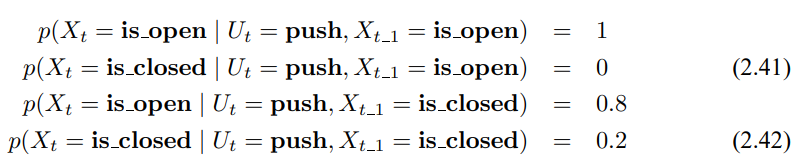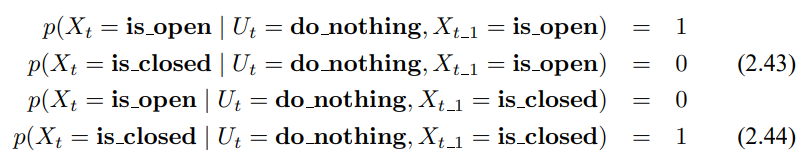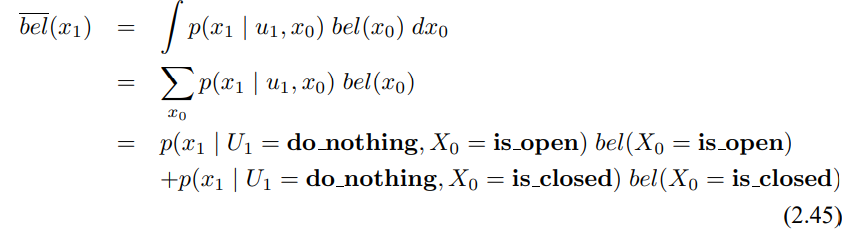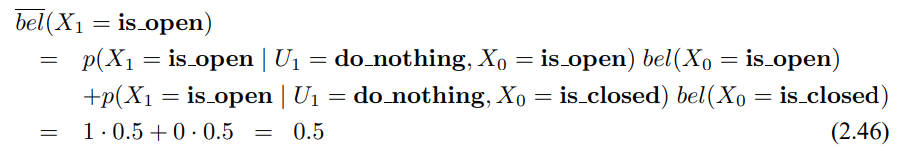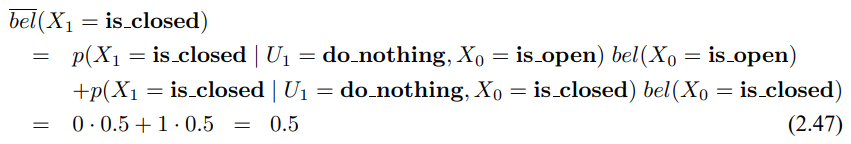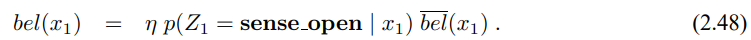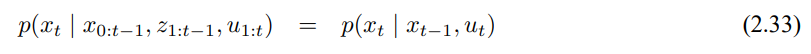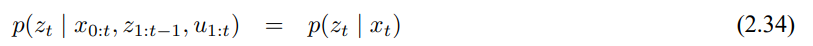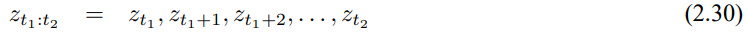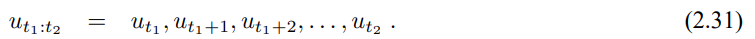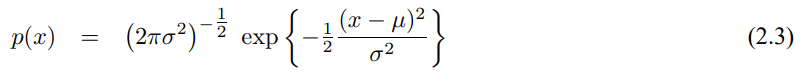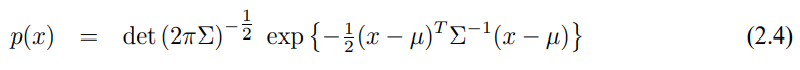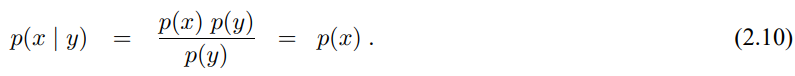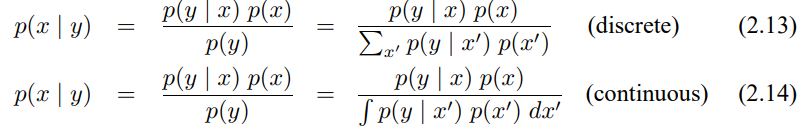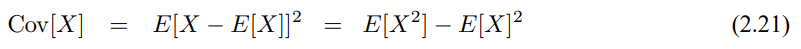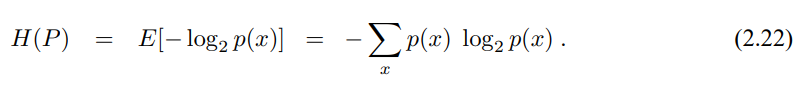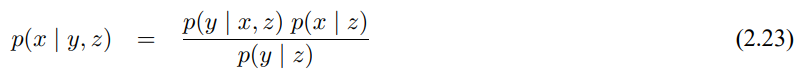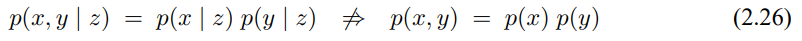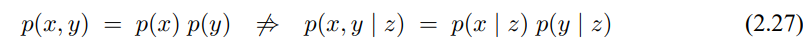마르코브 가정은 우리가 현재 상태 $x_t$를 알고있다면 과거와 미래의 정보는 독립으로 생각하는것입니다. 이 가정이 얼마나 중요한지 보기위해서 이동 로봇의 위치 추정문제를 다루어 봅시다. 여기서 $x_t$는 로봇의 자세이고 베이즈 필터가 고정된 맵에 대해 자세를 추정하는데 사용될것입니다. 다음의 요인들이 센서 읽기에 영향을 줄것입니다. 이들은 마르코브 가정의 위배하게 됩니다.
- $x_t$에 포함되지 못한 모델링 되지않은 동역학들(ex. 움직이는 사람들과 센서 측정에서의 영향)
수많은 변수들은 상태 표현법에 포함시킬수는 있지만 베이즈 필터 알고리즘의 계산 복잡도를 줄이기 위해 불완전한 상태 표현법이 완전한 것보다 더 선호됩니다. 실제로도 베이즈 필터는 그렇나 위반에도 강인성을 보이며, 모델링 하지 않은 상태 변수들의 영향을 고려하여 상태 $x_t$를 신중하게 정의하여야 합니다.
신뢰도 계산에서 사용되는 가장 일반적인 알고리즘으로 베이즈 필터가사용됩니다. 이 알고리즘은 신뢰도 분포 bel을 측정과 제어 데이터로 계산하게 되는데 우선 이 기본 알고리즘을 보고 수치적인 예시로 자세히 다뤄보겠습니다. 그러고 난 후 수학적으로 다루어 보겠습니다.
표 2.1 베이즈 필터 기본 알고리즘
표 2.1은 기본 베이즈 필터의 슈도 알고리즘 형태로 베이즈 필터는 재귀적이므로 bel($x_t$)는 이전의 bel($x_{t-1}$)로부터 계산할 수 있습니다. 이 알고리즘의 입력은 시간 t-1에서의 신뢰도 bel과 최근의 제어 입력 $u_t$와 측정 $z_t$가 됩니다. 그리고 이 알고리즘의 출력은 시간 t에 대한 신뢰도 bel($x_t$)이 됩니다. 표 2.1은 베이즈 필터의 기본 단계인 갱신 법칙을 보여주고 있습니다. 이 갱신 법칙은 제귀적으로 수행되어 이전에 구한 bel($x_{t-1}$)로 bel($x_t$)를 구하는데 사용됩니다.
베이즈 필터 알고리즘은 2가지 필수적인 단계로 이루어지는데, 3번째 줄에서는 제어 $u_t$가 사용되어 사전확률로 상태 $x_{t-1}$과 제어 $u_t$를 이용하여 상태 $x_t$에 대한 신뢰도를 구하게 됩니다. 특히 신뢰도 $\bar{bel}$($x_t$)는 두 분포의 곱을 적분하여 상태 $x_t$를 구하는데, 이 때 $x_{t-1}$에 대한 사전확률과 제어 $u_t$가 $x_{t-1}$에서 $x_t$로 상태를 전이 시킬때의 확률를 사용합니다. 이는 식 (2.12)에서 본 갱신 과정과 비슷할 수 있는데 이 갱신 단계를 제어 갱신 control update나 예측 prediction이라 합니다.
베이즈 필터의 다음 단계로 측정 갱신 measurement update라 합니다. 베이즈 필터 알고리즘의 4번째 줄은 신뢰도 $\bar{bel}$($x_t$)를 측정 $z_t$에 대한 확률을 곱하게 됩니다. 이는 각 상태 사후확률 가정에 대해 적용이 됩니다. 곱의 결과는 일반적인 확률이 아니게되어 적분을 수행하지 않습니다. 그래서 이 결과는 정규화가 수행되어야 하는대 정규화 상수 $\eta$로 정규화를 수행합니다. 이 결과가 6번째 줄의 신뢰도 bel($x_t$)가 됩니다.
사후확률 신뢰도를 재귀적으로 계싼하기 위해서 이 알고리즘은 맨 처음의 신뢰도 bel($x_0$)이 필요한데, $x_0$에 대해 알고있다면 특정 지점 $x_0$을 중심으로 하는 분포로 초기화 하고 나머지에는 0으로 할당될겁니다. 하지만 초기값 $x_0$를 모른다면, bel($x_0$)은 균일 분포로 초기화가 되어야 합니다. 초기 값 $x_0$에 대해 일부분만 알고 있다면 비 균일 분포를 사용할 수 있지만 초기 값을 완전히 알거나 완전히 모르는 두 경우가 일반이게 됩니다.
2.4.2 예시
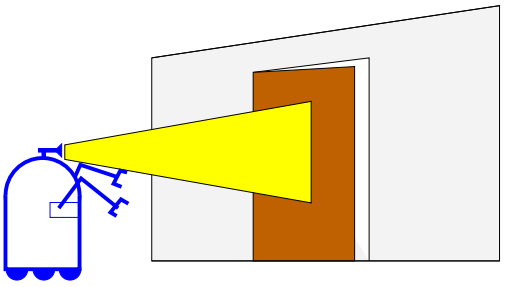
그림 2.2 문의 상태를 추정하는 이동 로봇
그림 2.2의 시나리오를 따라 베이즈 필터 알고리즘을 적용해보면, 여기서 로봇은 카메라를 이용해 문의 상태를 추정하고 있습니다. 이 문제를 쉽게 다루기 위해서 문에 대해서 2가지 상태(열림과 닫힘)만 존재한다고 가정하고, 로봇이 문의 상태를 바꿀수 있다고 합시다. 추가적으로 로봇은 처음에 문의 상태를 모른다고도 합시다. 대신, 두가지 문의 상태에 대해 다음과같이 똑같은 사전 확률을 주어봅시다.
로봇의 센서는 노이즈를 가지고 있으므로 노이즈는 다음과 같은 조건부 확률로 나타내어 보겠습니다.
이 확률들을 보면 로봇의 센서는 닫힌 문을 감지하는 경우 에러 확률이 0.2가 될만큼 더 신뢰할수 있음을 볼 수 있습니다. 하지만 문이 열린 경우 잘못 측정할 가능성이 0.4만큼이나 됩니다.
마지막으로 로봇이 매니퓰레이터로 문을 밀어 연다고 생각해봅시다. 문이 이미 열려있다면, 열린 채 일것이고 닫힌 경우에는 0.8의 확률로 열리게 될것입니다.
물론 매니퓰레이터를 사용하지 않는 경우도 존재하며 이 때 상태는 바뀌지 않을겁니다. 이를 조건부 확률로 다음과 같이 정리 할수있습니다.
시간 t에 대해서 로봇이 아무런 제어 동작을 하지 않았지만 문이 열려있다고 인식했다고 합시다. 결과 사후확률 신뢰도는 사전 확률 신뢰도 bel($X_0$)과 제어 $u_1$ = do_nothing, 측정 sense_open을 입력으로 하는 베이즈 필터로 구할 수 있습니다. 상태 공간은 유한하므로 3번째 줄의 적분을 유한 개의 합으로 나타내면 다음과 같습니다.
여기서 상태 변수 $X_1$에 대한 두가지 값을 정리할수 있는데, $X_1$ = is_open이라면 다음과 같이 정리 할 수 있습니다.
이처럼 $X_1$인 경우에도 아래와 같이 구할 수 있습니다.
우리가 구한 신뢰도 $\bar{bel}$($x_1$)은 사전 신뢰도 $x_0$와 같은데, 동작이 do_nothing이므로 상태에 영향을 주지 않으니 같더라도 놀랄 일은 아닙니다.
하지만 측정을 합치면 신뢰도가 변하게 됩니다. 베이즈 필터 알고리즘의 4번째 줄을 따라
우리가 구한 두가지 경우인 $X_1$ = is_open과 $X_1$ = is_closed 구하면 다음의 결과를 얻을 수 있습니다.
정규자 $\eta$는 다음과 같이 계산할수 있으니
베이즈 필터를 이용해 구한 결과는 다음과 같습니다
다음 시간에 대해서 쉽게 개산할 수 있는데 이번에는 $u_2$ = push 이고, $z_2$ = sense_open 이라면 아래와 같이 계산할 수 있습니다.
상태와 측정값은 확률 법칙이 적용됩니다. 그래서 보통 시간에 대한 상태 $x_t$는 확률적으로 만들어지게되고 확률 분포로 나타내게 됩니다. 우선 상태 $x_t$는 과거의 모든 상태와 측정, 제어에 조건부이므로 다음 혀앹의 확률 분포로 상태를 나타낼 수 있습니다.
그러나 상태 x가 완전하다면 이전 시간이 발생한 모든 것들의 결과라고 볼수 있습니다. $x_{t-1}$은 이전 모든 제어 $u_{1:t-1}$와 측정 $z_{1:t-1}$의 결과가 됩니다. 위를 이용해서 상태 $x_{t-1}$를 알고 제어 $u_t$만 중요하다고 하면 확률적인 용어로 이를 다음의 식으로 나타낼 수 있습니다.
이러한 식은 조건부 독립의 예시를 보여주는데, 조건부 독립은 전반적으로 계속 다룰것이며 확률론적 로봇공학 알고리즘을 추적하는데 주요하게 사용됩니다.
비슷하게 측정이 수행되는 과정을 모델할때 $x_t$가 완전한 경우, 조건부 독립으로 다음과 같이 중요한 식을 구할 수 있습니다.
이는 상태 $x_t$로 측정 $z_t$를 예측하는데 충분한 것으로, 상태 $x_t$가 완전하다면 이전의 측정이나 제어, 상태 값들에 대해 알 필요가 없습니다.
두 조건부 확률 p($x_t$ | $x_{t-1}$, $u_t$)와 p($z_t$ | $x_t$)를 다루어 봅시다. 우선 확률 p($x_t$ | $x_{t-1}$, $u_t$)는 상태 전이 확률로 state transition probability 로봇 제어 $u_t$의 함수로 어떻게 상태를 진행시킬지를 알려줍니다. 로봇 환경은 확률론적이므로 p($x_t$ | $x_{t-1}$, $u_t$)는 결정론적인 함수가 아니라 확률분포가 됩니다. 때떄로 상태 전이 확률 분포는 시간 t에 의존하지 않을수 있습니다.
확률 p($z_t$ | $x_t$)는 측정 확률 measurement probability로 시간 t에 대해 의존하지 않을때는 p(z|x)로 쓸 수 있습니다. 측정 확률은 주위 환경 상태 x로부터 측정된 z에 대해 알려주며, 측정은 노이즈가 존재하는 상태의 사영이 됩니다.
상태 전이 확률과 측정 확률은 함께 사용하여 로봇과 주위 환경의 동적 확률시스템을 나타냅니다.
2.3.4 신뢰도 분포 Belief Distribution
확률론적 로봇공학에서 다른 주요 컨샙으로 신뢰도 belief가 있습니다. 이 신뢰도는 환경 상태 중에서 로봇에 관한 정보들을 알려주는데 이미 상태는 직접적으로 측정할수 없다고 했었습ㄴ디ㅏ. 예를 들어 로봇의 위치가 x = <14.12, 12.7, 0755>에 존재하더라도, 로봇은 GPS없이는 스스로의 위치를 직접 측정할수 없으므로 알 수가 없습니다. 대신 로봇은 데이터로부터 자세를 추론해야내만 하는데, 진짜 상태와 상태에 대한 지식을 신뢰도로 구분해서 다루겠습니다.
확률론적 로봇공학은 신뢰도를 조건부 확률 분포로 나타냅니다. 신뢰도 분포는 가정이 주어질때 진짜 상태에 대한 확률로 주어진 데이터에 대한 상태 변수들의 조건부 사후 확률입니다. 상태 변수 $x_t$에 대한 신뢰도를 bel($x_t$라 하며, 사후확률로 아래와 같이 표기 할 수 있습니다.
이 사후확률은 모든 이전의 측정 $z_{1:t}$과 제어 $u_{1:t}$가 주어질때 시간 t에 대한 상태 $x_t$의 확률 분포가 됩니다.
이 내용을 보다보면 신뢰도는 측정 $z_t$를 합한 구에야 구할수 있다고 볼수 있지만, 제어 $u_t$를 수행한 후 $z_t$를 합치기 전에 사후확률을 계산하여 유용하게 사용할 수 있습니다. 이 사후확률은 다음과 같이 표기합니다.
이 확률 분포는 확률 필터링 과정에서 예측 과정이라고도 부르며 이 용어는 $\bar{bel}$($x_t$)는 이전의 상태 사후확률를 이용하여 시간 t에서 측정을 합치기 전의 상태를 예측하는 것을 의미하게 됩니다. $\bar{bel}$($x_t$)로부터 bel($x_t$)를 계산하는 과정을 측정 갱신/갱신 mearuement update/correction이라 합니다.
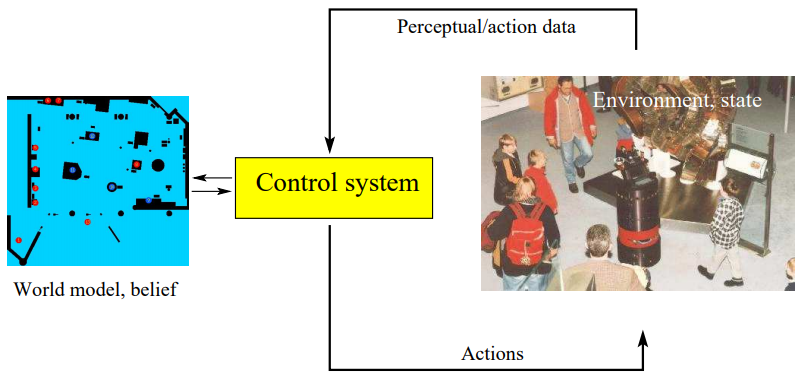
그림 2.1은 로봇이 주위 환경과 상호작용하는것을 보여주고 있습니다. 로봇의 주위 환경은 동적인 시스템으로 로봇은 센서로 부터 주위 환경에 대한 정보들을 얻을수 있습니다. 하지만 센서는 노이즈를 가지고 있으면서 직접적으로 감지할수 있는 것들이 많이 존재합니다. 그 결과 로봇은 주위 환경의 상태에 대해 내부적으로 신뢰도를 가지고 있어야 하는데 이는 좌측의 그림과 같습니다. 로봇은 또한 이 구동기를 통해 이동하면서 주위 환경에 영향을 줄수 있게 됩니다. 하지만 이러한 영향은 예측할수 없는데 더 자세히 다루어보겠습니다.
그림 2.1 로봇 환경 인터렉션
2.3.1 상태 state
환경은 상태로 정리할 수 있습니다. 상태를 로봇과 주위 환경의 모든 값들의 집합으로 보면 됩니다. 상태는 사람의 위치처럼 시간에 따라 변할수도 있고, 벽의 위치 처럼 로봇이 이동하는 와중에 정적으로 존재할 수도 있습니다. 이러한 변하는 상태를 동적 상태 dynamic state라 하며 변하지 않는 상태를 정적 상태static state라 할 수 있습니다. 이 상태들은 로봇 자신의 위치, 속도 +(센서) 등을 포함하고 있으며 이 책에서 x로, 시간 t에 대한 상태를 $x_t$로 표기하겠습니다.
- 로봇의 자세 pose 는 전역 좌표계 global coordinate frame로부터의 위치 location과 방위 orientation으로 이루어지며 강체 이동 로봇은 6개의 상태 변수를 가지고 있는데 3개의 카티지안 좌표계와 오일러 각이라 부르는 3개의 방위값(피치, 롤, 요)들로 이루어집니다.
- 주변 환경에 존재하는 물체들의 특징과 위치. 물체로는 나무나, 벽, 특정 물체가 될수 있으며 이러한 물체들의 특징으로 시각적 외형(색상, 질감)이 될수 있습니다. 그러한 상태의 입자에 따라 로봇의 주위 환경은 수십개에서 수백만개의 상태 변수로 이루어 질 수도 있습니다. 실제 물리적 환경을 정확하게 나타낼려면 얼마나 많은 비트들이 필요할지 생각해보세요. 이 책에서 다루는 많은 문제들은 주위 물체들이 정적이 될것입니다. 이 물체를 랜드마크라 부를것이며 서로 구분할수 있고, 주변환경의 일부분으로 볼것입니다.
- 움직이는 물체와 사람들의 위치와 속도. 로봇만이 환경에서 움직이는 것이 아니라 다른 개체들도 각자의 기구학과 동역학적 상태를 가지고 있습니다.
상태 $x_t$는 미래에 대한 최고의 예측기라 한다면 완전하다고 할 수 있습니다. 다시 설명하면 완전함은 상태와 측정값, 제어 입력에 대한 과거의 정보들은 더이상 정보를 주지는 않지만 미래를 더 정확하게 예측하는데 도움을 줍니다. 완전함에 대한 정의는 미래가 상태의 결정론적인 함수가 될 필요가 없는 사실을 아는것이 중요합니다. 미래는 확률적일지도 모르나, 의존 관계가 상태 $x_t$의 영향을 받지 않는다면, 미래의 확률적인 상태에 영향을 주는 변수는 존재하지 않습니다. 이러한 가설을 마르코브 체인이라 합니다.
상태의 완전함에 대한 용어는 이론적으로 중요하나 실용적인 측면에서 현실적인 로봇 시스템에서 완전한 상태는 불가능 합니다. 완전한 상태는 미래에 대해 영향을 주는 모든 환경의 측면일 뿐만 아니라 로봇 자신과 컴퓨터 메모리 주위 환경의 사람들 등을 포함하기 때문입니다. 이 모두를 얻기는 힘듦므로 현실적인 구현을 위해서 모든 상태 변수들의 일부분만 다루며 이러한 상태를 불완전 상태 incomplete state라 합니다.
대부분의 로봇 공학 응용에서 상태는 연속적이며, 연속 상태 공간의 좋은예 예시로 로봇의 자세(위치와 방위)가 있습니다. 상태가 이산적인 경우 예시로 이진 상태 공간이 있는데, 센서를 신뢰할수 있는지 없는지를 나타냅니다. 두가지 연속과 이산 변수들을 포함하는 상태 공간을 하이브리드 상태 공간이라 합니다.
로봇 공학의 문제에서 대부분의 경우 상태들은 시간에 대해 변하게 도는데 여기서 시간은 이산적으로 다룰 것입니다.
2.3.2 환경 인터렉션
로봇과 환경의 인터렉션으로 2가지 타입이 존재합니다. 로봇은 구동기를 통해 이동하면서 주의 환경의 상태에 영향을 줄 수 있으며 센서를 통해 그 상태 값을 얻을 수 있습니다. 두 타입의 인터렉션다 동시에 발생하며 이 책 전반적에 구분해서 볼것입니다. 이 인터렉션은 그림 21과 같습니다.
- 센서 측정
인식은 로봇이 센서를 사용하여 주위 환경에 대한 상태 정보를 얻어서 처리 됩니다. 예를들어 로봇이 카메라 영상, 스캔 정보나 다른 주위 환경 정보를 얻을수 있는 센서를 가졌을 수 있습니다. 이러한 인식 상호작용을 측정 measurement라 하며, 관측 observation이나 percept 인지라고도 합니다. 일반적으로 센서 측정은 약간의 딜레이를 가지고 있어 몇초 전의 상태를 제공하게 됩니다.
- 제어 동작 control anction
제어 동작은 주위의 상태를 변화시키며 영향을 줄수 있습니다. 제어 동작의 예시로 로봇이 의동과 물체를 매니퓰레이션이 있겠습니다. 그리고 로봇이 아무런 동작을 하지 않더라도 상태는 변하고 있습니다. 그래서 로봇은 이동을 위해 모터를 사용하지 않더라도 항상 제어 동작을 하는것이라 볼수 있습니다. 실제로 로봇은 제어와 측정을 동시에 끊임없이 하게 됩니다.
가설적으로 로봇은 이전의 모든 센서 측정과 제어 동작을 기록한다고 할수도 있습니다. 그러한 집합을 데이터(이들이 기억되지는 않더라도)로 보겠습니다. 두가지의 상호작용 타입과 마찬가지로 로봇은 두가지 다른 데이터 스트림을 가지고 있습니다.
- 관측 데이터 measurement data
관측 데이터는 주위 환경의 순간적인 상태 정보를 제공하고 있씁니다. 예시로 카메라 이미지, 레이저 스캔, 기타 등등이 있습니다. 대부분의 경우 우리는 아주 작은 시간 간격은 무시하게 됩니다.(예를 들자면 레이더는 매우 빠른 속도로 스캔하지만 특정 시간대의 경우에만 측정을 합니다.) 시간 t에 대한 측정 데이터는 다음과 같이 표기합니다.
이 책 전반에서 로봇은 시간에 대해 한번의 측정을 한다고 볼것이며 이 가정은 모든 알고리즘 단일 시간 단위에 대해 사용하겠습니다. 다음의 표기는 시간 $t_1$에서 $t_2$까지의 모든 측정들의 집합을 의미합니다.
- 제어 데이터 control date
제어 데이터는 주위 환경의 상태 변화에 대한 정보를 전달합니다. 이동 로봇의 제어 데이터 예시로 로봇의 속도가 있으며 5초동안 초당 10cm씩으로 속도를 설정하면 이 동작 후에 실행 전보다 50cm 정도 앞에 있음을 추정할 수 있습니다. 그래서 제어 데이터의 주요 정보는 상태의 변화들을 알려주게 됩니다.
제어 데이터의 대신하는것중 하나로 오도메터 odometer가 있습니다. 오도메터는 로봇의 휠 회전을 측정하는 센서인데, 이 센서는 상태 변화율에 대한 정보를 알려줍니다. 오도메터가 센서이더라도 로봇의 위치 변화를 주로 다루기 때문에 제어 데이터로 다루겠습니다.
제어 데이터는 $u_t$로 표기하며, 시간 주기 (t-1; t]사이의 상태 변화를 나타냅니다. 이전의 표기법 처럼 제어 데이터의 시퀀스를 $u_{t1:t2}$로 정리할 수 있습니다.
측정과 제어를 구분하는것은 매우 중요하며, 각각의 데이터는 아직 다루지는 않았지만 다른 역활을 하게 됩니다. 인지를 통해 환경의 상ㅇ태에 대한 정보를 얻으머 로봇의 지식을 늘릴수 있고, 동작을 통해서는 가지고 있는 노이즈 때문에 기존의 지식을 잃어버리게 됩니다.
확률적 로봇 공학에서의 핵심은 센서 데이터로부터 상태를 추정하는 것입니다. 상태 추정은 센서 데이터를 이용해서 직접 구할수 없으나 추론해 낼수 있는 값이나 양을 추정하는 문제를 다루고 있습니다. 대다수의 로봇 공학 어플리케이션에서 값을 확실히 알수 있다면 상대적으로 쉬울 것입니다. 예를들자면 로봇과 로봇 주위의 장애물의 위치를 알고 있다면 이동 로봇의 동작은 상대적으로 쉬울것입니다.
불행이도 이러한 변수들은 바로 구할수가 없으며, 대신 로봇은 이러한 정보들을 얻기 위해 센서를 이용하여야만 합니다. 센서들은 이 값들에 대해 부분적인 정보만 제공하며 이 측정치들은 노이즈가 더해지게 됩니다. 상태 추정은 이 손상된 데이터로부터 상태 변수를 복원하게 됩니다. 확률적인 상태 추정 알고리즘은 모든 가능한 상태들 중에서 신뢰할수 있는 확률 분포를 계산하며, 확률적인 상태 추정의 예시로 이미 소개 단에서 이동 로봇의 위치 추정 문제를 통해 살펴보았습니다.
이번 장에서의 목표는 센서 데이터로부터 상태 추정에 있어서 기본적인 용어와 수학적인 도구를 소개하여 보겠습니다.
- 2.2장에서는 이 책 전반에 사용하는 확률적인 기본 개념과 용어에 대해서 소개하겠습니다.
- 2.3장에서는 전반적으로 다루는 모델을 설명하겠습니다.
- 2.4장에서는 상태 추정을 위해 모든 기술들의 기반이 되는 베이즈 필터와 재귀적인 알고리즘을 소개하겠습니다
- 2.5장에서는 베이즈 필터를 구현시 발생하는 문제들을 다루어 보겠습니다.
2.2 확률 기본 개념
이번 장에서는 기본 용어와 확률적인 개념들을 살펴보겠습니다. 확률적 로봇 공학에서는 센서 측정, 제어, 로봇 상태, 주위 환경 등 같은 값은 확률 변수로 다룰수 있습니다. 확률 변수는 확률 법칙을 따르는 여러 값들로 이루어져 있습니다. 확률 추론은 센서 데이터와 같은 다른 확률 변수들로부터 구할 수 있는 확률 변수를 이러한 법칙에 따라 계산하는 과정이 됩니다.
X를 확률 변수, x을 X에 대한 특정 사건이라고 합시다. 확률 변수의 기본적인 예시로 코인 뒤집기인데, 여기서 X의 사건으로 앞면과 뒷면이 존재합니다. X에 대해 일어날 수 있는 값들이 이산적이라면 확률 변수 X가 x일 때 확률을 아래와 같이 나타낼 수 있습니다.
예를 들어 동전은 p(X=앞면) = p(X = 뒷면) = 1/2처럼 정리 할수 있으며, 이 이산 확률의 합은 아래와 같습니다.
추가적으로 확률은 항상 음수가 아니므로 p(X = x) >= 0이 됩니다. 이를 단순히 나타내기 위해 가능한 확률 변수의 표기를 생략하기도 하는데 p(X = x) 대신 p(x)로 주로 쓰입니다.
이 책에서 설명하는 대부분의 기술들은 연속 공간에서의 추정과 결정 문제를 다르며, 연속 공간은 연속적인 값을 가지는 확률변수로 나타낼 수 있습니다. 이 책 전체에서 확률 밀도 함수 (PDF probability density functions)를 가지는 연속 확률 변수를 사용하겠습니다. 가장 흔한 확률 밀도 함수로 1차원 정규 분포 normal distribution로 평균 $\mu$와 분포 $\sigma^2$로 이루어져 있습니다.
이 분포는 아래의 가우시안 함수로 나타낼 수 있습니다.
정규 분포는 이 책에서 큰 역활을 할것이며 이를 N(x; $\mu$, $\sigma^2$)로 특정 확률 변수와 그 변수의 평균, 분산을 표현하겠습니다.
(2.3)의 정규 분포에서 x는 스칼라 값을 의미하며 x가 다차원 벡터가 될수도 있습니다 이 경우 벡터에 대한 정규 분포를 다변수 multivarate라 하며 다변수 정규 분포는 아래의 확률 밀토 함수로 나타낼 수 있습니다.
위 식에서 $\mu$는 평균 벡터이고 $\Sigma$는 공분산이라 부르는 대칭 행렬이 됩니다. 첨자 $ ^{T}$는 벡터의 전치를 나타내며, 식 (2.4)가 식 2(.3)을 일반화 한것임을 알 수 있습니다. 1, 2차원 정규분포의 확률 밀도 함수는 그림 5.6에서 보여주고 있습니다.
식 (2.3), (2.4)은 확률 밀도함수의 예시로 이산 확률 분포의 합이 1이 되듯이 PDF도 항상 적분하면 1이 됩니다.
이 책에서는 확률, 확률 밀도, 확률 밀도함수라는 개념을 계속 사용할 것이며 모든 연속 확률 변수들이 측정 가능하고, 모든 연속 확률 분포들이 밀도를 가지고 있다고 가정하겠습니다.
두 확률 변수 X, Y의 결합 분포 joint distribution은 다음과 같습니다.
이 표현법은 확률 변수 X의 값이 x이고 Y의 값이 y일때 사건의 확률을 나타내며, X와 Y가 독립이라면 다음과 같이 나타낼 수 있습니다.
종종 확률 변수들은 다른 확률 변수들에 대한 정보도 같이 제공하는 경우도 있습니다. Y의 값인 y를 이미 알고있다고 햇을때 X의 값인 x의 확률을 다음과 같이 나타낼 수 있으며 이를 조건부 확률이라 합니다.
만약 p(y) > 0 이면 조건부 확률은 다음과 같이 정의 할 수 있습니다.
X, Y가 독립인 경우 아래와 같습니다.
다르게 설명하면 X, Y가 독립이라면 Y는 X의 값을 구하는데 영향을 주지 않는다고 할 수 있습니다. 이 경우 우리가 X을 알아야 할때 Y를 안다고 아무런 도움이 되지 않습니다. 독립과 조건부 독립은 이 책 전반에서 중요한 역활을 하게 됩니다.
조건부 확률과 확률에 대한 공리로부터 찾을수 있는것으로 전체 확률 정리 theorem of total probability가 있는데, p(x|y)나 p(y)가 0이라면, p(x|y)p(y)는 0이 됩니다.
다른 중요한 것으로 베이즈 정리가 있는데 조건부 확률 p(x|y)는 역인 p(y|x)와 관련을 가지고 있습니다. 이 정리에 따라 정리하면
베이즈 정리는 호가률적 로봇 공학에서 중요하게 되는데, x가 y로 부터 추론할 값이라면 확률 p(x)는 사전 확률 분포, y는 데이터(센서 측정값)이라 할 수 있습니다. 확률 분포 p(x)는 데이터 y를 합치기 전에 X에 대한 정보를 의미하며, 확률 p(x|y)는 X에 대한 사후 확률 분포라 부릅니다.
식 2.14)와 같이 베이즈 정리는 역 조건부 확률인 p(y|x)와 사전확률 p(x)를 이용해서 사후 확률 p(x|y)을 계산하는 쉬운 방법을 제공하고 있습니다. 우리가 센서 데이터 y를 이용해 값 x를 구해야한다면, 베이즈 정리는 x가 주어질때 데이터 y의 확률을 의미하는 역 확률을 통해 구하도록 하고 있습니다. 로봇 공학에서 이 역 확률 변수를 생성 모델 generative model이라고도 하며, 이는 어떻게 상태 변수 X가 센서 측정 Y에 영향을 주는지를 나타냅니다.
베이즈 정리에서 또 중요한 점은 분자 p(y)로 x에 대해 의존하지 않습니다. 그래서 식 (2.13)과 (2.14)에서 p(y$)^-1$은 사후 확률 p(x|y)에서 어느 x에 대해 똑같습니다. 이런 이유로 p(y$)^-1$는 정규화 변수 $\eta$로 표기하겠습니다.
확률 변수 X의 기댓값은 다음과 같이 구할 수 있습니다.
확률 변수의 선형 함수에 대한 기댓값은 다음과 같으며 여기서 a, b는 일반적인 수치 값을 의미합니다.
X의 공분산은 다음의 식으로 구할 수 있습니다.
공분산은 평균과 재곱의 기댓값의 차이로 구할수 있으며 위에서 살펴보았던 다변수 정규 분포 N(x; $\mu$, $\Sigma$)의 평균은 $\mu$이고 여기서 공분산은 $\Sigma$가 됩니다.
확률 변수의 다른 중요한 특성으로 엔트로피가 있습니다. 이산 확률 변수에서 엔트로피는 다음의 식으로 구할 수 있습니다.
엩프로피라는 개념은 정보 이론 information theory에서 나왔는데 엔트로피는 x의 값이 전달하는 정보의 기댓값을 말합니다 : -$log_2$ p(x)는 최적의 인코딩을 통해 x를 인코딩하는데 필요한 비트의 수이며 p(x)는 x를 관측할 확률을 의미합니다. 이 책에서 엔트로피는 로봇이 감지할 때 얻을수 있는 정보를 표현하기 위해 사용합니다.
마지막으로 다른 확률 변수 Z가 있는 조건부 확률을 정리하면 Z=z인 베이즈 정리에 따라 다음과 같이 정리할 수 있습니다.
변수 z가 식(2.7)처럼 독립 확률변수라면 조건부 정리는 다음과 같이 됩니다.
이러한 관계를 조건부 독립이라 하며 식 (2.24)는 다음과 같습니다.
로봇 공학에서 조건부 독립은 중요한 역활을 하게 됩니다. 다른 변수 z를 알고있으나, y가 변수 x에 대해 아무런 정보를 제공하지 않을때 사용할 수 있습니다. 조건부 독립은 완전한 독립이라고 할 수 없습니다.
로봇 공학은 물리적 세계에서 장치를 이용해 감지하고 제어하는 학문이며 대표적으로 우주 탐사에 이용되는 로봇 시스템이나 조립 라인에서의 로봇 팔, 고속도로를 달리는 자동차, 수술을 도와주는 로봇 팔 등이 있을겁니다. 로봇 시스템은 흔하게 있으며 그들은 센서로 주위 환경을 인지하고 제어를 하게 됩니다.
하지만 여전히 로봇 공학에서 부족한점은 많지만 지능을 가진 로봇은 우리 사회를 바꿀 큰 잠재력을 가지고 있스비다. 자동차가 스스로 제어하여 차 사고가 존재하지 않게 되거나 채르노빌 같은 재해 현장을 사람이 아닌 로봇이 청소한다거나 지루한 집안을 등을 로봇이 대신 할수 있으면 얼마나 좋을까요?
앞으로의 응용분야는 조립 라인에서 작업만 하던것과는 달라지고 있습니다. 새로운 로봇들은 미지의 환경에서도 동작할수 있게 되었고, 조립 라인에서는 더 정교해 지고 있습니다. 그 결과로 로봇 공학에서 센서 입력은 더 중요해지고, 여러가지 상황에 대처할수 있도록 소프트웨어도 강인해져야 합니다. 로봇공학은 그래서 점점 다양한 환경에서도 대응할수 있도록 소프트웨어 공학적인 측면이 커지고 있습니다.
이 책에서는 로봇 공학의 중요한 요소인 불확실성 uncertainty를 주로다루고 있습니다. 불확실성은 로봇이 작업을 수행하는데 중요한 정보가 부족할때 일어나는데, 여기에는 다섯가지의 요인이 있습니다.
1. 환경 : 물리적 세계는 예측하기가 어렵습니다. 반면에 조립라인과 같은 구조화된 환경에서 불확실한 정도는 작을것이나, 고속도로나 살고 있는 집은 매우 동적이고 예측하기 어려운 환경들입니다.
2. 센서 : 센서는 기본적으로 감지하는데에 있어 제한을 가지고 있습니다. 이 제한은 2가지 요소가 있는데, 첫번째로 센서의 범위와 해상도는 물리적인 법칙을 따르고 있습니다. 예를 들어 카메라는 벽 너머를 볼수 없고, 카메라 영상의 해상도는 제한되어 있습니다. 두번째로는 센서는 노이즈를 가지고 있어 센서 측정에 방해를 받아 얻을 수 있는 정보가 제한됩니다.
3. 로봇 : 로봇 구동에 있어 사용되는 모터는 노이즈 같은 예측할수 없는 영향을 가지고 있습니다. 산업용으로 사용되는 구동기는 정확할 수 있어도 이동 로봇의 저가의 경우 매우 정확하지 않습니다.
4. 모델 : 모델은 기본적으로 정확하지 않습니다. 왜냐면 모델은 현실 세계를 추상화 한것으로 로봇과 주위 환경에서 물리적인 처리 과정을 일부분만을 표현하기 때문인데, 모델 에러는 불확실성의 원인이 되나 로봇 공학에 있어서 대부분 무시됩니다.
5. 계산 : 로봇은 실시간 시스템으로 계산량이 제한되어 있습니다. 많은 최신 알고리즘들은 그래서 정확도를 희생하여 제 시간에 수행될수 있도록 추정을 수행하게 됩니다.
이러한 모든 요인들이 불확실성을 일으키게 됩니다. 기존의 로봇 공학에서 이러한 불확실성들이 무시되어 왔으나, 로봇들이 공장을 너머 구조적이지 않은 환경에서 다니게 되면서 이러한 불확실성을 다루는 능력이 중요하게 되어지고 있습니다.
1.2 확률적 로봇 공학
이 책에서는 로봇 공학에서 확률적 알고리즘들의 개요를 살펴볼 것인데, 확률적 로봇 공학은 로봇의 인지와 동작에 있어서 불확실성을 다루는 로봇공학의 새로운 접근 방법입니다. 확률적 로봇 공학의 키 아이디어는 확률 이론을 이용해서 불확실 성을 다루는 것인데, 현실 세계에서 정확한 값을 사용하기 보다는 확률적인 알고리즘은 확률 분포로 정보를 표현하게 됩니다. 이렇게 함으로서 애매함과 신뢰할수 있는 정도를 나타낼 수 있는데, 이를 이용해서 아서 설명한 불확실성을 다룰수 있게 됩니다. 그러므로 확률 정보를 이용하여 제어 결정을 다룸으로서 이러한 알고리즘들은 다양한 불확실성들을 다룰수 있으며 어려운 로봇 공학 문제들의 해결 방법으로 사용되고 있습니다.
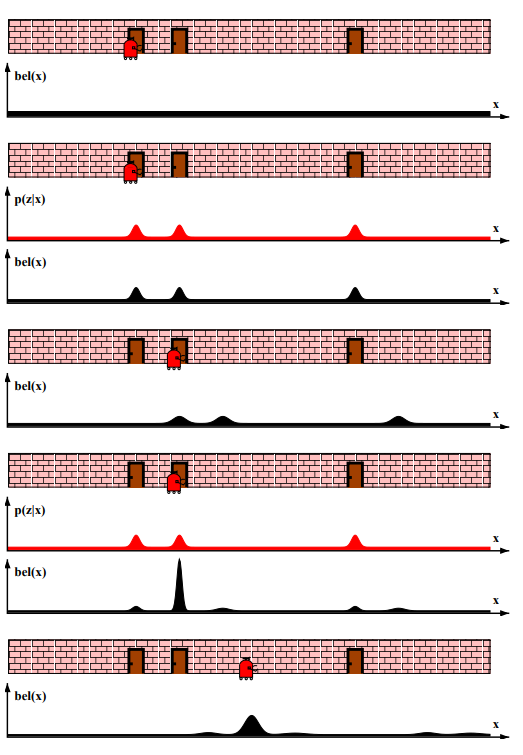
간단한 예시(이동 로봇 위치 추정)로 확률론적인 접근 방법을 살펴보겠습니다. 위치 추정은지도를 사용하여 센서 데이터로부터 로봇의 좌표를 추정하는 문제인데 그림 1.1이 이동 로봇 위치 추정문제에서 확률적인 접근 방법을 보여주고 있습니다. 이러한 위치 추정 문제를 전역 위치 추정 global localization 이라 하는데, 이는 처음 부터 로봇이 어디에 있는지 추정해 나가는 문제를 말합니다.
확률적 다이어그램에서 로봇의 추정량(신뢰도라 합니다)은 확률 밀도 함수로 표현되며, 그림 1.1의 첫번째로 균일 분포(사전 확률)를 보여주고 있습니다. 로봇이 처음으로 센서 데이터를 받았더니 문이 존재한다고 가정해봅시다. 그러면 그림 1.1에서 2번째 다이어그램 처럼 문이 존재하는 곳들이 높은 확률을 가질것이고, 나머지 부분들은 낮은 확률을 가질 것입니다. 이 분포들은 3개의 꼭대기를 가지고 있는데 각각은 구분할수 없으나 문들중 하나를 나타내고 있습니다.
그러므로 결과적인 확률 분포는 3위치에 높은 확률로 나타나고 있으며, 확률적인 방법들로 이러한 모호한 상황에서 자연적으로 발생하는 여러 상반된 가설들을 다룰수 있습니다. 그래서 문이 아닌 위치에는 0이 아닌 확률들을 가지고 있습니다. 이는 측정 시 내재된 불확실성에 의해 설명할 수 있는데, 이러한 작은 0이 아닌 확률들은 로봇이 문 앞에 있지 않음을 의미합니다.
이제 로봇이 움직인다고 가정해봅시다. 그림 1.1의 세번째 다이어그램은 로봇이 이동한 후의 신뢰도를 보여주고 있습니다. 신뢰도들은 동작 방향을 따라 이동했으며 로봇이 가지고 있는 불확실성에 의해 완만해 졌습니다. 마지막으로 그림 1.1의 4번째와 마지막 다이어그램을 살펴보면 다른 문을 관측한 이후의 신뢰도를 나타내는데, 이 관측을 통해 문 앞 중 가장 가능성이 높은 곳에 위치하게 되며, 이 곳에 로봇이있다고 볼수 있습니다.
그림 1.1 마르코브 위치 추정의 기본 아이디어 : 이동 로봇의 전역 위치 추정
이 예시는 인지 문제에 있어서 확률적인 파라다임을 보여주는데, 로봇 인지 문제는 상태 추정 문제이며, 로봇의 위치 추정 예시는 전체 공간에서 사후 확률 추정치를 구하는 베이즈 필터라고 부르는 알고리즘을 사용한 것입니다. 비슷하게 동작을 결정할때, 확률적인 접근방법으로 모든 불확실성을 고려해야 합니다. 이렇게 함으로써 확률적인 접근 방법은 수집 한 정보를 이용해 최적의 동작을 수행하게 됩니다.