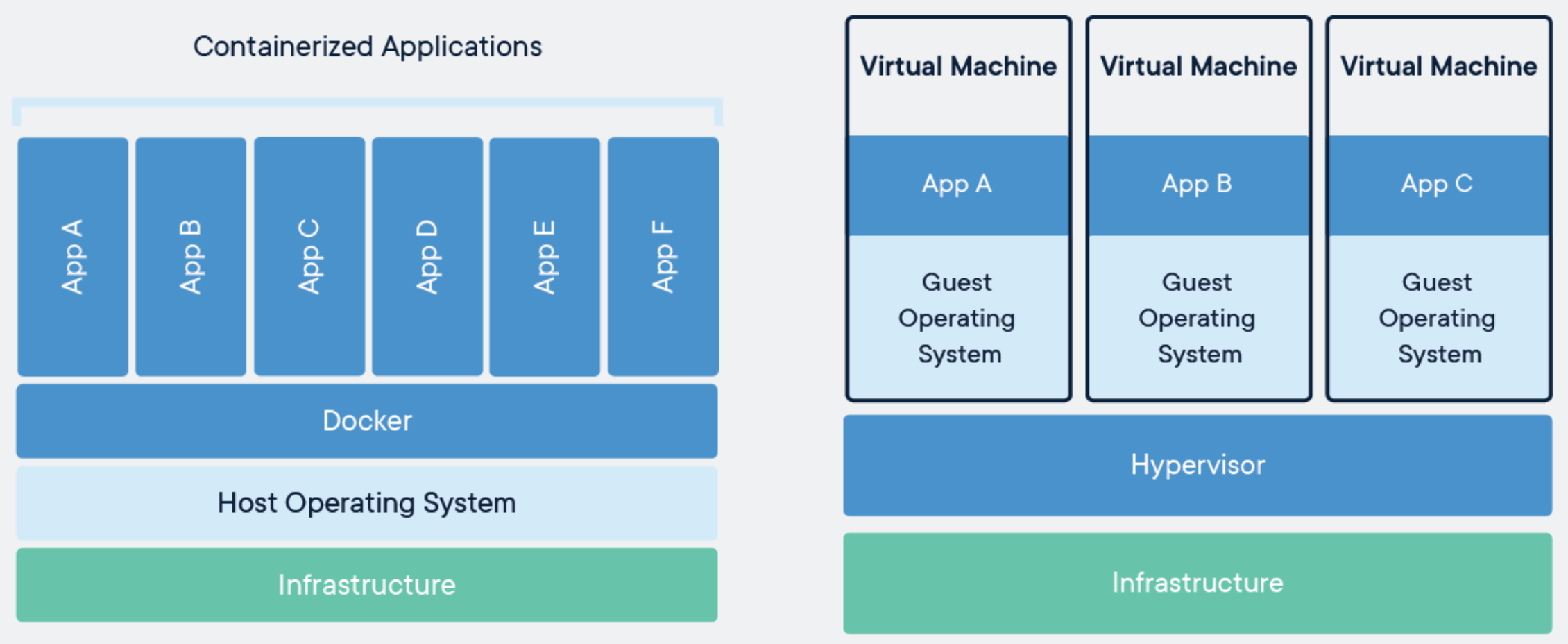
최근 푹 쉬고 나서 빅데이터 공부하면서 다시 조금식 페이스를 찾아가고 있다.
어쩌다가 IT분야를 시작하게 되었는지 쓰고 싶어지면 남기고
그 동안 과정을 한번 글로 정리하고 싶었는데 적어보려고 한다.
대학교를 그만둔 직후에는
프로그래밍 분야에 어떤게 있는지 잘 몰랏었다.
2016년 당시에는 검색해보면 그나마 가장 많이 나왔던게 웹개발 국비 과정이라
웹 개발자에서부터 시작하게 되었다.
자바, 데이터베이스, JSP, 스프링 프레임워크 등을 배우면서
프로그래밍 언어의 기본적인 틀과 자료구조
데이터베이스를 어떻게 설계하는것인지
HTTP 프로토콜 요청에 따라 웹서버가 어떻게 처리를 하는지
JDBC로 자바와 데이터베이스 사이 연동하는 과정
데이터베이스 데이터를 자바 클래스에 맞추고
프론트 단에 넘겨서 화면에 보여주기 등
혼자서 기본적인 계층형 게시판 같은 웹 어플리케이션을 만들수 있을 만큼 실력을 쌓았고
당시 팀프로젝트에선 팀원들의 개별적인 문제와 각자의 모듈을 합쳐 정상적으로 돌아가도록 했었다.
중기청 SW 대회에서 혼자 모의 주식게임 웹어플리케이션을 제출하여 특별상을 수상하고,
작은 스타트업에 취업을 하게 되었다.
거기선 입사한 당시에는 사수는 없었고, 클라우드 플랫폼에 올라간 웹 서비스를 다루어야 했다.
내가 다니던 학원에서는 리눅스를 하지 못해 그 즈음 리눅스를 처음 만지기 시작해서,
포트포워딩, 클라우드, 그리고 ORM 객체 관계 모델 이었던가 데이터베이스 테이블 한 데이터를 객체에
매핑 시켜서 다루는 기술들을 공부해나갔다
당시 웹 개발을 하는 신입들 중에서 못하는 편은 아니었다고 생각은 하지만
내 성향상 업무를 잘 수행하지 못하고, 그만 두고 말았었다.
그 시점에서는 당시 지금처럼 노드나 리액트같은 js들이 많이 사용되기 전이었다보니
기본적으로나마 ERD를 설계해서 데이터베이스 서버를 돌리고,
스프링 웹어플리케이션 MVC 모델이나, 부트스트랩 같은 프론트앤드를 다루기는 했으니
이 만큼이면 웹에 대해 전반은 다뤘다고 생각했었고,
깊이 들어간다면 더 깊이 들어갈수 있었더라도
더 이상 웹분야에 공부할 필요성을 느끼지 못하고 컴퓨터에 대해서 제대로 공부하고 싶어졌었다.
대학교를 자퇴하고나서 고졸이던 나는 학점은행제를 준비하고 있었으나 아직 학점이 부족했었고,
국가장학금을 받을걸 생각하고 폴리텍에 입학하여 컴퓨터 과학에 대해 제대로 공부하기 시작하였다.
컴퓨터 개론, 디지털 회로 기초 같은 과목들을 들으면서 컴퓨터 기본 이론을 공부하고,
C언어와 소켓 통신을 별도로 공부했었다.
하지만 당시 폴리텍 수업만으로는부족해서 다른 과정도 생각하고 있었다.
우리가 가장 밀접하게 사용되는 프로그램이라 하면 웹, 모바일, 임베디드 정도라 생각하고 있었는데
웹에서도 하이브리드로 모바일 어플리케이션을 만들수 있었으니,
전자와 임베디드 분야를 해보고 싶던 나는 임베디드 학원을 다니게 되었다.
그 곳에서의 과정은 임베디드에 필요한 전반을 다루다보니
C/C++에서부터 데이터베이스, 리눅스, 라즈베리파이, 디바이스드라이버, QT GUI 정도를 다뤘었는데
이전부터 C나 데이터베이스, 리눅스는 조금씩 공부해온게 있었던 덕분에 조금은 수월하게 들을수 있었다.
특히 QT를 배우면서
서버단, 프론트단, 데이터베이스 까지 고려해야하는 웹과는
다르게 생각보다 쉽게 데스크탑 어플리케이션을 만들수 있어서 신기하더라.
그리고 이 즈음 학사 학위를 받을 만큼 학점이 준비되어 학점은행제로 학위를 받았다.
임베디드 분야도 조금 공부하고, 학사 학위를 받았지만 약간 욕심이 생겨 대학원에 가고 싶었는데
제대로 된 대학원에 들어갈수 있을거란 자신이 없었었다.
당시 나는 제대로 된 대학을 나와 학사 학위를 받은게 아니라 전공 지식도 없고
웹/임베디드 학원 다니면서 배운 개발 지식이 전부다 보니 대학교 연구실 받아주는곳이 있을까 싶더라
그리고 군대 문제도 있다보니 전산병으로 가야되지않을까 고민하던 시기였다.
평소 그렇게 고민하면서 검색하던 중 한 대학원을 찾았는데
거기서 국비 지원으로 등록금도 안들고, 미필자의 경우 전문연구요원으로 병역 문제도 해결해준다고 하더라
너무 좋은 소리만 하고, 비전공자가 들어갈수 있는 대학원이야 제대로된 곳은 아니었다.
몇 번 가보고 나서는 가지 말려고 주저하기는 했었으나 교수는 계속 연락하지
부담은 안되고, 공부는 더하고 싶고, 제대로 된 곳에 갈 자신이 없었던 나는 바보같은 선택을 하고 말았다.
내가 들어간 당시에는 본교 재학생들도 다 도망가고 안오는 곳이라
제대로된 연구 성과나 선배없이 밑 바닥에서 시작했다.
거기선 딥러닝, 드론, 자율주행차 하게 되었는데
당시에는 공학/수학적 지식이 전혀 없다보니
아무 생각없이 시중에 파는 교재를 보거나 최대한 검색하면서 공부해나갔다.
그러다보니 다른 대학원의 연구 성과 같은걸 보면 너무 부러웠지만 어쩔수가 없었다.
한번은 의존 관계에 대한 개념 자체가 없는 상태에서 자율주행 오픈소스를 빌드하는데
자꾸 빌드 실패가 났었다.
나는 아무리 고치려 해도 빌드 실패하는 이유를 찾을수가 없었고,
2주동안 빌드로 해매면서 눈물나더라
여러 분야를 조금이나마 공부한 지금은
당시 교수가 왜 이런식으로 시켯을까 많은 생각이 든다.
그때는 암만 미워도 내발로 들어온 곳인데 좋든 나쁘든 성의것 했고 트러블도 있었지만 졸업은 할 수 있었다.
비전공자 치고는 나름대로는 열심히 했다고 생각해
그 이후로는
이 블로그를 만들고
대학원에서 삽질하느라 못했던 공부를 잔뜩하다보니
벌써 2020년이 끝나가고 있다.
지금까지
전기, 전자, 대학수학, 공업수학, 선형대수, 임베디드, 확률, 통계, 제어, 신호처리 등
이것 저것 공부하면서
개념이 확실하게 이해된 부분도 많아졌지만
잊은 내용도 많고, 더 공부해야할게 보인다.
그런데 이러면 끝이없고
이렇게까지 공부할 필요없이
어느 분야든 취업해서 그 분야에 필요한 도메인 지식과 노하우를 익혀나가는것도 길이라 생각한다.
아직 정해진건 없고
적어도 올해 빅데이터 분석기사만 따고 잘 마무리 했으면 좋겠다.
그리고 곧 글 1000개 달성 !

'그외 > 로그' 카테고리의 다른 글
| 인공지능에 대해 공부하면서 (0) | 2020.11.11 |
|---|---|
| 시험 준비와 근황 (0) | 2020.11.09 |
| 공부 고민 (0) | 2020.08.16 |
| 가끔 보는 유튜브 - 커넥팅닷 (0) | 2020.08.16 |
| 프로젝트가 우선이냐 이론이 우션이냐 ojtube (0) | 2020.08.16 |