. 파티클 필터 알고리즘의 실제 트릭은 8~11번째 줄에서 수행됩니다. 이 세 줄은 리샘플링 or 가중치 리샘플링을 구현한 것으로 임시 파티클 집합 $\bar{\chi_t}$로부터 M개의 파티클을 대체시키게 됩니다. 중요도 가중치에의해 각 파티클들의 확률이 주어지면, 리샘플링 과정에서 기존의 M개 파티클 집합을 동일한 크기의 다른 파티클 집합으로 변환시킵니다. 이 중요도 가중치를 리샘플링 과정에 적용함으로서 파티클의 분포가 변하게 되는데, 리샘플링 전에 파티클 집합은 $\bar{bel}$($x_t$)를 따랐다면 리샘플링을 수행한 이후에는 사후 확률 bel($x_t$) = $\eta$ p($z_t$ | $x_{t}^{[m]}$) $\bar{bel}$($x_t$)를 따르게 됩니다. 파티클들이 대체 되었기 때문에 결과 파티클 집합은 많은 복제된 파티클들을 가지게 됩니다. 더 중요한 점은 $\chi_t$에 포함되지 않은 파티클들은 적은 중요도 가중치를 가지는 경향이 있습니다.
리샘플링 단계는 파티클들을 사후 확률 bel($x_t$)를 만드는 중요한 함수이며, 각각의 파티클의 중요도 가중치는 1로 초기화되어 곱이 수행됩니다.
파티클 필터 알고리즘은 사후확률을 근사화 시키나 수많은 파티클들이 사후확률이 낮은 영역에 머무르게 됩니다. 그 결과 더 많은 파티클들이 필요하게 되는데 이는 사후확률의 형태에 따라 정해집니다. 리샘플링 단계는 적자생존 survival of the fittest 의 확률적인 구현으로 높은 사후 확률 역역에 존재하는 파티클 집합을 중심으로 만듭니다. 이렇게 함으로서 상태 공간 상에 문제를 다루는 영역에 한하여 필터 알고리즘의 자원 사용을 적용하게 됩니다.
로그 오즈의 값은 -inf에서 inf 사이가 되어, 로그 오드 표현법을 이용해 베이즈 필터 신뢰도 갱신시 확률이 0이나 1에 가까워지는 문제를 피하게 해줍니다.
표 4.2 역 관측 모델을 로그 오즈로 표현한 이진 베이즈 필터
- $l_t$는 시불변 이진 상태 변수에 대한 사후확률 신뢰도의 로그오즈
표 4.2는 기본적인 갱신 알고리즘으로, 베이즈 필터를 로그 호즈 형태로 만듦으로서 측정 값에대해 변수를 증가시키거나 감소시키는 형태가 됩니다. 이 이진 베이즈 필터는 기존에 보았던 모델 p($z_t$ | x) 대신, 역 측정 모델 inverse measurement model p(x | $z_t$)을 사용하며 이 역측정 모델은 측정 $z_t$이 함수가 주어질때 이진 상태 변수에 대한 분포를 의미합니다. 역 모델은 측정치가 이진 상태보다 복잡한 상황에서 종종 사용됩니다. 예를들자면 카메라 영상을 이용하여 문이 열렸는지 닫혔는지 추정하는 문제인데, 여기서 상태는 단순하지만 측정치의 공간은 매우 큽니다. 이는 닫힌 문이 주어질때 카메라 영상에 대한 확률 분포를 구하는것보다, 카메라 영상이 주어질때 문이 닫힌 확률을 계산하는 함수로 고치는것이 더 쉽습니다. 쉽게 얘기하자면 전방향 센서 모델 보다 역방향 모델을 구현하는것이 더 쉽습니다.
가우시안 기술을 대신하는 것으로 비모수적 필터가 있습니다. 비 모스적 필터는 가우시안 같은 고정된 형태의 사후확률에 의존하지 않고 대신 상태 공간 영역에서 각각에 대해 유한개의 수의 사후확률들을 근사화 시킵니다. 일부 비모수적 베이즈 필터는 상태 공간의 하부 영역에 대한 사후 밀도의 누적 함수로 상태 공간을 분해하여 활용하기도 합니다. 다른 것들은 사후 확률 분포로부터 임의의 샘플을 이용하여 상태 공간을 근사화 시킵니다. 이러한 경우에는 사후 확률을 근사화 시키기 위해 사용하는 파라미터의 갯수가 달라질 수 있습니다. 근사의 퀄리티는 이러한 사후확률을 나타내기 위해 사용하는 파라미터의 수에 따라 정해지며 파라미터의 수가 무한대에 갈수록 비모수적 기술은 정확한 사후 확률로 응집하게 됩니다.
이번 장에서는 연속 공간에서 사후확률을 근사화 하는 두가지 비모수적 접근방법을 살펴보겠습니다. 첫번째는 상태 공간을 유한개의 영역으로 분해하고, 히스토그램으로 사후확률을 나타내는 방법으로 히스토그램은 각 영역에 대해 누적 단일 누적 확률 분포를 놓습니다. 이들은 연속 영역에 있어서 근사화에 있어서 최고의 방법으로 여겨지고 있습니다. 두번째 방법으로 유한한 많은 샘플들로 사후확률을 구하는 방법인데, 이를 파티클 필터라 하며 특정 로봇 공학 문제에 있어서 유용하게 사용되고 있습니다.
히스토그램과 파티클 필터 둘다 사후 확률 밀도에 대한 강한 파라미터 가정을 만들지는 않고, 대신 그들은 멀티모달 신뢰도를 나타내는데 적합합니다. 이러한 이유로 전역적인 불확실성을 다룰 때나 서로 나누어 구분하기 힘든 데이터를 다룰때 사용됩니다. 하지만, 이러한 기술 가장 큰 장점은 계산량인데, 이번 장에서 설명하는 비모수적인 방법들은 사후확률의 복잡도에 따라 파라미터의 수를 조절할 수 있습니다. 사후 확률이 복잡하지 않을때(불확실성이 낮은 단일 상태를 구하는 경우), 적은 수의 파라미터만 사용하면 되고, 사후확률이 복잡한 경우(상태 공간 상에서 다양한 사후확률들을 구할 때)에는 파라미터의 수를 늘리면 됩니다.
이러한 사후확률에 맞게 파라미터의 수를 조절하는 기술을 적응적 adaptive라 부르며, 이들은 신뢰도 계산에 있어서 컴퓨터 자원에 기반할 수 있다면, 자원 적응적 resoure-adaptive이라고 부를수 있습니다. 자원 적응적 기술은 로봇공학에서 중요한 역활을 하는데, 이는 컴퓨터 계산량이 가능함에 따라 실시간으로 로봇이 결정을 할수 있도록 만들어줍니다. 파티클 필터는 사용가능한 계산 자원에 따라 실시간으로 파티클 수를 조절하도록 종종 자원 적응적 알고리즘으로 구현되기도 합니다.
4.1 히스토그램 필터
표 4.1 이산 베이즈 필터
히스토그램 필터는 상태 공간을 유한개의 공간을 분해하고 각각의 여역을 단일 확률값에 대한 누적 사후확률로 나타냅니다. 이를 이산 영역에 적용하면 이산 베이즈 필터라 하고, 연속 상태 공간에 적용하면 히스토그램 필터라고 부릅니다. 우선 이산 베이즈 필터를 설명할것이고 이후 연송 상태 공간에서의 사용을 다루어보겠습니다.
4.1.1 이상 베이즈 필터 알고리즘 The Discrete Bayes Filter Algorithm
이산 베이즈 필터 알고리즘은 확률 변수 $X_t$가 유한 값을 가질수 있는 유한 상태 공간 문제에 사용됩니다. 이미 이산 베이즈 필터를 2.4.2장에서 문이 열렸는지 닫혔는지 확률을 추정하는 예제에서 살펴보았습니다. 이후에 살펴볼 일부 로봇 공학 지도 작성 문제들도 이런 이산 확률 변수를 다룹니다. 예를들면 점유 격자 지도 작성 알고리즘에서는 각각의 공간들이 점유되었는지 비어있는지를 정하게 됩니다. 이러한 확률 변수는 이진값이 되어 2가지의 값만 가질수 있습니다. 그래서 유한 상태 공간은 로봇 공학에 있어서 중요한 역활을 하게 됩니다.
표 4.1은 이상 베이즈 필터의 슈도 코드가 됩니다. 이 코드는 표 2.1의 기본 베이즈 필터에서 적분을 유한 합으로 바꾸어서 구할수 있으며 변수 $x_i$와 $x_k$는 유한개의 상태가 됩니다. 시간 t에 대한 신뢰도는 상태 $x_k$에 대한 확률로 $p_{p,t}$로 표기하며, 이 알고리즘에 대한 입력은 이산 확률 분포 $p_k,t$와 최근 제어 입력 $u_t$, 측정치 $z_t$가 됩니다. 3번째 줄은 예측 과정으로 제어 입력으로 새 사애에 대한 신뢰도를 계산합니다. 이 예측은 4번째 줄에서 측정 값을 합치면서 갱신 됩니다. 이산 베이즈 필터 알고리즘은 다양한 신호처리(음성 인식 같은)분야에서 사용되며 히든 마르코므 모델이라고 불립니다.
4.1.2 연속 상태 contiunuos state
이 첵에서 연속 상태 공간 상에서 근사 추론도구로 이산 베이즈 필터를 사용하겠습니다. 이러한 필터를 히스토그램 필터라 하며, 히스토그램 필터는 연속 상태 공간을 유한개의 영역으로 분해합니다.
여기서 $X_t$는 로봇의 상태를 나타내는 확률 변수로 함수 range($X_t$)는 상태 공간입니다. 각각의 $X_{k, t}$는 볼록한 공간 convex region이 됩니다. 이 영역들은 상태 공간들의 일부분이 되어 이들은 i != k일때 $x_{i,t}$ $\cap$ $x_{k,t}$ = $\o$이고 $U_k$ $x_{k,t}$ = range($X_t$)가 됩니다. 연속 상태 공간을 분해하여 이차원 그리드가되어 각각의 $x_{k,t}$는 그리드 셀이 됩니다. 입자 분해 granularity of the decomposition을 통해 정확도와 계산 효율 사이 조절을 할 수 있습니다. 분해를 많이 할 경우 추정 에러가 그러지 않을 경우보다 작겠지만 계산 복잡도 비용은 증가하게 됩니다.
이미 이산 베이즈 필터로 각각의 영역 $x_{k,t}$와 확률 $p_{k,t}$에 대해 살펴보았고, 이 영역들에서 이산 베이즈 필터는 신뢰도 분포에서 아무런 정보를 주지 않습니다. 그래서 사후 확률은 각각의 영역 $x_{k,t}$와 상태 $x_t$에 대해 균일 분포를 따르는 상수 확률 밀도 함수가 됩니다.
여기서 |$x_{k, t}$|는 $x_{k, t}$의 크기를 말합니다.
상태 공간이 완전히 이산적이라면 조건부 확률 p($x_{k, t}$ | $u_{t}$, $x_{i, t-1}$) 와 p($z_t$ | $x_{k, t}$)가 정의되어 알고리즘을 구현할 수 있습니다. 연속 상태 공간에서 확률 밀도 p($x_t$ | $u_t$ , $x_{t-1}$)와 p($z_t$ | $x_t$)가 주어질때 이는 상태 공간에서 일부 영역이 아니라 각각의 상태를 정의하는게 됩니다.
각각의 영역 $x_{k, t}$이 작거나 같은 크기인 경우에 이러한 밀도들은 $x_{k, t}$를 해당 영역을 나타내는 값으로 대체하여 근사화 시킬수 있습니다. 예를 들어 $x_{k, t}$의평균상태를구한다면
아래와 같이 바꿀 수 있습니다.
이 추정은 (4.2)에서 살펴본 이산 베이즈 필터의 균일 분포 구현한 결과가 됩니다.
식 (4.4)는 합리적인 근사화로 p($z_t$ | $x_{k, t}$)는 다음의 적분으로 표현할 수 있습니다.
이 표현식은 식 (4.2)에서 균일 분포 모델에 따른 확률을 정확히 구할 수 있습니다. 만약 p($z_t$ |$x_{k, t}$)를 p($z_t$ |$\hat{x_{k, t}}$)$으로 근사화 시킨다면, 식 (4.4)의 근사화 구문으로 아래의 식을 얻을 수 있습니다.
식 (4.5)에서 p($x_{k, t}$ |$u_{t}$,$x_{i, t-1}$)의 근사 시에도 비슷한데, 조건부 확률 양 쪽을 각각의 영역에 대해 다루기 때문입니다. 위에서 살펴본 변환처럼 아래의 식을 얻을 수 있습니다.
이전에 $x_{t-1}$과 $u_t$ 사이에 독립이라 하는 마르코브 가정을 사용하면 p($x_{t-1}$ | $u_t$) = p($x_{t-1}$)으로 식 (4.8)은 아래와 같이 정리됩니다.
4.1.3 분해 기술들 Decomposition Techniques
로봇 공학에서 상태 공간을 분해하기 위한 방법들로는 크게 정적과 동적으로 2가지 종류로 나눌 수 있습니다. 정적 기술들은 지정한 고정 크기로 분해하여 근사화된 사후확률의 형태를 무시하게 됩니다. 동적 기술은 사후 확률 분포의 형태에 따라서 분해를 합니다. 정적 기술들이 먼저 구현이 되었으나 이들은 자원 사원량에 낭비를 초래할수 있습니다.
(a) 2차원 확률 밀도의 그리드 기반 표현법. 이 확률 밀도는 상태 공간 상에서 우측 위와 좌측 아래에 집중되어 있습니다. (b)는 같은 확률 분포의 밀도 트리
동적 분해 기술의 대표적인 예로 밀도 트리 density tree 군이 있습니다. 밀도 트리는 상태 공간을 재귀적으로 분해하여 사후 질량 확률의 해상도에 적응시킵니다. 이 분해의 중요한 점은 분해의 세부적인 레벨이 사후 확률 함수이 되어, 영역이 적은 경우 분해도 적게 될겁니다. 그림 4.1은 2차원 확률 밀도 상에서 정적 그래드 표현법과 밀도 트리 표현법을 보여주고 있습니다. 두 표현법은 같은 근사치를 가지고 있지만, 밀도 트리가 그리드 표현법보다 소형이 됩니다. 밀도 트리 같은 동적 기술들은 정적의 것보다 계산 량을 줄일 수 있으나 구현하는데 더 많은 노력이 필요합니다.
이러한 동적 분해와 비슷한 효과를 선택적 갱신 selective updating을 통해서도 수행할 수 있습니다. 그리드에서 표현한 사후확률을 갱신할때 선택적 기술은 일부 그리드만 갱신시킵니다. 이 방법의 구현물은 사용자가 지정한 임계치를 초과한 사후 확률의 그리드 셀만 갱신하도록 하여 선택적 갱신은 상태 공간을 세밀한 그리드로 분해하고 전체 영역중에서 일부 부분만 선택하는 점에서 하이브리드 분해라고 볼수 있습니다. 또, 이 방법은 실시간으로 사후 확률의 형태에 따라 갱신할 그리드 셀을 선택한다는 점에서 동적 분해 기술로도 볼수 있습니다. 선택적 갱신 기술은 갱신할 신뢰도를 고르는대 관여함으로서 계산 량을 줄일수 있고, 3, 4차원 공간에서도 그리드 분해를 사용할수 있도록 도와줍니다.
이동 로봇 책에서는 종종 공간에 대해 미터 표현법과 위상학을 구분해서 다루기도 합니다. 여기 용어에는 명확한 정의가 없지만 토폴로지 표현법에서는 그래프 표현법도 사용되는데, 그래프의 노드들은 주위 환경에서 지점(특징)들에 대응합니다. 실내 환경에서 교차점이나 T점, 등등 같은 공간이 그러한 특징들이 됩니다. 이런 곳에서 분해 해상도는 주위 환경에 의해 정해지며, 다른 방법으로 그리드를 사용해 상태 공간을 분해할수도 있습니다. 이 경우 분해 시에는 주위 환경 특징의 위치나 형태에 의존하지 않게 됩니다.
그리드 표현법은 종종 미터법으로 여겨지는데, 이 공간이 분해가 아니라 미터 공간으로 보기도 하기 때문입니다. 이동 로봇공학에서 그리드 표현법의 공간 해상도는 토폴로지 표현법보다 큰 편이며, 7장에서 몇가지 예시에서는 10cm이하의 셀사이즈를 가지는 그리드 표현법을 사용할 것입니다. 이는 정확도를 올리긴 하나 계산 비용을 증가시키게 됩니다.
가우시안 노이즈가 추가된 선형 상태 전이와 선형 측정이란 가정은 현실에서는 매우 드뭅니다. 예를 들면 로봇이 상수 값으로 평행, 회전 속도로 원형 운동을 할 경우 이는 선형 상태 전이로 나타낼 수 없습니다. 이러한 유니모달 신뢰도를 이용하는 것은 실제 대부분의 로봇 공학 문제에 적용하기가 어렵습니다.
확장 칼만 필터 EKF는 이러한 선형성 문제들을 극복하였습니다. 여기에는 상태/측정 확률에 비선형 함수 g와 h이 적용이 된다고 하여
이 모델은 식 (3.2), (3.5)에서 정리한 선형 가우시안 모델을 일반화 한것으로 함수 g가 행렬 식 (3.2)에서 $A_t$, $B_t$를 대체하며, 식 (3.5)에서의 행렬 $C_t$를 h로 대체하였습니다. 하지만 함수 g, h로 구한 신뢰도는 더이상 가우시안이 되지 않으므로 비선형 함수 g, h에 대해 신뢰도 갱신 수행이 불가능 하게 됩니다.
확장 칼만 필터는 실제 신뢰도를 추정을 통해 계산하며, 이 추정치를 가우시안으로 나타냅니다. 그래서 신뢰도 bel($x_t$)는 평균 $\mu_t$와 공분산 $\Sigma_t$로 나타냅니다. 확장 칼만 필터는 칼만 필터의 기본적인 신뢰도 표기법을 상속받아 사용하나 이 신뢰도는 칼만필터에서 구했던것과는 달리 추정치가 됩니다.
3.3.1 테일러 전개를 이용한 선형화 Linearization Via Taylor Expansion
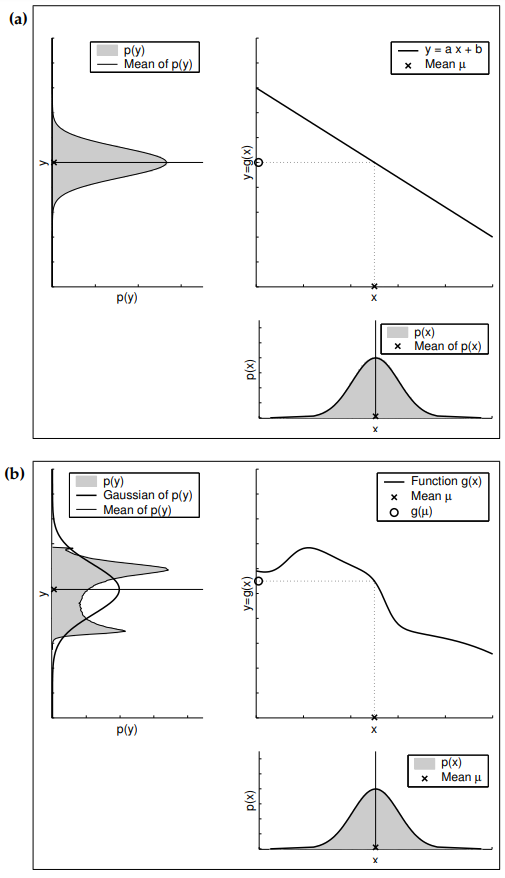
그림 3.3 가우시안 확률 변수의 (a) 선형, (b) 비선형 변환
아래의 우측은 기존의 확률변수 X의 밀도 함수를 보여줍니다. 이는 확률 변수는 우측 위 그래프 함수가 적용되며(평균에서의 변환을 점선이 가르키고 있습니다.) 확률 변수 Y에 대한 결과 분포는 좌측 위 그래프에서 나타나고 있습니다.
확장 칼만필터의 핵심 아이디어는 선형화가 됩니다. 그림 3.3은 기본 컨샙을 보여주는데, 비선형 상태 함수 g가 주어졌다고 할때, 가우시안을 이함수에 사영한 결과는 비가우시안이 됩니다. 이는 비선형 함수 g가 가우시안의 형태를 바꾸도록 신뢰도를 왜곡시키기 때문인데, 선형화는 가우시안의 평균치에 g의 기울기에 대한 선형 함수로 g를 근사화 시킵니다.
이 선형 근사화에 가우시안을 사형시킴으로서 사후 확률은 가우시안이 됩니다. g가 선형화 되어지고 나서 신회도 계산과정은 기존의 칼만 필터와 동일하게 수행됩니다. 이는 측정 함수 h의 가우시안 곱 연선에서도 동일하게 적용되어 즉, EKF는 h에 대한 기울기를 나타내는 선형 함수로 h를 선형화하여 가우시안 형태의 사후 확률 신뢰도를 구합니다.
이러한 비선형 함수를 선형화하는데에는 다양한 기술들이 존재하지만, EKF에서는 1차 태일러 전개라는 방법을 사용합니다. 테일러 전개는 비선형 함수 g의 값과 기울기로 함수 g를 선형 추정 하는것으로 이 기울기에 대한 편미분은 다음과 같습니다
g의 값과 기울기는 g의 매개변수에 의해 결ㄷ정되어지며, 선형화 시간에 따라 영향을 받습니다. 가우시안인 경우 상태는 사후확률 $\mu_{t-1}$의 평균이 되며, g는 $\mu_{t-1}$에서의 값으로 근사화되며, 이 선형 추정은 $\mu_{t-1}$, $u_t$가 주어질 때 g의 기울기에 비례하게 됩니다.
상태 전이 확률을 가우시안으로 근사화 시키면 다음과 같습니다.
여기서 $G_t$는 크기가 n x n인 행렬로 여기서 n은 상태의 차원을 발하며 이 행렬을 자코비안이라 합니다. 자코비안의 값은 $u_t$와 $\mu_{t-1}$에 의존하는데 이는 시간에 따라 달라지게 됩니다.
EKF는 측정 함수 h에 대해서도 동일한 선형화를 수행하며 여기서 테일러 전개는 $\bar_{\mu_t}$에 대해서 수행됩니다.
가우시안으로 이를 정리하면 다음과 같이 구할수 있습니다.
3.3.2 EKF 알고리즘
표 3.3은 EKF 알고리즘을 보여주고 있습니다. 이는 여러 부분에서 표 3.1의 칼만 필터와 비슷한 점이 많으나 가장 큰 차이점은 합이 수행되는 과정입니다.
표 3.3 확장 칼만 필터 알고리즘
칼만 필터에서의 선형 예측 과정이 EKF의 비선형 함수로 바뀌었으며, EKF는 칼만 필터에서 선형 시스템 행렬 $A_t$, $B_t$, $C_t$ 대신 자코비안 $G_t$, $H_t$를 사용하고 있습니다. 자코비안 $G_t$는 행렬 $A_t$, $B_t$를 대신하며, 자코비안 $H_t$는 $C_t$를 대신하고 있습니다. 이에 대한 확장 칼만 필터 예시는 이후 챕터에서 살펴보겠습니다.
3.4 정보 필터
생략
3.5 정리
이번 장에서는 다변수 가우시안을 이용하여 사후확률을 나타내는 효율적인 베이즈 필터 알고리즘들을 살펴보았습니다. 여기서 다음과 같은 내용들을 살펴볼수 있었는데
- 가우시안은 2가지 방법으로 표시할 수 있었습니다. 모멘트 표현법과 표준 표현법으로 모멘트 표현법은 가우시안의 평균(1차 모멘트)와 공분산(2차 모멘트)으로 이루어집니다. 표준 표현법은 정보 행렬과 정보 벡터로 나타냅니다. 두 표현법다 동일하며 매트릭스 변환을 통해 되돌릴 수 있습니다.
- 베이즈 필터는 두 표현법으로 구현할 수 있으며, 모멘트 표현법을 사용한 경우 필터를 칼만 필터라 부르며, 표준 표현법으로 사후확률을 나타낸 것을 정보 필터라 합니다. 칼만 필터에서 제어 갱신은 간단하나 측정치 통합 과정은 어렵습니다. 반대로 정보 필터의 경우 측정치 통합은 간단하나 제어 갱신은 어렵습니다.
- 두 필터 다 올바른 사후확률을 구하며 3가지 가정이 성립되어야 합니다. 첫번째로 초기 신뢰도는 가우시안이여야 하며, 두번째는 상태 전이 확률이 가우시안 노이즈를 가지는 선형 함수여야 합니다. 세번째는 똑같은 점이 측정 확률에도 적용되어야 합니다. 이러한 세가지 가정이 적용된 시스템을 선형 가우시안 시스템이라 할 수 있습니다.
- 두 필터 다 비선형 문제를 다룰수 있도록 확장할수 있는데 이 챕터에서 비선형 함수에서의 기울기를 계산하는 과정을 살펴보았습니다. 탄젠트 기울기는 선형이되어 이 필터를 적용할수있도록 도와줍니다. 이 기울기를 찾는 기술을 태일러 전개라 하며 태일러 전개를 통해 기울기 함수의 일차 미분을 계산하여 특정 지점에 대해서 구하는 과정을 다룹니다. 이 동작의 결과로 자코비안 행렬을 구하며, 이 필터를 확장되었다고 할 수 있습니다.
- 테일러 급수 전개의 정확도는 두가지 요소에 의존합니다. 시스템의 비선형성 정도와 사후확률의 폭으로, 확장된 필터는 시스템의 상태에 대해서 잘 알고있다면 좋은 결과를 얻어 결과 공분산은 작게 됩니다. 불확실 성이 클수록 선형화 시 오차가 커지게 됩니다.
- 가우시안 필터의 주요 이점으로 계산상에서 장점을 가지고 있습니다. 갱신 과정은 상태 공간 차원에 대해 다항식 시간이 필요하나 이는 다음장에서 설명할 기술들의 경우와는 다릅니다. 가우시안의 단점은 유니모달 가우시안 분포를 이용해야만 하는것이 됩니다.
이번장에서 설명한 내용들은 로봇공학에서 가장 많이 사용하는 내용들을 기반으로 정리하였습니다. 여기서 소개한 가우시안 필터를 기반으로 수많은 바리에이션들이 있지만 여기서 가장 큰 문제점은 사후확률이 단일 가우시안으로 표현되는것이고, 이는 사후 확률이 유니모달인 경우에만 이러한 필터를 사용할수 있게 됩니다. 이는 불확실성이 제한된 로봇이 상태를 추적해 나가는 트래킹 어플리케이션에 적합할 수 있으나, 불확실성이 전역으로 증가하는 경우 단일 모드로는 불충분하여 가우시안이 실제 사후확률을 추정하는데 문제가 될수있습니다. 이러한 제한점은 잘 알려져있으므로 가우시안을 조합한 멀티모달 신뢰도를 이용하는 방법을 사용하거나 다음 챕터에서 설명할 비가우시안 방법들이 주로 사용되고 있습니다.
칼만 필터 알고리즘은 표 3.1과 같으며, 여기서 신뢰도 bel($x_t$)는 시간 t에 대해 평균 $\mu_t$, 공분산 $\Sigma_t$를 가집니다. 칼만 필터의 입력으로 시간 t-1일때의 신뢰도로 이 때 평균 $\mu_{t-1}$, $\Sigma_{t-1}$로 표현합니다. 이 값들을 갱신하기 위해 칼만 필터는 제어 입력 $u_t$와 측정 $z_t$가 필요하며, 그 결과가 시간 t에 대한 신뢰도가 됩니다.
2,3번째 줄에서 예측 신뢰도 $\bar{\mu}$, $\bar{\Sigma}$가 신뢰도 $\bar{bel} (x_t)$를 나타내고, $z_t$를 합치기 전의 값이 됩니다. 이 신뢰도는 제어 입력 $u_t$,를 합하여 구할수 있습니다. 이 평군치는 상태 전이 함수 (3.2)의 결정론적 형태를 이용하여 $x_{t-1}$ 대신 $\mu_{t-1}$로 대입하여 구할 수 있습니다. 공분산의 갱신을 하기 위해서는 선형 행렬 $A_t$를 통해 이전의 상태에서 구하며, 이 행렬은 공분산에 이차 형태로 곱해지게 되어, 공분산은 이차 행렬이 됩니다.
신뢰도 $\bar{bel}(x_t)$는 4 ~ 6줄의 과정을 통해 측정 $z_t$를 합쳐 신뢰도 $bel(x_t)$로 변형 됩니다. 여기서 4번 줄의 변수 $K_t$는 칼만 게인이라 부르며, 측정치를 새로운 상태 추정에 얼마나 반영할지 지정하는 이득으로 사용됩니다. 5번째줄에서 실제 측정치 $z_t$와 식 (3.5)의 측정 확률을 이용해 예측 측정치의 차이는 칼만 게인 $k_t$에 비례하여 평균값을 구하게 됩니다. 마지막으로 사후확률 신뢰도의 공분산은 6번재 줄과 같이 계산되는데 측정 치로부터 정보 게인을 조절을 하게 됩니다.
3.2.3 과정
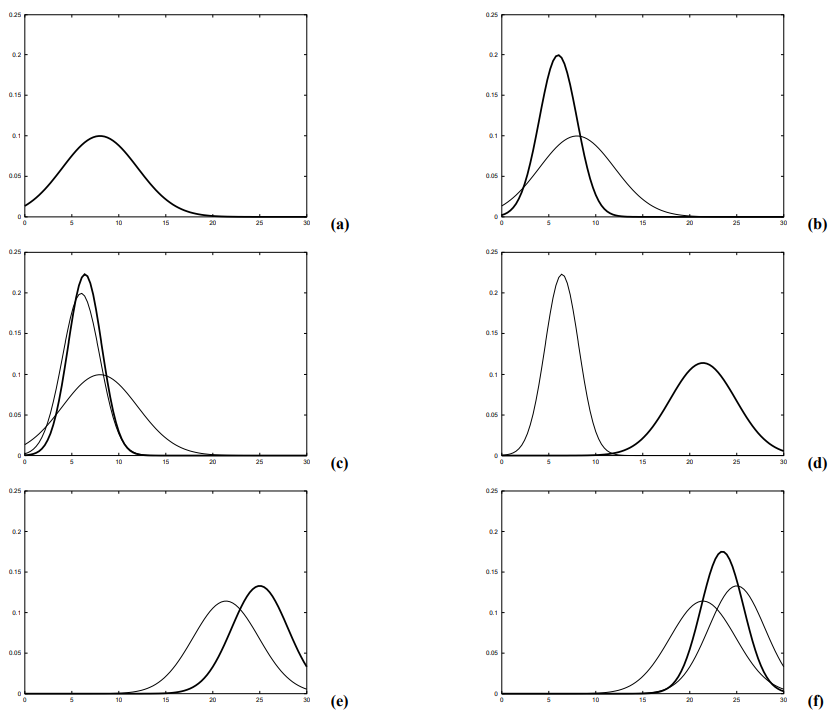
그림 3.2 칼만 필터 처리 과정
(a) 초기 신뢰도
(b) 측정치(굵은 가우시안)
(c) 칼만 필터 알고리즘을 이용해 측정치를 합쳐 구한 신뢰도
(d) 우측으로 이동후의 신뢰도(불확실성이 증가함)
(e) 새로운 측정
(f) 칼만 필터 수행후 구한 신뢰도
그림 3.2는 간단한 1차원 위치 추정 문제에서 칼만 필터 알고리즘의 수행과정을 보여줍니다. 그림 3.2의 각각의 다이어그램은 수평 축을 따라 로봇이 이동한다고 가정을 하고 있으며, 그림 3.2a에서 로봇의 위치 사전확률이 정규 분포로 주어지고 있습니다. 로봇은 gps와 같은 센서를 이용해 현재 위치를 확인하고 있으며, 그림 3.2b에서 굵은 가우시안의 꼭대기 중심이 측정치를 의미하고 있습니다. 이는 센서로 예측한 값으로 폭은 측정에서 불확실성에 대한 공분산을 의미합니다. 사전확률과 측정치를 합하여 표 3.1의 4~6줄 과정으로 그림 3.2c의 굵은 가우시안을 구하게 됩니다. 이는 기존의 두개의 평균 사이에 신뢰도의 평균이 존재하게 되며 그 값이 불확실성은 사용된 가우시안 분포 보다 작아지게 됩니다. 이는 칼만 필터의 정보 통합에 의한 기본적인 특성입니다.
다음으로 로봇이 우측으로 이동한다고 가정해봅시다. 그러면 불확실성은 증가하게 되고 칼만필터 알고리즘 2~3줄에 따라 그림 3.2d와 같은 가우시안 분포가 나ㅏ나게 됩니다. 이 가우시안은 로봇이 이동한 만큼 움직이게 되며 여러가지 이유로 폭이 커지게 됩니다. 그림 3.2f에서 굵은 가우시안으로 두번째 측정치를 구하고, 그림 3.2f에서 구한 사후확률을 굵은 가우시안으로 보여주고 있습니다.
이 예제는 칼만 필터에서 기존 신뢰도에 센서 데이터를 합치는 측정 갱신 과정(5 ~7 줄)과 동작 후 신뢰도의 변화를 보여주는 예측 과정을 보여주고 있습니다. 갱신 과정에서는 로봇 신뢰도 불확실성이 줄어드나 예측 과정에서는 불확실성이 커지는 모습을 볼 수 있습니다.
이번에는 중요한 재귀 상태 추적기 군인 가우시안 필터 gaussian filter을 설명하겠습니다. 역사적으로, 가우시안 필터는 일찍부터 연속 공간에서 베이즈 필터의 구현체로 여겨져 왔습니다. 이들은 수많은 결점들도 가지고 있지만 가장 많이 상용되고 있습니다.
가우시안 기술들은 기본적으로 모두 다변수 정규 분포를 이용하여 신뢰도를 표현하고 있습니다. 다변수 정규 분포는 (2.4)에서 보았고 다시 적으면 아래와 같습니다.
변수 x에 대한 밀도는 두가지 파라미터로 나타낼수 있는데 평균 $\mu$와 공분산 $\sigma$가 됩니다. 평균 $\mu$는 상태 x와 같은 차원인 벡터이며 공분산은 대칭이며 positive semidefinte인 이차 행렬이 됩니다. 공분산의 차원은 상태 x를 제곱한것과 같으며 공분산 행렬의 원소 개수는 상태 벡터의 원소에 이차적으로 됩니다.
가우시안을 이용한 사후확률 표현은 중요한 영향을 끼쳤는데, 가장 중요한 것으로 가우시안은 단봉 형태이므로 단일 최대치를 가지고 있습니다. 그러한 사후확률은 로봇 공학에서 많은 추적 문제의 특성으로 사후확률은 적은 불확실성을 가진체 진짜 상태에 가깝게 됩니다. 가우시안 사후확률은 많은 구분가능한 가정들이 존재하는 전역 추정 문제에 있어서 낮은 성능을 보이는데 여기서 여러개의 사후확률들이 존재하기 때문입니다.
가우시안의 평균과 공분산을 이용한 표현법을 모멘트 표현법 moments representation이라 하는데 이는 평균과 공분산이 확률 분포의 1, 2차 모멘트 이기 때문입니다. 정규 분포에서 다른 모든 모멘트들은 0이 됩니다. 이번 장에서 다른 표현 방법인 표준 표현법 canonical representation에 대해서 살펴보겠습니다. 모멘트 표현법과 표준 표현법 둘다 전단사 하는점에서 같으나, 직교적인 계산 특성들을 가지는 필터 알고리즘들로 유도합니다.
이번 장에서 2가지 기본적인 가우시안 필터 알고리즘을 다루겠습니다.
- 3.2장에서 칼만 필터를 설명하겠습니다. 이는 선형 동역학, 측정 함수 문제에서 모멘트 표현법으로 베이즈 필터를 구현한 것입니다.
- 칼만 필터는 3.3장에서 비선형 문제를 다룰수 있도록 확장하는데 이를 확장 칼만 필터 extended kalman filter라 합니다.
- 3.4장에서는 정보 필터 information filter에 대해 설명하겠습니다. 이는 칼만 필터를 가우시안 표준 표현법으로 표현한 것입니다.
3.2 칼만 필터
3.2.1 선형 가우시안 시스템
베이지안 필터 구현한 최고의 기술은 아마 칼만 필터(KF : Kalman Filter)일 것입니다. 칼만 필터는 1950년대에 루돌프 에밀 칼만이 만들었으며 선형 시스템의 필터링과 예측을 수행합니다. 칼만 필터는 연속 상태에서 신뢰도를 계산을 하며, 이산 이나 하이브리드 상태 공간에 적용할수는 없습니다.
칼만 필터는 모멘트 표현법으로 신뢰도를 나타내는데 시간 t일때, 신뢰도는 평균 $\mu_t$, 공분신은 $\Sigma_t$가 되며, 사후확률은 마르코브 가정을 따르는 베이즈 필터에 다음의 3가지 성질을 가지고 있습니다.
1. 다음 상태 확률 p($x_t$ | $u_t$, $x_{t-1]$)은 반드시 가우시안 노이즈가 추가된 선형 함수여야 하며 다음의 식으로 나타낼 수 있습니다.
여기서 $x_t$와 $x_{t-1}$은 상태 벡터, $u_t$는 제어 벡터이며 이 표기법에서 이러한 벡터는 수직 벡터로 아래의 형태로 이루어 집니다.
$A_t$, $B_t$는 행렬로 $A_t$는 크기가 n x n인 2차 행렬로 n은 상태 백터 $x_t$의 차원이 됩니다. $B_t$는 n x m인 크기로 m은 제어 벡터 $u_t$의 차원이 됩니다. 상태와 제어 벡터를 각각 $A_t$와 $B_t$에 곱하여 상태 전이 함수는 이 매개 변수에 대해 선형이 됩니다. 그래서 칼만 필터는 선형 시스템 동역학을 가정합니다.
식 (3.2)의 변수 $\varepsilon_t$는 가우시안 랜덤 백터로 상태 전이에서 노이즈가 됩니다. 이는 상태 벡터와 동일한 차원이며, 평균은 0 공분신을 $R_t$로 표기합니다. 식 (3.2)의 상태 전이 확률의 형태를 선형 가우시안이라 하며 가우시안 노이즈가 추가된 매개변수에 대해 선형이 됩니다.
식 (3.2)는 상태 전이 확률 p($x_t$ | $u_t$, $x_{t-1}$)을 정의하며 이 확률은 식 (3.2)를 다변수 정규분포 식 (3.1)의 정의에 대힙하여 구할 수 있습니다. 사후확률 상태의 평균은 $A_t x_{t-1}$ + $B_t u_t$이고, 공분산은 $R_t$가 됩니다.
2. 측정 확률 p($z_t$ | $x_t$)는 가우시안 노이즈가 추가된 선형이여야 합니다.
여기서 $C_t$는 크기가 k x n인 행렬로 k는 측정 벡터 $z_t$의 차원이 됩니다. 벡터 $\delta_t$는 측정 노이즈로 $\delta_t$의 확률 분포는 평균이 0이고 공분산이 $Q_t$인 다변수 가우시안이 됩니다. 측정 확률은 그래서 다음의 다변수 정규 분포를 따르게 됩니다.
3. 마지막으로 초기 신뢰도 bel($x_0$)은 정규 분포여야 합니다. 그래서 이 신뢰도의 평균과 공분산을 $\mu_0$, $\Sigma_0$로 표기하겠습니다.