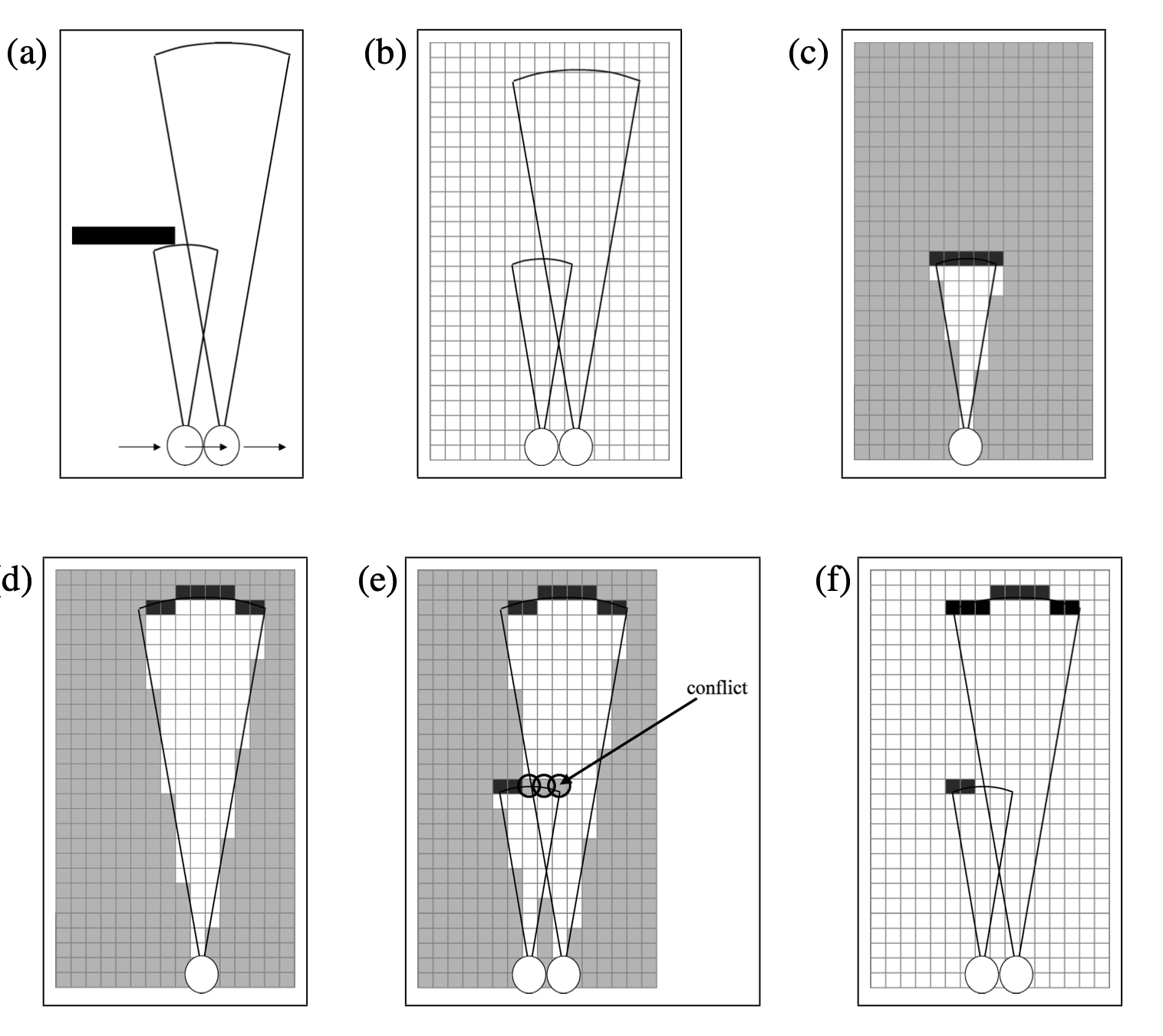
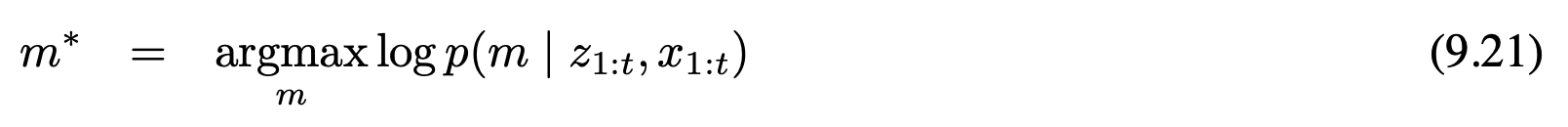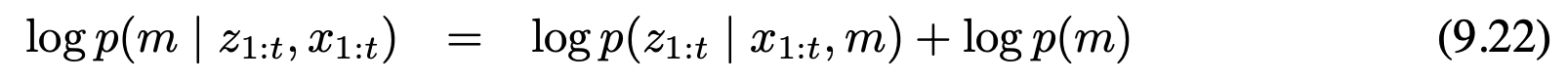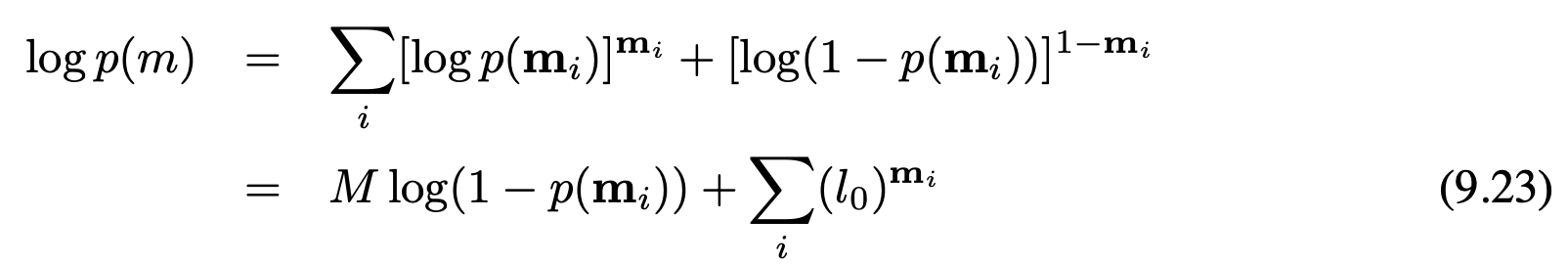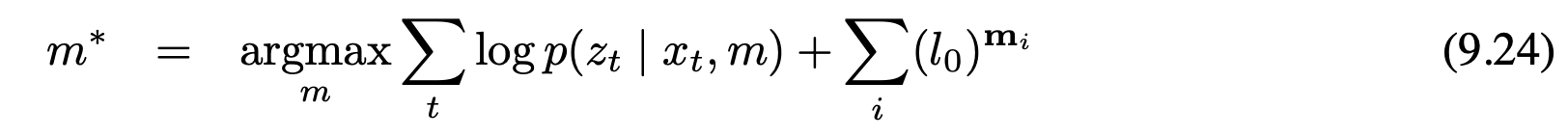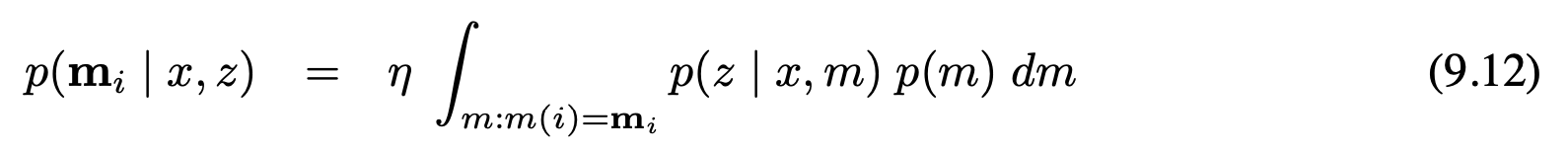10.3.3 특징 선택과 지도 관리 feature selection and map management
EKF SLAM을 현실에서 더 강인하게 만들려면 지도를 관리하기위한 추가적인 기술들이 필요합니다. 이러한 기술들 대부분은 가우시안 노이즈 가정은 비현실적이며, 많은 이상한 관측치들이 노이즈 분포의 끝에 발생한다는 사실을 고려하는데, 이러한 이상한 관측치는 지도 생성시 잘못된 랜드마크를 발생할수 있으며 위치 추정에 부정적인 영향을 주게됩니다.
최신 기술들은 관측 공간에서 아웃라이어들을 대처하는 방법들을 다루며, 지도상에서 랜드마크의 불확실성 범위를 넘어가는 것들을 아웃라이어로 정의합니다. 이런 아웃라이어를 다루는 가장 흔한 방법은 임시 랜드마크 목록 provisional landmark list를 유지하는것인데, 새로운 랜드마크에 관측될때 지도에 추가하는것보다 그런 새 랜드마크를 우선 임시 랜드마크 목록에 추가시키는 것입니다. 이 목록은 지도처럼 다루나 목록에 존재하는 랜드마크들은 로봇의 자세에 적용시키지는 않습니다. 이 랜드마크가 일관되게 관측이 되고 불확실성 타원이 줄어들게 되면 이 랜드매크는 정규 지도에 이동하게 됩니다.
현실에서 구현하기위해서 이 방법은 중요한 요소로서 지도에 존재하는 랜드마크의 개수를 중요하는 경향이 있는데 반면에 지도에 존재하는 랜드마크들은 매우 높은 확률을 가지게 됩니다. 더 나아가 최신 구현 방법들에서는 랜드마크 존재의 사후확률 우도를 보유하는데, 이러한 확률은 지도 상의 j번째 랜드마크의 로그 오즈비 $o_j로 표기하여 구현합니다. j번째 랜드마크 $m_j$가 관측될때마다 고정 값은 증가하게 되고 로봇의 인지 거리 안에서 $m_j$가 관측되지 않으면 $o_j$는 감소하게 됩니다. 랜드크가 로봇의 인지 거리에 있는것으로 존재여부를 확실히 알수 없기 때문에, 그러한 사건에 대한 확률을 감소시킵니다. $o_j$가 임계치 보다 떨어지면 지도에서 랜드마크는 삭제 됩니다. 이러한 기술들은 비 가우시안 관측 노이즈에서 더 효과적이게 됩니다.
이전에도 살펴봤지만 데이터 연관에서 최대 우도 방법은 명확한 한계를 가지고 있습니다. 이 한계는 최대 우도 방법이 확률적 로봇 공학에서 완전 사후확률 근사의 아이디어에서 얻었기 때문에 발생하는것인데, 혼합 상태와 데이터 연관들 사이 결합 사후확률을 사용하는 대신, 데이터 연관 문제를 결정론적인 결정으로 줄여 최대 우도 연관이 항상 올바른것인것 처럼 다루어지게 됩니다. 이러한 한계로 EKF는 잘못된 결과를 구하는 랜드마크 실패에 취약하며, 연구자들은 이 문제를 완화하기 위해서 다음 두 방법중 하나를 사용하기도 합니다.
- 희소 배치 spatial arrange
랜드마크들이 서로 더 떨어질수록 이들을 잘못 결정할 경우는 줄어들게 됩니다. 그래서 충분히 멀리 떨어진 랜드마크를 선택하는것이 유용합니다. 이는 흥미로운 트레이드 오프를 보여주는데 랜드마크의 수가 증가할수록 햇갈리는 위험도 증가하게 됩니다. 랜드마크가 너무 적은 경우에는 로봇의 위치 추정을 어렵게 하여 이 역시도 랜드마크를 잘못 구할 확률이 커지게 됩니다. 랜드마크의 최적 밀도에 대해 아직 알려진것은 없어 연구자들은 직관적으로 특정 랜드마크를 선택해서 사용하기도 합니다.
- 시그니처 signature
적절한 랜드마크 선택시에 랜드마크의 구별성을 최대화 하는것이 필수적입니다. 예를들자면 다른 색을 가진 문들이 있거나, 복도가 다른 폭을 가지고 있는 경우 이러한 시그니처는 성공적인 SLAM에선 필수적입니다.
추가적으로 보면 EKF SLAM 알고리즘은 하늘을 날거나 깊은 바다속, 버려진 광산 등을 다니는 로봇들을 포함하는 현실의 많은 범위에서 성공적으로 사용되고 있습니다.
EKF SLAM의 한계는 적적한 랜드마크 선택이 필수적인것이며, 이렇게 하여 대부분의 센서 정보들은 버려지게 됩니다. 더 나아가 EKF의 2차적인 갱신시간은 1,000개 특징 이하인 경우의 희소한 지도에서만 사용할수있도록 제한됩니다. 현실적으로 특징이 $10^6$개나 그 이상인 경우에는 EKF를 사용할수 없게 됩니다.
상대적으로 저차원의 지도에서는 데이터 연관을 만들기가 어렵습니다. 이는 쉽게 확인할수 있는데, 눈을 뜨고 방안을 한번보세요 거기 아무것도 없다면 어디있는지 알기 어려울겁니다. 랜드마크가 적은 경우에도 어디있다고 판단하기 또한 어려울것입니다. EKF SLAM에서 데이터 연관은 차후에 다룰 SLAM 알고리즘보다 어렵다고 할수 있습니다. 이는 EKF SLAM 알고리즘의 원칙적인 딜레마로 빠지게 만듭니다. 최대 우도 데이터 연관이 수백만개의 특징으로 이루어진 밀집된 지도에서 잘 동작하더라도 희소한 지도에서는 불안정하게 됩니다. 하지만 EKF는 이차적인 복접도로 인해 희소 지도를 요구하고 있습니다. 차후에는 더 큰 지도를 효율적으로 다루는 SLAM 알고리즘에 대해 살펴보겠습니다. 여기서 강인한 데이터 연관 기술들을 더 다뤄볼것이고, EKF SLAM 알고리즘의 한계들을 더 역사적으로 보겠습니다.
10.4 정리
이번장에서는 일반적인 SLAM 알고리즘의 문제와 EKF 방법에 대해 소개하였습니다.
- SLAM 문제는 동시적 위치 추정 및 지도 작성 문제로 정의되며 로봇은 주위 환경에 대한 지도를 얻고 이 지도에 대한 상대적인 자신의 위치를 추정치를 찾게 됩니다.
- SLAM 문제는 두가지 버전으로 다룰수 있는데 온라인과 전역이 있습니다. 두 문제다 지도 근사를 다루는데, 온라인 슬램에서는 순간적인 로봇의 자세를 추정한다면, 전역 문제에서는 모든 자세들을 찾게 됩니다. 두 방법다 현실적으로 중요합니다.
- EKF SLAM 알고리즘은 앞선 SLAM 알고리즘으로 확장 칼만 필터를 온라인 슬램 문제에 적용한것이 됩니다. 대응 관계가 주어진 경우 알고리즘의 결과는 증가하게 되는데, 지도상에 존재하는 랜드마크의 수에 따라서 갱신시 이차적인 시간을 요구하고 있습니다.
- 대응관계를 모르는경우 EKF SLAM알고리즘은 증가 최대 우도 근사기로 대응관계 문제를 다루었습니다. 이 알고리즘의 결과는 랜드마크가 충분히 떨어져 있을때 잘 동작하였습니다.
- 지도 관리르 위해 추가적으로 살펴본 기술들이 있는데, 아웃라이어를 식별하기 위한 두가지 흔한 방법으로 아직 충분히 자주 관측되지 않은 랜드마크들을 담는 임시 랜드마크 리스트와 랟느마크의 존재에 대한 사후확률을 계산하는 랜드마크 존재 카운트가 있습니다.
- EKF SLAM은 수많은 로봇공학 지도 작성 문제에서 사용되어 왔지만, 이 알고리즘으 ㅣ결점은 충분한 수의 구분되는 랜드마크가 필요하며 갱신시 복잡한 계산 복잡도가 필요한 점입니다.
현실에서 EKF SLAM은 일부의 경우 성공적으로 사용되어 왔습니다. 랜드마크가 충분히 구분되면 이 방법은 사후확률을 잘 근사시켰습니다. 완전 사후확률 계산의 이점은 많은데, 이 알고리즘은 존재하는 모든 불확실성을다루고 로봇이 이 불확실성을 제어시에 고려할수 있도록 도와줍니다.
하지만 EKF SLAM 알고리즘은 수많은 갱신 복잡도와 희소 지도에 의한 한계의 문제를 가지고 있으며, 이는 데이터 연관 문제를 어렵게 만들며, 수많은 랜드마크가 애매한 환경에서 좋지 않은 성능을 보이게 됩니다. 이는 EKF SLAM 알고리즘이 증가 최대 우도 데이터 연관 기술에 의존하기 때문에 이러한 취약성이 존재하게 됩니다. 이 기술은 데이터 연관을 개선시킬수 없게 만들어 ML 데이터 연관이 잘못된 경우 위치 추정이 실패하게 됩니다.
EKF SLAM 알고리즘은 온라인 슬램에 적용한 것으로 완전 슬램 문제라고 볼수는 없습니다. 완전 슬램문제는 새로운 자세가 매 시간마다 상태 백터에 추가되어 상태 백터와 공분산이 한계없이 증가하게 만들어 버립니다. 이 공분산을 갱신하는것은 그래서 수없이 증가하는 시간을 필요로 하며, 프로세서가 얼마나 빠르던지간에 많은 계산시간을 필요로 하게 됩니다.
'번역 > 구)확률적로봇공학' 카테고리의 다른 글
| 확률적 로봇공학 - 11. 확장 정보 형태 알고리즘 (0) | 2020.06.27 |
|---|---|
| 확률적 로봇공학 - 3.4 정보 필터 (0) | 2020.06.27 |
| 확률적 로봇공학 - 10.3 대응관계를 모르는 경우 EKF SLAM (0) | 2020.06.27 |
| 확률적 로봇공학 - 10.2 확장 칼만 필터를 이용한 SLAM (0) | 2020.06.27 |
| 확률적 로봇공학 - 10. 동시적 위치 추정 및 지도 작성 SLAM (0) | 2020.06.27 |