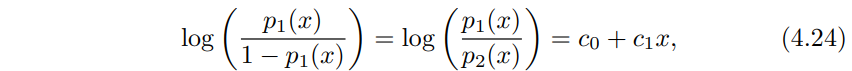LOOCV Leave-one-out cross-validation은 5.1.1장에서 본 검증 방법과 비슷한 방법이나 그 방법의 결점을 개선한 것으로 교차 검증셋 방법처럼 LOOCV도 전체 데이터를 두 파트로 나누지만, 어느 정도의 크기의 하부 집합으로 분할하는게 아니라 하나의 데이터 ($x_{1}$, $y_{1}$)만 검증 셋으로 사용하고 나머지 {($x_{2}$, $y_{2}$, . . ., ($x_{n}$, $y_{n}$))}은 훈련셋으로 사용하는 방법입니다. 그래서 통계적 학습 방법을 이용하여 n - 1개의 훈련 데이터들을 학습하고, 1개의 데이터 $x_{1}$으로 $\widehat{y}_{1}$을 예측하게 되요.
($x_{1}$, $y_{1}$)만 훈련 과정에서 사용되지 않다보니 $MSE_{1}$ = ($y_{1}$ - $\widehat{y}_{1}$ $)^{2}$은 불편향 추정량인 테스트 에러가 됩니다. 그리고 하나의 데이터만 가지고 테스트를 추정기에는 변동이 큰 문제가 있겠습니다. 이 과정을 ($x_{2}$, $y_{2}$)을 검증셋으로 사용하고 나머지 n - 1개를 훈련으로 사용해서$MSE_{2}$ = ($y_{2}$ - $\widehat{y}_{2}$ $)^{2}$ 를 계산할 수가 있겠습니다. 그래서 이 제곱 오차를 n번 구할수가 있고 $MSE_{1}$, $MSE_{2}$, . . . , $MSE_{n}$을 구해서 이 n 개의 테스트 에러 추정치를 평균으로하여 LOOCV 추정량을 계산 할 수가 있겠습니다.
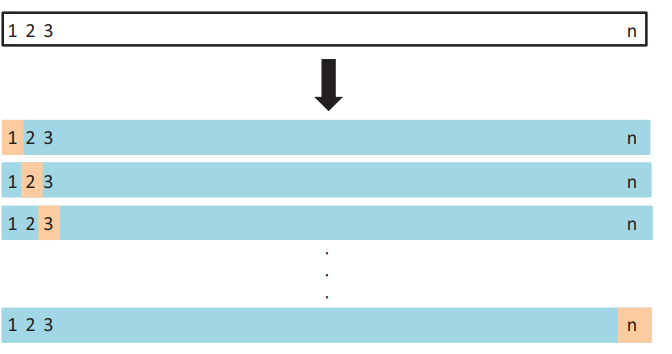
그림 5.3 LOOCV 개요도. n개의 데이터를 가지고 데이터 1개를 검증셋(주황색), 나머지 n - 1개의 데이터들을 훈련셋으로 사용함. 테스트 에러는 n개의 MSE의 평균을 구하여 계산한다.
* LOOCV에 대한 내용은 여기까지만*
5.1.3 K-폴드 교차 검증
이번에 볼 LOOCV(생략)의 대안으로 사용할 수 있는 방법으로 k-fold 교차 검증 방법이 있다. 이 방법은 전체 데이터들을 동일한 사이즈를 가지는 k개의 그룹(폴드)로 무작위로 나누고 한 폴드는 검증 데이터셋 나머지 k - 1개의 폴드들은 학습하는데 사용하는 방법이다.
평균 제곱 오차 MSE는 각 폴드들은 한번은 검증 데이터셋, 나머지는 학습 셋으로 사용되도록 하여 전체 k번을 반복하며 각 k 번째 폴드의 $MSE_{1}$, $MSE_{2}$, . . ., $MSE_{k}$의 평균을 구하는 식으로 K-폴드 검증 테스트 에러를 구한다.
그림 5.5 이 그림은 5-폴드 교차검증의 개요도로. 전체 데이터들을 겹치지 않는 5개의 그룹으로 분할한다. 각 분할된 폴드(베이지)는 검증셋으로 사용되고, 그 이외는 훈련셋(파란색)으로 사용된다. 테스트 에러는 각 폴드들의 MSE를 평균으로 계산한다.
LOOCV는 K-폴드 교차검증에서 k를 n으로 설정한거라고 할수 있는데, k-폴드 교차검증에서는 k = 5 혹은 k = 10이라는 식으로 사용한다. k = n이 아닌, k = 5 또는 k = 10으로 지정해서 사용ㅇ하는 경우 이점은 어떤게 있을까? 가장 명확한 장점은 계산 성능이라고 할수 있겠다. LOOCV는 학습과정에 n번을 수행하여야 하다보니 계산 비용이 아주 클수가 있다.
하지만 교차 검증은 어떤 통계적 학습 방법이던 간에 사용할수 있는 방법이기도 한데, 일부 학습 방법의 경우 계산 비용이 아주 클수가 있고, 그래서 LOOCV는 특히 n이 큰 경우에 계산비용적으로 문제가 될수 있다.
하지만 이와 반대로 10-폴드 교차검증의 경우에는 학습 과정을 10번만 하면 되다보니, n보다는 더 계산할수 있으며, 5.1.4장에는 5-폴드 혹은 10-폴드 교차검증의 계산과 관련되지 않은 장점들 편향-분산의 트레이드오프를 보겠다.
그림 5.4 차량 데이터셋에서 마력에 대한 다항함수로 mpg를 얼마나 잘 예측하는지를 보기 위해 테스트 에러를 계산하도록 교차검증이 사용됨. 좌측 : LOOCV 곡선, 우측 : 10폴드 교차검증으로 구한 결과. 우측의 계산 결과들은 조금씩 다르게 나오고 있다.
그림 5.4의 우측 판낼은 10-폴드 교차검증으로 구한 9개의 테스트 에러 결과인데, 10폴드로 나누어서 학습하고 검증시킨 결과에 약간의 변동이 있는걸 볼수 있다. 하지만 이 변동은 그림 5.2의 오른쪽 판낼에서 볼 수 있는 검증셋 방법(홀드 아웃 방법)보다 테스트 에러에서 변동이 일반적으로는 더 작다.
실제 데이터를 사용하는 경우, 우리는 실제 테스트 MSE를 모르다보니 교차 검증의 결과가 얼마나 정확한지를 판단하기는 어려우나 시뮬레이션으로 생성한 데이터를 사용하는 경우 실제 Test MSE를 계산할수 있고 교차 검증의 결과가 얼마나 정확한지 평가할 수 있다.
그림 5.6 그림 2.9, 2.10, 2.11에서 사용한 시뮬레이션 데이터의 실제 그리고 추정 테스트 MSE. 실제 MSE는 파란색 선이고, LOOCV로 구한 결과는 검은 점선, 10-폴드 교차 검증으로 구한 결과는 주황색이다. 그리고 X 표시된 지점은 각 MSE곡선이 최저인 지점들을 표기하였다.
그림 5.6은 2장에서 본 그림 2.9 ~ 2.11에서 사용된 시뮬레이션된 데이터를 가지고 교차 검증/실제 테스트 에러율을 보여주고 있습니다. 여기서 실제 테스트 에러율은 파란선이고, 검은 점선과 주황 선은 LOOCV와 10-폴드 교차검증 추정 MSE가 됩니다.
세 플롯들 다 두 교차 검증 추정량은 비슷하지만 그림 5.6의 오른쪽 판낼에서 실제 테스트 에러율과 교차 검증 테스트 에러율이 아주 비슷한 것을 볼 수 있습니다. 그림 5.6의 중간 판낼의 경우 두 교차 검증 곡선은 차수/유연성이 낮을때는 비슷하지만 유연성/차수가 높을때 테스트 에러율을 과대 추정하고 있습니다. 그림 5.6의 왼쪽 판낼은 교차 검증 곡선들을 형태는 올바르지만 실제 테스트 MSE를 과소 추정하고 있는걸 볼 수 있습니다.
이런 교차 검증을 사용해서 테스트 MSE 추정치를 계산을 하는게 목표가 될 수도 있고, 테스트 MSE 커브의 최소가 되는 지점을 찾는게 목표가 될수도 있겠습니다. 이 지점은 다양한 차수/복잡도를 가지는 모델을 교차검증으로 구할수가 있습니다. 그림 5.6에서처럼 어떤 경우 테스트 MSE 곡선이 실제 테스트 MSE를 과소 평가할때도 있지만, 모든 교차 검증 곡선들은 복잡도에 따라 동일한 형태를 보이며 이를 통해서 가장 작은 테스트 MSE를 찾을수가 있겠습니다.
이번 주에는 그래도 설 연휴 쉬고난 직후였던 지난 주보다는 마음 잡고 조금은 더 많이 할 수 있었다.
통계적 학습 기법
이번 주 동안에는 분류 문제를 다루는 다양한 통계적 학습 기법을 살펴봤는데 대표적으로 로지스틱 회귀 모델과 선형 판별 분석, 그리고 이차 판별분석 등을 살펴 봤었고, 다양한 시나리오 그러니까 데이터들이 어떤 특성을 보이는지 분포가 어떻게 되는지와 같은 상황에 따라 비모수적 분류 모델인 KNN 분류기를 포함하여 각 방법들이 어떤 특성과 성능을 보이는지 정리할 수 있었다.
이 외에는 뭐더라.. 그 리샘플링 방법에 대해서 간단히 살펴봤는데, 대표적인 리샘플링 방법인 교차 검증이나 부트스트랩 같은 방법에 앞서 가장 간단한 방법인 홀드 아웃에 대해서 살펴보면서 일단 통계적 학습 기법을 마무리하였다. 이번 주중으로 챕터 5장은 마무리 해야지
컴퓨터 비전을 위한 딥러닝
다음으로 컴퓨터 비전을 위한 딥러닝의 경우 이번주 초에는 상당히 고생을 했었다 1시간 짜리 영어 강의를 이해하기 위해서 번역을 하면서 정리를하는데 강의 하나를정리하는데 순수하게 8 ~ 12시간 쯤 걸리는것 같다. 왜냐면 직독 직해가 가능한 간단한 표현들도 존재하지만 특히 이론적인 동작 원리를 설명하는 부분에서 직독 직해가 안될 때가 많고, 이게 실제 강의한 내용들을 정리하다 보니 구어체적인 표현들이 내가 배웠던 영어 문법과 맞지 않아 교수님이 문법을 엉터리로 하구나?라고 생각이 들기도 했었다. 사실 내가 다양한 표현들을 제대로 공부안해서 모르는거기도 하지만
하지만 내가 이 강의를 정리할 때 가장 큰 문제는 표현들을 모르는것도 있지만 너무 직역을 하려고 하고 있었더라 적당히 의역을 해야하는데, 나도 모르는세 한단어 한단어 의미를 바꿔가면서 하려고하다보니 시간도 오래걸리고 말도 덜 자연스러웠다. 거기다가 내가 이해하지 못하는 부분이 생기면 따로 검색을 하거나 파파고 번역기도 돌려보고 어떻게 하면 이걸 정리할수 있을까 삽질하느라 시간이 너무 소모가되고 붙잡고할 맨탈도 너무 무너졌었다.
그런 이유로 어떻게 하면 리딩을 잘 할수 있을가 검색하다가보니 내 문제는 리딩 보다는 분명 아는 단어들인데 왜 해석을 해도 이해가 안되는 말들이 나오는지가 문제였고, 이에 대한 유튜브 검색을 하다가 내가 의역을 잘 하지 않는다는걸 알게되었다. 그 덕분에 이후에는 교수님이 문법에 맞지 않는 단어들을 사용한다 해도 거기에 큰 의미를 두지 않고 나름대로 의역을 하려고 신경 쓴 덕분에 이전 보다는 내용을 정리하는데 약간은 시간이 더 빨라진것 같았다.
그리고 이전까지는 PPT에다가 정리를 해왔었는데 이걸 정리하는데 낭비하는 시간이 너무 많아서 아예 블로그에다가 올리고 있고, 지난번에 다 못뽯었던 신경망을 잘 학습시키기 위해서 학습전에 설정해야 할것들, 활성화 함수, 데이터 전처리, 가중치 초기화, 규제 방법들에 대해서 전체적으로 살펴 볼수 있었다. 또 다음 강의에서는 신경망을 잘 학습하기위해서 알아야 할 것들 중에 가중치 감쇄에 관한 내용들을 살펴 보았다.
기타
이 외에는 알고리즘 공부를 하던중 이번에는 그래프에 대해서 정리해보았다. 이전부터 SLAM에 대해 관심을 가져오다보니 그래프에 대해서 제대로 공부를 하고 싶어했었는데, 오랜만에 그동안 공부했던 내용들을 한번에 다 정리해볼 수 있었다.
간단하게 그래프가 무엇인지 어떻게 생겼는지, 그리고 그래프를 어떻게 표기를 할수 있는지, 그래프에 대한 종류, 그래프를 저장하는 방법과 그래프의 사용 예시까지 우선 첫번째 글에서 다루었고
그 다음으로는 그래프 이론에 대한 배경 쾨니히스베르크의 다리 이야기에서 부터 시작하였다. 쾨니히스베르크의 다리, 해밀턴 경로, 외판원 문제 TSP에 대해서 살펴보면서 TSP가 NP-완전 문제였는데, 이전 부터 도대체 NP-완전이 뭔지 NP가 뭔지 감이 잘 잡히지를 않았었다
그렇다보니 이번에 이 개념들을 한번 정리해보자 해서 NP에 대한 글을 찾아봤고, NP가 비결정론적 튜링머신으로 다항식 시간에 풀수 있는 문제라는걸 알게 되어 그러면 튜링 머신이 뭔지 비결정론적인 튜링 머신이랑 뭐가 다른지를 그리고 다항시간이 뭔지 등을 나오는 개념들 중에서 내가 NP-완전이라는 단어를 한번에 정리할수 있을 만큼 모르는 개념들을 계속 파고파고 들어갔다.
그 덕분에 튜링 머신이 무엇인지, 추상 기계의 한 종류이며 사고 실험을 하는데 사용하는 것인걸 알 수 있었고, 비결정론적인 튜링머신이란게 튜링 머신이 한번의 상태에 대한 연산만 가능했다면 아무것도 안하거나 여러가지를 동시에 할수 있는 튜링머신이란걸 알수 있었고 실제로 구현을 할수가 없어 비결정론적인 튜링 머신으로 풀수 있는 문제들은 정확한 해를 구하지 못하고 근사적인 방법으로 푼다는 것을 알 수 있었다.
이 외에도 이러한 개념들이 계산 이론, 계산 복잡도 이론에 관한 것이다 보니 결국에 계산 복잡도 이론이 현실에 존재하는 수 많은 문제들을 다양한 복잡도를 기준으로 분류하기 위한 문제 집합에 대한 연구 분야라는걸 알 수 있었고 EXPSPACE, EXPTIME, PSPACE, PTIME, NP 등과 같은 용어들이 문제 집합이라는것을 알 수 있었다. 그래서 대략적인 NP완전에 대한 개념들을 이애 할 수 있었다.
마지막으로는 그래프를 이용한 탐색 방법이 어떤것들이 있는지 DFS, BFS가 있는지를 간단하게 보고, 백트래킹이 무엇인지 보고 제약 충족문제 CSP가 어떤것들이 있는지 살펴보면서 마무리할수 있었다.
이제 11번째 강의를 할 차례고 오늘 배울 내용은 몇가지 핵심적인 팁들과 신경망을 학습하는데 필요한 기법들에 대해서 배워보도록 합시다.
우선 이번 강의에서 더 나은 제목을 만들지 못해서 일단 사과를 하고, 지난 강의에서는 신경망을 학습을 할때 필요한 다양한 방법들을 살펴봤었습니다. 하지만 어떻게 해야 좋은 타이틀을 만들지가 어려웠습니다.
아무튼 이번 강의에서는 여러분들이 신경망을학습하는데 알아야할 것으로 약간 다른 주제의 중요한 것들을 다루려고 합니다. 지난 시간에는 one-time setup 그러니까 신경망 아키텍처에서 시작 설정을 어떻게 할지에 대해 위주로 살펴봤는데 학습을 시작하기전에 해야될 것들을 배웠다고 할수 있겠습니다.
그래서 아주 다양한 활성화 함수들에 대해서 살펴봤었고, 왠만한경우 ReLU를 사용하기로 정리하였습니다.
그리고 데이터 전처리에 대해서도 이야기 했지만, 데이터 전처리에 관한 미스터리들은 과제를 하면서 이해할수 있었을거에요.
그리고 다음으로는 자비에 같은 초기화 방법들을 사용해서 어떻게 활성화 함수를 초기화 시킬지 신경망 각 계층마다 좋은 분포로 나올수있도록 하는 것에 대해서 살펴봤구요. 그 과정에서는 출력 결과가 너무 작아 0에 가까워지거나 혹은 너무커서 1이나 -1로 극단적으로 되거나 하는 문제 사이에서 어떻게 이걸 트레이드 오프/궤환관계/조정을 해나갈지에 대한것들을 볼수 있었습니다.
그리고 지난 시간에 데이터 증강에 대해서 이야기했는데, 기존 훈련 셋을 신경망에 학습 시키기전에 훈련 데이터셋을 임의의 변환들을 적용해서 훈련 셋의 크기를 여러배로 늘리는 방법을 말한다고 했었습니다. 그리고 데이터 증강 방법을 고를때 우리가 어떤 문제를 다룰것인지에 따라 다른 데이터 증강 기법을 사용해서 신경망 훈련 과정에 사용하였습니다.
그리고 우리는 규제에 대한 일반적인 개념들을 봤었는데, 과제물에서 l2 같은 규제가 규제항을 추가하여 사용해보았을겁니다. 이 규제항은 비용 함수에 추가되어 패널티를 주는데 L2 규제의 경우 가중치 행렬의 노름 norm을 사용하였었구요.
하지만 지난 시간에는 신경망에서 자주 사용되는 더 일반화시킨 규제기, 규제 역활을하는 방법에 대해서 봤었는데 이 방법에서는 신경망의 순전파 처리과정에 랜덤성 같은 노이즈를 주고, 테스트 과정에서 노이즈/랜덤성에 대해 주변화를 한다거나 평균을 구하는 과정이 규제의 일반화 된 패턴인 것으로 알 수 있었습니다.
위 그림에서 다양한 규제 방법들의 예시를 볼 수 있는데, 우리는 드롭 아웃이나 프랙탈 풀링, 드롭 커낵스, 확률적 깊이 방법이나, 실제로는 잘 사용되지는 않지만 컷아웃이나 믹스업 같은 특이한 방법도 알아봤었어요. 아무튼 규제에 대해서는 여기까지 봤고, 이제 다음 배울 내용으로 넘어갑시다.
지금까지는 지난 시간에 배운 내용들을 살펴봤고, 오늘은 어떻게 신경망을 학습시킬것인가에 대한 다른 중요한 주제들에 대해서 배워봅시다. 특히 이번에 이야기하고자 하는건 모델을 훈련 시킬때 조심할 필요가 있는데, 모델이 학습할수 있도록 하기 위해선 학습률 스케줄 learning rate schedule을 설정하고, 어떻게 하이퍼 파라미터를 선정할지를 잘 고려애야 합니다.
이 과정이 엄청 힘든건 알지만, 그 이후에 우리가 추가적으로 고려해야 할 사항들은 학습을 잘 마친 이후인데, 우리 모델을 어떻게 할지에 대해섭니다. 모델 앙상블을 할수도 있고, 전이 학습을 할 수도 있고, 그리고 만든 모델을 스케일 업, 더 키워서 어떻게 전체 데이터센터 레벨에서 계산을할지 등을 학습한 이후에 고려해야 합니다.
우선 가장 먼저 다룰 주제는 학습률 스케쥴 learning rate schedules인데
이전에 다양한 최적화 알고리즘을 봤었었죠. 바닐라 SGD나 SGD + 모멘텀, Adagrad, RMSProp, Adam 같은 것들이요. 그리고 이 모든 최적화 알고리즘들은 학습률 learning rate라고 부르는 하이퍼 파라미터를 가지고 있었어요. 보통 이 학습률 하이퍼 파라미터는 심층 신경망 모델을 설정하는데 있어서 필요한 가장 중요한 하이퍼 파라미터라고 할수 있습니다.
지금까지는 다양한 모델들에다가 SGD를 사용을 했었다보니, 다른 최적화기에다가 다른 학습률을 사용했을때 어떤일이 일어날지 아마 감이 잡히기 시작할건데, 일단 위의 왼쪽 그림으로 다양한 학습율을 지정했을때 최적화가 어떻게 되는지 보여주고 있다.
이 그림에서 노란색 예시는 학습율을 너무 높게 지정한 경우로 바로 폭증해 버려 무한대로 가게 된다. 그래서 아주 빠르게 잘못되는 경우라고 볼수 있다. 반대로 파란색 같은 경우에는 학습률을 아주 작게설정한 경우로 학습하는 과정이 매우 느리게 진행된다. 이렇게 학습률을 설정한느건 비용이 무한대로 폭증하지는 않아 좋을수는 있지만, 학습하는 과정에서 비용이 떨어지도록 하는데 오랜 시간이 걸리게 된다.
이번에 녹색선의 경우 학습률이 높기는하나 너무 싶하기 크지는 않은 경우로 다행이 비용이 무한대로 폭증하지는 않는다. 파란색 학습률보다 높게 설정한 덕분에 더 빠르게 최저점으로 수렴을 할수있으나 비용이 최소가 되는 지점으로 확실하게 수렴한다고는 할수 없는 문제가 있다.
마지막으로 빨간색 곡선의 경우 가장 이상적인 학습률로 비용이 최소가 되는 지점으로 빠르게 수렴하며, 무한대로 폭증하지 않고, 학습 과정이 꽤 빠르게 진행된다. 그래서 빨간색 곡선과 같은 학습률을 찾는게 좋겠다.
하지만 빨간색 커브처럼 좋은 학습률을 찾지 못하는 경우도 있는데, 이런 완벽한 학습률을 찾을수 없을때는 위의 질문 처럼 우리는 어떻게 해야할까? 어떻게 위 그림에서 보이는 차선의 학습률들 사이에서 트레이드 오프를 잘 고려해서 선택해야한다고 한다면
위 질문에서는 사용하기 가장 좋은 학습률이 어떤 것인가를 묻고 있으나 이 질문을 조금 비틀어서 보면, 꼭 다양한 학습률중에서는 한가지만 사용해볼 필요 없이 모두 사용해보면 된다.
예를 들자면 상대적으로 학습률이 큰 경우에서 시작해서 녹색 곡선같은, 그러면 비용은 첫 학습 에폭에서는 비용이 어느 정도 낮은 지점까지 떨어지고 나서 시간이 흐르면 녹색 커브는 평평하게 된다.
파란색 곡선처럼 학습률이 낮은 경우를 생각하면 결국에는 비용이 가장 최저가 되는 지점을 찾을수 있을거다. 그래서 높은 학습률에서 시작하고 시간이 지나면서 학습률을 낮추면, 시작 당시에는 빠르게 진행하고 학습 끝에는 비용이 아주 작은 지점으로 수렴할수 있게 된다.
하지만 지금까지 이야기 했던 것들은 명확하지 않고 애매하게 이야기를 했는데, 지금까지 큰 학습률로 시작하고 나중에는 낮은 학습률을 사용한다고 했지만 이 과정을 어떻게 구체적으로 표현할 수 있을까?
조금 더 구체적으로 이야기 하자면 학습 과정에 학습률을 바꿔가는 메카니즘을 골라서 처리하는 과정을 학습률 스케쥴이라고 한다. 이 학습률 스케쥴에는 여러가지가 있는데 심층 신경망 모델을 학습하는데 자주 사용되고 있다.
가장 많이 사용되는 학습률 스케줄 방법으로 스텝 스케줄이 있다. 위 예시에서 여러가지 학습률 값들이 있는데 ResNet에서 이런 스텝 학습률 스캐줄이 잘 사용되고 있다. 이런 학습률 스케쥴을 가지고 처음에는 상대적으로 큰 학습률 0.1로 시작하였다가 최적화 가정에서 특정 지점에서 학습률을 감쇄시키고자 더 낮은 학습률을 사용한다.
그래서 ResNet에서 학습률 스케줄은 처음에는 0.1에서 시작하고 30 에폭에서 학습률을 0.01로 낮추어 학습을하고, 60에폭에는 더 크게 떨어트리고 90에폭에서는 더 떨어트리는 식으로 학습이 진행된다. 일반적으로 훈련 중 30 에폭마다 학습률을 1/10의 비율로 떨어트린다.
위의 왼쪽 그림은 학습률 감쇄 스케쥴이라고 부르는 건데, 여기서 비용 함수의 특성이 나타나는 곡선을 볼수 있다. 여기서 스텝 학습률 감쇠로 첫 30 에폭 페이스에선 상대적으로 큰 학습률을 사용해서 빠르게 진행을 하여, 큰 값으로 시작했던 초기 비용을 지수적으로 줄일수가 있었다.
하지만 30 에폭쯤에서 처음 처럼 빠르게 진행할 수가 없어, 이 30에폭 시점에서 학습률을 감쇄시켜 10으로 나눈뒤 학습을하면 다시 비용이 급격히 떨어져 지수적인 패턴이 나오기 시작한다. 또 다시 평탄한 부분이 나오면 60 에폭 쯤에서 학습률을 다시 감쇄하여 빠르게 떨어트리고 다시 평탄해지는 스케줄을 사용하였을때 이런 특성이 나타나게 된다. 이게 스탭 학습률 스캐쥴이란 방법으로 모델을 학습시킬때 볼수 있는 학습률 곡선의 특성 형태가 되겠다.
이런 스탭 학습률 스케쥴을 사용할때 문제가 있는데, 모델을 학습하는데 여러개의 하이퍼 파라미터가 필요하다. 지금까지는 우리는 어떤 규제를 할지, 지금까지 모델을 학습할때 사용했던 초기 학습율을 고를지를 고려했으나 그 뿐만이아니라 어디 쯤, 어느 에폭에서 학습률 감쇄를 할지도 골라야 한다.
그렇다보니 스텝 감쇄 스캐쥴의 경유 튜닝하는데 워낙 많은 경우의 수가 있다보니 꽤 많은 시행착오가 필요하다. 사람들이 주로 학습률 커브를 설정하는 방식은 비용이 평평한 지점을 찾도록 꽤 오랫동안 큰 학습률로 학습을 시키는 것으로 한번 다른 논문들을 살펴본다면 다들 경험적인 방법을 사용했다고 하는데 비용이 평평한 지점이 나올떄까지 혹은 검증 정확도가 평탄해질떄까지 그대로 유지시키다가 학습률을 감쇄시키며 경험적으로 감쇄 스캐줄을 할 스탭을 선정하였다.
하지만 이렇게 하는것의 문제는 다양한 감쇄 스케줄을 실험해볼 시간이 충분하지 않다는 점은데, 그래서 이 스탭 감쇄 스케쥴은 튜닝해야할 부분들이 너무 많다보니 이 사용하기 좀 까다로운 문제가 있다.
그래서 스탭 감쇄 스케줄의 단점을 극복한 다른 학습률 스캐줄 방법으로 최근 몇년간 트랜드로 사용되고 있는걸로 코사인 학습률 감쇄 스케줄이 있다. 이 방법에서는 이전 처럼 특정 반복 회차, 에폭에서 감쇄하는게 아니라 시간에 대한 함수를 사용하는데, 학습률은 모든 에폭 회차에 대한 함수로 정해집니다. 그래서 여기서 할일은 학습률을 어떻게 감쇄시킬지를 나타내는 곡선 형태의 함수가 있으면 되요.
이 중에서 가장 대표적인것으로 코사인으로 하프 코사인 학습률 스캐쥴러가 있으며 오른쪽과 같습니다. 여기서 학습률은 시간에 대한 함수로 처음에는 아주 큰 값으로 시작하고, 학습률 감쇄는 코사인파의 절반과 같은 형태로 정해지게 되요.
그래서 처음에는 학습률이 높이 시작했다가 학습이 끝날떄 쯤에 핛습률이 감쇄되서 0에 가까워 지게 됩니다. 이 ㅋ코사인 학습률 감쇄 스캐줄은 파라미터가 2개 뿐인데, 초기 학습률로 사용할 $\alpha_{0}$와 다른 하나는 학습할 에폭의 수로 T로 표기합니다.
이 코사인 학습률 스케쥴에서는 초기 학습률과 에폭 수만 필요하지, 이전에 봤던 다른 하이퍼 파라미터가 필요하지 않습니다. 그래서 코사인 스캐줄러는 이전에 본 스탭 감쇄 스캐줄러보다 다루기가 쉬우며, 일반적으로 학습을 길게 할수록 잘 동작하는 경향을 보여요.
우리가 할 일은 초기 학습률과 모델이 얼마나 오래 학습시킬지만 튜닝하면 되겠습니다. 그래서 이런 이유들 덕분에 코사인 학습률 스캐줄러가 최근 몇년간 가장 많이 사용되었다고 볼수 있겠습니다. 그리고 위 슬라이드 아래 부분에다가 최근 몇 년간 코사인 러닝 스케줄이 사용된 논문들을 짚어넣었습니다.
하지만 코사인은 시간 변화에 따른 학습률 감쇄에 사용할수 있는 수많은 형태중 하나이고, 다른 감쇄 스케줄로 사람들이 종종 쓰는걸로 단순 선형 감쇄도 있습니다. 일정한 초기 학습률로 시작해서 학습 과정을 거쳐 0까지 감쇄가 되요. 하지만 코사인 감쇄보다 이 감쇄 학습 스케쥴은 학습률을 시간에 따라 선형적으로 간단하게 감쇠를 해요.
그리고 많은 문제에서 잘 동작을 하는데, 짚고 넘어갈 점은 다른 스케줄링 기법이랑 비교해서 잘되는지에 대한 좋은 연구들이 없습니다. 그래서 코사인 학습률 스캐줄러가 좋은지 선형 학습률 스캐줄러가 좋은지 확실하게 말하기는 어렵습니다.
제 생각에 대부분의 사람들이 실제로 사용하는 방법은 사전에 있었던 연구가 어떤 타입의 스케쥴을 사용했던지 상관없이 참고해서 사용합니다. 이게 무슨 말이냐면 여러 딥러닝 분야에 따라 다른 학습률 스캐줄 방법을 사용하는 경향이 있는걸 보게 될게 되요.
=> 정리가 매끄럽지가 않은데 다시 정리하면
학습률 스캐줄러를 정하기 위해서 관련된 사전 연규에서 사용한 학습률 스캐줄러를 사용함.
그래서 특정 문제에서 비슷한 학습률 스캐줄러가 자주 사용되는 경향을 보임
하지만 한 분야, 특정 분야에서에서 그 학습률 스캐줄러가 좋아서 그렇게 사용했다고 하기보다는, 저의 생각에서는 이전 연구에서 있었던것과 비교하기 위해서 그렇게 한다고 생각됩니다.
-> 이전 연구에서 사용한 학습률 스캐줄러를 쓰는건 그 스캐줄러가 해당 분야에서 성능이 다른것 보다 좋아서라기 보다는 이전 연구와 비교하기 위함.
우리가 이전 연구를 보면서 명심해야할건 우리가 다룰 컴퓨터 비전의 문제에 따라서 어떤 경우 코사인 학습률 감쇄 스캐줄을 사용할수도 있고, 아주 큰 스캐일의 자연어 처리를 다루는 경우에는 선형 학습률 스캐줄을 사용할수도 있습니다.
이 학습률 스캐줄링은 비전이랑 자연어에 대한 근본적인것은 아니지만 서로 다른 분야의 연구자들이 연구해온 방향대로 사용하면 되겠습니다.
이번에 또 다른 학습률 스캐줄러로 역 제곱 루트 스케줄러가 있는데, 아주 큰 학습률로 시작해서 작은 학습률로 끝나게 되는데, 이 방식은 2017년에 아주 주목을 받던 논문에서 사용하던거라 추가하였습니다. 하지만 선형 감쇄 스캐줄이나 코사인 감쇄 스캐줄과 비교해서 사용되는갈 자주보지는 못했어요.
제 생각에는 역 제곱근 스캐줄러가 가지는 잠제적인 위험은 아주 높은 학습률을 사용하는 시간이 아주 짧기 때문이라고 봅니다. 여러분도 이 학습률이 아주 큰 초기값으로 시작하지만 급격히 떨어지고 대부분의 시간을 아주 낮은 학습률로 학습을 하게되는걸 볼수 있어요.
그래서 이걸 선형이나 코사인학습률 스캐줄과 비교해본다면, 다른 학습률 스캐줄러는 초기에 아주 높은 학습률이 더 오랜 시간동안 사용되는걸 볼 수 있어요.
지금까지 본 학습률 스캐줄과 다른 이번에는 실제로 아주 많이 사용되는 학습률 스케줄링 방식은 상수 스캐줄 입니다. 이건 아주 많은 문제들에서 실제로도 잘 동작을 하는데, 우리가 알다시피 그냥 초기 학습률을 지정하면 그 학습률로 전체 학습 과정에서 쭉 학습을 하는거에요.
이 방식을 다른 걸쓸 이유가 없다면 실제로 쓰는걸 추천하는데, 사람들이 딥러닝 프로젝트를 시작할때 이 학습률 스캐줄을 가지고 오랜시간 해매는걸 봤었고, 이 학습률 스캐줄을 조정해나가는게 모델을 개발하고 동작하는데 필요한 일인데, 상수 시간 학습률 스캐줄을 사용하면 꽤 좋은 결과를 얻을수 있어요.
상수 학습률 스캐줄과 다른 복잡한 스캐줄을 사용했을때 모델이 동작하느냐, 안하느냐에서 일반적으로 차이는 없고 대신 상수 스캐줄에서 복잡한 스캐줄로 바꿀때 성능이 몇 퍼센트 정도 더 좋아집니다. 그래서 어는 문제에 대한 기술을 다룰 뿐만이 아니라 목표가 해매는 일 없이 빠르게 돌려보고 있다면, 상수 시간 학습률이 꽤 좋을 수 있겠습니다.
여기서 학습률과 최적화기 사이에 대해서 더 이야기 할게 있는데, 확률적 경사하강 + 모멘텀을 사용할때 어떤 학습률 감쇄 스캐줄을 사용할 것인지가 중요할 수도 있습니다. 하지만 RMSProp나 Adam같은 복잡한 최적화기를 사용하는 경우라면 상수 시간 학습률 스캐줄만 사용해도 됩니다.(이전에 최적화에 대한 강의에서 RMSProp, Adagrad 등의 방법에서 학습률을 최적화기가 조정했던 것으로 기억)
다음 주제로 넘어가기 전에 학습률 스캐줄에 대한 질문들을 보면, 여러분들은 오랜 시간 동안 학습을 해서 비용이 쭉 내려가면 아주 좋겠죠. 여러분들이 만든 모델이 좋은 모델이니까. 그런데 비용이 갑자기 증가해버린다면 실망할겁니다. 하지만 이런 일이 있을때 일반화시켜서 말하기가 힘드는데, 잘못 동작하도록 해서 이런 문제가 생기는 원인이 많으니까요.
한가지 경우는 중간에 그라디언트가 0이 되는 경우가 있어서 그럴수도 있는데, 이 문제가 아니라 그라디언트가 여러번 반복하는과정에서 너무 누적되서 급격히 커지는 경우가 생기면 학습이 잘못 될겁니다. 또, 우리가 다루는 문제의 타입에 따라 잘못된 학습 과정으로도 이런 문제가 생길수도 있구요. 다른 종류의 생성모델이나 다른 종류의 강화학습 문제를 다루다가 학습 커브가 잘못되는걸 볼 수도 있겠습니다.
우리가 잘 정리된 분류 문제를 다룬다고 해도, 일정 기간 학습을 한 후에 비용이 급격히 커지는 일이 생긴다면, 나쁜 하이퍼 파라미터를 써서 버그가 생긴걸 수도 있고, 데이터가 로드 되는 과정에서 버그가 생겼거나, 훼손된 데이터를 가지고 학습을 시켜서 생깃 것으로 추정할 수도 있겠습니다.
그리고 우리가 가진 데이터셋에 한 샘플이 잘못된 경우도 문제의 원인이 될수도 있고, 다른 문제가 생길수 있는 경우로 여러분들이 Flickr를 알고 있으면 사용자들이 Flickr나 다른 사진 공유 사이트에 올릴수 있을거에요. 그리고 후에 이 사진들을 삭제를 할수도 있겟죠.
Flickr 이미지 배포 링크로 실제 JPEG이미지들을 모아 데이터셋을 만들수도 있는데, 그 중간에 이미 삭제된 이미지를 다운로드 하려고 할수도 있을거에요. 그래서 실제 이미지가 아닌 손상된 JPEG 파일/실제 내용은 없고 텅빈 이미지 파일을 다운받을 수도 있고, 훈련하는 과정에서 사용하면 그 이미지는 라벨은 가지고 있으나 0인 데이터가 될수도 있어 비용을 급격하게 증가시킬수도 있겠습니다.
그래서 여러분이 이런 손상된 이미지들을 포함한 미니패치를 가지고 학습을 하려고해서 갑자기 이런 문제를 발생시킬수도 있어요. 그래서 일반화 시켜서 대답하기는 힘들고 여러분들의 문제가 뭐가 원인인지 깊게 들여다봐야 합니다.
다음 질문은 적응적 학습률에 관한 것으로 Adadgrad나 RMSprop 혹은 다른 적응적 학습률 방법이 있는데, 이들도 문제를 발생시킬수도 있지만 이 방법들은 더 강인하게 만들어지다보니 그래도 최적화 문제에서 계속 사용해도 되갰습니다.
*이후 몇가지 질문에 대해서 더 얘기하지만 학습률 스캐줄에 관해서는 여기까지..
훈련을 얼마나 지속시킬지 결정하는데 도움되는 것으로 빠른 중지early stopping이라고 하는 개념이 있습니다. 이전에 신경망을 학습하면서 주로 세가지 커브를 보았는데, 하나는 좌측의 비용에 대한 그래프로 정상적으로 동작하면 지수적으로 감쇄되는걸 볼수 있어요. 그리고 꼭 봐야하는것으로 신경망의 훈련 정확도인데, 매 애폭마다 채크를 해줘야하고, 훈련셋에 대한 정확도 뿐만이 아니라 검증셋에 대한 정확도도 확인해주어야 합니다.
이 곡선들을 보면서 만든 신경망이 학습 과정에서 정상적으로 동작하는지 알수 있어요. 일반적으로 우리가 할수 있는건 검증 정확도가 가장 높은 지점에서 학습을 중지시킬수가 있겠습니다. 그리고 그리고 그 지점을 최대 반복 회수 최대 에폭으로 지정해서 훈련을 할수 있을것이고, 매 애폭마다 배치단위들을 학습할수가 있겠습니다.
하지만 모든 에폭 혹은 모든 5에폭 단위 혹은 10 에폭씩 훈련셋과 검증셋 정확도를 확인해야하고, 각 지점에서 모델 파라미터들을 저장을 해두어야 합니다. 모델이 핛브을 마친 후에 이러한 곡선들을 그릴 수 있고, 가장 검증셋의 성능이 좋은 시점에서의 지점을 고르면 되겠습니다. 그 체크포인트에서의 모델을 실제로 사용하겠습니다.
이런 식으로 모델을 돌리는 중간에 훈련 과정에서 비용이 뒤에 갑자기 증가하는 경우도 생기는데, 이건 큰 문제가 되지 않고, 그냥 커브를 보고 갑자기 증가하기 이전에 있는 것들 중에서 가장 적합한 체크포인트의 모델을 사용하면 되겠습니다.
이 방법은 신경망을 어떻게 학습시킬지 어디까지 학습시킬지 고르는데 매우 유용한 경험적인 방법이라고 할 수 있겠습니다. 그리고 이걸 신경망을 학습할떄시킬떄마다 사용하라고 추천드리고 싶습니다.
michigan online justin johnson 교수님의 deep learning for computer vison 강의
lecture 10 : training neural network 1 나머지 내용들
그래서 지금까지 모델을 훈련하는 다양한 방법들에 대해서 얘기를 했다. 활성화 함수를 보고, 초기화에 대해서도 예기를 했는데, 우리가 모델을 잘 만들더라도 학습하는 과정에서 오버 피팅이 심해지는걸 볼수도 있다.
처음에는 테스트셋이 훈련 셋보다 성능이 더 좋게 나올수도 있지만 시간이 지나면서 나빠질수가 있는데, 이 문제를 해결하기 위해서 규제 regularization라는 방법을 사용한다.
보통 규제를 하기위해서는 비용함수에다가 규제 항을 추가시키는 방법이 자주 사용되고 있는데, 이 강의의 과제에서 전에 L2 규제를 사용했던 적이 있었다. 이 L2 규제를 가중치 감쇄 weight decay라고도 부르며 가중치 행렬의 놈 norm을 패널티로 사용하는 방법이다.
이렇게 규제항을 사용하는 방법이 심층 신경망에서 널리 사용되고 있으나 이 외에도 사람들이 딥러닝에서 자주사용하는 규제 기법으로 드롭 아웃 drop out이 있다. 이 드롭아웃의 아이디어는 신경망이 순방향으로 진행하는 과정에서 임의로 일부 뉴런을 0으로 지정해서 계산을 해나가는 방법이다.
그래서 순전파 방향으로 각 계층들을 계산하는 과정에서 임의의 뉴런들이 0으로 만들고 계산하고, 다른 계층에서는 다른 임의의 뉴런들을 0으로 해서 계산하고, 이런 식으로 순방향으로 나간다. 여기서 뉴런을 드롭 아웃 시킬 확률은 하이퍼파라미터로 일반적인 경우 0.5로 지정한다.
하지만 1/2로 하는건 코인 던지기 같은 확률로 뉴런을 살릴까 말까 결정하다보니 어의없을수도 있지만, 구현하기가 쉽다. 이 예시는 2층 완전 연결 신경망을 드롭아웃 기법과 사용해서 구현한건데 보다시피 아주 간단하게 구현할수 있다.
그냥 각 계층에서 연산을 마친 뒤에 이 이진 마스크 bianry mask를 곱하기만 하면 되겠다. 여기서 U1, U2가 이진 마스크 역활을 하고 있는데, U1가 생성한 난수가 [0.3, 0.6, 0.7]인 경우 여기다가 < p 연산을 하면 [0, 1, 1]가 U1이 된다. 이 U1을 완전 연결 계산 결과(입력과 가중치 행렬의 곱 결과)와 곱함으로서 이진 마스크 역활을 하며 드롭아웃 기법을 구현한게 되겠다.
드롭아웃은 신경망이 중복된 표현들을 학습해서 가지는걸 방지한다. 이걸 다시 말하자면 특징의 공적응 = 상호 적응 co-adaptation을 방지한다고 할수 있는데, 물체를 강인하게 인식할수 있도록 다양한 표현 벡터들을 신경망이 학습하게 만든다고 할수 있다.
한번 예를들면 고양이 분류기를 만들때, 나쁜 일이지만 벡터의 각 원소가 독립적으로 고양이 인지 아닌지를 학습할수도 있다.
하지만 드롭아웃을 추가한다면, 우리가 더 강인한 표현들을 학습 하길 원한다고 할때, 어떤 뉴런은 귀를 학습하고, 어떤건 털을 학습하고, 어떤 건 고양이의 고차원적인 특징 같은것들을 배워야 할것이고,
이런 뉴런들을 드롭 아웃으로 절반을 제거시키면서 학습을하면 고양이에 대한 표현식이 어지르더라도(위 특징들), 일부 특징 만으로도 강인하게 고양이를 인식 할수 있게 되겠다.
* 원문을 직역하면 이상하고, 의역해도 이상해서 어떻게든 고쳐봤는데 이 의미가 맞는지는 모르겠다.
=> 아무튼 이부분을 다시 정리하면
드롭 아웃 : 특징의 상호 적응 방지
드롭 아웃은 신경망이 비슷한 특징, 중복된 특징이 되도록 하는걸 방지하고, 이걸 다른 말로 공적응을 서로 비슷해지는것을 방지한다고 말한다. 하지만 드롭 아웃은 특징들이 서로 비슷해지는걸 막다보니 다양한 표현들, 벡터들을 학습해서 물체를 더 강인하게 인식할수 있게 된다고 하는것 같다.
고양이 분류기의 예를 들자면 벡터의 한 원소만 가지고 독립적으로 고양이 인지 아닌지를 구분하도록 한다면, 내 생각에는 아주 일부 특징 한가지만 가지고 고양이로 판정을 내리려 한다면 잘못된 예측을 할수 있어 좋지 않다는 말인것같다.
하지만 드롭 아웃을 추가 한 경우, 신경망이 임의로 뉴련들이 제거되다보니 신경망이 다양한 표현식들을 학습을해서 어떤 뉴런은 귀를, 어떤것들은 털을, 어떤것들을 고양이에 대한 고차원 특징들을 학습하게 되고,
이렇게 뉴런들을 드롭 아웃으로 절반씩이나 제거하면서 학습한 덕분에, 어질러진 표현식이라도 다양한 특징들이 모이다보니 강인하게 고양이를 인식할수 있다. 라는 말로 정리할수 있을것같다.
아우 진짜힘들어..
드롭 아웃에 대해서 다른 방식으로 이해한다면, 이 드랍아웃 기법은 모든 가중치를 공유하는 신경망들의 앙상블을 효율적으로 학습시키는 방법이라고 볼수 있겠다.
왜냐면 각 계층에서 뉴런들을 마스킹으로 없애면서 하나의 새로운 신경망을 만들었다고 볼수도 있는데, 원본 신경망으로 부터 다양한 하부 신경망을 각 순전파 때마다 만들고, 우린 하부 신경망 하나하나를 학습해 나간다.
그 결과 가중치가 공유되는 지수적으로 아주 많은 하부 신경망들을 학습을 하다보니, 전체 신경망은 수 많은 하부 신경망의 앙상블 모델이라 할수 있겠다.
아무튼 드롭아웃에 관한 자세한 사항은 논문을 확인해서 어떻게 동작하는지 보면 될거고
* 이부분을 정리할때 테스트 시간이 랜덤성을 바꾼다는 말인지, 드롭 아웃이 테스트에 걸리는 시간을 바꾸는지 이해가 되질않는다. 이후 내용을 계속 보다보니 테스트 시간에, 테스트 떄마다 랜덤하게 동작 되는걸로 다시정리했다.
드롭 아웃이 가지고 있는 문제는 테스트 시간에 신경망이 무작위로 동작한다는 점인데, 순전파 순간 순간 마다 각 계층의 뉴런 절반을 임의로 제거하기 때문이며, 실제로 드롭 아웃을 적용한 신경망을 사용할때 일관된(deterministic을 결정이 아니라 일관으로 해석) 결과가 나와야하지만 그렇지 못하게 된다.
한 웹서비스에다가 사진을 업로드 해서 고양이라고 인지되었다가 다음날 다른걸로 인지되는 경우가 생길수가 있어서 드롭 아웃을 사용한 신경망은 결과가 바뀔수 있는 문제를 가지고 있다.
그래서 신경망을 사용할때 결과가 일관되게 나오게 만들기 위해서는 랜덤한 결과들의 평균을 취하면 되겠다. 그렇게 하려면 신경망에 대한 수식을 고치면 되는데, 입력을 실제 입력 이미지 X와 랜덤 마스크 z 두개를 주자. 여기서 z는 랜덤 변수로 신경망을 순전파시키기전에 구한 표본이라 하자.
그러면 신경망 출력 결과는 입력 데이터와 랜덤 변수에 따라 결정 될거고, 신경망이 일관된 결과를 출력되도록 할 일은 테스트 시간때 랜덤 변수를 평균을 취해주면 되겠다. 이걸 하기위한 방법은 랜덤 변수 z에 대한 기대값을 구하면 되겠다.
그래서 이거를 해석적으로 계산을 한다면, 수식을 통해 계산을 한다면 확률 변수 z에 대해서 적분으로 주변화해서 계산하면 되겠지만 신경망의 크기를 생각하면 이걸 해석적으로 해낼수 있는 방법이 없다.
그래서 이 적분 대신에 할수 있는 방법은 연결 강도 w1, w2를 가지는 뉴런 하나에다가 두 입력 x, y를 주고, 스칼라 출력a를 구한다고 할께요.
테스트를 할때는 가중치 행렬과 두 입력의 내적을 한다고 하고
훈련 과정에 드롭아웃을 사용해서 4가지 경우의 랜덤 마스크(모든 경우의 확률은 1/4로 같다)가 있다고 하자. 이렇게 해서 x, y 둘다 살리거나 x만 살리는 경우 y만 살리는 경우, 둘다 죽는 경우를 구할수가 있겠다.
이런 4가지 경우의 수가 나올수 있는 이유는 x가 살수있는 확률이 1/2, y가 살수 있는 확률도 1/2로 같기 때문이다. 이 예시로 구한 출력은 순전파 출력에다가 1/2한것과 같아지겠다.
이걸 일반화해서 본다면, 드롭아웃을 적용한 한 계층의 기대값은 기존의 출력에다가 드롭아웃의 확률을 곱해서 구할수 있는것을 알수 있겠다.
그래서 우리가 원하는건 테스트 때도 훈련 시간때 기대한 출력이 나온것과 동일한 결과가 나오는 것인데, 위 정리를 통해서 얻을 수 있다. 다시 말하면 테스트 때는 모든 뉴런들이 활성화 되어있고, 모든 뉴런들이 가중치를 가지고 동작을 할하게 된다. 그리고 각 계층의 출력을 드롭아웃 확률을 이용해서 리스캐일링을 시키면 된다.
이 내용들은 드롭 아웃 구현 정리인데, 순전파 과정에서 드롭아웃을 구현해서 랜덤 마스크를 생성하고 일부 뉴런들을 무작위로 0으로 만드는걸 볼수가 있겠다.
그리고 테스트 시간에는 드롭아웃때 사용한 확률을 곱함으로서 출력을 리스케일을 시키면 각 층에서의 출력이 기대값이 되어 무작위성에 의한 영향이 더 이상 존재하지 않게 된다.
이렇게 기대값을 계산하는 방법은 각 드롭아웃 계층을 여러게 쌓아가면서 만든 상황에서 사실 정확하다고는 할수는 없다. 하지만 실제로 사용할때는 적당히 잘 동작한다고 볼 수 있겠다.
여기서 짚고 넘어갈만한 흔하게 드롭아웃을 구현하는 방법은 역 드롭아웃 inverted dropout이라 부르는 방법인데, 기본적인 틀은 같지만 약간 다르게 구현이 되어있다. 차이점은 리스케일링을 테스트때 하느냐 훈련중에 하느냐일 차이 뿐이라, 실제 사용할 시스템의 효율성을 높일 수 있도록 우리가 테스트 때 리스케일링을 하기 싫다면 이렇게 쓰면 된다.
왜냐면 모바일 장치나 서버같은 곳에서 많은 양의 이미지를 다룰 수도 있고, 훈련 과정에서 비용을 더 쓰고 싶다면 이 방법을 사용하면 되겠다. 이 방법은 실제로 자주 사용되고 있는데 훈련 과정에서 랜덤 마스크를 생성해서 드롭아웃하고, 뉴런들을 확률로 나눠주면, 테스트 타임때는 그냥 모든 뉴런을 가지고 평소 하던데로 계산만 하면 되겠다.
질문이 들어왔는데, 드롭아웃 계층은 신경망 아키텍처의 어디에 넣어야 할까?
일단 이전에 봣던 AlexNet과 VGG 아키텍처의 경우를 떠올려보면 아주 많은 량의 학습 파라미터가 있었고, 이런 것들은 신경망의 맨 끝에 위치한 완전 연결 계층에 위치하고 있었다. 그 부분이 드롭아웃을 주로 넣어야할 위치이며, 이런 합성곱 신경망의 맨 끝에 위치한 아주 커다란 완전 연결 계층에 주로 드롭 아웃 계층을 넣는다.
하지만 ResNet이나 GoogleNet같이 큰 완전 연결 계층이 없는 최신 신경망 구조 같은 경우에는 드롭아웃기법을 사용하지 않는다. 하지만 2014년까지 혹은 초반까지만 해도, AlexNet이나 VGG 같은 모델이 오버피팅하는걸 크게 줄이는데 도움 됬으며 신경망이 잘 동작하는데 있어서 필수적인 기법이었었다.
드롭 아웃은 좀더 현대적인 아키텍처들 ResNet 같은 것들이 나오면서 덜 중요해 졌지만, 신경망에서 자주 사용되는 다른 형태의 규제 기법이라고 할수 있겠다.
지금까지 드롭아웃에 대해서 보면서 봤던 개념들은 많은 신경망 규제 방법에서 사용되는 흔한 패턴이다. 기본적으로 훈련하는 동안 시스템에 다른 랜덤한 정보에 영향을 받도록 랜덤성을 추가시키고, 테스트때는 일관된 결과를 얻을 수 있도록 랜덤성에 대해 평균을 구하였다. 드롭아웃의 경우 랜덤 마스크로 랜덤성을 추가시킨거라 볼 수 있겠다.
하지만 이 외에도 지금까지 다른 타입의 수 많은 규제들을 봤었는데, 우리가 이미 본 다른 규제 방법중 하나로 배치 정규화가 있다. 왜냐면 배치정규화가 훈련 과정에서 랜덤성을 추가했었는데, 출력이 임의로 만들어진 미니 배치로 만들어지기 때문이며,
미니배치에서 평균과 표준 편차를 계산하고 사용을 했었는데, 이 미니배치가 훈련 중 반복 때마다 어떻게 혼합되어 들어가 있는지에 따라 변할수 있고 계산 결과도 달라지기 때문이다. 또 배치 정규화에서는 훈련 중 어떻게 배치를 만들지 가중을 줌으로서 랜덤성을 추가할수도있다.
그러고 나서 테스트 중에는 드롭 아웃에서 출력에 확률을 곱하여 기대값, 랜덤하게 나온 결과들의 평균을 구하는 것과는 달리, 전체 평균들과 표준 편차들의 평균을 사용한다.
이후에 다룰 ResNet이나 다른 현대적인 신경망 아키텍처에서 드롭 아웃 대신 배치 정규화가 주로 규제 용도로 사용되고 있다. 추가적으로 ResNet에서는 L1, L2 가중 감쇄와 배치 정규화가 훈련 과정에서 주로 사용되고 있으며, 아주 큰 심층 신경망에서도 잘 동작한다.
여기서 (교수님이) 잘못 말한 부분이 있는데, 실제로 랜덤성을 추가시키는 다른 하는 방법 있다고 말 하였지만. 다른 사람들은 규제라고 보지 않는 방법이 있습니다.
-> 교수님은 규제라고 생각하지만 남들은 규제라고 보지 않는다? 라는 말로 보임.
여기서 말하고자 하는 방법은 데이터 증강 data augmentation으로 지금까지 수업에서 데이터를 읽고 반복해서 훈련하는것에 대해서 이야기 해 왔는데, 항상 훈련 데이터를 로드 할때 고양이 사진과 고양이 라는 라벨을 훈련 데이터라고 해 왔습니다.
이 이미지는 신경망 전체를 지나가서 예측한 라벨과 실제 라벨이 맞는지 비교하고, 비용이 줄어드는 방향으로 그라디언트를 계산하는데 사용됩니다.
하지만 현실에서 자주 사용되는 방법으로 이 데이터 샘플을 변환시킬수가 있는데, 신경망에다가 입력으로 주기 전에 해당 샘플의 라벨은 나두고 입력 이미지를 무작위로 변환해서 사용할 수가 있습니다.
예를 들어 수평 방향으로 뒤집은 이미지를 만들수도 있겠는데, 이미지를 수평 방향으로 뒤집더라고 고양이인걸 알수 있죠.
다른 흔하게 사용하는 방법은 모든 훈련 과정에서 임의로 자른다거나 크기를 조정시키는것으로 이미지를 임의의 크기로 줄이거나 이미지 일부분을 잘라낼 수가 있겠습니다. 왜냐면 고양이 이미지 일부를 잘라내더라도 여전히 고양이로 인식할 수 있으니까요.
이 아이디어들은 효과적으로 훈련 데이터셋을 늘리는 방법이라고 할수 있어요. 훈련 데이터를 변환시켜 늘렸고, 훈련 라벨을 바뀌지 않았죠. 그래서 이건 비용을 들이지 않고 신경망에 더 많은 입력 이미지를 학습시킬수 있도록 훈련 데이터셋을 배로 늘렸다고 할수 있을거에요.
이건 다시 훈련 시간때 랜덤성을 추가시킨건데 이 예시에서 랜덤하게 자르고, 뒤집고, 스캐일링하고 있는데, ResNet 같은 신경망은 매 반복때마다 모든 훈련 이미지를 랜덤 사이즈로 조정하고, 임의 224 x 224 사이즈 이미지를 잘라낸 걸로 학습을 하게 되요. 매 반복 과정마다 각 이미지들을 랜덤하게 자르고, 크기조정하고, 뒤집는다고 할수 있겠죠.
또 다른 랜덤성을 더하는 방법으로, 테스트 때 랜덤성에다가 주변화 개념을 적용시켜볼수도 있겠습니다. 데이터 증강을 위해서 몇 고정된 이미지 일부 crop의 집합을 가지고 크기조정된 것들의 집합을 가지고 테스트 평가시에 사용할 수도 있다.
ResNet 논문에서는 5가지 서로 다른 이미지 스케일이 있었는데, 각 스케일로 5가지 이미지 크롭을 뽑았고, 원점을 중심으로 수평뒤집은 것으로 총 10개의 이미지를 사용하여 평가를 하였습니다. 또 다른 크롭들을 가지고 여러차례 동작시킨후에 모든 예측 결과의 평균을 구하였는데, 이러하 방식으로 훈련중에 랜덤성을 더하고, 테스트 중에 랜덤성의 평균을 구할수가 있었습니다.
또 다른 사람들이 사용하는 기법으로 임의로 색상에 지터링을 주는건데, (자세한 설명은 없이 넘어간다) 슬라이드에 따르면 임의로 밝기랑 명암을 조정하는 방법인가 보다.
이 아이디어들이 크리에이티브하게 생각해낼수 있는 다른 타입의 데이터 증강 방법들이 있지만 어떤 증강방법을 사용할지는 풀고자 하는 문제에 달려있다. 예를들어 오른손인지 왼손인지 알려주는 분류기를 만드는데, 수평 뒤집기는 좋은 데이터 증강 방법이라 할수 없겠지만 고양이와 강아지를 분류해야하는 경우 수평 뒤집기는 괜찬은 방법이 되겠다.
아니면 의학 이미지를 다루는 상황에서 막 인지 세포인지 인지해야하는 경우 임의 회전을 시키는게 좋은 방법이 되겠다. 그래서 데이터 증강을 할때는 사람의 전문 지식을 활용해서 훈련 할 시스템에 어떤 변환을 해서 라벨에 영향을 안주고 증강을 할수 있는지 판단하여야 한다.
지금까지 훈련때는 랜덤성을 추가하고 테스트 때는 주변화, 평균을 구하는 규제에서 흔히 사용되는 패턴들을 보았다. 이런 패턴을 보이는 나머지 예시들이 있긴한데 필요할때 자세히 보면 되겠다.
이 방법은 드롭 커낵트라고 부르는것으로 드롭아웃이랑 비슷한데 드롭아웃에서 활성 결과를 0으로 만들던것과는 달리 이건 매 순전파때마다 랜덤하게 가중치를 0으로 만드는것을 말한다. 그리고 테스트때 유연하게 평균을 해서 일관된 결과를 얻을수가 있겠다.
다른 방법으로 프랙탈 맥스 풀링이라고 부르는 방법이 있는데 풀링할 수용장 영역의 크기를 랜덤하게 구하는 방법으로 어떤 영역은 2 x 2 풀링 영역을 가질수 있고, 어떤 뉴론들은 1 x 1 풀링 영역을 가질수도 있을거고 이게 매 순전파때마다 일어난다. 이게 프랙탈 맥스 풀링이라 부르는 이유는 1 x 1 수용장이냐 2 x 2 수용장이냐를 선택하는 사이에 랜덤성이 1.35의 풀링 기대값을 가지고 있기 때문이다(?)
다른 아주 특이한 방법으로 확률적인 깊이를 가지는 심층 신경망을 만드는 방법이 되겠다. ResNet처럼 100층 넘어가는 신경망을 만드는데, 훈련 중 순전파때 다른 잔류 블록들을 사용하고, 테스트떄는 모든 블록을 사용한다.
우린 드롭 아웃을 봤었는데, 그 때는 각 뉴런들의 값을 없앴고, 또 드롭 커낵션의 경우 개별적인 가중치 값을 제거했었다. 이건 드롭 블록이라고 할수 있는 방법으로, 이 심층 잔차 신경망 아키텍처에서 블록들을 제거해 나가겠다.
이번에 볼 방법은 주로 컷아웃 cutout이라고 부르는 방법인데, 여기서는 간단하게 훈련과정에서 매 순전파때마다 입력 이미지의 일부 영역들을 0으로 설정한다. 그리고 테스트 떄는 전체 이미지를 사용한다. 이런 랜덤성을 사용하는 훈련떄 신경망을 망치는 랜덤성이 존재한다.
이번에 볼 방법은 (교수님도 왜 동작하는지 모르겟다고 말하는..) 믹스업 mixup 방법인데, 입력 이미지들을 임의의 비율로 섞는것으로 고양이 이미지와 강아지 이미지 샘플을 임의의 비율로 섞었는데, 예측 결과가 고양이는 0.4, 강아지는 0.6으로 실제 섞은 비율과 동일한 결과가나왔다.
이 방법이 잘 동작은 하지만 어쩌면 합리적인 방법일수도 있는게 여기서 섞은 비율이 베타 분포를 따르고 있는데, 이 경우 섞은 비율은 고양이가 0.4, 강아지가 0.6이 아니라 0에 아주 가깝거나 1에 아주 가까운 식으로 되야한다. 그러면 고양이는 0.95, 강아지는 0.05 될것 같지만 실제로는 그렇지가 않다.
지금까지 본 내용들을 보면서 실제로 어떤 방법을 사용할지가 중요한데, 일단 우리가 아주아주 큰 완전 연결 계층을 가진 신경망 아키텍처를 만난다면 드롭 아웃을 쓰면 된다. 하지만 요즘은 잘 사용되지는 않고, 주로 배치 정규화나 L2 가중치 감쇄 그리고 데이터 증강 같은것들이 오늘날 신경망 규제에 사용되고 있다.
그리고 놀랍게도 컷아웃과 믹스업이 CIFAR10같이 작은 데이터셋에서 유용하게 사용되고 있다. 하지만 이미지넷같이 큰 데이터넷의 경우 드롭아웃이나 컷아웃, 믹스업 같은 방법은 그렇게 잘 사용되지는 않는다.
위의 예시에서는 가중치 행렬을 정규 분포로 초기화를 시키고 0.01을 곱하여 표준 편차를 줄여주고 있ㄴ느데
이런 가우시안 분포로 가중치 행렬을 할때에는 평균이 0으로 지정하나, 표준 편차의 경우 위의 0.01과 같이 하이퍼 파라미터로 설정 할 수 있다.
그래서 이렇게 작은 임의의 가우시안 분포를 따르는 값으로 초기화하는 경우는 얕은 신경망에서 잘 동작하지만 깊어질수록 잘 동작하지 않는 문제가 있다고 한다. 왜 그런지 활성화 함수에 관한 통계량을 보면서 알아보자.
어떻게 진행되는지 일단 이 코드 스니팻/코드 조각을 보면서 어떻게 계산되는지 6층 신경망이 순방향으로 가면서, 은닉층의 크기는 4096개라고 하면
-> 일단 이 코드 스니팻/조각을 보면서 어떻게 활성 통계량들이 전파되는과정에서 계산되는지 은닉층의 유닛이 409개인 6층 완전 연결 신경망의 예시로 한번 보자.
* 이렇게 긴덩어리는 풀기 너무 힘들다.
그래서 여기서는 tanh를 활성화 함수로 쓸건데, 그 이유는 얼마전 슬라이드에 봤었던 어드바이스들을 안따랏을때 어떻게 되는지 보려고한다.(tanh를 사용한 경우 입력이 x가 -inf, +inf에 가까워질수록 y는 각각 -1, +1에 가까워졌으며 그라디언트 소멸이 발생함)
순방향으로 처리하고, 각 계층들의 은닉층 값 그러니까 다음층의 입력에서 사용되는 값(이전 계층에서 활성화 함수의 출력)의 히스토그램을 보여주고 있다.
일단 여기서 가중치 행렬을 곱하고, tanh를 적용한 결과로 여기서 보면 값들이 어떤 분포 형태를 따르는걸 볼 수 있다. 하지만 신경망이 깊게 들어가면 들어갈수록 활성화 함수가 모든 출력들을 0에 가까운 수가 나오도록하게 만든다.
그래서 이렇게 되면 모든 활성화 함수의 출력에 0이 가까워지고, 그라디언트도 근사적으로 0에 가까워지기 지다보니 결국 역전파를 계산하기 힘들어져 좋다고 할 수 없다.
첫번째 계층 행의 경우 tanh를 통과하다보니 모든 값들이 -1과 1 범위 사이안에 존재하게 되었고, 이게 처음으로 통과하다보니 히스토그램의 값이 고르게 분포가 되어있다.
하지만 두번째 계층의 경우 다시 tanh를 거쳐 출력하는 만큼 1층보다 -1 혹은 1에 가까워질 경우의수 빈도가 줄어들다보니 첫번째 계층의 은닉층 값 만큼 고르게 분포되어 있지 않다.
세 번째 층, 넷, 다섯, 여섯 번째 층까지 순전파가 진행되는 과정에 tanh라는 활성화 함수로 인해 대부분의 출력 값들이 0에 가깞게 분포하게 되어 처음 표준 편차가 0.49이던것에서 0.05로 줄어들었다.
그래서 이 신경망은 활성정도가 0에 가까워지면서 그라디언트의 갱신치도 0에 가까워지고 효율적으로 학습을 할 수 없게 되는게 이렇게 가중치 초기화시키는 경우의 문제라고 할 수 있겠다.
잠깐 여기서 말이 햇갈리는게 tanh의 입력이 -inf, inf에 가까운경우 그라디언트가 0에 가까워지는건 이해가 되는데 왜 활성 정도가 0으로 되면 그라디언트가 0에 가까워진다는건지 이해가 되지않는다.
그냥 내 생각에는 가중치 갱신치를 계산하는데 입력 그러니까 이전 은닉층의 활성 정도가 0에 가까우니 가뜩이나 작은 가중치 갱신치가 매우 작아져 학습이 제대로 되지 않는다고 생각된다.
그래서 표준 편차를 0.01로 아주 작게 해서 가중치를 초기화하는 바람에 이런 문제가 생겼고 대신에 0.05로 초기화 하는 경우를 한번 보면,
이번에는 가중치 행렬이 너무 커져지다보니 tanh 비선형 활성화 함수의 포화 영역으로 입력값들을 밀어 넣게 된다. 그래서 히스토그램을 보면 이렇게 큰 값으로 가중치 행렬을 초기화 시킨 결과 대부분 tanh 함수의 출력 값들이 포화영역에 위치한걸 볼수 있다.
그래서 이렇기 때문에 로컬 그라디언트는 0이 되고 학습이 제대로 되지않는다. 그래서 지금까지 가중치를 너무 작게 설정했을때 그라디언트에 0에 가까워지던 경우랑 가중치를 너무 크게 설정하여 활성 정도가 포화 영역에 빠져버리던걸 봤었다.
그래서 우리는 가중치를 너무 작지도 않고, 크지도 않지만 좋은 성능을 보이는 골디락스 존을 찾아서 초기화 시켜야 한다. 위 슬라이드의 아래에 인용된 논문에서는 표준 편차를 하이퍼 파라미터로 사용하지 않고, 표준편차를 1/sqrt(Din)으로 사용하여 가중치 행렬을 초기화 시키는 방법을 자비에 초기화 Xaiver Initialization이라고 정의 하였다.
그래서 이런 골디락스 영역으로 가중치를 초기화 시킨경우 활성 히스토그램이 아주 좋게 조정된 분포 scaled distribution로 나오게 되며 더 이상 신경망 깊이이 깊어지면서 가중치가 사라지는 문제가 줄어들었다.
그리고 완전 연결 신경망 뿐만이 아니라 합성곱 계층 경우에도 잘 동작한다. 이런 자비에 초기화 방법은 출력의 부산이 입력의 분산과 동일하게 해주는 방법이라고 할수 있겠다. 이후 내용은 정의에 관한 건데 정리 하기 힘들고 일단 이 부분에서 자비에 초기화가 입력의 분산과 출력의 분산이 같게 만들어주는 초기화 기법인지에 대한 증명 과정 같은거라 넘어가겠다.
하지만 문제는 활성화 함수로 ReLU를 사용하는 경우인데 (생략한) 정리 내용은 랠루 같은 힌지 비선형 함수를 고려한게 아니라 문제가 된다.
제가 지금까지 예시에서 tanh를 사용한 이유는 이 함수로 선형 연산 계층에 대해서만 이야기했기 때문이며, 이런 선형 함수에서 tanh처럼 0 주위로 대칭이 되는 비선형 함수를 사용할 수도 있기 때문이다.
선형 계층들의 분산들이 tanh를 사용했을때 일치되어/다 비슷비슷 해져서 괜찬지만, ReLU를 사용하는 경우에는 같은 방식으로 초기화 하면 문제가 생긴다.
위 그림을 보면 ReLU를 활성화 함수로 사용한 경우를 볼수 있는데 활성 통계량이 망가져서 히스토그램이 이상하게 만들어지는걸 볼수 있다. 이 이유는 ReLU가 x = 0을 기준으로 힌지 형태이기 때문이며 ReLU가 0이하의 모든 값들을 제거하기 때문이다.
이번에는 히스토그램의 0이 아닌 부분을 위주로 보면 심층으로 갈수록, 활성 정도가 0에 가까워지는걸 볼 수 있고 로컬 그라디언트가 0이되어 학습하기 어려워지게된다.
이런 문제가 있다보니 ReLU 활성화 함수에 적합한 다른 초기화 방법이 필요한데, 이 문제를 고치려면 2로 표준 편차를 나눈걸 곱해주면 된다.
자비에 초기화에서는 sqrt(1/Din)을 표준편차로 사용했었지만, ReLU 함수의 경우 sqrt(2/Din)을 표준편차로 사용하면 된다. 여기서 2인건 ReLU가 입력의 절반을 죽이던거에 대처하기 위함이며이런 초기화 방법을 초기에 나왔을때는 Kalming 초기화 혹은 논문 저자가 마이크로소프트 아시아 연구팀에 있었다보니 MSRA 초기화라고도 부르고 있다.
그래서 우리가 이런 비선형 함수를 초기화를 할때 MSRA 초기화 방법이 필요할 수도 있을거고, 써보면 잘 동작하는걸 볼수 있다고 한다. 그리고 지난 시간에 VGG 모델에 대해서 이야기 했었는데, 그 아키텍처가 만들어진 2014년 당시에는 아직 배치 정규화가 없다보니 괴상한 트릭을 사용하지 않고서는 VGG를 수렴시킬수가 없었다.
하지만 이 Kalming 초기화 기법 덕분에 VGG는 초기화 방법만 간단하게 바꿈으로서 학습을 할수 있어졌고, 크게 유명한모델이 될 수 있었습니다.
하지만 기억해야할 건 VGG에 대한 경우이고, 지난 시간에 표준 베이스라인 아키텍처로 ResNet을 사용해야한다고했었습니다. 이 모델에서는 MSAR, Kalming 초기화 방법은 ResNet에 좋은 방법은 아니에요.
그래서 ResNet을 사용한다고 가정할때, 출력의 분포와 입력의 분포를 동일하게 만들어주는 여기에 맞는 합성곱 계층들의 초기화 방법을 만들어야 하는데요.
이 신경망에서 Residual connection, 스킵 커낵션을 사용하다보니, 스킵 커낵션 이후로는 입력을 다시 더해보리기 때문에 출력의 분산어 더 커지게 될겁니다.
그래서 여기서 MSRA이나 자비에 초기화를 잔류 신경망에다가 사용한다면 활성의 분산은 여러 계층을 거치면 거칠수록 계속 커지다보니 폭발하게 될거고, 최적화 과정에 있어서 좋은 방법은 아니에요.
그래서 ResNet에서 사용할수 있는 해결 방안으로는 Residual Block 잔류 블록의 첫번째 계층은 MSRA로 초기화 시키고, 두번째 계층은 0으로 초기화 시키면 되겠습니다. 그렇게 하면 이 블록은 분산을 완전히 보존하면서도 항등함수처럼 동작할수 있거든요. 이 기법은 ResNet을 초기화 하는데 자주 사용되고 있어요.
-> 이 부분에서 이해가 안되점은 두번째 합성곱 계층의 가중치를 0으로 초기화를 시킨다면 이전 계층에서 뭐가 들어오던간에 활성화 함수의 입력이 0이 된다는 얘기라. 위 그림의 2번째 합성곱 계층 뒤에 입력 x를 더하면 그대로 x가 될텐데 Var(x + F(x) ) = Var(x)라고 표기하는 이유를 잘 모르겠다. 어짜피 F(x) = 0인데도 일단 이부분은 넘어가고 잠깐 이전에 이해되지 않던 Residual Block에 대해 검색해보았다.
Residual Blcok 잔차 블록
* 그동안 잔류 블록이라 불렀는데 잠깐 검색해보니 잔차 블록이 맞는것 같다. 이 블록이 항등 함수가 되도록 한다는 말의 의미가 잘 이해가 되지 않았는데 아래의 링크를 통해서 이 블록이 항등함수가 되도록 학습한다는 것의 의미를 조금 더 이해할 수 있었다.
"무한한 저장공간은 무한한 길이의 테이프로 나타나는데 이 테이프는 하나의 기호를 인쇄할 수 있는 크기의 정사각형들로 쪼개져있다. 언제든지 기계속에는 하나의 기호가 들어가있고 이를 "읽힌 기호"라고 한다. 이 기계는 "읽힌 기호"를 바꿀 수 있는데 그 기계의 행동은 오직 읽힌 기호만이 결정한다. 테이프는 앞뒤로 움직일 수 있어서 모든 기호들은 적어도 한번씩은 기계에게 읽힐 것이다"
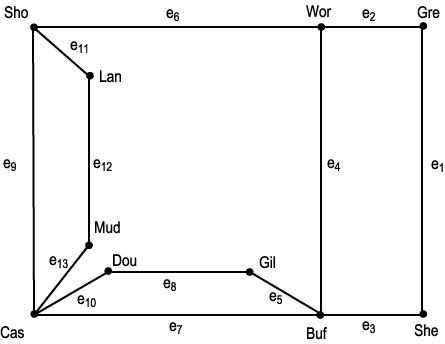
- 아래의 그림은 와이오밍 주의 고속도로 시스템이며, 모든 도로를 가장 경제적으로 순찰하는 방법을 찾아야 한다. 하지만 순찰하는 방법에 대해서 생략하고, 우선 아래의 그림은 그래프로 표현, 모델링 할수 있는데 어떻게 나타내는지 한번 살펴보자 살펴보자.
와이오밍 주 고속도로 시스템. AiStudy
- 위의 그림에서보면 각 도시들과 도시들을 이어주는 도로들을 볼 수 있다. 각각의 도시를 노드(정점)로 보고, 두 도시를 연결하는 도로를 에지(간선)이라고 하자. 그러면 위 그림의 그래프 G = (V, E)는 아래와 같이 그릴 수 있다. 각 노드의 이름은 이름의 앞 세글자로 하고, 에지들은 $e_{1}$, . . ., $e_{13}$과 같은 식으로 정리하였다.
와이오밍 주 고속도로 시스템의 그래프화. AIStudy
- 아래의 그래프도 모양은 다르지만 위의 그래프와 동일한 그래프라고 볼 수 있다.
와이오밍 주 고속도로 시스템의 대안 그래프. AIStudy
2.3 AIStudy에서 설명해주는 그래프 정리
- 우리는 그래프를 다음과 같이 표기한다. : G = (V, E)
- 하나의 간선 e는 간선 집합 E의 원소로 다음과 같이 표기한다 : e $\in$ E
- 하나의 간선 e는 두 노드 v, w를 연결하므로 e = (v, w) 혹은 e = (w, v)로 표기한다.
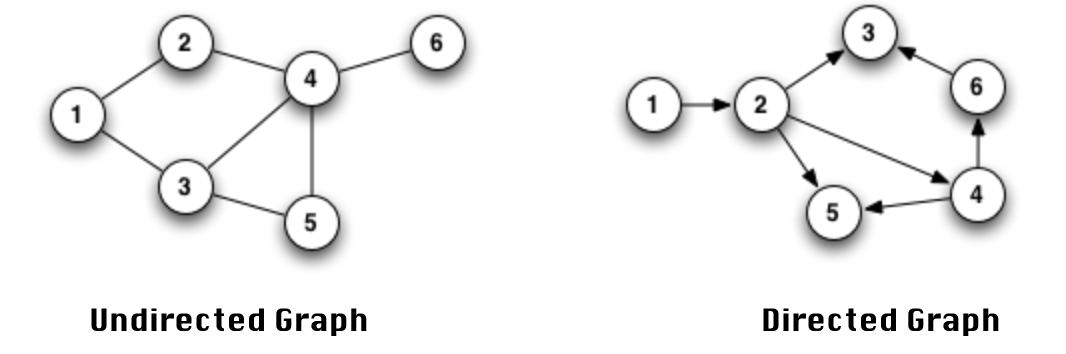
* 무방향 그래프 undirected graph의 경우 노드의 순서가 상관없으나, 유방향 그래프의 경우 노드 순서를 지켜야한다.
* 그래프 G가 유방향 그래프이고, e = (v, w) 라면, 노드 v에서 노드 w를 가리키는 간선이 된다.
2.4 와이오밍 주 고속도로의 간선과 정점 정리
- 아래의 와이오밍 주 고속도로 그래프 시스템은 무방향 그래프
- 노드에 대한 집합 V = {Gre, She, Wor, Buf, Gil, Sho, Cas, Dou, Lan, Mud}
- 에지에 대한 집합 E = {$e_{1}$, $e_{2}$, . . ., $e_{13}$}
- 간선 예시 1 : 간선 $e_{1}$ = (Gre, She) = (She, Gre)
- 간선 예시 2 : 간선 $e_{10}$ = (Cas, Dou) = (Dou, Cas)
와이오밍 주 고속도로 시스템의 그래프화. AIStudy
2.5 방향 그래프와 무방향 그래프 비교
- 에지/간선이 화살표 직선인 경우 방향 그래프
- 에지/간선이 그냥 직선인 경우 무방향 그래프
2.6 그래프 이론에서의 경로 path와 사이클 cycle
- 경로 Path : 하나의 정점에서 다른 정점으로 가는 길.
* example : 정점 A에서 정점 D로 가는 경로 A -> C -> D
- 사이클 Cyle : 한 정점에서 자기 자신으로 돌아갈 수 있는 경로. 사이클이 없는 경우 트리가 된다.
그동안 ppt로 강의 내용을 정리하고 있었는데 오늘 부터는 블로그에다가 그대로 하려고한다.
계속 똑같은 사진 복붙하기가 너무 힘들어
지금까지 데이터 전처리에 대해서 봤고 다음으로 다룰 내용은 가중치 초기화에 대해서 다뤄보겠습니다. 여러분들이 신경망을 학습할떄마다 맨 처음에는 어떤 방법으로든 가중치를 한번 초기화를 해줘야 해요.
한번 질문을 하면, 우리가 가중치와 편향을 0으로 초기화하면 어떤일이 벌어질까요? 아마도 아주 안좋은 결과가 나오게 됩니다. 왜냐면 가중치와 편향이 0이라는건 ReLU나 다른 비선형 활성화 함수들의 출력값들이 0이 될것이고, 그러면 입력 값으로 뭘 받던간에 그라디언트가 0이되버려서 멈춰버리겠죠.
-> 가중치 행렬이 모두 0이 되면 출력이 0이 되니, 해당 층에 대한 로스의 그라디언트도 0이 되는건 당연할거같다.
그래서 실제로 사용할때는 이런 문제 때문에 0으로 초기화 시켜서는 안돠요. 0이나 특정한 상수로 초기화해서 생기는 문제, 대칭 깨짐symmetry breaking이 일어나지 않거든요.
-> 가중치 행렬의 모든 원소를 0 혹은 특정한 상수로 다 채워버리면 행렬 자체가 대칭해져버리기 때문
-> 대칭 깨짐에 대해 검색했더니 물리학적인 용어가 나오는데 행렬 원소들이 다 똑같아, 대칭이되니 대칭깨짐이 없다고 말하는거같다.
-> 아니면 가중치가 모두 같은 값을 가지면 가중치의 대칭이 깨지는 식으로 학습이 되지 않아 대칭 깨징이 없다고 하는거같기도 하고
4.5 분류 방법들의 비교 A Comparison of Classification methods
이번 장에서는 우리는 3가지 분류 방법인 로지스틱 회귀, LDA, QDA까지 살펴봤습니다. 2장에서도 KNN에 대해서 이야기 해썼는데, 몇 가지 상황에서 이런 방법들이 성능이 어떻게 나오는지 한번 살펴봅시다.
이 방법들끼리 고안된 배경은 다르지만 로지스틱회귀와 LDA 방법들은 아주 가까이 관련되어 있어요. 두 클래스를 분류하는 상황에서 입력변수 p = 1이라고 할께요. 그러면 $p_{1}$(x), $p_{2}$ = 1 - $p_{1}$(x)가 관측치 X = x가 주어질때 클래스 1 혹은 클래스 2에 속할 확률이 될거에요. LDA의 경우 식 (4.12), (4.13)을 로그 오즈를 취하면 아래와 같이 될겁니다. $c_{0}$, $c_{1}$은 $\mu_{1}$, $\mu_{2}$, $\sigma^{2}$에 대한 함수가 되겠습니다.
식 (4.4)로부터 로지스틱 회귀의 경우 아래와 같이 정리할 수 있는데
식 (4.24)와 식(4.25)둘다 x에 대한 선형 함수에요. 그래서 로지스틱 회귀와 LDA는 선형 결정 경계를 만들어 냅니다. 두 방법사이 차이점이라 하면 $\beta_{0}$, $\beta_{1}$는 최대 가능도법 maximum likelihood로 구한다는것이고, $c_{0}$, $c_{1}$는 정규 분포를 따르는 평균과 분산 추정량으로 계산한다는 점입니다. LDA와 로지스틱 회귀 사이 이런 관계가 p > 1인 다차원 데이터에서도 존재해요.
로지스틱 회귀와 LDA의 차이점이 학습하는 과정뿐이다보니 두 방법은 비슷한 결과를 보이고 있어요. 하지만 항상그렇지는 않습니다. LDA는 관측치들이 각 클래스들끼리 공통된 공분산을 가지는 가우시안 분포를 따른다고 가정하고 있어, 이 가정이 올바른 경우 로지스틱 회귀를 능가합니다. 역으로 로지스틱 회귀난 가우시안 가정이 적합하지 않은 경우 LDA보다 더 좋으성능을 보입니다.
2장에서 봤던 KNN은 이번장에서 본 분류기랑은 완전히 다른 방법인데, X = x에 대한 관측치를 예측하기 위해서, x와 가까운 K개의 관측치를 찾아야 합니다. 그리고 주위에 있는 관측치가 많이 속해있는 클래스로 분류되요. 그래서 KNN은 완어떠한 결정 경계의 형태를 가진다는 가정이 없는 완전히 비모수적인 방법이라고 할수 있습니다.
그러므로 이 방법은 LDA나 로지스틱회귀보다 결정 경계가 완전히 비선형적인경우 더 뛰어난 성능을 보인다고 할 수 있어요. 하지만 KNN은 입력 변수들이 얼마나 중요한지 알려주는게 없다보니 표 4.3과같은 계수에 대한 테이블을 만들수가 없습니다.
마지막으로 QDA는 비모수적 방법인 KNN과 선형 LDA, 로지스틱 회귀 방법들을 절충한거라고 할수 있어요. QDA는 이차 결정 경계를 가정하다보니, 선형 방법들보다 더 넓은 범위를 정확한 모델을 만들수가 있어요. 하지만 KNN만큼 유연하지는 않고, QDA는 결정 경계의 형태에 대한 가정들을 만들다 보니 데이터가 많이 있을수록 더 좋은 성능을 보여요.
이 네가지 분류 방법의 성능을 보기위해서 6가지 서로 다른 시나리오의 데이터를 생성하였습니다. 세가지 시나리오 에서는 베이즈 결정경계는 선형적이고, 나머지 시나리오에서는 비선형적이라고 하겠습니다. 각 시나리오는 훈련데이터가 100개라고 해요. 그리고 이 데이터셋들로 학습을하고, 테스트 에러율을 구해볼게요.
그림 4.10 선형적인 시나리오들의 에러율을 비교하는 박스플롯.그림 4.11 비선형적인 시나리오들에 대한 테스트에러율의 박스플롯
그림 4.10가 선형 시나리오에 대한 결과, 그림 4.11은 비선형적인 시나리오들의 테스트 에러율의 결과를 보여주고 있습니다. KNN은 K를 지정하는게 필요하니 K는 1로 지정한 경우와 5장에서 다룰 교차검증 cross validation이란 방법으로 자동적으로 찾은 K를 사용하였습니다.
이 6개의 시나리오들은 p = 2이며, 아래와 같습니다.
- 시나리오 1 : 클래스 2개에 각각 20개의 관측치가 있고, 한 클래스에 속하는 관측치들ㅈ은 서로 다른 클래스와 상관관계를 가지고 있지 않아요. 그림 4.10의 왼쪽 그림에서 LDA가 잘동작하고 있지만 KNN는 편향을 제거하여 분산이 오프셋되지않다보니 나쁜 성능을 보이고 있습니다. QDA또한 LDA보다 필요 이상으로 유연하다보니 좋은 성능이 나오지않아요. 로지스틱 회귀는 선형 결정 경계를 가정으로 하고있어 LDA보다 성능이 약간 떨어지는걸 볼수 있습니다.
- 시나리오 2 : 자세한 사항은 시나리오 1과 동일하지만 두 입력변수간에 -0.5의 상관관계를 가진다고 할께요. 그림 4.10의 중간 판낼을 보면 이전 시나리오와 비교하면 각 방법들의 성능이 약간 바뀐걸 볼수 있어요.
- 시나리오 3 : $X_{1}$과 $X_{2}$는 t분포로를 따르며, 각 클래스 당 관측치가 50개를 가져요. t 분포는 정규 분포와 비슷한 형태이지만 평균으로부터 더 멀어진 경향을 보여요. 여기서도 결정경계는 선형적이고, 로지스틱을 학습한다고 할께요. 하지만 LDA의 가정을 위반해서, 다시말하면 정규분포를 따르지않아 그림 4.10의 오른쪽 판낼에서 로지스틱이 LDA보다 더 좋은 성능을 보이고 있고, 다른 방법들보다 우수한 성능을보여요. 하지만 비정규성을 따르다보니 QDA의 성능이 상당히 떨어졌어요.
- 시나리오 4 : 데이터를 정규 분포로 생성했고 첫번쨰 클래스의 입력변수들은 0.5의 상관관계를 가지고 있고, 두번쨰 클래스의 입력 변수들은 -0.5의 상관관계를 갖는다고 할꼐요. 이 상황은 QDA의 가정을 잘 따르므로 이차 결정 경계의 형태가 나오죠. 그림 4.11의 왼쪽 패널은 QDA가 다른 방법들에 비해 큰 성능을 보이는걸 알 수 있어요.
- 시나리오 5 : 각 클래스들에 대한 관측치들은 정규분포로 생성했으며, 입력 변수 끼리 상관관계를 가지고 있지 않습니다. 하지만 반응 변수들을 $X_{1}^{2}$, $X_{2}^{2}$, $X_{1}$ x $X_{2}$를 입력변수로 하는 로지스틱 함수로부터 얻었다고 할께요. 그결과 결정 경계가 이차적으로 되다보니 그림 4.11의 중간 판낼에서 QDA가 최고의 성능을 보이고 KNN_CV가 뒤쫓아오고 있어요. 하지만 선형 방법들은 성능이 크게 떨어집니다.
- 시나리오 6 : 이전 시나리오와 동일하나 반응 값들을 더 복잡한 비선형 함수로 얻은 경우로, 결과를 보면 QDA의 이차 결정 경계는 이 데이터를 적절하게 모델링하지 못하고 있습니다. 그림 4.11의 오른쪽 판낼을 보면 QDA는 다른 선형 모델보다 약간 더 나은 성능을 보이기는 하지만 가장 유연한 KNN-CV방법이 최고의 결과를 보이고 있어요. 이 시나리오에서는 데이터가 너무 복잡한 비선형 관계를 가질때 유연성의 정도(K값)을 적절하게 지정하지 않으면 KNN같은 비모수적 방법도 여전히 성능이 뒤떨어지는걸 볼 수 있어요.
이 여섯가지 예시들을보면 모든 상황에서 최고의 성능을보이는 한가지 방법은 존재하지 않습니다. 실제 결정경계가 선형인 경우 LDA와 로지스틱 회귀가 잘 동작하는 편이었으며, 결정경계가 약간 비선형적이라면 QDA가 좋은 성능을 보였어요. 마지막에 아주 복잡한 결정 경계를 갖는 경우 KNN같은 비모수적 방법이 가장 뛰어났습니다. 하지만 비모수적 방법의 완만도(K값)을 신중하게 정해야해요. 다음 장에서는 올바른 완만도를 찾기위한 수많은 방법들을 살펴보고 최적의 방법을 골라보겠습니다.
마지막으로 3장에서 배운 내용을 다시 생각해보면, 입력 변수들을 변환을 하고 회귀를 수행해서 입력과 반응 사이 비선형적인 관계를 다룰수가 있었습니다. 비슷하게 분류에서도 그렇게 할수가 있어요. 예를들면 $X^{2}$, $X^{3}$, $X^{4}$같은 입력변수들을 추가해서 로지스틱 회귀의 유연한 버전을 만들수도 있겠습니다.
하지만 이거는 분산이 크게 증가하느냐에 따라 성능이 개선될수도 있고 안될수도 있어요. 이건 추가된 유연성이 편향을 충분히 크게 상쉐시킬지에 달렸거든요. LDA에서도 똑같이 적용할수 있겠습니다. 만약 LDA다가 이차항이나 교차항을 추가시키면, 계수 추정치가 다르더라도 QDA랑 똑같은 형태가 될수도 있을거에요. 이러한 방법들로 LDA를 QDA로, QDA를 LDA로 변화시킬수 있겠습니다.
5. 리샘플링 기법
리샘플링 기법은 현대 통계학에서 필수적인 도구입니다. 이 방법은 훈련 데이터셋으로 반복해서 샘플을 뽑고, 이렇게 뽑은 샘플로 모델을 학습시켜 전체 훈련 데이터셋을 한번에 학습시킨것과 다른 모델을 만들어 추가적인 정보를 얻을수가 있어요. 예를든다면 선형 회귀 모델의 변동성을 추정하고자 할때 훈련 데이터셋으로부터 다른 샘플들을 반복해서 뽑고 이걸 학습을 시키면, 다른 학습 모델을 만들어 추가적인 정보를 얻을수가 있습니다. 이러한 방법을 덕분에 기존 원본 훈련 데이터 샘플을 만든 모델과는 다른 정보들을 얻을수 있게 됩니다.
리샘플링 기법은 계산 비용이 꽤 클수 있는데, 훈련 데이터에서 여러 하부집합들을 뽑아 여러번 통계적인 학습을 수행할수도 있거든요. 하지만 최근 계산 성능이 좋아지면서 리샘플링 기법의 계산 비용 문제는 사라졌습니다. 이번 장에서는 가장 널리 사용되는 리샘플링 기법인 교차 검증 cross validation과 부트스트랩 boostrap 기법에 대해서 이야기 해봅시다.
이 방법 둘다 많은 통계적 학습 과정에서 매우 자주 사용되는 방법인데, 예를들어 교차 검증 같은 경우에는 우리가 만든 통계적 학습 모델의 테스트 에러율을 구하여, 모델의 성능을 보거나 적절한 유연성 정도를 찾기위해서 사용해요. 이렇게 추정한 모델의 성능을 평가하는 과정을 모델 평가 model assessment라고 부르고, 모델의 유연성 정도를 찾아내는 과ㅏ정을 모델 선택 model selection이라고 부릅니다. 부트스트랩 boostrap은 다양한 상황에서 사용되고 있는데, 가장 흔하게는 주어진 통계적 학습 방법의 파라미터 추정치가 얼마나 정확한지 측정하고자 사용되요.
5.1 교차 검증 cross-validation
2장에서 테스트 에러율 test error rate와 훈련 에러율 train error rate의 차이를 살펴봤었습니다. 테스트 에러율은 학습하지 못한 관측치를 예측할때 평균 에러율이었었어요. 데이터셋이 주어지고 테스트 에러가 낮은 통계적 학습 방법이 사용되어요. 테스트 에러는 테스트 데이터셋이 있으면 쉽게 계산할수 있지만 가끔 없는 경우도 존재합니다.
반대로 훈련 에러는 통계적 학습 모델에다가 훈련떄 사용한 관측치들을 넣어 쉽게 계산할 수 있어요. 하지만 2장에서 봤다 시피 훈련 에러율은 테스트 에러율과 꽤 다를수 있으며, 대체로 훈련 에러율은 테스트 에러율보다 크게 떨어져요.
테스트 에러율을 계산하는데 필요한 테스트 데이터셋이 없을때 가지고 있는 데이터로 이 척도를 구하는 많은 방법들이 있는데, 어떤 방법들은 훈련 에러율을 수학적인 방법으로 조정해서 테스트 에러율을 구하기도 하지만 이건 6장에서 살펴보겠습니다.
이번 장에서는 학습 과정에서 사용될수 있는 훈련 관측치들의 일부를 홀드 아웃hold out/집어와서 테스트 에러율을 계산하는 방법들을 이야기해보고, 통계적 학습 기법들에 적용해봅시다.
5.1.1 ~ 5.1.4장에서는 양적 반응을 가지는 회귀 모델을 가정하고 간단하게 살펴보고, 5.1.5장에서는 질적 변수를 다루는 분류 문제를 살펴봅시다. 질적 변수든 양적 변수든 키 컨샙은 같다고 보면 되요.
5.1.1 검증 데이터셋 방법 The Validation Set Approach
그림 5.1 검증 데이터셋 방법의 개요도 schemetic. n개의 관측치들이 있는 데이터셋을 훈련 데이터셋(파란색 부분, 7, 22, 13, 그리고 나머지)와 검증 데이터셋(베이지부분, 91, 그리고 나머지)로 분할하였습니다. 통계적 학습 기법으로 훈련 데이터셋을 학습하고 검증데이터셋으로 성능을 평가하면 되요.
한번 우리가 훈련 에러율을 구하고 싶을대, 그림 5.1의 검증 데이터셋 방법이 사용될 수 있는대 매우 간단한 방법이에요. 그냥 주어진 데이터셋을 훈련데이터셋 training set과 검증 데이터셋 validation set/ 홀드아웃데이터셋 hold-out set으로 임의로 나눠주기만 하면 되거든요. 그러면 모델은 훈련 데이터셋을 학습하고, 학습한 모델을 검증 데이터셋으로 결과를 예측해서 검증하면 되요. 그렇게 양적 반응에 대한 MSE를 계산해서 검증 데이터셋의 에러율을 구하면 그게 테스트 에러율로 보면 되겠습니다.
한번 이 검증 데이터 셋 방법을 차량 데이터셋에다가 사용해볼꼐요. 우리는 지난 3장에서 mpg와 마력 사이에 비선형 관계가 있는걸 봤었어요. 그리고 마력과 $마력^{2}$으로 mpg를 예측하는 모델을 만들어서 선형 항만 있었을때보다는 더 나은 결과를 얻을수가 있었습니다. 그렇다보니 무조건 더 높은 차수를 가지고 있으면 더 좋은 결과를 얻을수 있을까? 궁금할수 있을거에요.
3장에서 이 질문에 대해서 2차항과 더 고차 항을 사용하는 선형 회귀의 p value를 보면서 확인할수 ㅇ있었습니다. 하지만 p value말고도 검증 데이터셋을 사용해서 확인할 수도 있어요. 그러면 한번 392개의 관측치들을 196개의 훈련 데이터셋과 196개의 검증 데이터셋으로 분할시켜볼꼐요.
그림 5.2 검증 데이터셋 방법을 차량 데이터셋에 사용한 결과. 테스트 에러율은 마력에 대한 다항식으로 mpg를 예측해서 구했습니다. 좌측 : 전체 데이터셋을 훈련과 검증 데이터셋을로 나누었을때 검증 에러율. 우측 : 검증 데이터 셋 방법을 10번 반복해서, 10개의 랜덤한 훈련데이터들셋과 검증데이터셋들로 구한 결과를 보여주고 있습니다. 여기서 보이는 테스트 MSE가 이 방법의 변동성을 보여주고 있어요.
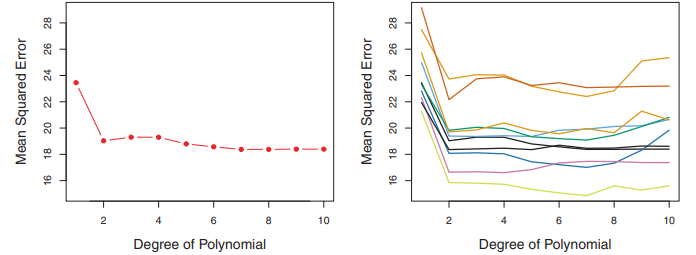
검증 데이터셋 에러율은 훈련 데이터셋으로 여러가지 복잡도/차수를 가진 모델들을 학습하고, 검증 셋으로 성능 평가해서 구할수가 있겠죠. 여기서 MSE를 검증 셋의 에러 평가 척도로 사용해서 보았고, 그 결과를 그림 5.2의 왼쪽 판낼에서 볼수 있어요.
이차 학습 모델의 검증 데이터셋 MSE는 선형적인 모델보다 상당히 줄어들었지만, 삼차항 모델같은 경우 이차 모델보다 약간 증가하였죠. 그래서 회귀 모델에서 삼차항까지 포함시킨다고해서 간단하게 이차항을 썻을때보다 예측성능이 더나아진다고 볼수는 어렵습니다.
한번 그림 5.2의 판낼처럼 만들기위해서 한번 데이터셋을 훈련 데이터셋과 검증 데이터셋으로 임의로 나눴다고 해볼깨요. 그런데 이 동작을 여러번 반복하면, 테스트 MSE도 계속 다르게 나올거에요. 이 내용이 그림 5.2의 오른쪽 판낼에서 나오는대 서로 다른 10개의 훈련데이터로 학습하고, 검증데이터셋으로 평가한 테스트 MSE를 보여주고 있어요.
모든 곡선들을 보면 이차항 까지만 포함된 모델의 경우 선형 항만 포함된 모델보다 훨씬 테스트 MSE가 적은걸 볼수 있어요. 그러므로 10가지 경우들을 보면서 3차항이나 더 고차항을 쓴다고해서 더 나은 성능을 얻을수 있지 않다는걸 알 수 있어요. 그리고 서로 다른 회귀 모델가지고 테스트 MSE를 구했으니 서로 다른 곡선들이 나오는게 당연하구요. 그렇다보니 한 모델이 가장 낮은 검증 MSE를 가진다고 하기도 힘들어요. 이런 곡선들의 변동성을 고려해서 우리가 결론 내릴수 있는건 이 데이터셋에 선형 모델이 적합하지 않다는 거구요.
검증 데이터셋 방법은 간단하며 구현하기도 쉽습니다. 하지만 다음의 두가지 결점을 가지고 있어요.
1. 그림 5.2에 보시다시피, 검증 에러율은 훈련 데이터셋과 검증 데이터셋이 임의로 만들어지는거에 크게 영향을 받아 변동이 심합니다.
2. 검증 데이터셋방법은 전체 관측치의 일부를 사용하다보니, 검증 데이터셋은 훈련 데이터셋보다 적어요. 그리고 적은 데이터로 훈련하면 성능이 떨어지다보니, 검증 데이터셋 에러율은 전체 데이터셋으로 학습한 모델의 테스트 에러율을 과소평가/ 전체 데이터셋을 학습한 모델의 테스트 에러율보다 떨어지는 경향이 있어요.
그래서 다음 장에서는 검증 데이터셋 방법이 가지고 있는 두가지 문제를 개선하고자 나온 방법인 교차 검증 cross validation에 대해서 알아봅시다.