규칙 기반 머신러닝의 한계
- 우리가 살고 있는 현실에는 노이즈가 존재하여 관측되므로 원하는 결과를 구하기 힘듬.
우리가 필요한 것들
- 노이즈가 있는 데이터에 더 강건해야하는 방법
- 가설을 더 명확하게 설명할수 있는 방법
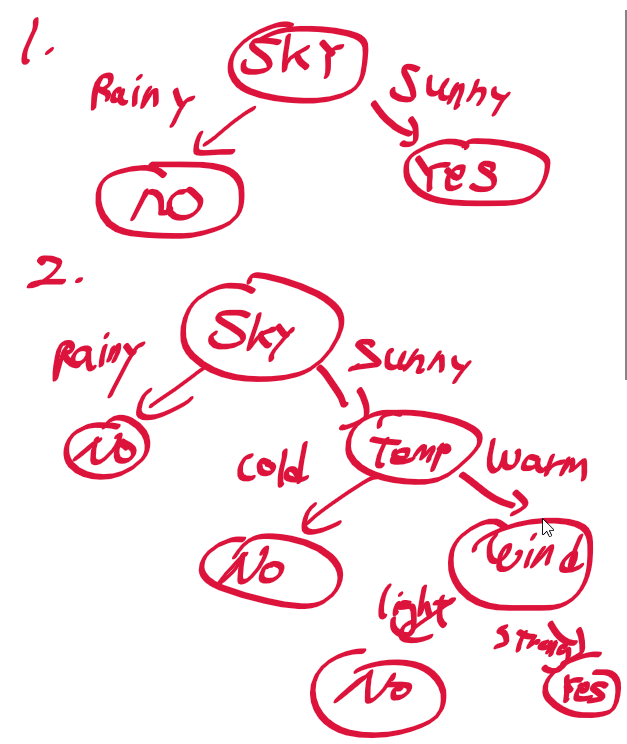
규칙 기반 머신러닝 기법으로 나가 놀지 여부를 결정 트리로 표현 하는 경우
신용 평가 데이터셋을 사용한 머신 러닝
- 신용카드를 발급해줄지 말지를 이 데이터셋으로 판단해보자
- 690개의 인스턴스, 307개의 긍정 케이스(신용 카드 발급)
- ref : http://archive.ics.uci.edu/ml/datasets/Credit+Approval
- 신용 평가 정보 Attribute Information:
A1: b, a.
A2: continuous.
A3: continuous.
A4: u, y, l, t.
A5: g, p, gg.
A6: c, d, cc, i, j, k, m, r, q, w, x, e, aa, ff.
A7: v, h, bb, j, n, z, dd, ff, o.
A8: continuous.
A9: t, f.
A10: t, f.
A11: continuous.
A12: t, f.
A13: g, p, s.
A14: continuous.
A15: continuous.
A16: +,- (class attribute)
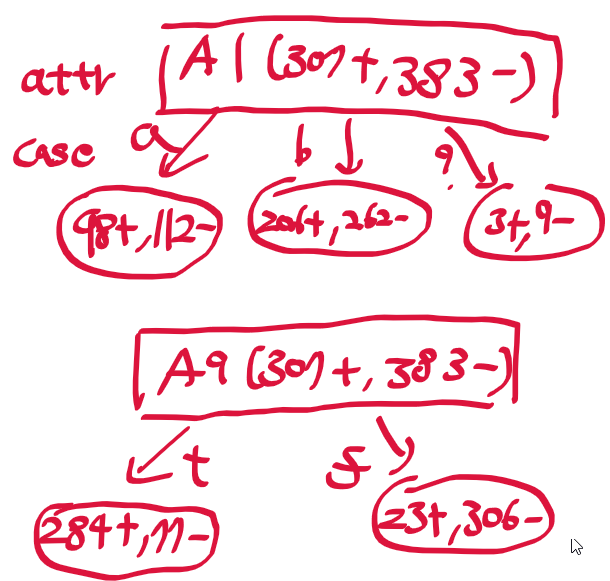
A1속성만으로 판단하는 경우
- A1 속성 값이 a인 경우 98개가 긍정이고, 112개가 부정
- A1 속성 값이 b인 경우 206개가 긍정, 262개가 부정
- A1 속성 값이 알수없음 ?인 경우 3개가 긍정, 9개가 부정
=> 가능한 모든 경우의 총 긍정 307, 총 부정 383
=> A1 속성만으로는 긍정과 부정 여부를 잘 분류하지 못한다고 볼수 있다. 거의 50:50 비율로 판별하므로
A9 속성 만으로 판단하는 경우
- A9 속성 값이 t인 경우 284개가 긍정, 77개가 부정
- A9 속성 값이 f인 경우 23개가 긍정, 306개가 부정
=> A9 속성이 t일때 긍정을 많이 찾고, f일때 부정을 많이 찾는다. => A1 속성보다는 잘 분류해낸다.
'인공지능' 카테고리의 다른 글
| AINIZE를 활용한 ML 프로젝트 배포 (0) | 2021.03.26 |
|---|---|
| [인공지능및기계학습]02.4 엔트로피와 정보 이론 (0) | 2021.01.14 |
| [인공지능및기계학습]02.머신러닝의 기반들 (0) | 2021.01.08 |
| [인공지능및기계학습]01.동기부여 및 기초 (0) | 2021.01.07 |
| 컴퓨터 비전 & 패턴 인식 - 32. 아웃라이어에 대처하는 기하 변환 방법 (0) | 2020.12.16 |