정보 이론 information theory
그동안 패턴 인식에 기반이 되는 확률 이론과 결정 이론에 대한 개념들을 살펴봤고,
이번에는 정보 이론에 대해서 알아보자
이산 확률 변수 x가 주어졌을때 이 확률 변수에는 정보가 얼마나 있는지 궁금할수 있다.
정보의 양은 x를 학습하는 중에 발생하는 놀람의 정도(degree of surpise, 갑작스러운 변화의 정도)로 볼수 있는데
예상치 못한 상황이 많이 발생할수록 그렇지 않은 경우보다 정보가 많다고 할수 있으며
혹은 특정한 상황이 발생하지 않는다면 정보가 없는게 된다.
정보의 양
그래서 정보의 양에 대한 척도는 확률 분포 p(x)에 영향을 받으며
정보의 양을 나타내는 h(x)는 확률 변수 p(x)가 얼마나 단조로운지, 변화가 없는지에 대한 함수라고 할수있겠다.
두 사건 x, y가 전혀 상관관계가 없는 경우 이들로부터 얻을수 있는 정보의 양은
각 정보의 양의 합이되며 h(x, y) = h(x) + h(y)가 된다.
두 사건 x, y는 독립이므로 p(x, y) = p(x) p(y)도 되겠다.
h(x)를 구하는 간단한 방법으로 확률 분포 p(x)에 로그를 취하면 되는데
아래와 같이 음의 부호를 붙임으로서 정보의 양이 양의 값이나 음의 값을 가지게 된다.
* p(x)는 0 ~ 1사이 값을 가지므로, 로그를 취할 시 음수가 되기 때문
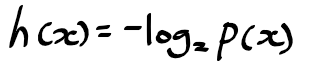
엔트로피 entropy
엔트로피 = 정보의 양에 대한 기대값(정보의 불순 정도)
위 식을 보면 사건 x가 발생할 확률이 적을수록 정보의 양이 크다는 점을 알수 있는데,
h(x)의 단위는 비트 단위이므로, 로그의 밑이 2인 로그를 사용한다.
한번 송신자가 수신자에게 확률 변수 값들을 보내는 경우를 생각해보자.
여기서 보내지는 정보의 평균 양은 확률 분포 p(x)에 대한 위 식의 기대값으로 구할수 있는데 아래와 같다.

이 양을 확률변수 x에 대한 엔트로피라 부른다.
엔트로피와 불순도
지금까지 정보의 정의와 엔트로피에 대해서 살펴보았고, 이 개념이 얼마나 유용한지 알아보자
경우 (1)
확률 변수 x가 8가지 경우가 존재하고, 각각 경우의 확률들은 동일하다고 생각해보자.
* p(x = x1) = 1/8, p(x = x2) = 1/8, ...
x의 값으로 수신자에게 정보를 보낸다고 한다면, 길이가 3비트인 메시지를 전송하면 되겠다.
이 확률 변수의 엔트로피는 아래와 같이 구할수 있다.

하지만 위 경우는 모든 경우의 수가 동일한 확률일 경우를 가정한 경우이고
경우 (2)
8가지 상태 {a, b, c, d, e, f, g, h}가 있을때 각각의 상태의 확률이 {1/2, 1/4, 1/8, 1/16, 1/64, 1/64, 1/64, 1/64}라고 할때
엔트로피는 아래와 같이 구할수 있다.
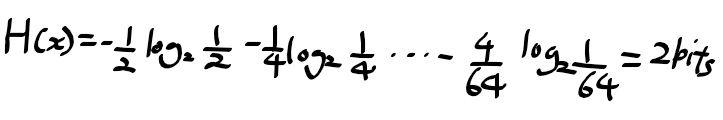
위의 두가지 경우 균일하지 않은 분포일수록 균일한 경우보다 엔트로피 값이 작아진다는것을 알 수 있는데,
이를통해 엔트로피라는 용어가 불순도의 정보를 의미한다는 것을 알수있다.
다시보면
경우 1은 aaabbbcccdddeeefffggg..... 모든 상태가 균일하므로 불순도가 크므로 엔트로피가 크지만
경우 2는 aaaaaaaaaaaaaaaaaabbbbbbbccccddefg같이 불균일하게 되면서 경우 1보다 불순도가 떨어져 엔트로피가 작다
엔트로피로 보는 코드 스트링 해독
상태 값들을 보내는 경우를 생각해보자 8가지의 경우가 존재하므로 3비트 수를 사용하면 좋을것 같지만,
경우 2는 비균일 분포를 따르고 있으므로 많이 발생하는 경우 짧은 코드를 사용하도록하면
전체 코드 길이를 줄일수 있는 장점이 생기게 된다.
{a, b, c, d, e, f, g, h}를
0, 10, 110, 1110, 111100, 111101, 111110, 111111라는 코드 스트링으로 나타내자
통신을통해 보내지는 코드의 평균 길이는
확률 변수의 엔트로피와 동일한 값을 가지게 된다.

여기서 주의해야하는건 이보다 짧은 코드 스트링을 사용해선 안되는데,
연결된 문자열을 부분 부분으로 나눌때, 차이를 구분해야하기 때문이다.
11001110의 경우 110, 0, 1110으로 나누어서 보면 cad로 해독할수 있겠다.
엔트로피와 최단 코드 길이는 동일한 것으로 볼수 있는데,
노이즈리스 코딩 이론에 따르면 엔트로피는 확률 변수 상태들을 전송하는데 필요한 비트 수의 하한이라 할수있다.
다중성 multiplicity와 엔트로피
지금까지 정보의 평균 양으로서 엔트로피를 살펴봤는데,
엔트로피라는 개념은 물리학의 평형 열역학에서 소개되었으며, 이후 통계 분야의 불순도 척도로서 사용되었다.
이제 엔트로피를 몇개의 구간으로 나눌수 있는 N개의 동일한 객체들로서 엔트로피를 살펴보자
객체들을 일정 구간으로 나누는 방법의 수를 생각해보자,
첫번째 물체를 선택할때 N가지의 경우, 두번째 물체의 경우 (N - 1)의 경우
천체 N개의 물체들을 구간화하기위한 전체 경우의 수는 N!가 되겠다.
하지만 물체들을 각 구간별로 구분시키고 싶지 않다면, i번째 구간에 n_i!가지의 정렬하는 경우가 있다고 치고
전체 N개의 물체를 구간별로 배정하는 방법의 수는 아래와 같이 구할수 있으며
이를 다중성 multiplicity라 부른다.

엔트로피는 적절한 상수로 조정된 다중성의 로그로 정의된다.

여기서 N이 무한대로 된다면 n_i/N은 특정 값으로 수렴이되고, Stirling의 근사를 적용하면

아래의 엔트로피에 관한 식을 얻게 된다.

이로부터 상태 x_i를 이산 확률 변수 X의 구간으로 볼수 있으며, p(X = x_i) = p_i가 되고
확률 변수 X의 엔트로피는 아래와 같이 정의가 되겠다.
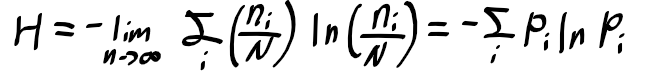
뾰족하게 생긴 p(x_i)에 대한 분포는 작은 엔트로피(불순도가 작음=타 경우의 확률이 적음)값을 가지며,
반대로 높은 엔트로피의 값을 가지는 경우(불순도가 큼=타 경우가 자주발생) 확률 변수의 분포는 균일한 형태를 가지게 된다.

'인공지능' 카테고리의 다른 글
| 컴퓨터 비전 & 패턴 인식 - 10. 연결요소 connected component (0) | 2020.12.13 |
|---|---|
| 컴퓨터 비전 & 패턴 인식 - 9. 패턴인식과 확률분포 (0) | 2020.12.13 |
| 컴퓨터 비전 & 패턴 인식 - 7. 결정 이론 (0) | 2020.12.12 |
| 컴퓨터 비전 & 패턴 인식 - 6. 확률론적 커브피팅 (0) | 2020.12.12 |
| 컴퓨터 비전 & 패턴 인식 - 5. 확률 이론, 최대 가능도 법과 한계 (0) | 2020.12.11 |