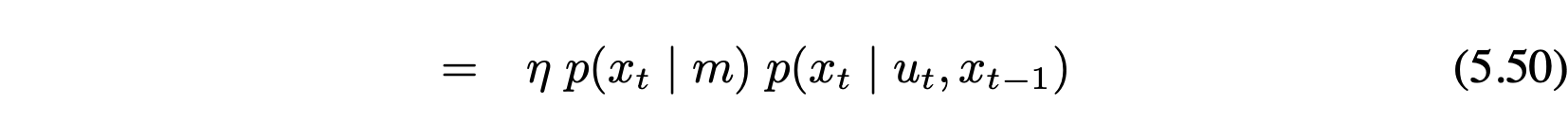6.4.2 우도 필드 추가사항 extensions
전에 다루었던 빔 기반 모델에비해 우도 필드 모델의 이점은 부드러움이라 할 수 있습니다. 유클리디안 거리의 부드러움으로 로봇의 자세 $x_t$에서 약간의 변화는 결과 분포 p($z_t^k$ | $x_t$, m)에서 약간의 영향만을 가지게 됩니다. 다른 주요 이점은 3차원 대신 2차원에서 전계산이 수행되어 전계산된 정보의 조밀함이 더 커지게 됩니다.
하지만 이 모델또한 3가지 주요 단점을 가지고 있는데, 첫째는 짧은 거리로 읽힐수 있는 사람이나 다른 동역학을 설계할수 없는 점이고, 2번째는 벽너머도 볼수있는것처럼 센서를 사용하는데, 이는 광선 투사 동작이 최근접 이웃 nearest neighbor 함수로 대체되기 때문입니다. 이 최근접 이웃 함수는 점까지의 경로가 지도상의 장애물로 가로막히는지 아닌지 판단할수 있는 능력을 가지지 못하고 있습니다. 셋 째 이유는 여기서는 지도의 불확실성을 고려하지 않았습니다. 확실히 얘기하면 확인하지 않은 공간들을 다룰수 없으며, 이 공간들은 명시되지 않거나 매우 큰 불확실성을 가지고 있습니다.
우도 필드 거리계 모델 기본 알고리즘들은 이 제한들의 영향을 줄이도록 개선시킬수가 있는데, 예를들어 기존의 2가지 값을 사용하던 지도를 3가지 카테고리의 값(점유, 텅빈, 알수없음)으로 사용하는 방법이 있습니다. 센서 측정 $z_t^k$가 알수없음 카테고리에 해당될때, 그 확률 p($z_t^k$ | $x_t$, m)은 상수 값인 $\frac{1} {z_{max}}$라 가정합니다. 확인되지 않은 공간에서의 확률적 모델 결과는 센서 측정값이 동일하다고 봐서 p($z_t^k$ | $x_t$, m)는 밀도 $\frac{1} {z_{max}}$에 대한 균일 분포로 설계 됩니다.

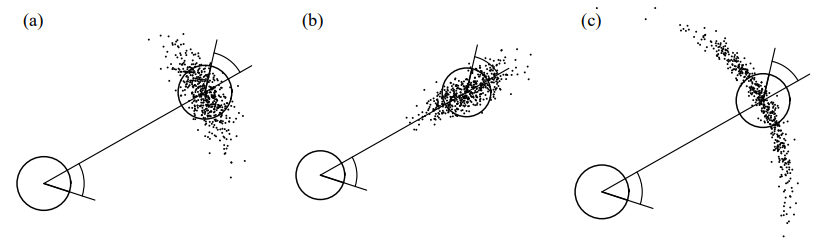
그림 6.9 (a) 샌 조스 테크 박물관 san jose tech museum의 점유 격자 지도, (b) 전처리된 우도 필드
그림 6.9는 지도와 그에 대한 우도 필드를 보여주고 있습니다. 여기서 x-y 위치의 회색 정도는 센서가 읽은 우도치를 알려주며, 여기서 최근접 장애물까지의 거리가 지도 안에 있는것으로 판단되어 탐사된 공간으로 본다는것을 알 수 있습니다. 바깥의 우도 p($z_t^k$ | $x_t$, m)는 상수 값이 됩니다. 계산을 효율적으로 하기 위해서 2차원 그리드에서 최근접 이웃 전계산이 중요한데, 볼수 있는 공간 전반에 대한 우도 필드는 지역 지도를 정의하는 최근 스캔으로 구할 수 있습니다. 직관적으로 확장하자면 스캔 데이터와 맵을 체계적으로 매칭시키고, 맵 안에 스캔된 우도 필드를 계산을 수행함과 더불어 체계적인 확장이 스캔된 우도 필드에 상대적인 물체에 대한 우도를 계산합니다. 이러한 체계적인 루틴은 이후 맵핑에서 중요하게 다루어 질것인데 이 스캔들을 정리하여 맵을 만들게 됩니다. 간결하게 일단 표 6.3에 대한 알고리즘을 구하는 과정은 생략하겠습니다. 하지만 우도 필드 기술 구현이 이 확장된 체계적인 알고리즘이 사용됩니다.

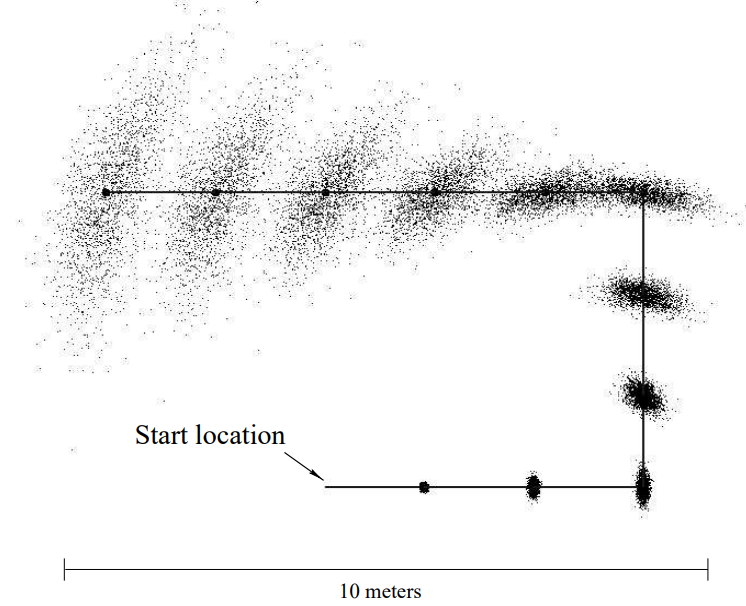
그림 6.10 (a) 버드 아이 뷰로 본 센서 스캔. 로봇은 그림 바닥에 위치하여 180도 전방에 대한 스캔 데이터를 생성
(b) 센서 데이터로 생성한 우도 함수. 검은 지역일수록 물체가 거기에 존재할 우도가 작음. 점유된 지역은 하얗게됨.
6.5 상관관계 기반 센서 모델 correlation-based sensor model

측정치와 지도사이에 상관관계를 측정하는 다양한 거리 센서 모델들이 존재하는데, 여기서 대표적인 기술로 지도 매칭 map matching이 있습니다. 지도 매칭은 이후 챕터에서 다룰것이지만 스캔 데이터를 점유 격자 지도에 변환을 수행합니다. 일반적으로 맵 매칭은 연속적인 약간의 스캔 데이터를 지역 지도 local map $m_{local}$로 변환시키는 것으로 그림 6.11이 점유 격자 형태의 지역 지도를 보여주고 있습니다. 관측 모델은 지역 지도 $m_{local}$을 전역 지도 m에 비교하는데 p($m_{local}$ | $x_t$, m)가 클수록 m과 $m_{local}$이 더 비슷해집니다.
지역 지도는 로봇 위치에 상대적인 표현으로 비교하기 위해선 지역지도의 셀들을 전역 지도 좌표계상으로 변환을 해야합니다. 이 변환은 우도 측정 모델이 사용된 센서 측정의 좌표 변환 (6.33)과 비슷하게 수행되는데, 로봇이 위치 $x_t$에 존재하면 $m_{x, y, local}$($x_{t}$)로 나타내며 지역 지도의 그리드는 전역 좌표계의 (x y$)^T$에 대응하게 됩니다. 둘다 같은 기준 좌표계에 존재한다면, 아래와 같이 정의되는 지도의 상관 함수로 비교할수 있는데

여기서 모든 셀에 대한 합은 지도 둘다 다음과 같이 정의할 수 있고, $\bar{m}$은 지도의 평균값이 됩니다.

N은 지역 지도와 전역 지도 사이 겹친 요소의 수를 나타냅니다. .상관관계 $\rho_{m, m_{local}, x_t}$의 스케일은 +-1로, 맵 매칭은 로봇의 자세 $x_t$와 전역 지도 m이 주어질 때 지역 지도의 확률로 정리할 수 있습니다.

맵 매칭은 수많은 성질들을 가지고 있는데, 자세 파라미터 $x_t$에서 부드러운 확률을 구할수 있지는 않지만 우도 필드 모델처럼 계산하기 쉽습니다. 이 우도 필드를 근사화하는 방법은 지도 m을 가우시안 커널과 컨볼루션을 하고 이 부드러워진 지도를 맵매칭을 수행하면 됩니다.
가우시안 필드에서 맵매칭의 가장 큰 이점은 두 지도 사이의 점수에서 자유 공간을 도려하는 점인데, 우도 필드 기술은 점유된 공간이라고 판단하는 스캔의 끝점만을 다룹니다. 하지만 많은 지도 맵핑 기술들은 센서 너머서도 지역 지도를 만들게 됩니다. 예를 들면 이 기술들은 실제 센서 측정 거리의 0.5까지만 측정하도록 설정하면 로봇 주위로 원형 지도를 만들게 됩니다. 이런 경우처럼 센서가 벽 너머서도 볼수있는것 처럼 실제 측정 거리를 벗어난 공간을 합칠때 위험할 수 있습니다. 이런 사이드 이펙트는 수많은 맵 매칭 기술들에서 볼수 있습니다. 이 단점은 맵 매칭이 물리적으로 합리적이라고 할수는 없지만, 상관관계가 지도 사이의 2차적인 거리를 정규화 되어집니다.
'번역 > 구)확률적로봇공학' 카테고리의 다른 글
| 확률적 로봇 공학 - 6.6.3~ 알려진 대응관계를 가진 센서 모델 (0) | 2020.06.24 |
|---|---|
| 확률적 로봇 공학 - 6.6 특징 기반 센서 모델 (0) | 2020.06.24 |
| 확률적 로봇 공학 - 6.4 거리계에 대한 우도 필드 (0) | 2020.06.23 |
| 확률적 로봇공학 - 6.3.4 현실적인 고려 사항 (0) | 2020.06.23 |
| 확률적 로봇공학 - 6.3.2 고유 모델 파라미터 조절하기 (0) | 2020.06.23 |