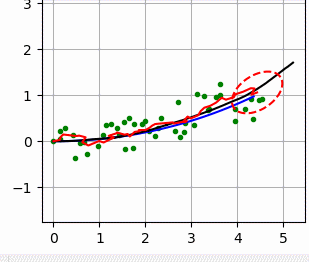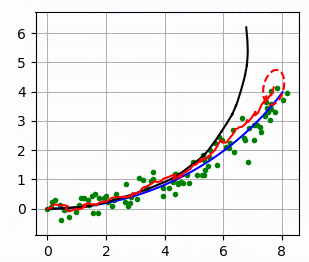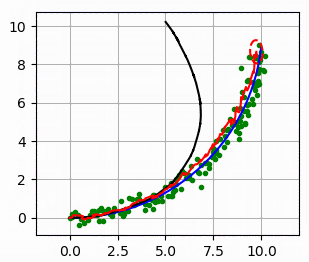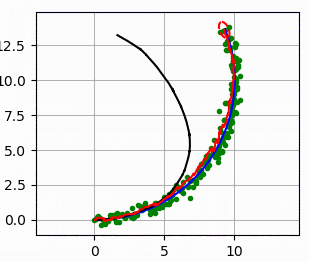
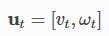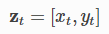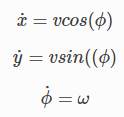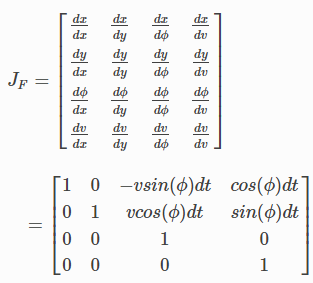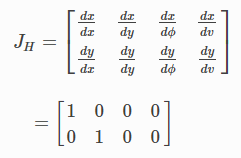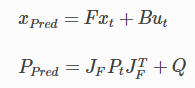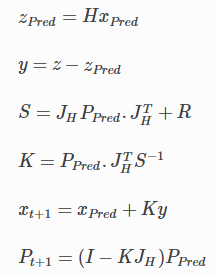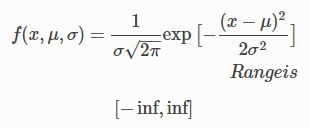def normalize_probability(grid_map):
sump = sum([sum(i_data) for i_data in grid_map.data])
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
grid_map.data[ix][iy] /= sump
return grid_map
while SIM_TIME >= time:
time += DT
print("Time:", time)
u = calc_input()
yaw = xTrue[2, 0] # Orientation is known
xTrue, z, ud = observation(xTrue, u, RF_ID)
grid_map = histogram_filter_localization(grid_map, u, z, yaw)
if show_animation:
plt.cla()
# for stopping simulation with the esc key.
plt.gcf().canvas.mpl_connect(
'key_release_event',
lambda event: [exit(0) if event.key == 'escape' else None])
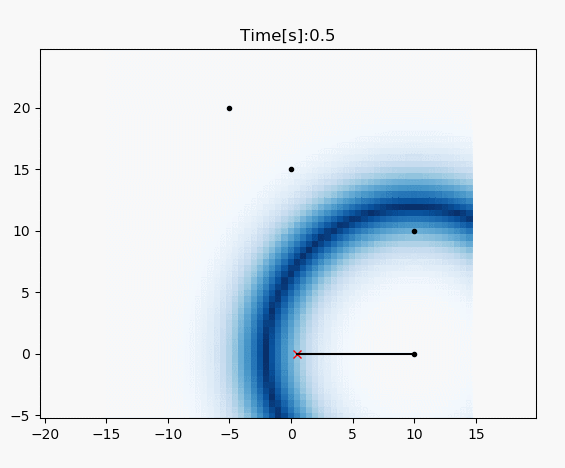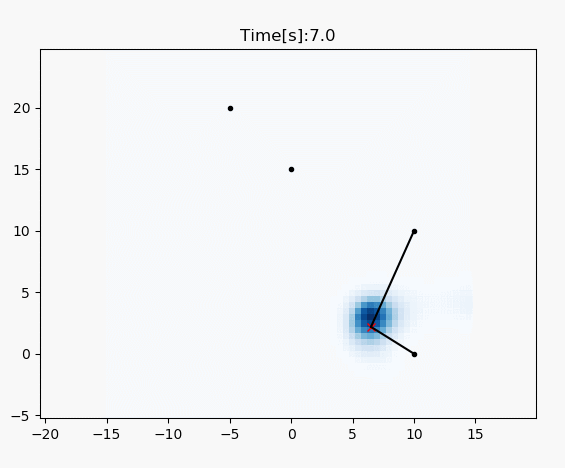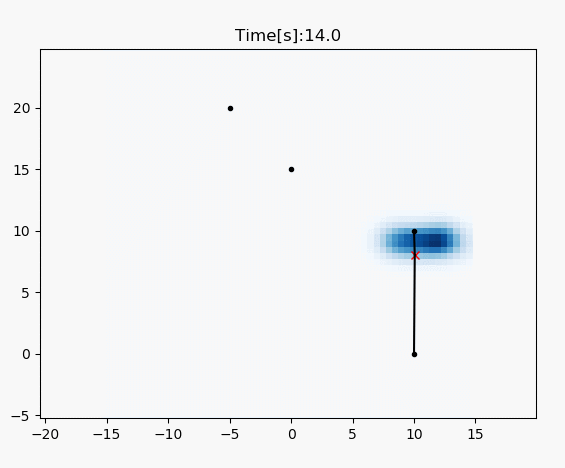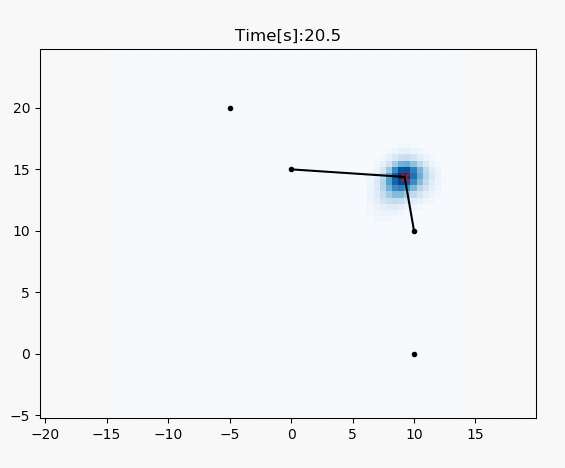
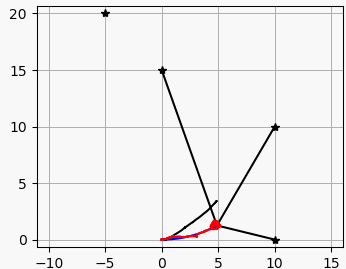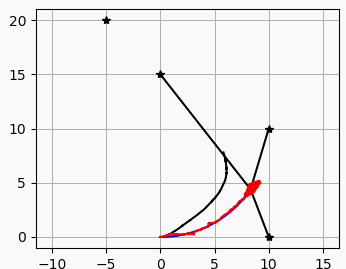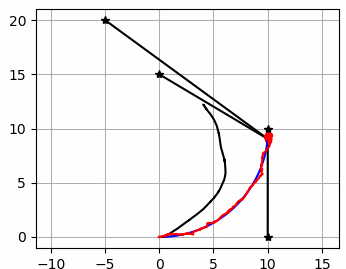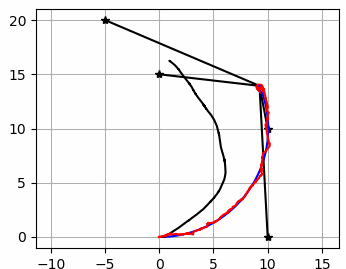
draw_heat_map(grid_map.data, mx, my)
plt.plot(xTrue[0, :], xTrue[1, :], "xr")
plt.plot(RF_ID[:, 0], RF_ID[:, 1], ".k")
for i in range(z.shape[0]):
plt.plot([xTrue[0, :], z[i, 1]], [
xTrue[1, :], z[i, 2]], "-k")
plt.title("Time[s]:" + str(time)[0: 4])
plt.pause(0.1)
여기서 시각화 하는 부분을 빼면
1. 입력 계산 calc_input
2. 관측 observation
3. 히스토그램 필터 위치추정 histogram_filter_localization
이렇게 3 파트로 나눌수 있겠습니다.
입력 계산을 살펴보겠습니다.
def calc_input():
v = 1.0 # [m/s]
yaw_rate = 0.1 # [rad/s]
u = np.array([v, yaw_rate]).reshape(2, 1)
return u
여기는 속도 기반 모델인지
2,1의 행렬로
첫재 값은 선속도, 둘때 값은 각속도를 넣어서 반환해 줍니다
다음으로 관측을 봅시다
def observation(xTrue, u, RFID):
xTrue = motion_model(xTrue, u)
z = np.zeros((0, 3))
for i in range(len(RFID[:, 0])):
dx = xTrue[0, 0] - RFID[i, 0]
dy = xTrue[1, 0] - RFID[i, 1]
d = math.hypot(dx, dy)
if d <= MAX_RANGE:
# add noise to range observation
dn = d + np.random.randn() * NOISE_RANGE
zi = np.array([dn, RFID[i, 0], RFID[i, 1]])
z = np.vstack((z, zi))
# add noise to speed
ud = u[:, :]
ud[0] += np.random.randn() * NOISE_SPEED
return xTrue, z, ud
일단 관측하기전에
실제 상태에 노이즈 없는 입력을 주어
실제 이동 위치를 구하고
실제 이동 위치와 RFID 사이의 거리를 계산하겠습니다.
여기서 구한 거리 d가 관측 가능 거리에 속한다면
관측 노이즈 dn과 가우시안 분포를 곱하여 노이즈를 반영한 실제 측정치가 됩니다.
이 실제 측정치들을 모든 RFID에 구하여 z에 vstack으로 쌓아주면
아마 zi가 거리, rfid x, rfid y이므로 (1, 3)
zi가 4개이니
z는 (4, 3)d의 데이터가 될겁니다.
이제 실제 이동후 위치와 노이즈가 반영된 관측치, 노이즈가 반영된 입력치를 필터에 사용할수있도록 반환해줍시다.
while SIM_TIME >= time:
time += DT
print("Time:", time)
u = calc_input()
yaw = xTrue[2, 0] # Orientation is known
xTrue, z, ud = observation(xTrue, u, RF_ID)
grid_map = histogram_filter_localization(grid_map, u, z, yaw)
if show_animation:
plt.cla()
# for stopping simulation with the esc key.
plt.gcf().canvas.mpl_connect(
'key_release_event',
lambda event: [exit(0) if event.key == 'escape' else None])
draw_heat_map(grid_map.data, mx, my)
plt.plot(xTrue[0, :], xTrue[1, :], "xr")
plt.plot(RF_ID[:, 0], RF_ID[:, 1], ".k")
for i in range(z.shape[0]):
plt.plot([xTrue[0, :], z[i, 1]], [
xTrue[1, :], z[i, 2]], "-k")
plt.title("Time[s]:" + str(time)[0: 4])
plt.pause(0.1)
이제 이 시뮬레이션의 핵심인
히스토그램 위치 추정 파트를 살펴보겠습니다.
def histogram_filter_localization(grid_map, u, z, yaw):
grid_map = motion_update(grid_map, u, yaw)
grid_map = observation_update(grid_map, z, RANGE_STD)
return grid_map
def observation_update(grid_map, z, std):
for iz in range(z.shape[0]):
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
grid_map.data[ix][iy] *= calc_gaussian_observation_pdf(
grid_map, z, iz, ix, iy, std)
grid_map = normalize_probability(grid_map)
return grid_map
관측 갱신에서는 기존의 지도, 관측 데이터,
관측 노이즈 표준편차를 사용하여 계산됩니다.
우선 z에 대해서 도는것을 보니 각각의 관측치 데이터를 가지고
전체 격자들의 값들을 변경시키는것 같습니다.
루프문 맨 안에 보면 가우시안 관측 밀도 함수 계산값을 구하여 각 격자 값을 갱신시키고 있습니다.
가우시안 관측 확률 밀도 계산 함수를 살펴보겠습니다.
def calc_gaussian_observation_pdf(grid_map, z, iz, ix, iy, std):
# predicted range
x = ix * grid_map.xy_resolution + grid_map.min_x
y = iy * grid_map.xy_resolution + grid_map.min_y
d = math.hypot(x - z[iz, 1], y - z[iz, 2])
# likelihood
pdf = (1.0 - norm.cdf(abs(d - z[iz, 0]), 0.0, std))
return pdf
일단 z는 첫번째 rfid (10, 0)로
여기서 z는 관측 모델에서 구한 (10, 10, 0)으로 가정하겠습니다. (거리, x, y)
def calc_gaussian_observation_pdf(grid_map, z, iz, ix, iy, std):
# predicted range
x = ix * grid_map.xy_resolution + grid_map.min_x
y = iy * grid_map.xy_resolution + grid_map.min_y
d = math.hypot(x - z[iz, 1], y - z[iz, 2])
# likelihood
pdf = (1.0 - norm.cdf(abs(d - z[iz, 0]), 0.0, std))
return pdf
격자 (1,1)에서 예측 d는 첫번재 랜드마크와 매우 멀으므로
abs(예측 거리 - 실제 거리)는 매우 큰 값이 될것이고,
누적 정규 분포에 따라 1에 가까운 값이 됩니다.
하지만 우도를 계산하는만큼 1 - (1에 가까운 값)이라면 0에 가까운 확률 밀도가 반환되고
결국 (1,1) 격자는 가중치가 매우 작아질겁니다.
하지만 실제 첫번째 랜드마크와 가까운 격자라면
예측 거리 - 실제 거리는 매우 작은 값이 될것이며
높은 pdf 값을 반환한다고 볼수 있겠습니다.
def observation_update(grid_map, z, std):
for iz in range(z.shape[0]):
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
grid_map.data[ix][iy] *= calc_gaussian_observation_pdf(
grid_map, z, iz, ix, iy, std)
grid_map = normalize_probability(grid_map)
return grid_map
다시 관측 갱신으로 돌아와
확률 정규화 과정을 시키면
첫번째 루프의 히스토그램 필터 수행이 완료됩니다.
# Parameters
SIM_TIME = 20.0 # simulation time [s]
DT = 0.5 # time tick [s]
MAX_RANGE = 10.0 # maximum observation range
MOTION_STD = 1.0 # standard deviation for motion gaussian distribution
RANGE_STD = 3.0 # standard deviation for observation gaussian distribution
파라미터를 조금 수정해서
동작시켜보겠습니다.
전체 코드 histogram_filter.py
"""
Histogram Filter 2D localization example
In this simulation, x,y are unknown, yaw is known.
Initial position is not needed.
author: Atsushi Sakai (@Atsushi_twi)
"""
import copy
import math
import matplotlib.pyplot as plt
import numpy as np
from scipy.ndimage import gaussian_filter
from scipy.stats import norm
# Parameters
SIM_TIME = 20.0 # simulation time [s]
DT = 0.5 # time tick [s]
MAX_RANGE = 10.0 # maximum observation range
MOTION_STD = 1.0 # standard deviation for motion gaussian distribution
RANGE_STD = 3.0 # standard deviation for observation gaussian distribution
# grid map param
XY_RESOLUTION = 0.5 # xy grid resolution
MIN_X = -15.0
MIN_Y = -5.0
MAX_X = 15.0
MAX_Y = 25.0
# simulation parameters
NOISE_RANGE = 2.0 # [m] 1σ range noise parameter
NOISE_SPEED = 0.5 # [m/s] 1σ speed noise parameter
show_animation = True
class GridMap:
def __init__(self):
self.data = None
self.xy_resolution = None
self.min_x = None
self.min_y = None
self.max_x = None
self.max_y = None
self.x_w = None
self.y_w = None
self.dx = 0.0 # movement distance
self.dy = 0.0 # movement distance
def histogram_filter_localization(grid_map, u, z, yaw):
grid_map = motion_update(grid_map, u, yaw)
grid_map = observation_update(grid_map, z, RANGE_STD)
return grid_map
def calc_gaussian_observation_pdf(grid_map, z, iz, ix, iy, std):
# predicted range
x = ix * grid_map.xy_resolution + grid_map.min_x
y = iy * grid_map.xy_resolution + grid_map.min_y
d = math.hypot(x - z[iz, 1], y - z[iz, 2])
# likelihood
pdf = (1.0 - norm.cdf(abs(d - z[iz, 0]), 0.0, std))
return pdf
def observation_update(grid_map, z, std):
for iz in range(z.shape[0]):
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
grid_map.data[ix][iy] *= calc_gaussian_observation_pdf(
grid_map, z, iz, ix, iy, std)
grid_map = normalize_probability(grid_map)
return grid_map
def calc_input():
v = 1.0 # [m/s]
yaw_rate = 0.1 # [rad/s]
u = np.array([v, yaw_rate]).reshape(2, 1)
return u
def motion_model(x, u):
F = np.array([[1.0, 0, 0, 0],
[0, 1.0, 0, 0],
[0, 0, 1.0, 0],
[0, 0, 0, 0]])
B = np.array([[DT * math.cos(x[2, 0]), 0],
[DT * math.sin(x[2, 0]), 0],
[0.0, DT],
[1.0, 0.0]])
x = F @ x + B @ u
return x
def draw_heat_map(data, mx, my):
max_value = max([max(i_data) for i_data in data])
plt.pcolor(mx, my, data, vmax=max_value, cmap=plt.cm.get_cmap("Blues"))
plt.axis("equal")
def observation(xTrue, u, RFID):
xTrue = motion_model(xTrue, u)
z = np.zeros((0, 3))
for i in range(len(RFID[:, 0])):
dx = xTrue[0, 0] - RFID[i, 0]
dy = xTrue[1, 0] - RFID[i, 1]
d = math.hypot(dx, dy)
if d <= MAX_RANGE:
# add noise to range observation
dn = d + np.random.randn() * NOISE_RANGE
zi = np.array([dn, RFID[i, 0], RFID[i, 1]])
z = np.vstack((z, zi))
# add noise to speed
ud = u[:, :]
ud[0] += np.random.randn() * NOISE_SPEED
return xTrue, z, ud
def normalize_probability(grid_map):
sump = sum([sum(i_data) for i_data in grid_map.data])
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
grid_map.data[ix][iy] /= sump
return grid_map
def init_grid_map(xy_resolution, min_x, min_y, max_x, max_y):
grid_map = GridMap()
grid_map.xy_resolution = xy_resolution
grid_map.min_x = min_x
grid_map.min_y = min_y
grid_map.max_x = max_x
grid_map.max_y = max_y
grid_map.x_w = int(round((grid_map.max_x - grid_map.min_x)
/ grid_map.xy_resolution))
grid_map.y_w = int(round((grid_map.max_y - grid_map.min_y)
/ grid_map.xy_resolution))
grid_map.data = [[1.0 for _ in range(grid_map.y_w)]
for _ in range(grid_map.x_w)]
grid_map = normalize_probability(grid_map)
return grid_map
def map_shift(grid_map, x_shift, y_shift):
tmp_grid_map = copy.deepcopy(grid_map.data)
for ix in range(grid_map.x_w):
for iy in range(grid_map.y_w):
nix = ix + x_shift
niy = iy + y_shift
if 0 <= nix < grid_map.x_w and 0 <= niy < grid_map.y_w:
grid_map.data[ix + x_shift][iy + y_shift] =\
tmp_grid_map[ix][iy]
return grid_map
def motion_update(grid_map, u, yaw):
grid_map.dx += DT * math.cos(yaw) * u[0]
grid_map.dy += DT * math.sin(yaw) * u[0]
x_shift = grid_map.dx // grid_map.xy_resolution
y_shift = grid_map.dy // grid_map.xy_resolution
if abs(x_shift) >= 1.0 or abs(y_shift) >= 1.0: # map should be shifted
grid_map = map_shift(grid_map, int(x_shift), int(y_shift))
grid_map.dx -= x_shift * grid_map.xy_resolution
grid_map.dy -= y_shift * grid_map.xy_resolution
grid_map.data = gaussian_filter(grid_map.data, sigma=MOTION_STD)
return grid_map
def calc_grid_index(grid_map):
mx, my = np.mgrid[slice(grid_map.min_x - grid_map.xy_resolution / 2.0,
grid_map.max_x + grid_map.xy_resolution / 2.0,
grid_map.xy_resolution),
slice(grid_map.min_y - grid_map.xy_resolution / 2.0,
grid_map.max_y + grid_map.xy_resolution / 2.0,
grid_map.xy_resolution)]
return mx, my
def main():
print(__file__ + " start!!")
# RF_ID positions [x, y]
RF_ID = np.array([[10.0, 0.0],
[10.0, 10.0],
[0.0, 15.0],
[-5.0, 20.0]])
time = 0.0
xTrue = np.zeros((4, 1))
grid_map = init_grid_map(XY_RESOLUTION, MIN_X, MIN_Y, MAX_X, MAX_Y)
mx, my = calc_grid_index(grid_map) # for grid map visualization
while SIM_TIME >= time:
time += DT
print("Time:", time)
u = calc_input()
yaw = xTrue[2, 0] # Orientation is known
xTrue, z, ud = observation(xTrue, u, RF_ID)
grid_map = histogram_filter_localization(grid_map, u, z, yaw)
if show_animation:
plt.cla()
# for stopping simulation with the esc key.
plt.gcf().canvas.mpl_connect(
'key_release_event',
lambda event: [exit(0) if event.key == 'escape' else None])
draw_heat_map(grid_map.data, mx, my)
plt.plot(xTrue[0, :], xTrue[1, :], "xr")
plt.plot(RF_ID[:, 0], RF_ID[:, 1], ".k")
for i in range(z.shape[0]):
plt.plot([xTrue[0, :], z[i, 1]], [
xTrue[1, :], z[i, 2]], "-k")
plt.title("Time[s]:" + str(time)[0: 4])
plt.pause(0.1)
print("Done")
if __name__ == '__main__':
main()
신뢰도는 상태 $x_t$로 나타내며, 이 값은 모든 이전 상태와 측정, 그리고 제어 입력이 주어질 때 구할수 있는데, 이 조건부 확률은 수학적으로 정리하면 다음과 같습니다.
1. $z_t$는 측정
2. $u_t$ 동작 명령
3. $x_t$는 시간 t에 대한 로봇이나 주위 환경의 상태(위치, 속도 등)
만약 우리가 상태 $x_{t-1}$과 $u_t$를 알고 있다면, 상태 $x_{0:t-2}$와 $z_{1:t-1}$는 조건부 독립 성질에 따라 아는게 크게 중요하지는 않습니다. 상태 $x_{t-1}$는 $x_t$와 $z_{1:t-1}$, $u_{1:t1}$ 사이 조건부 독립을 나타내는데 사용됩니다. 이를 정리하면 다음과 같습니다.
2법칙
$x_t$가 완전하다면
여기서 $x_t$가 완전하다는것의 의미는 과거의 상태, 측정, 동작 명령이 미래를 예측하는데 필요한 정보를 주지않는 경우를 말합니다.
p($x_t$ | $x_{t-1}$, $u_t$) -> 상태 전이 확률 state trasition probability
p($z_t$ | $x_t$) -> 측정 확률
조건부 의존과 조건부 독립의 예제
- 독립인 경우와 조건부 의존하는 경우
2개의 양면 동전이 있다고 합시다.
A - 첫번째 동전이 앞면을
B - 두 번째 동전이 앞면을
C - 두 동전이 같은 경우
A와 B만 보면 독립이지만, C가 주어진 경우라면 A와 B는 조건부 독립이 됩니다. C라는 사실을 알고 있다면 첫번째 동전의 결과가 다른 것의 결과도 알려주기 때문입니다.
- 의존하는 경우와 조건부 독립인 경우
어느 상자에 2개의 동전이 있는데 1개는 일반적인 동전이고 하나는 둘다 동일한 가짜 동전이라고 합시다(P(H) = 1). 동전을 하나 고르고 던지는 것을 2번 해보면 이 사건들을 다음과 같이 정의할 수 있습니다.
A = 첫 코인이 앞면이 나온 경우
B = 두 번째 동전이 앞면이 나오는 경우
C = 일반 동전을 골른 경우
A가 발생한 경우, 우리가 일반 코인 보다는 가짜 코인을 고른 가능성이 더 크다고 볼 수 있습니다. 이는 B가 발생할 조건부 확률을 증가시키는데, A와 B는 의존 관계임을 의미합니다. 하지만 C라는 사실이 주어질 때는 A와 B는 서로 독립이 됩니다.
베이즈 법칙 bayes rule
사후 확률 posterior P(B | A) = $\frac{우도 Likelihood P(A|B) * 사전 확률 prior P(B)} {주변 확률 분포 Marginal P(A)}$
여기서
- 사후 확률 : A라는 사건 일어났을때, 사건 B가 일어날 확률
- 우도 : 사건 B가 일어났을때, A인 확률
- 사전 확률 : 사건 B가 일어날 확률
- 주변 확률 : 사건 A가 일어날 확률
예제 :
여성 중 1%는 유방암을 가지고 99%는 그렇지 않습니다. 유방함 검사로 80%의 경우 유방암을 찾아내지만 20%는 놓치게 됩니다. 유방암 검사에서 9.6%는 유방암이 존재하지 않지만 유방암이 있다고 잘못 찾아냅니다.
베이즈 정리로 이를 식으로 정리하면 다음과 같이 정리할 수 있습니다.
- Pr(A|X) - 양성 (X)인데, 실제로 암을 가진 (A) 확률을 위 식을 이용해서 구하면 7.8%가 됩니다.
- Pr(X|A) - 암을 가진 경우 (A), 양성인 (X) 경우 이는 참 긍정으로 80%가 됩니다.
- Pr(A) - 암이 있는 경우 1%
- Pr(not A) - 암이 없는 경우 99%
- Pr(X | not A) - 암이 없는데 (~A) 양성 (X)이 된 경우, 이는 거짓 긍정 false positive으로 9.6%가 됩니다.
베이즈 필터 알고리즘
기본 필터 알고리즘은 $x_t$에 대해 다음과 같이 정리 할 수 있습니다.
예측 단계
첫 번째 단계는 베이즈 정리 bayes theorem을 이용하여 사전확률을 구하는데 이를 예측 과정 prediction step이라 합니다. 신뢰도 $\bar{bel}(x_t)$는 시간 t일때 측정 $z_t$를 반영하기 이전으로 이 단계에서는 동작이 발생함에 따라 기존의 가우시안과 공분산이 더해져 기존 정보를 잃어버리게 됩니다. 이 방정식의 RHS(right hand side) 우항은 사전 확률 계산을 위해서 전체 확률 법칙 law of total probabily를 사용합니다.
갱신 단계
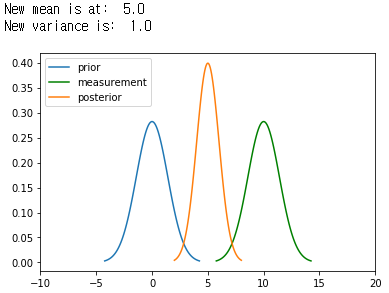
다음은 갱신 단계로 correction or update step 시간 t에서의 측정 $z_t$를 통합하여 로봇의 신뢰도를 계산하는데, 로봇이 어디에 있는지 센서 정보로 반영하며 구하며 여기서 가우시안 분포들을 곱하게 됩니다. 가우시안의 곱 연산 결과로 평균은 사이에 위치하고, 공분산은 작아지게 됩니다.
복도를 따라 이동하며 문을 감지하는 센서를 가진 로봇.
위 그림은 베이즈 필터로 로봇의 위치를 추정하는 예시로서 로봇은 복도가 어떻게 생겼는지는(지도) 알지만 자신의 위치를 모르는 상태 입니다.
1. 맨 처음, 로봇은 지도상에서 어디에 위치하는지 모르므로 지도 전체에 동일한 확률들을 배정합니다.
2. 첫 센서 결과로 문이 존재하는것을 알았습니다. 로봇은 지도가 어떻게 되어있는지 알고는 있으나 문이 3개가 있으므로 어디에 있는지는 아직 알 수 없습니다. 그래서 각각의 문 위치에다가 같은 확률들이 배정됩니다.
3. 로봇이 앞으로 전진하면서 예측과정이 발생하는데 일부 정보를 잃어버리므로 4번째 다이어그램 처럼 가우시안의 분산이 커지게 됩니다. 마지막으로 신뢰도 분포는 이전 단계서의 사후확률과 동작후 상태를 컨볼루션한 결과로 평균이 우측으로 이동하게 됩니다.
4. 다시 측정 결과를 반영을 하는데 문이 존재한다면, 세 문들 앞에서 모두 문이 존재할 확률들은 같으므 5번째 다이어그램에서 계산한 사후확률을 구할 수 있습니다. 이 사후확률은 이전 사후확률과 측정의 컨벌루션 결과이며 로봇이 2번째 문 근처에 있음을 알 수 있습니다. 이때 분산은 작아지며 확률은 커지게 됩니다.
5. 이러한 동작과 갱신 과정이 반복되면 로봇은 6번째 다이어그램처럼 주위 환경에 대해 자신의 위치를 추정할 수 있게 됩니다.
베이즈 필터와 칼만 필터 구조
칼만 필터의 기본 구조와 컨셉은 베이즈 필터와 동일합니다. 다만 차이점은 칼만 필터의 수학적인 표현법인데, 칼만 필터는 가우시안을 이용한 베이지안 필터가 아닙니다. 베이즈 필터를 칼만 필터에 적용하기 위해서 가우시안을 히스토그램이 아닌 방법으로 나타낼건데, 베이즈 필터의 기본 공식은 다음과 같습니다.
$\bar{x}$는 사전 확률
$\iota$는 사전 확률 $\bar{x}$가 주어질때 측정에 대한 우도
$f_x$($\cdot$)은 속도를 이용해서 다음 위치를 예측할때 사용하는 모델이 됩니다.
*는 컨볼루션을 의미합니다.
칼만 게인
위에서 x는 사후확률이며 $\iota$와 $\bar{x}$는 가우시안이 됩니다.
그러므로 이 사후확률의 평균은 다음과 같이 정리할 수 있습니다.
다음과 같은 형태로 사전확률과 측정치를 스캐일링을 할수 있는데
여기서 분모가 정규화 시키므로 가중치를 하나에 합치며 K = $W_1$로 정리하면 다음과 같습니다.
칼만 게인에서의 분산은 다음과 같습니다.
K는 칼만게인이라 하며 측정치 $\mu_z$와 예측 평균 $\bar{\mu}$ 사이 값을 얼마나 반영할지 스케일링하는데 사용됩니다.
로봇이 동작하는 환경은 확률론적이기 때문입니다. 로봇과 주위 환경은 (시간에 대한 함수인)결정론적인 모델이 될수 없는데, 현실 세계의 센서들은 에러를 포함하고 있어 그 센서에 대한 평균과 분산으로 나타냅니다. 그래서 앞으로 평균과 분산을 이용한 모델을 다루게 될 것 입니다.
확률 변수의 기대값이란 무엇인가? expectation of a random variable
기대값은 확률의 평균 뿐만이 아니라
연속 영역에서의 형태로도 나타낼 수 있습니다.
import numpy as np
import random
x=[3,1,2]
p=[0.1,0.3,0.4]
E_x=np.sum(np.multiply(x,p))
print(E_x)
멀티모달보다 유니모달로 신뢰도를 나타내는 경우 이점은 무엇인가?
What is the advantage of representing the belief as a unimodal as opposed to multimodal?
움직이는 자동차의 위치를 두 가지 확률로 나타내는건 햇갈리므로 효율적이지는 않습니다.
분산, 공분산, 상관계수
분산
분산은 데이터가 퍼진 정도를 의미하며, 평균은 데이터가 얼마나 많은지를 나타내지는 않습니다.
x=np.random.randn(10)
np.var(x)
공분산
다변수 분포 multivariate distribution인 경우에 사용되는데, 예를 들면 2차원 공간에서의 로봇은 위치를 나타내는데 x, y 값을 사용할겁니다. 이를 나타내기 위해서 평균이 x, y인 정규 분포가 사용됩니다.
다변수 분포에서 평균 $\mu$는 아래의 행렬로 나타낼수 있는데
이처럼 분산도 표현할 수 있습니다.
하지만 중요한 점은 모든 변수들은 그 값에 대해 분산을 가지고 있는 점인데, 각각의 확률 변수들이 어떻게 서로 다른 형태 존재하도록 가능해 집니다. 역시 이 두 데이터셋에는 그들이 얼마나 관련되어있는지를 의미하는 상관 계수와도 관련 있습니다.
예를 들자면 보통 키가 증가하면 몸무게도 증가하는데, 이러한 변수들은 서로 상관관계를 가진다고 할 수 있습니다. 이 값들은 한 변수가 커지면 다른것도 커지므로 양의 상관 관계가 가진것이 됩니다.
이제 다변수 정규분포의 공분산을 공분산 행렬 covariance matrix를 사용해서 다음과 같이 나타내겠습니다.
이 이론에 따르면, 독립 확률 변수 n개 샘플의 평균은 샘플 사이즈를 늘릴수록 정규 분포의 형태가 되는 경향이 있습니다.(일반적으로 n >= 30)
import matplotlib.pyplot as plt
import random
a=np.zeros((100,))
for i in range(100):
x=[random.uniform(1,10) for _ in range(1000)]
a[i]=np.sum(x,axis=0)/1000
plt.hist(a)
가우시안 분포 gaussian distribution
가우시안은 연속 확률 분포 중 하나로 평균 $\mu$와 분산 $\sigma^2$ 두개의 파라미터로 나타내며 정의는 아래와 같습니다.
이는 평균 $\mu$과 표준편차 $\sigma$의 함수로서 종 모양이 되는 정규 분포의 특성을 나타냅니다.
import matplotlib.mlab as mlab
import math
import scipy.stats
mu = 0
variance = 5
sigma = math.sqrt(variance)
x = np.linspace(mu - 5*sigma, mu + 5*sigma, 100)
plt.plot(x,scipy.stats.norm.pdf(x, mu, sigma))
plt.show()
가우시안의 성질 Gaussian Properties
곱 multiplication
베이즈 필터 bayes filter의 측정 갱신 measurement update에서 그 알고리즘은 사전 확률 P($X_t$)와 측정 확률 P($Z_t$ | $X_t$)를 다음의 사후 확률을 구하기 위해 곱하여야 합니다.
여기서 분자 P(Z | X), P(X)는 N($\bar{\mu}$, $\bar{\sigma}^{1}$), N($\bar{\mu}$, $\bar{\sigma}^{2}$)을 따르는 가우시안이 됩니다.
이번 예시는 이변수 가우시안 분포 bivariate gaussian distribution를 시각화하는 예제로 2차원 표면에서 나오는 결과를 3차원으로 사영한 결과를 보여줍니다. 타원에서 가장 깊은 곳은 가장 높은 부분으로 주어진 (x,y)의 최대 확률이 됩니다.
#Example from:
#https://scipython.com/blog/visualizing-the-bivariate-gaussian-distribution/
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
# Our 2-dimensional distribution will be over variables X and Y
N = 60
X = np.linspace(-3, 3, N)
Y = np.linspace(-3, 4, N)
X, Y = np.meshgrid(X, Y)
# Mean vector and covariance matrix
mu = np.array([0., 1.])
Sigma = np.array([[ 1. , -0.5], [-0.5, 1.5]])
# Pack X and Y into a single 3-dimensional array
pos = np.empty(X.shape + (2,))
pos[:, :, 0] = X
pos[:, :, 1] = Y
def multivariate_gaussian(pos, mu, Sigma):
"""Return the multivariate Gaussian distribution on array pos.
pos is an array constructed by packing the meshed arrays of variables
x_1, x_2, x_3, ..., x_k into its _last_ dimension.
"""
n = mu.shape[0]
Sigma_det = np.linalg.det(Sigma)
Sigma_inv = np.linalg.inv(Sigma)
N = np.sqrt((2*np.pi)**n * Sigma_det)
# This einsum call calculates (x-mu)T.Sigma-1.(x-mu) in a vectorized
# way across all the input variables.
fac = np.einsum('...k,kl,...l->...', pos-mu, Sigma_inv, pos-mu)
return np.exp(-fac / 2) / N
# The distribution on the variables X, Y packed into pos.
Z = multivariate_gaussian(pos, mu, Sigma)
# Create a surface plot and projected filled contour plot under it.
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z, rstride=3, cstride=3, linewidth=1, antialiased=True,
cmap=cm.viridis)
cset = ax.contourf(X, Y, Z, zdir='z', offset=-0.15, cmap=cm.viridis)
# Adjust the limits, ticks and view angle
ax.set_zlim(-0.15,0.2)
ax.set_zticks(np.linspace(0,0.2,5))
ax.view_init(27, -21)
plt.show()