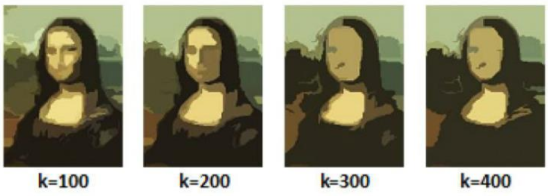
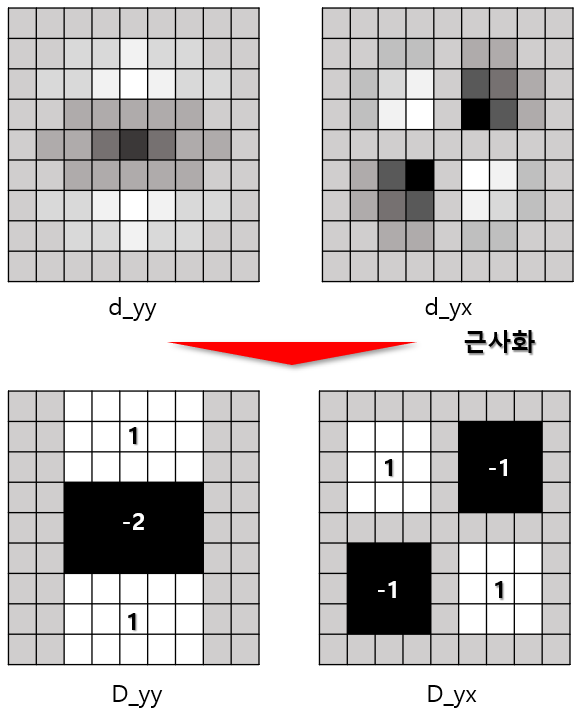
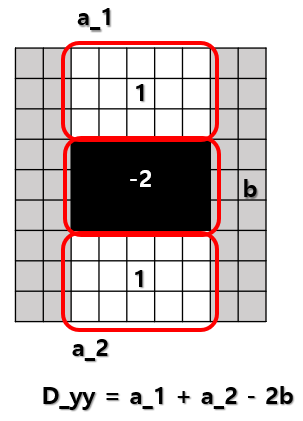
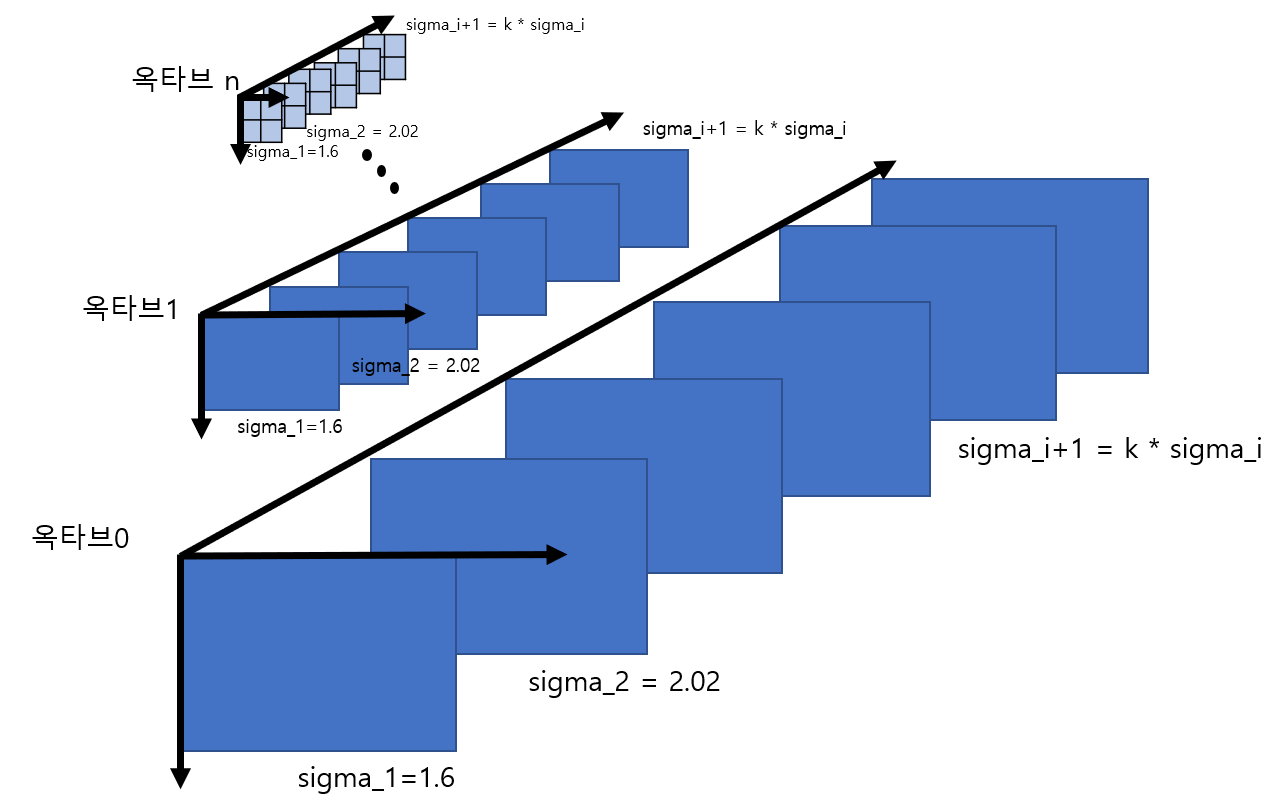
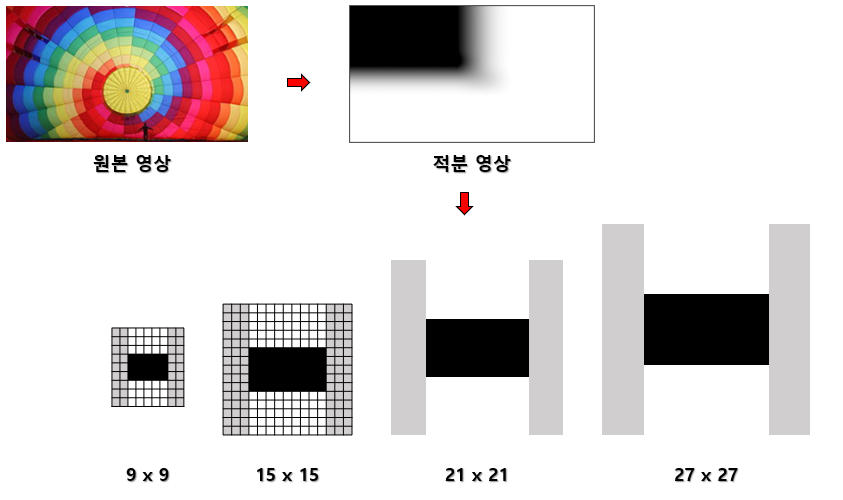
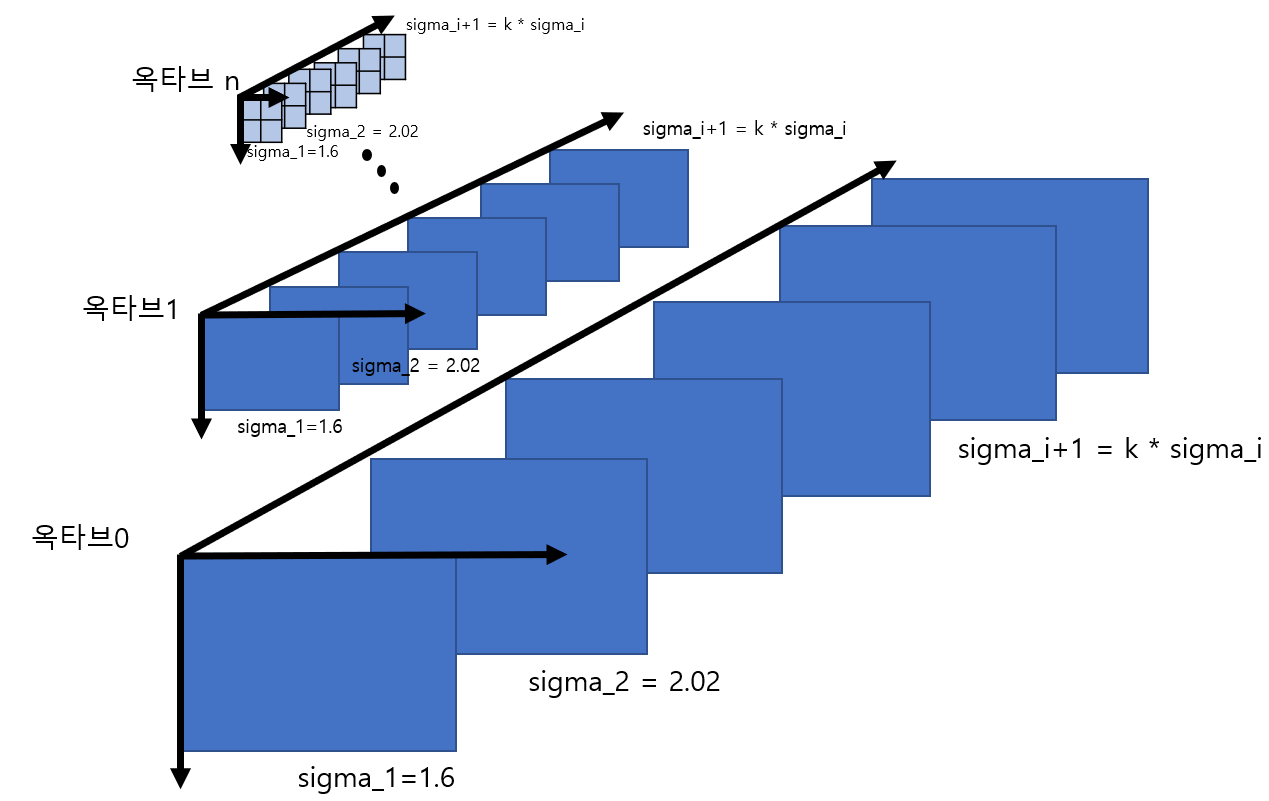
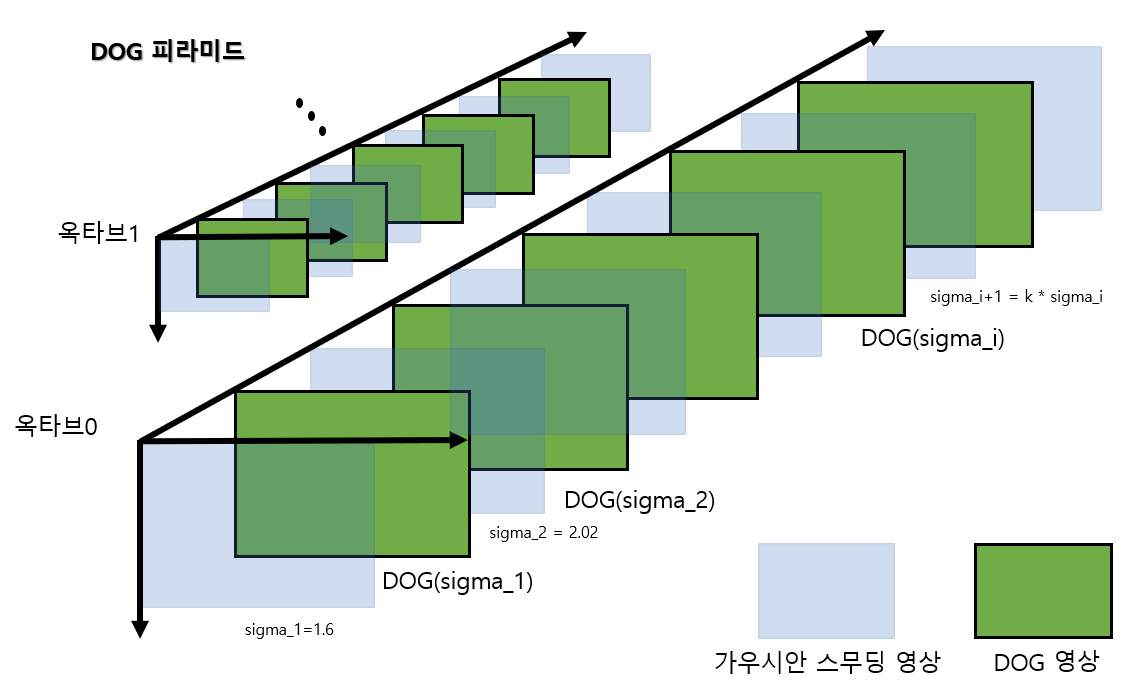
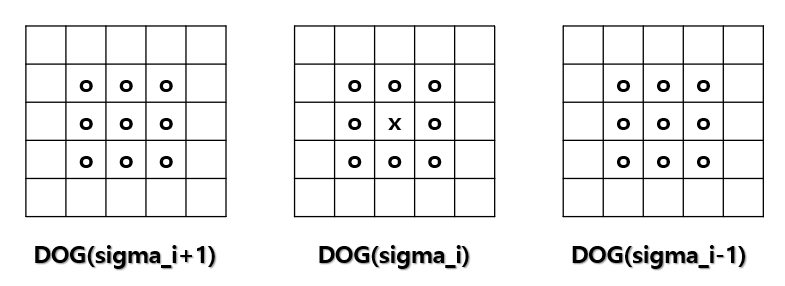
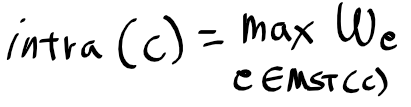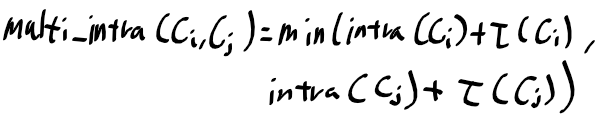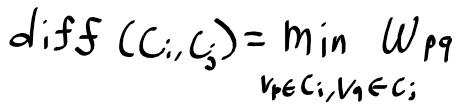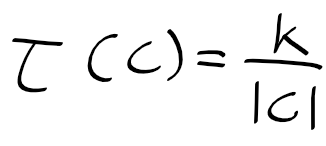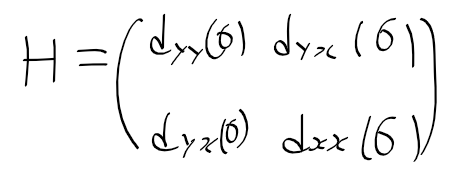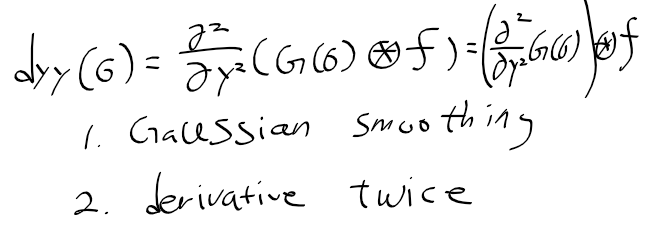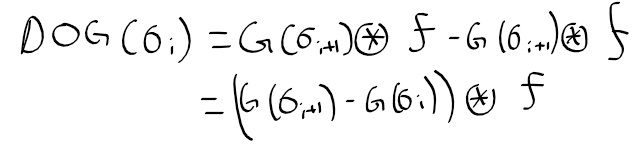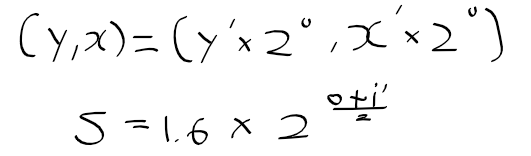컴퓨터 비전 정리를 중간?
공부할 내용들 중 실제로 1/3정도 쯤 온것 같기도 한데
집에서 혼자서 해서 그런가 참 하기가 싫다.
중간 중간에 쉬었다가 하다가 그렇게 나마 반복하고있는데
점점 하기싫어 지는 기분이 커지더라
분명 처음 이 내용을 공부할때보다는 이해되는 부분은 많았다.
오츠 알고리즘 때부터 최적화 기법으로 가장 좋은 이진화 임계치를 찾는다고 하였는데,
통계/대학 수학/공업 수학 공부를 하면서 클래스간 분산이 최대가 되도록 하는 임계치를 찾는 다는 말이 이해가 되더라
이후 내용도 특징 벡터, 기술자라는 용어들이 햇갈렷엇다
키포인트나 기술자나 같은게 아닌가. 싶엇는데
키포인트가 주어지면 이미지 패치로 구한 키포인트와 주변 픽셀에 의한 성질이 키포인트고
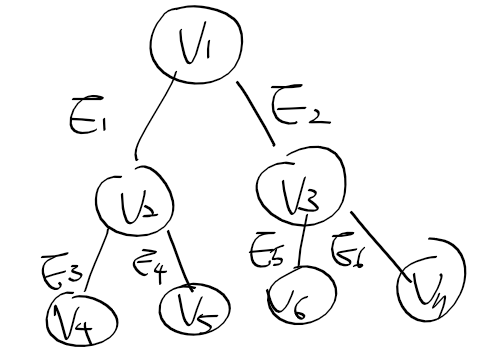
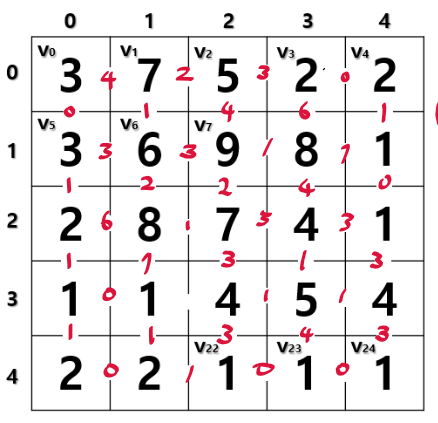
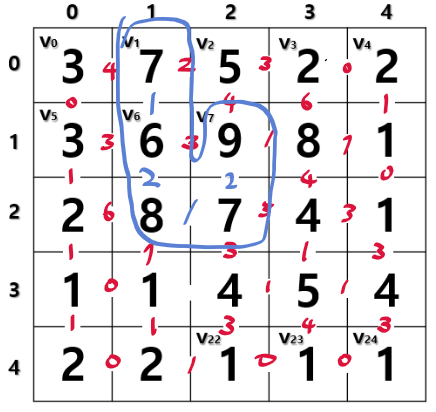
그래프에 대한 내용도 어느정도 이해되기 시작했다.
내가 이전에 이 공부를 여러번 할때마다 힘들었던건
자료구조, 알고리즘, 선형대수, 확률 통계론, 공업 수학 등에 대한
터미놀로지, 개념들에 대한 이해, 빈 틈이 너무 많았기 때문이었던것 같았다.
당장 당장 모르는 개념들 간단히 필요할때마다 보면 잠깐 찾아보면 되겠지 싶었으나
그 개념이 나오기 까지의 배경에 대한 일들이 전혀 모르니
개념에 대한 정의만 알아서는 뭘 할수가 없었다.
이걸 가장 크게 느낀 개념이 최대 우도법인데
이전에 본 서적에서는 최대 우도법이라는 표현을 쓰고있어서
우도 함수를 최대화하는 모수를 찾는 방법 이라는 단순 설명 만으로는 이해하기 힘들었었다.
그런데 확률, 통계론을 공부하는 과정에서
우도를 가능도라는 이름으로 바꿔서 보고, 모수란 무엇인지
확률 분포와 모수의 관계, 빈도론자와 베이지안 관점, 함수의 다변수 미분 그라디언트 등에 대해서 이해하고 나서야
최대 가능도 방법에 대해 완전히 받아들일수 있게 되었다.
이게 컴퓨터 비전을 처음 공부하기 시작한지
2년이 지나서야 가능했다.
지금 이 내용들이 이해가 가면서 다른 문제가 생겼는데
그 동안 시행착오를 하면서 지친것인지,
급한 마음이 없어져선지
열심히 하고싶은 마음이 사라졌고
내가 왜 이걸 하는지 의문이 들더라
학교 다닐때는 어쩔수 없이 공부 해야만 했기 때문에 열심히라도 했었는데
지금은 이 비전 분야를 공부해 나가고싶어서 공부하지만 이전 처럼은 열심히가 되질 않는다.
컴퓨터 비전에서 하고싶은게 무엇인가
내가 우선 컴퓨터 비전 분야에서 하고싶은것들은 다음과 같은 것들이 있겠다.
이미지 매칭
영상 분할
물체 인식
이미지 매칭에 필요한 특징들과 기술자들을 살펴봤고,
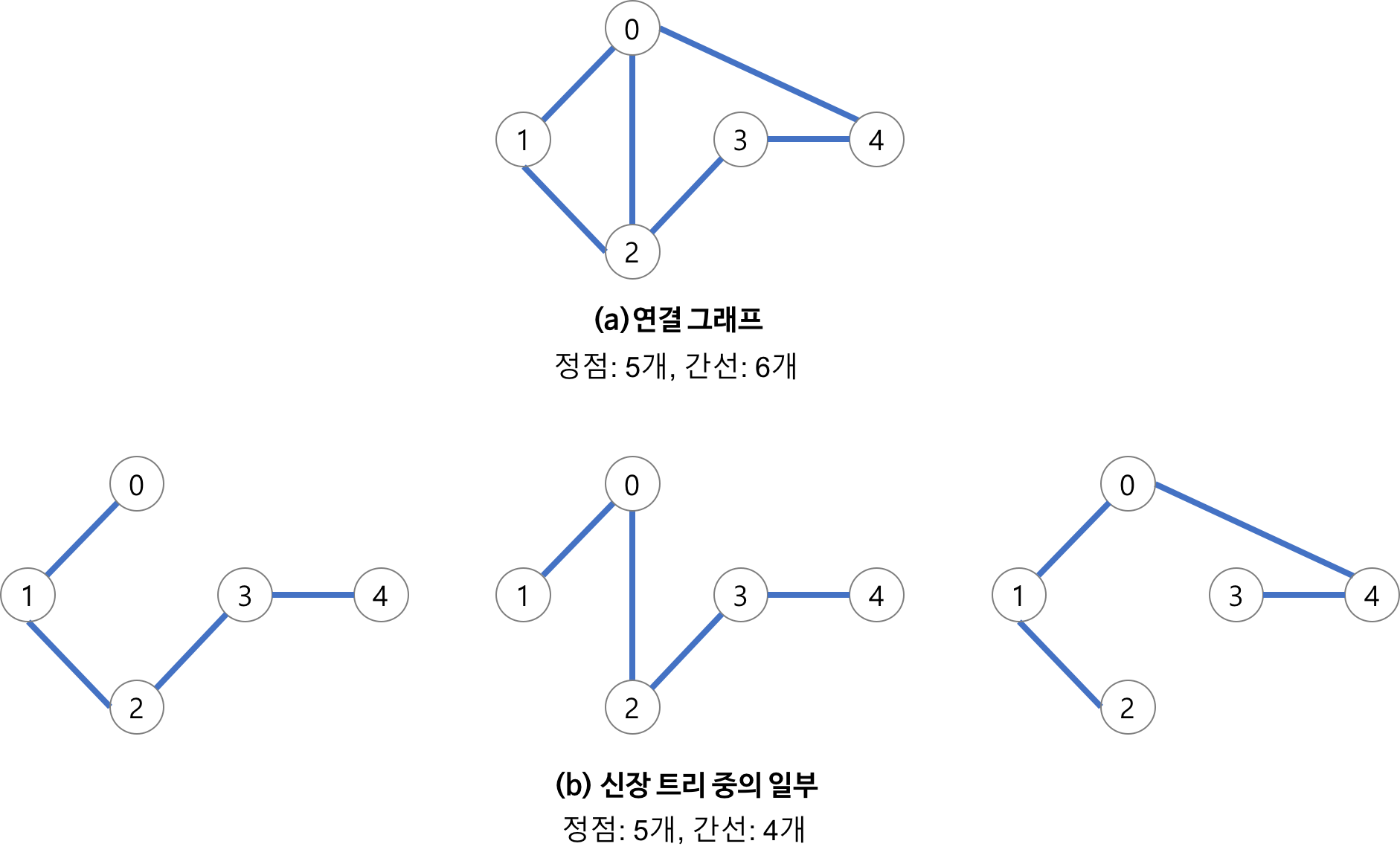
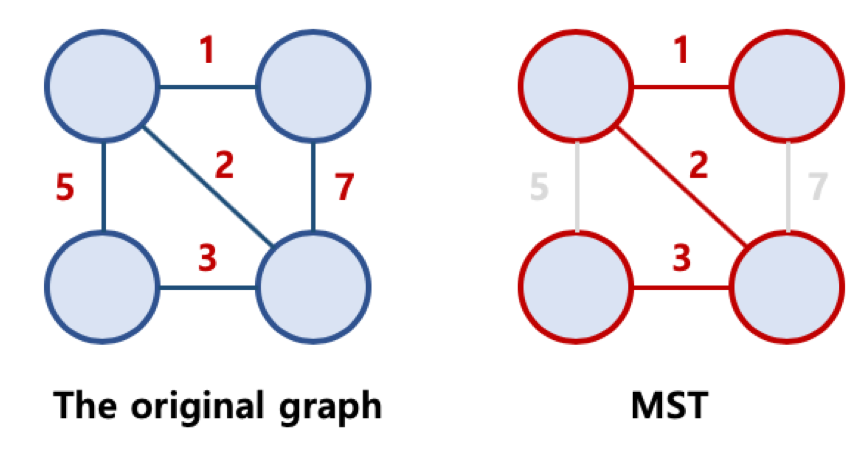
영상 분할의 경우 전통적인 방법과 기본적인 그래프를 이용한 방법을 살펴봤다.
물체 인식의 경우 이전에 단순 분류 cnn가지고 만들어보는 수준이었지 세부적인 분류나 다중 물체인식을 어떻게 하는지
논문 찾아가면서 삽질하다가 포기 했었다.
지금이라면 이해할수 있을것 같긴한데
너무 글만쓰는것 같기도 하고
'인공지능' 카테고리의 다른 글
| 컴퓨터 비전 & 패턴 인식 - 30. kd트리 기반 최근접 이웃 탐색 (0) | 2020.12.16 |
|---|---|
| 컴퓨터 비전 & 패턴 인식 - 29. 이미지 매칭을 위한 거리 척도와 매칭 방법 (0) | 2020.12.16 |
| 컴퓨터 비전 & 패턴 인식 - 27. 대표적인 이진 기술자들 (0) | 2020.12.15 |
| 컴퓨터 비전 & 패턴 인식 - 26. 이진 기술자 (0) | 2020.12.15 |
| 컴퓨터 비전 & 패턴 인식 - 25. SIFT 변형 (0) | 2020.12.15 |