이번에는 비디오에서 물체를 찾고 추적하는 알고리즘인 민시프트와 캠시프트 알고리즘을 배워보자
민시프트
- 민시프트의 개념은 간단합니다. 점들의 집합이 존재하는데(히스토그램 역전파 같은 픽셀 분포가 있다고 합시다), 여기다가 작은 원형 윈도우를 주고, 이 윈도우가 픽셀 밀도가 최대인 방향으로 이동시킵니다(점들의 개수가 최대인 지점). 이를 나타내면 아래와 같습니다.
초기 윈도우는 파란색 원으로 여기서 c1이라고 하겠습니다. 이 원의 중심은 파란색 사각형으로 c1_o라 하겠습니다. 이 윈도우 안에서 중심점을 찾는다면 c1_r로 작은 원으로 그리겠고, 실제 윈도우의 중심이라 할수 있습니다.
원의 중심과 점들의 중심이 맞지 않으면 윈도우는 이동하고, 새로운 윈도우의 중심은 이전의 센트로이드와 동일해질겁니다(c1_r이 새로운 중심점이 됨). 다시 새로운 센트로이드를 찾고 이동하는게 반복됩니다.
아마 매치가 되지않는다면 다시 이동하윈도우의 중심이 반복되는 결과 같은 지점으로 수렴하게 됩니다. 결과적으로 픽셀 분포가 최대가 되는 지점에 윈도우는 존재하게 됩니다. 이를 녹색선으로 그리고 c2라 하겠습니다. 위에서 보시다시피 이 곳이 점들이 최대가 되는 지점이라 할수 있습니다. 전체적인 과정은 아래의 이미지에서 볼수 있겠습니다.
히스토그램 역투영 영상과 초기 목표 위치를 통과할거고, 물체가 움직인다면 히스토그램 역투영 영상에서 반영될겁니다. 그 결과 민시프트 알고리즘은 윈도우를 이동시키고 결과적으로 최대 밀도가되는 지점에 도착하게 됩니다.
opencv meanshift
- opencv에서 민시프트를 하려면 우선 타겟을 설정해야합니다. 그리고 그 타겟의 히스토그램을 구해야 타갯의 역투영을 할수 있고 민시프트 계산이 가능해집니다. 그리고 초기 윈도우의 위치가 필요합니다. 히스토그램에서는 hue만 고려할수 있으니 저조도에 의한 거짓 값을 피하기 위해서 cv2.inRange()함수로 저조도 값들을 제거하겠습니다.
캠시프트
조금전 결과를 자세히 보셧나요? 여기선 문제가 있는데 윈도우가 항상 차가 밖에 나갈때까지도 같은 크기로 되어 카메라 가까이 까지 따라옵니다. 이건 좋지 않으니 윈도우 크기를 타겟의 크기와 회전에 따라 조절해주어야 합니다. 그래서 opencv 연구실에서 CAMshift (continuosly adaptive meanshift)라는 방법을 제안하였습니다.
처음에는 민시프트를 적용합니다. 민시프트가 수렴하고나면, 윈도우 크기를 아래와 같이 조절해줍니다. 이것은 최적의 타원 방향을 계산해 줍니다.
다시 새로운 스케일된 탐색 윈도우와 이전 윈도우 위치로 민시프트를 적용하고고 이를 반복하면 아래와 같이 정밀한 결과를 얻을수 있습니다.
이제 민시프트랑 동일하게 캠시프트를 적용해보겠습니다. 하지만 여기서는 회전된 사각형과 박스 파라미터(다음 반복에 사용할)를 반환해 줍니다.
import numpy as np
import cv2
cap = cv2.VideoCapture('./res/slow.mp4')
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 135,90,270,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# Draw it on image
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame,[pts],True, 255,2)
cv2.imshow('img2',img2)
cv2.imshow('dst',dst)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k)+".jpg",img2)
else:
break
cv2.destroyAllWindows()
cap.release()
다음 이미지는 캠시프트 한 결과를 보여주는데 아래는 히스토그램 역투영 영상 위는 캠시프트 결과를 보여주고 있습니다.
이번에는 피처 매칭과 호모그래피 탐색을 이용하여 복잡한 이미지상에 있는 물체를 찾아보겠습니다.
지난 시간는 쿼리 이미지를 사용해서 다른 훈련 이미지상에 존재하는 특징점들을 찾았습니다. 정리하자면 다른 이미지에 존재하는 물체 일부의 위치를찾은것이라 볼수 있겠습니다. 이 정보가 있으면 훈련 이미지 상에 존재하는 물체를 찾기에 충분합니다.
그러기 위해서 이번에는 calib3d 모듈에서 cv2.findHomography() 함수를 사용해보겠습니다. 두 이미지 상에서 점집합을 찾았다면 이제 그 물체의 원근 변환을 얻을수 있습니다. 그러고나서 cv2.perspectiveTransform()으로 물체를 찾겠습니다. 이 변환을 얻기 위해서는 4개의 올바른 점들이 필요합니다.
매칭하는 중에 결과에 영향을 주는 에러들이 존재할수도 있지만, 이 부분은 RANSAC이나 LEAST_MEDIAN(플래그로 설정가능)을 사용해서 해결하겠습니다. 좋은 매치를 인라이어라 하고, 아닌것을 아웃라이어라 부르겠습니다. cv2.findHomography()는 인라이어와 아웃라이어 포인트들을 정리하는 마스크를 반환해줍니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10
img1 = cv2.imread('./res/box.png',0) # queryImage
img2 = cv2.imread('./res/box_in_scene.png',0) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1,des2,k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
if len(good)>MIN_MATCH_COUNT:
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
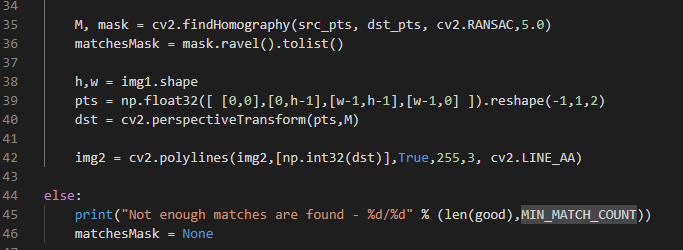
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
h,w = img1.shape
pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
else:
print("Not enough matches are found - %d/%d" % (len(good),MIN_MATCH_COUNT))
matchesMask = None
draw_params = dict(matchColor = (0,255,0), # draw matches in green color
singlePointColor = None,
matchesMask = matchesMask, # draw only inliers
flags = 2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
plt.imshow(img3, 'gray'),plt.show()
우선 찾은 물체에 존재하는 10개의 매치들을 구합니다. 충분히 매치들을 찾았다면, 두이미지에 존재하는 매치된 키포인트의 위치들을 추출하겠습니다.
이제 이 매치들을 사용해서 원근 변환을 찾아보겠습니다. 3 x3 크기의 변환 행렬을 얻을건데, 이 행렬을 사용해서 쿼리 이미지의 키포인트(코너)들을 훈련 이미지 상에 대응지점으로 변환시킬수 있습니다.
findHomography로 변환 행렬을 구하고, 쿼리 이미지의 코너들을 원근 변환 행렬로 훈련 이미지 상에 나타내고 이를 직선으로 이어줍시다.
브루트 포스 매처는 단순합니다. 첫 집합에서 하나의 특징 기술자를 주어지면 거리 계산 방법으로 두번째 집합에 존재하는 모든 특징들과 매치시켜봅니다. 그리고 가장 가까운것을 반환해줘요.
BF 매처에서는 처음 BF매처를 생성시키고 (cv2.BFMatcher())) 여기서 2개의 옵션 파라미터를 줄수 있습니다. 첫번째 옵션은 거리 측정 방법을 명시해주는데 넘어가고, 두번쨰 파라미터는 교차 검증을 하는것으로 기본적으로 false로 되어있습니다.
매처에서는 A 집합에서 i번째 기술자와 B 집합에서 j번째 기술자가 서로 잘맞는지 매치 결과를 반환해주는데, 같은 집합에 대해 두 특징을 한다면 서로 잘 될거고 일관된 결과를 보여줄겁니다.
일단 매처가 만들어지고 나면, 두 중요한 방법으로 BFMatcher.match()와 BFMatcher.knnMatch()가 있습니다. 첫번째는 최적의 매치를 반환하고, 두번째는 사용자가 지정한 k개만큼의 최적의 매치를 반환해줍니다. 하고싶은 데로 하시면 되겠습니다.
그 다음 키포인트를 그리기 위해서 cv2.keypoints()를 사용했지만 cv2.drawMatches()를 사용해서 매치를 그릴수가 있겠습니다. 이걸 사용하면 두 이미지가 평행하게 놓여지고, 첫번쨰 이미지에서 두번째 이미지로 최적의 매치를 하는 선을 그려줄겁니다. k개의 최적 매치에 대해서 cv2.drawMatchsKnn도 사용할수 있겠습니다.
이제 SURF와 OR의 예시를 한번 보겠습니다
ORB 기술자를 이용한 브루트포스 매칭
두 이미지 사이 피처를 매칭시키는 간단한 예시를 보겠습니다. 이 경우에서 쿼리 이미지와 훈련 이미지가 있는데요. 피처 매칭을 사용해서 트레이닝 이미지에 쿼리 이미지가 어디있는지 찾겠습니다.
우선 시프트 기술자를 사용해서 피처를 매치시켜보겠씁니다. 여기서 이미지를 읽고 기술자를 찾겠습니다.
다음으로 할일은 BFMatcher 객체를 생성해서 거리는 cv2.NORM_HAMMING그리고, 더나은 결과를 얻도록 crossCheck를 해줍시다.
10개를 찾아 띄워주면 아래의 결과를 얻을수 있겠습니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./res/box.png',0) # queryImage
img2 = cv2.imread('./res/box_in_scene.png',0) # trainImage
img3 = img1
# Initiate SIFT detector
orb = cv2.ORB_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# create BFMatcher object
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1,des2)
# Sort them in the order of their distance.
matches = sorted(matches, key = lambda x:x.distance)
# Draw first 10 matches.
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10], img3,flags=2)
plt.imshow(img3),plt.show()
플란 기반 매처 FLANN based Matcher
FLANN은 Fast Library for Approximate Nearest Neighbors를 말하며, 크고 고차원 데이터에서 고속 최근접 탐색을 위해 최적화된 알고리즘들의 집합을 가지고 있습니다. 많은 데이터셋에서 BFMatcher보다 더 빠르게 동작하므로 이번에는 플란 기반 매처를 사용해보겠습니다.
플란 기반 매처를 사용하려면, 어떤 알고리즘을 사용할지 명시하는 딕셔너리 두개가 필요합니다. 첫번째는 인덱스 파라미터로 FLANN 문서에 자세히 설명되어있습니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./res/box.png',0) # queryImage
img2 = cv2.imread('./res/box_in_scene.png',0) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# Need to draw only good matches, so create a mask
matchesMask = [[0,0] for i in range(len(matches))]
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
plt.imshow(img3,),plt.show()
OpenCV 연구자로서 가장 중요한 것중 하나로 ORB를 꼽을수 있겠습니다. 이 알고리즘은 Ethan Rublee이 ORB: SIFT나 SURF의 효율적 대안(ORB:An efficient alternative to SIFT or SURF) 이라는 논문에서 2011년에 소개되었습니다.
이 논문 내용은 SIFT나 SURF보다 비용 계산과 매칭 성능 측면에서 좋은 대안임을 보여주고 있습니다. 특히 SIFT와 SURF는 특허로 되어있어 비용을 지불해야되지만 ORB는 그런게 없슴다.
ORB는 기본적으로 FAST 키포인트 검출기와 BRIEF 기술자를 조합하여 성능을 개선한 변형물이라 할수 있겠습니다. 먼저 FAST로 키포인트를 찾아내고, 그다음 맨 위에 있는 N개의 점들을 찾기위해 해리스 코너를 사용하겠습니다. 여기서 멀티 스케일 피처를 만들도록 피라미드를 사용할수도 있겠습니다.
여기서 문제는 FAST는 방향을 계산하지 않는것인데 어떻게 회전 불변이 가능할까요? 저자는 여기서 변형을 해주었습니다.
ORB에서는 코너를 가진 패치 중심의 가중화된 강도를 계산하고, 이 코너점에서 중앙으로 향하는 벡터의 방향을 방위로 보고 있습니다. 회전 불변량을 개선하기 위해서, 반지름의 r인 원형 공간에 존재하는 x와 y에 대한 모멘트를 계산하겠습니다.
이제 기술자를 넘어와서보면 ORB는 BRIEF 기술자를 사용하고 있습니다. 하지만 BRIEF는 회전 변화에 좋지 않은 성능을 보이고 있어, 키포인트의 방향에 따라 브리프를 회전시켜줍니다.
위치 (x_i, y_i)에서 n개의 이진 특징 집합에 대해 테스트를 하기 위해 2 x n 형태의 행렬 S(이 픽셀들의 좌표)를 정의하겠습니다.
ORB는 각도를 2pi/30 (12개)로 이산화시키고, 미리 계산한 BIREF 패턴의 룩업 테이블을 만들어 줍니다. 키포인트 방향 theta가 일관될수록 올바른 점들의 집합 S_theta가 이 기술자를 계산하는데 사용되겠습니다.
BRIEF는 각 비트 특징들이 고분산과 평균이 0.5정도 되는 특성을 가지고 있습니다. 하지만 키포인트 방향으로 향하면 기존의 속성을 잃어버리고 더 분산됩니다. 여기서 고 분산인 경우 입력에 대해 다르게 반응하여 특징을 더 차별하게 만들어 버립니다.
다른 바람직한 특성은 각 테스트들은 결과에 영향을 주기 때문에 테스트의 상관관계를 해재하여야 합니다. 이를 위하여 ORB는 탐욕 탐색을 하여 모든 가능한 이진 시험을 수행하여 고분산과 평균이 0.5, 상관관계가 없는 값들을 찾으며 이를 rBRIEF라 합니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('./res/simple.jpg',0)
img2 = img
# Initiate STAR detector
orb = cv2.ORB_create()
# find the keypoints with ORB
kp = orb.detect(img,None)
# compute the descriptors with ORB
kp, des = orb.compute(img, kp)
img = cv2.drawKeypoints(img,kp,img)
# draw only keypoints location,not size and orientation
img2 = cv2.drawKeypoints(img2,kp,img2, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
plt.subplot(121), plt.imshow(img)
plt.subplot(122), plt.imshow(img2)
plt.show()
지난 시간에 SIFT 기술자가 128차원의 벡터로 되어있다고 했습니다. 한 키포인터의 경우 여기서 부동 소수점을 사용하기 떄문에 기본적으로 512바이트를 차지하고 있고, SURF의 경우 (64차원이므로) 256바이트를 차지하게 됩니다.
그렇다보니 수천개의 특징 백터를 생성하는경우 많은 공간을 차지하게되고 제한된 자원을 가진 경우 실행하기 힘든 문제가 있습니다. 그리고 메모리가 더 많이 필요할수록 매칭하는데 더 많은 시간이 걸리게 되기도 하구요.
하지만 이런 모든 차원들이 실제 매칭하는데 필요한건 아닙니다. 주성분 분석 PCA나 선형 판별 분석 LDA같은 방법으로 그걸 압축시킬수도 있고, LSH Locality Sensitive Hashing을 사용하여 SIFT 기술자를 이진 문자열로 만들수도 있겠습니다. 이러한 이진 문자열들은 해밍 거르로 피처 매칭하는데 사용되기도 하는데 이를 통해 고속화가 될수 있기 때문입니다. 하지만 우선 기술자를 찾아야 해싱이 가능하니 메모리 문제를 해결한다고는 하기 어렵습니다.
BRIEF는 이 개념을 사용한건데, 기술자를 찾지 않은 상태에서 바로 이진 문자열을 찾아내는 방법이라 할수 있습니다. 이 방법에서는 스무스해진 이미지 패치를 가지고 위치 쌍 n_d(x, y)집합에서 선택합니다. 그러고 나서 일부 픽셀 강도 비교가 됩니다.
예를 들자면 첫 위치 쌍을 p, q라 하겠습니다. 만약 I(p) < I(q)이면 결과를 1 아니면 0으로 하겠습니다. n_d 위치쌍에 존재하는 모든 픽셀들에다가 사용하면 n_d 차원의 비트문자열을 얻게 됩니다.
n_d는 128, 256, 512바이트(길이로 16, 32, 64)가 될수 있으며 opencv에서는 모두 사용가능합니다. 하지만 기본 값으로는 256으로 설정되어있어요. 이 비트스트링을 얻으면 이 기술자들을 매칭시키는데 해밍 거리를 사용할수 있겠습니다.
중요한 점은 BRIEF는 특징 기술자이지, 특징을 찾는데 어떠한 방법을 제공하고 있지는 않습니다. 그래서 SIFT, SURF 같은 다른 특징 검출기를 사용해야 합니다.
정리하자면 BRIEF는 빠른 특징기술자를 계산하고 매칭하는 방법이라 할수 있겠고, 큰 이미지 회전만 아니라면 좋은 인식성능을 얻을수가 있겠습니다.
정리하면
- 일단 BRIEF는 특징 기술자 종류 중 하나
- SIFT나 SURF 기술자들은 너무 커서 실시간으로 돌리기힘듬
- 알고리즘 이해하기는 어려우나 키포인트에 대한 이진 문자열을 만드는데, 키포인트 주위 쌍으로 이진값을 할당
- 이렇게 만든 비트스트링으로 나중에 매칭시 해밍 거리를 구하는데 사용 가능
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('./res/home.jpg',0)
img2 = np.copy(img)
img3 = np.copy(img)
# Initiate FAST object with default values
surf = cv2.SIFT_create()
#find keypoints and descriptors directly
surf_kp, surf_desc = surf.detectAndCompute(img, None)
# Initiate BRIEF extractor
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create()
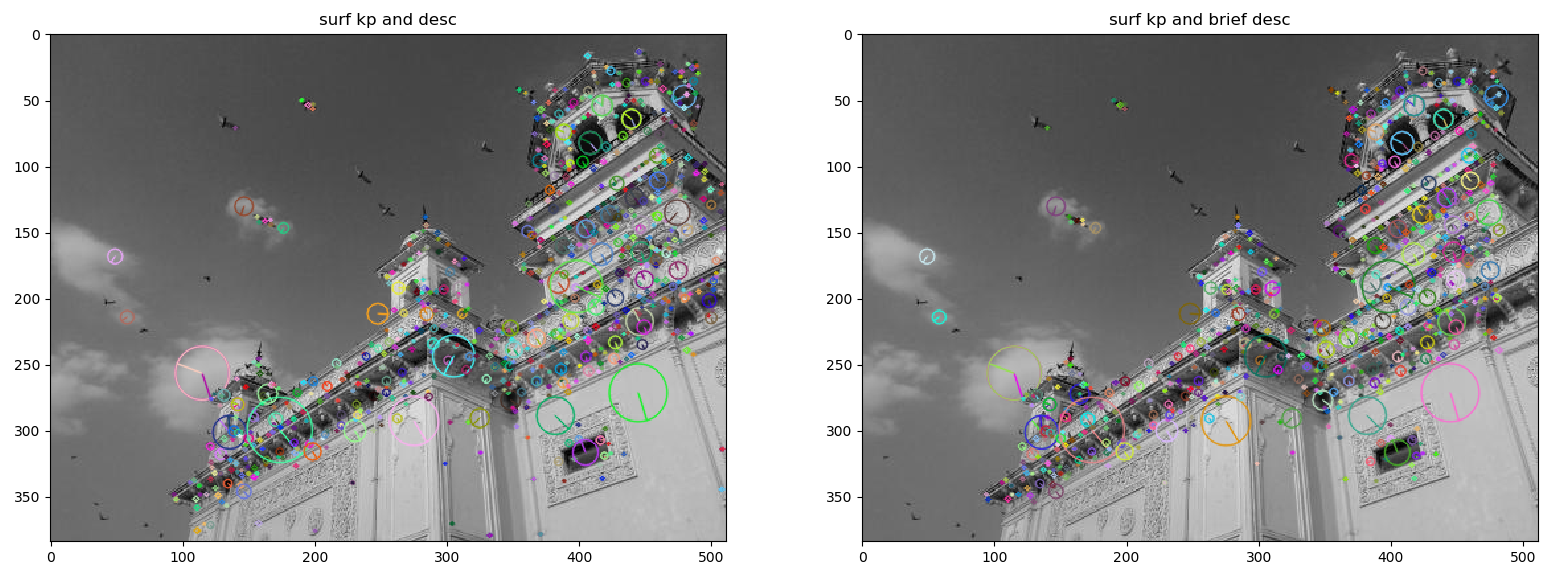
img2= cv2.drawKeypoints(img2, surf_kp, img2,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
print("surf_desc.shape : ", surf_desc.shape)
# compute the descriptors with BRIEF
brief_kp, brief_desc = brief.compute(img, surf_kp)
img3= cv2.drawKeypoints(img3, brief_kp, img3,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
print("brief_desc.shape : ", brief_desc.shape)
plt.subplot(121), plt.imshow(img2)
plt.subplot(122), plt.imshow(img3)
plt.show()
이전에 본 특징 검출기들은 대부분 좋지만, 실시간 어플에서 사용하기에는 충분히 빠르지는 않습니다. 그래서 SLAM에서 사용하기 좋은 알고리즘으로 FAST가 있습니다.
FAST Feature from Accelerated Segment Test 알고리즘은 에드워드 로스텐과 톰 드루몬드가 2006년에 재안했는데요. 이알고리즘을 간략하게 정리해보겠습니다.
FAST를 이용한 특징검출
1. 관심점 특정 픽셀 p를 선택하고, 이 픽셀의 강도를 I_p라 합시다.
2. 적절한 임계치 t를 설정해 줍시다.
3. 테스트할 p 주위의 16개의 픽셀을 선정합니다.
4. 위 이미지의 원에서 I_p +t보다 더 밝은 n개의 연결된 픽셀들이 존재하거나 I_p - t 보다 어두운 n개의 연결댜ㅚㄴ 픽셀들이 존재한다면 픽셀 p는 코너라고 판단하겠습니다. 위 예시에서 n은 12가 됩니다.
5. 여기다가 코너가 아닌경우를 제거하기 위해서 고속의 테스트가 진행됩니다. 이 테스트에서는 4개의 픽셀만 조사하는데요 1, 9, 5, 13번 픽셀을 보고, 이들이 더 밝은지 어두운지 보겠습니다. p가 코너라면 적어도 3개는 I_p + t보다 밝거나 I_p -t보다 어두울 겁니다. 하지만 아니라면 p는 코너가 아니라고 할수 있겠습니다. 이 점 p주위의 모든 픽셀들에대해서 수행할수도 있겠지만 고성능을 내기에는 부족하지만 이렇게 사용합니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('./res/home.jpg',0)
img2 = img
# Initiate FAST object with default values
fast = cv2.FastFeatureDetector_create()
# find and draw the keypoints
kp = fast.detect(img,None)
img2 = cv2.drawKeypoints(img, kp,img2, color=(255,0,0))
plt.subplot(121), plt.imshow(img, cmap="gray")
plt.subplot(122), plt.imshow(img2)
plt.show()