나이브 최근접 이웃 방법, 단순 최근접 이웃 매칭
기본적인 매칭쌍 탐색 방법은 두 영상 사이 모든 점들을 매칭시켜 보는 것으로
1번 영상 특징이 m개, 2번 영상의 특징이 n개인 경우 mn번을 수행함.
대강 이런 식이 되지 않을까 싶다..
아래의 경우 최근접 이웃으로 했는데 조금 수정해서 최근접 거리 비율로 고칠수도 있겠다.
m = len(keypoints1)
n = len(keypoints2)
mlist = []
for i in range(m):
shortest = inf
idx_lst = []
for j in range(n):
dist = get_dist(keypoints1[i], keypoints2[j])
if dist < smallest:
shortest = dist
if shortest < T:
ids_lst.append(j)
match = [i, min(idx_lst)]
mlist.append(match)
하지만 이 방법은 가능한 모든 특징 쌍들에 대해 계산하므로 너무 오랜 시간이 걸리게 된다.
이 외 방법으로 이진 검색 트리를 개조한 kd 트리나 해싱을 이용할수 있겠다.
이진 검색 트리 binary search tree
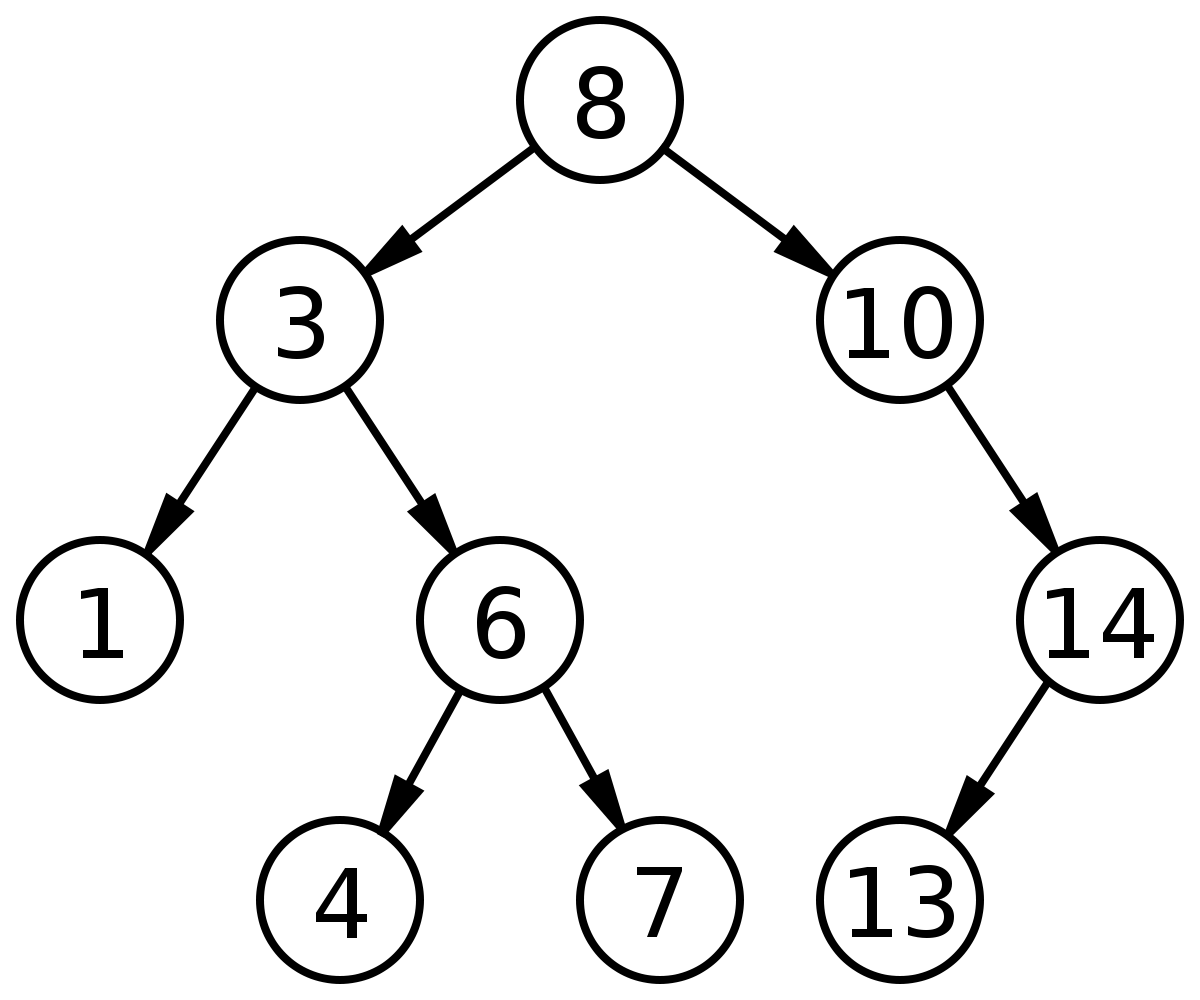
이진 검색 트리는 특정 노드를 기준으로 왼쪽은 작은 값 오른쪽은 큰 값을 가지는 트리를 말한다.
아래의 그림을 보면 값이 8인 루트 노드를 기준으로 왼쪽으로는 8보다 작고, 우측으로는 8보다 큰 값을 노드들이 갖는다.
검색 키를 4라고 지정하면,
1. 8보다 4가 작으므로 왼쪽 노드, 노드 값이 다르므로 한번 더
2. 3보다 4가 크므로 우측 노드, 노드 값이 다르므로 한번 더
3. 6보다 4가 작으므로 좌측 노드, 탐색 완료
이진 검색 트리를 이용해 3번만에 4를 찾을수 있었다.
이를 슈도 코드로 나타내면 아래와 같이 정리할수 있겟다.
트리의 깊이는 log(n)이므로 빅오 표기법으로 O(log(n)) 시간에 검색 마침
t = binary_search(T, v):
if (t = Null):
v가 존재하지 않음
else:
키가 v인 노드 t를 반환
def binary_search(t, v):
if t == Null:
return Null
if t.key == v:
return t
else:
if (v < t.key): # 탐색 값, 키가 현재 노드의키보다 작으면 왼쪽 노드 탐색
return binary_search(t.leftchild, v)
else: # 아니면 우측 자식 노드 탐색
return binary_search(t.rightchild, v)
빠른 특징 기술자 탐색을 위한 자료구조 - kd 트리
이진 트리 탐색 방법을 생각해보면
특징 벡터를 기반한 트리를 만들어 탐색함으로써
모든 특징벡터의 거리를 구해서 비교하는 기존 방법보다 빠르게 탐색할수 있겠다.
하지만 특징 벡터는 이진 트리처럼 1개의 값을 가지는게 아니라
SIFT 기술자는 128차원을 가지니 이에 맞는 트리 생성 알고리즘이 필요하다.
1975년 벤트리는 kd 트리를 제안함.
k dimension을 다루므로 kd 트리라 부르는것 같다.
kd 트리 분할 기준 2가지
1. 분할 축 선택
각 차원 분산 중 최대 분산을 가지는 차원 k를 분할 축으로 선정
2. 분할 기준 선정하기
차원 k 기준 정렬, 중앙값을 분할 기준으로 사용
X = [x_1, x_2, ...]
T = get_kdtree(X)
def get_kdtree(X):
if X == Null:
return Null
else if X == 1: #단일 노드이면
node.vector = X.m
node.leftchild, node.rightchilde = Null
return node
else:
k = 주어진 특징 벡터의 차원들 중에서 최대 분산을 갖는 차원
X_sorted = sort(X, k)
X_left, X_median, X_right = get_divided(X_sorted)
node.dim = k
node.vector = X_median
node.leftchild = get_kdtree(X_left)
node.rightchild = get_kdtree(X_right)
return node
kd 트리를 이용한 최근접 이웃 탐색
새 특징 벡터 x가 주어질 때, 최근접 이웃을 탐색해보자
1. 루트 노드의 분할기준 차윈 k을 확인하다.
2. 입력 벡터의 k차원 값과 루트노드의 기준값을 비교하여 좌측 혹은 우측 자식 노드의 입력으로 보낸다.
위 1과 2를 단일 노드에 도착할때까지 판복한다.
이렇게 탐색한 단일 노드는 항상 최근접이라는 보장은 없음.
다른 트리 가지에 찾아낸 노드 보다 가까운 벡터가 존재할수 있기 때문
개선된 최근접 이웃 탐색
위 방법에서는 반대편 노드를 확인하지 못해, 분명하게 최근접인지 확인할수 없음.
현재까지 탐색한 노드들을 스택에 저장 -> 깊이 방향 탐색 수행
리프 노드 도착시 백트래킹 수행 -> 입력 벡터 x와 스택에서 꺼낸 노드 t의 특정 차원 오차가 최근접 거리보다 작은경우
=> 노드 t의 반대편에 더 가까운 노드가 존재할 가능성이 있음. 재귀 탐색 수행
이 방법은 노드가 많더라도 log(n)으로 빠른 탐색이 가능,
하지만 특징 벡터의 차원이 10차원 이상일 경우 모든 특징벡터를 수행하는것과 비슷해져 성능이 떨어짐.
#지나온 노드를 저장할 스택 생성
stack s = null;
# 현재 최근접 거리
current_best = inf
# 현재 최근접 노드
nearest = Null
search_kdtree(T, x)
def search_kdtree(T, x):
t = T
# 리프 노드가 아니면
while is_leaf(t) == False:
# 현재 차원기준, x가 현재노드보드 작다
# 오른쪽 자식 노드는 스택에 대입
# 왼쪽 자식노드는 t에 대입
if x[t.dim] < t.vector[t.dim]
s.push(t, "right")
t = t.leftchild
else
s.push(t, "left")
t=t.rightchild
# 현재 노드 t와 x 거리 계산
d = dist(x, t.vector)
if d < current_best:
current_best = d
nearest = t
#거쳐온 노드에 대해 최근접 가능성 여부 확인
while s != null:
t1, other_side = s.pop()
#입력 벡터 x와 거쳐온 벡터 t1의 거리 계산
d = dist(x, t1.vector)
#거쳐왔던 벡터 t1이 최적이라면, 현재 최근접 거리와 벡터 변경
if d < current_best
current_best = d
nearest = t1
# (벡터 x의 어느 차원의 값 - t1의 어느 차원 값) < current_best
# t1의 반대편 t_other에 보다 가까운 점이 존재할 가능성이 있음.
if (x, t1.vector)의 분할 평면까지 거리 < current_best:
t_other = t1의 other_side 자식 노드
search_kdtree(t_other, x)
kd 트리를 이용한 근사 최근접 이웃 탐색
최근접 이웃이거나 가까운 이웃(근사 최근접 이웃 approximate nearest neighbor)을 찾는 방법
위 방법에서 스택 대신 우선 순위 큐인 힙을 사용
x로부터 거리가 우선순위로 이용됨.
-> 거쳐온 순서대로 백트래킹을 수행한 스택과 달리, 가장 거리가 가까운 노드부터 수행
추가로 try_allowed로 조사 횟수제한
#지나온 노드를 저장할 힙 생성
heap s = null;
# 현재 최근접 거리
current_best = inf
# 현재 최근접 노드
nearest = Null
# 비교 횟수
try = 0
search_kdtree(T, x)
def search_kdtree(T, x):
t = T
# 리프 노드가 아니면
while is_leaf(t) == False:
# 현재 차원기준, x가 현재노드보드 작다
# 오른쪽 자식 노드는 스택에 대입
# 왼쪽 자식노드는 t에 대입
if x[t.dim] < t.vector[t.dim]
s.push(t, "right")
t = t.leftchild
else
s.push(t, "left")
t=t.rightchild
# 현재 노드 t와 x 거리 계산
d = dist(x, t.vector)
if d < current_best:
current_best = d
nearest = t
try++
#지정한 횟수만큼 우선순위 노드를 백트랙킹으로 탐색 후에는 종류
if try > try_allowed:
탐색 종료
#거쳐온 노드에 대해 최근접 가능성 여부 확인
while s != null:
t1, other_side = s.pop()
#입력 벡터 x와 거쳐온 벡터 t1의 거리 계산
d = dist(x, t1.vector)
#거쳐왔던 벡터 t1이 최적이라면, 현재 최근접 거리와 벡터 변경
if d < current_best
current_best = d
nearest = t1
# (벡터 x의 어느 차원의 값 - t1의 어느 차원 값) < current_best
# t1의 반대편 t_other에 보다 가까운 점이 존재할 가능성이 있음.
if (x, t1.vector)의 분할 평면까지 거리 < current_best:
t_other = t1의 other_side 자식 노드
search_kdtree(t_other, x)
'인공지능' 카테고리의 다른 글
| 컴퓨터 비전 & 패턴 인식 - 32. 아웃라이어에 대처하는 기하 변환 방법 (0) | 2020.12.16 |
|---|---|
| 컴퓨터 비전 & 패턴 인식 - 31. 기하 변환과 최소 제곱법 (0) | 2020.12.16 |
| 컴퓨터 비전 & 패턴 인식 - 29. 이미지 매칭을 위한 거리 척도와 매칭 방법 (0) | 2020.12.16 |
| 컴퓨터 비전 & 패턴 인식 - 28. 중간 (0) | 2020.12.16 |
| 컴퓨터 비전 & 패턴 인식 - 27. 대표적인 이진 기술자들 (0) | 2020.12.15 |