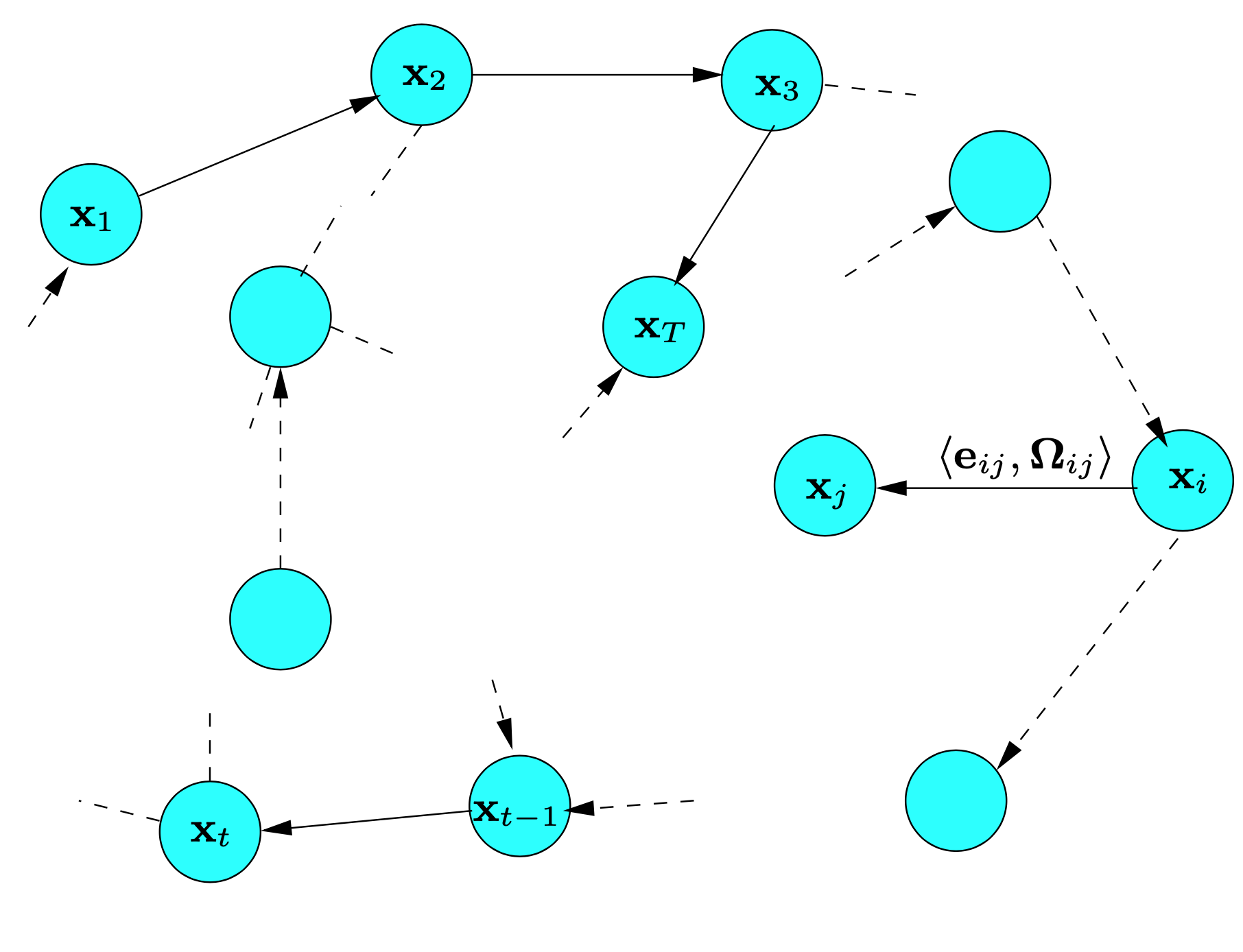
그림 6. SLAM 과정의 자세 그래프 표현. 그래프 상의 모든 노드들은 로봇의 자세를 의미합니다. 가까운 자세들끼리는 에지로 연결되어 있으며, 이 에지는 로봇의 자세 사이에서 관측으로 생기는 공간적인 제약들을 나타냅니다. 에지 $e_{t-1 t}$는 연속적인 자세들 사이에 있으며, 오도메트리 측정치를 설계하며, 다른 에지들은 동일하 환경에서 다중 관측으로부터 만들어지는 공간적인 제약조건들을 의미합니다.
x = ($x_1$, . . ., $x_T$$)^T$는 자세 노드 $x_i$의 벡터이며, $z_{ij}$와 $\Omega_{ij}$는 노드 i와 노드 j사이 가상 측정의 평균과 정보행렬을 의미합니다. 이 가상 측정은 i로부터 얻은 관측들이 j에서 얻은 관측들로 포개도록 만드는 변환입니다. 노드 $x_i$와 $x_j$의 형태가 주어질때 가상 측정의 예측치를 $\hat{z_{ij}}$($x_i$, $x_j$)라고 합시다.
이 예측은 두 노드 사이에 상대적인 변환이라고 할수 있으며, 관측 $z_{ij}$의 로그 우도 $l_{ij}$는 그러므로 다음과 같습니다.
e($x_i$, $x_j$, $z_{ij}$)는 기대 관측 $\hat{z_{ij}}$($x_i$, $x_j$)과 실제 관측 $z_{ij}$ 사이의 차이를 계산하는 함수로, 이 표기를 간단하게 정리하자면 관측 인덱스들을 에러 함수의 인덱스들로 바꾸겠습니다.
그림 7. 정점 $x_i$와 $x_j$를 연결하는 에지의 측면들. 이 에지는 관측 $z_{ij}$에서 시작합니다. 두 노드사이의 상대적인 차이로부터, $x_i$ 좌표계에서 보여지는 $x_j$를 나타내는 기대 측정치 $\hat{z_{ij}}$를 계산할수 있습니다. 에러 $e_{ij}$($x_i$, $x_j$)는 기대와 실제 측정치 사이의 차이에 의존하게되며, 에지는 에러 함수 $e_{ij}$($x_i$, $x_j$)와 불확실성을 나타내는 측정의 정보 행렬 $\Omega_{ij}$로 정리할수 있겠습니다.
그림 7은 그래프의 에지를 정의하는 양과 함수들을 보여주고 있습니다. C는 관측 제약 z가 존재하는 쌍 인덱스들의 집합이며, 최대 우도 방법의 목표는 모든 관측들에 대해 음의 로그 우도 F(X)를 최소화하는 노드 $x^{*}$의 형태를 찾는것이 되겠습니다.
이를 정리하면, 다음의 식을 푸는문제라고 할수 있겠습니다.
이번 섹션에서는 식 (5)를 풀고, 로봇의 주행 궤적에 따른 가우시안 근사를 계산하는 방법에 대해 설명하겠습니다. 가우스-뉴턴이나 Levenberg-Marquardt 알고리즘 같은 기존 최적화 방법을 사용하는 방법도 있지만, 이 방법은 구조 문제로 다루기 때문에 특히나 효율적으로 동작하게 됩니다.
우선 기존의 비선형 최소제곱 최적화 구현을 설명하고, 다음에는 로봇 자세 표현의 특이성을 다룰수 있도록 도와주는 다른 방법들을 소개하겠습니다.
A. 지역 선형화 반복을 통한 에러 최소화
로봇의 자세에 대한 좋은 초기 추측 guess $\breve{x}$를 알고있다면, 식 (5)의 수치적인 해는 가우스-뉴턴 법이나 Levenberg-Marquardt 알고리즘을 사용하여 얻을수 있겠습니다. 이 아이디어는 현재 초기 추측 $\breve{x}$ 주위에 1차 태일러 전개로 에러 함수를 근사화하는것으로 다음과 같습니다.
여기서 $J_{ij}$는 $\breve{x}$와 $e_ij$ = $e_{ij}$($\breve{x}$)로 계산되는 $e_{ij}$(x)의 자코비안입니다. 식 (4)의 에러 항 $F_{ij}$에 식 (7)을 대입하면 다음의 식을 얻을수 있겠습니다.
식 (14)와 같은 이차 식은 식 (13)에서 c = $\Sigma$$c_{ij}$, b = $\Sigma$$b_{ij}$, 그리고 H = $\Sigma$$H_{ij}$로 설정하여 얻을수 있으며, 선형 시스템의 해를 구함으로서 $\Delta$를 최소화 시킬수 있겠습니다.
행렬 H는 자코비안을 통해 궤정의 상태 공간에서 관측 에러를 사영함으로서 얻을수 있기 때문에 H는 시스템의 정보 행렬이 됩니다. 제약 조건에 의해 연결되는 자세들 사이에는 0이 아닌 값들을 가지며, 희소한 행렬이 됩니다. 이 행렬은 희소 Cholesky 분해를 이용하여 식 (15)을 풀수 있도록 도와줍니다. 희소 Cholesky 분해를 효과적으로 구현하기 위해 CSparse라이브러리를 사용할수 있겠습니다.
초기 추정을 더함으로서 선형화된 해률 얻을수 있게됩니다.
많이 사용되는 가우스-뉴턴 알고리즘은 식 (14)의 선형화와 식 (15)의 해, 식 (16)에서 갱신 단계를 반복해서 수행합니다. 모든 반복과정에서 이전의 해가 선형화 지점과 초기 추정치로 사용됩니다.
위에서 설명한 과정들은 다변수 함수 최소화에 사용하는 일반적인 방법으로 SLAM 문제의 특별한 경우에서 사용됩니다. 하지만 이 일반적인 방법은 파라미터 x들의 공간이 유클리디안이라고 가정하고 있으며, 이 경우에는 SLAM에 사용할수 없으며, 하부 최적의 해를 구해야 할수 있습니다.
그래프 기반 SLAM 방법은 가공되지 않은 센서 데이터들 이용하여 간소화된 추정 문제로 만듭니다. 이러한 로 관측 데이터들은 그래프 상에 에지로 대체되며, 가상의 측정치들로 볼수 있겠습니다. 더 자세하게 설명하자면, 두 노드 사이에 에지가 존재하며 이들은 두 자세 사이의 상대적인 위치가 주어질때 관측치에 대한 확률 변수로 표기 됩니다.
일반적으로 관측 모델 p($p_t$ | $x_t$, $m_t$)는 멀티 모달이므로 가우시안 가정을 적용할수 없습니다. 이런 이유로 단일 관측 $z_t$는 그래프 상에 존재하는 다른 자세들과 연결되는 다중 포텐셜 에지들이 될수 있으며, 그래프 연결성은 확률 분포로 설명해야 합니다. 추정 과정에서 멀티 모달을 직접적으로 다룬다면 복잡도가 크게 증가될수 있습니다. 그 결과 가장 실용적인 방법들은 가장 가능성있는 토플로지로 추정치들을 제한합니다.
그래서 관측을 이용하여 가장 높은 가능성을 가진 제약을 결정하여야 합니다. 이 결정은 로봇의 자세에 대한 확률 분포를 이용하며, 이 문제를 데이터 연관으로 볼수 있으며, SLAM의 프론트앤드에서 주로 다루게 됩니다. 올바른 데이터 연관을 구하기 위해서 프론트엔드는 로봇의 궤적 p($x_{1:T}$ | $z_{1:T}$, $u_{1:T}$)에 대한 조건부 사전확률의 일관적인 추정치를 필요로 합니다. 이 작업은 로봇이 주행하는 동안 프론트 앤드와 백앤드 사이에 끼워져야 합니다. 그러므로 백앤드의 정확도와 효율성은 좋은 SLAM 시스탬을 설계하는대 매우 중요합니다.
이 튜토리얼에서는 데이터 연관에 대한 복잡한 방법을 다루지는 않을 것이나, 그런 방법들로는 스팩트럴 클러스터링, 조건부 한정분기나 백트래킹 방법같은게 있습니다. 이런걸 고려하기 보다는 프론트엔드에서 일관된 추정치를 주고있다고 가정해서 보겠습니다.
그림 6. SLAM 과정의 자세 그래프 표현. 그래프 상의 모든 노드들은 로봇의 자세를 의미합니다. 가까운 자세들끼리는 에지로 연결되어 있으며, 이 에지는 로봇의 자세 사이에서 관측으로 생기는 공간적인 제약들을 나타냅니다. 에지 $e_{t-1 t}$는 연속적인 자세들 사이에 있으며, 오도메트리 측정치를 설계하며, 다른 에지들은 동일하 환경에서 다중 관측으로부터 만들어지는 공간적인 제약조건들을 의미합니다.
관측이 가우시안 노이즈의 영향을받고, 데이터 연관을 알고 있다면 그래프 기반 지도작성 알고리즘의 목표는 로봇의 궤적에 대한 가우시안 사후확률 근사를 계산하는것이 될겁니다. 이는 관측 우도를 최대화시키도록 하는 노드 형태로서 가우시안의 평균을 계산하는 것을 다루게 됩니다. 이 평균은 가우시안의 정보 행렬이라고도 알려져 있습니다. 앞으로 제약조건 최적화 문제로 이러한 최대치를 찾는 작업들에 대해 정리하겠습니다. 그리고 앞으로 사용할 표기법들을 그림 6에서 소개하겠습니다.
로봇 공학 커뮤니티에 수많은 SLAM 방법들이 연구되고 있습니다. 이 튜토리얼 전반에서 그래프 기반의 방법들을 중심으로 다룰것이고,
이러한 방법과 관련된 연구들에 대해서도 살펴보겠습니다.
Lu와 Milos는 제약을 이용해서 오차를 줄이는 시스템 방정식들을 전역적으로 최적화하는 지도를 처음 정의하였습니다. Gutmann은 그런 네트워크를 만들고, 중분 추정 알고리즘이 동작하는 동안 루프 폐쇄를 검출하는 효율적인 방법을 제안하였습니다. 이후에는 제약 네트워크 상의 오차를 최소화하는 수많은 방법들이 나왔는데요.
예를들자면 Howard는 로봇의 위치 추정과 지도 작성에 완화를 적용하였습니다. Frese는 멀티 레벨 완화 multi level relaxation이라 부르는 가우스-시델 완화의 변형 기술을 제안하였으며, 서로다른 해상도에서 완화기술이 적용됩니다. Dellaert와 kaess는 처음으로 오프라인 슬램에서 선형화된 문제를 풀기 위해 희소 행렬 분해를 사용하였는데요. 이후 Kaess가 희소 분할을 계산하는 편 재정렬을 사용한 온라인 버전인 iSAM을 소개하였습니다.
최근 Konolige는 효율적인 방법으로 선형화된 시스템을 생성하는 포즈 그래프 방법을 오픈소스로 구현하여 소개하였습니다. Olson은 확률적 경사 하강법을 기반하는 최적화 방법을 소개하였고, 이를 통해 큰 크기의 포즈그래프도 효과적으로 고칠수가 있게 되었습니다. Grisetti는 노드들을 트리로 나타내는 Olson의 방법의 개선판을 소개하였으며 이를 통해 수렴 속도를 올렸습니다.
GraphSLAM은 최적화 문제의 차원성을 줄이기 위해 다양한 제거 기술들을 적용한 것이고, ATLAS 프레임워크는 두 개층의 그래프를 만들어 냅니다. 바텀 계층을 만들기 위해서 Kalman filter를 사용하였고, 2계층에서 전역 최적화 방법으로 지역 지도를 정렬하였습니다. ATLAS와 비슷하게, Estrada는 독립적인 지역들을 사용하는 계층 SLAM을 제안하였습니다.
많은 최적화 기술들이 주어진 제약관계를 이용해서 최적의 지도를 계산하는데 목표를 두고 있으며 이를 SLAM 백엔드라고 부릅니다. 이와 반대로 SLAM 프론트엔드는 센서 데이터를 해석하여 최적화 방법에 기반이 되는 제약관계를 얻습니다. Olson은 스펙트럴 클러스팅을 기반으로하는 아웃라이어 제거를 사용한 프론트엔드 기술을 소개하였는데요. SLAM 프론트엔드에서 데이터 연관을 만들기 위해 통계학적인 테스트 $\xi^2$ 시험이나 결합 확률 시험 같은것들이 종종 사용되기도 합니다.
Nuchter의 연구에서는 3차원 지도 작성을 SLAM 시스템에 통합하는 것을 목표로 하였는데, 이 연구에서 매인 포커스는 SLAM 프론트엔드에서 제약조건들을 찾는것이었습니다. 최적화를 위해서 Lu와 Millios의 3차원 세팅을 위한 다양한 방법들이 사용되었고, 이러한 방법들이 프론트엔드 상에서 효과적으로 사용될수 있습니다.
SLAM 문제를 푸는것은 로봇의 궤적과, 로봇이 이동한 황경의 지도를 추정하는것으로 이루어집니다. 센서에는 노이즈를 갖고 있기 때문에 SLAM 문제를 확률적인 도구를 사용해서 나타냅니다. 로봇이 모르는 환경에서 이동한다고 할때, 궤적의 시퀀스를 확률변수 $x_{1:T}$ = {$x_1$, . . ., $x_T$}로 표기하겠습니다. 이동하는 동안 로봇은 오도메트리 측정 시퀀스인 $u_{1:T}$ = {$u_1$, . . .,$u_T$}와 관측 시퀀스인 $z_{1:T}$ = {$z_1$, . . .,$z_T$} 또한 얻게 됩니다.
완전 SLAM을 푸는 는 것은 모든 관측치들과 초기자세 $x_0$가 주어질때, 로봇의 궤적 $x_{1:T}$와 지도 m의 사후확률을 추정하는것으로 이루어 집니다.
초기 자세 $x_0$는 지도의 위치를 정의하며, 임의로 지정할수 있습니다. 편하게 표기하기 위해서 이 문서에서는 $x_0$는 생략하겠습니다. 자세들인 $x_{1:T}$와 오도메트리 $u_{1:T}$는 SE(2)나 SE(3)에서 2차원 혹은 3차원으로 변환되어 표현되기도 합니다.
지도는 점유격자같은 밀집된 표현이나 처리되지 않은 센서측정치로 공간상에 존재하는 랜드마크의 집합을 나타낸것이라 할수 있습니다. 어떤 지도 표현법을 사용할지는 사용하는 센서나, 주위 환경의 특성, 추정 알고리즘에 따라 선택하여야 합니다.
랜드마크 지도는 특징들이 쉽게 구분할수 있는 환경에서 선호되며, 특히 카레라를 사용하는 경우 그렇습니다. 하지만 밀집 지도에서는 레이저 거리계들이 사용되곤 합니다. 이러한 타입에 독립적으로 지도는 측정치와 그 측정치를 획득한 장소를 이용하여 만들어 집니다.
그림 2에서는 2차원과 3차원으로 3가지 밀집 지도 표현을 보여주고 있는데, 다층 표면 지도와 점구름, 점유격자가 있습니다. 그림 3의 경우는 일반적인 2차원 랜드마크 기반 지도를 보여줍니다.
그림 3. 독일 항공 센터에서 취득한 특징 기반 지도. 이 환경에서 랜드마크는 딱 위에 흰 원으로 이루어지며, 이 랜드마크는 왼쪽 그림처럼 로봇이 영상을 이용하여 감지 합니다. 우측 그림은 로봇의 궤적과 랜드마크의 추정 위치들을 보여주고 있습니다.
식 (1)의 사후확률을 추정하는데에는 고차원 상태 공간에서 연산이 수행됩니다. 그래서 SLAM 문제가 구조적으로 잘 정의되지 않는데면, 추적을 수행할수 없게 됩니다. 이 구조는 확실하고 일반적인 가정들을 따르는데, 이러한 가정으로 정적 환경 과정과 마르코브 가정이 있겠습니다.
그림 4. SLAM 과정의 동적 베이지안 네트워크
이러한 구조를 표현하기 위한 편리한 방법은 그림 4와 같은 동적 베이지안 네트워크 DBN을 사용하는것이 되겠습니다. 베이지안 네트워크는 유향 그래프로 확률 과정을 나타내는 그래프적인 모델이라 할수 있습니다. 이 그래프는 과정에 있어서 각 확률 변수로 노드와 두 노드사이에 조건부 의존을 나타내는 에지를 가지고 있습니다.
그림 4는 파란/회색 노드로 구분할수 있겠는데, 이는 측정된 변수들($z_{1:T}$, $u_{1:T}$)이고, 흰색 노드들은 은닉 변수들입니다. 은닉 변수인 $x_{1:T}$과 m은 로봇의 궤적과 주위에 대한 지도를 나타냅니다. DBN의 연결은 상태 전이 모델과 관측 모델에 의한 재귀적인 패턴으로 이루어 집니다.
상태 전이 모델 p($x_{t}$ | $x_{t-1}$, $u_t$)는 $x_t$를 구하는데 사용되는 2개의 에지들로 이루어지고, 시간 t-1에서의 로봇의 상태와 오도메트리 측정 $u_t$로 시간 t의 로봇의 상태에 대한 확률을 의미합니다. 관측 모델 p($z_t$ | $x_t$, $m_t$)는 로봇의 자세 $x_t$에서 수행한 관측 $z_t$의 확률로, $z_t$로 들어가는 화살표로 나타냅니다. $z_t$는 외부 수용적인 관측치로 정적인 지도 m와 현재 로봇의 위치 $x_t$에 의해 결정 됩니다.
SLAM을 DBN으로 표현함으로서 임시적인 구조를 강조할수 있고, 이를 통해 SLAM 문제를 다룰수 있는 필터 처리 과정을 묘사하는데 적합하게 됩니다.
DBN의 대안으로 그래프 기반, 네트워크 기반이라고 부르는 방법이 있는데, 이러한 방법은 공간적인 구조를 강조하게 됩니다. 그래프 기반 SLAM에서는 로봇의 자세들이 노드들로 설계되고, 이러한 자세들에 대해 라벨을 붙이게 됩니다. 이러한 자세들 간에 공간적인 제약(관측 $z_t$나 오도메트리 측정 $u_t$로 얻을수 있는)들은 노드들의 사이에 에지로 나타냅니다.
더 자세히 설명하자면 그래프 기반 슬램 알고리즘은 센서 측정치로 그래프를 만들어 냅니다. 그래프에서 각 노드들은 로봇의 위치와 해당 위치에서 얻은 측청치들을 나타내고, 두 개의 노드 사이의 에지는 로봇의 2개의 자세들 간에 관련된 공간적인 제약을 나타냅니다. 이 제약은 두 자세 사이의 상대적인 변환에 대한 확률 분포로 이루어 집니다. 이러한 변환들은 로봇의 자세 시퀀스 사이의 오도메트리 측정치이거나 두 장수에서 취득한 관측 데이터에 의해 정해질수 있겠습니다.
그래프가 생성이되면, 제약 조건들에 최적으로 만족하는 로봇 자세들의 형태를 찾게 됩니다. 그래서 그래프 기반 SLAM 문제는 두가지 작업으로 분리될수 있겠습니다. 우선 가공되지 않은 측정 데이터로 그래프를 생성하는 그래프 생성 작업과 그래프의 에지들이 주어질때 가장 높은 가능성을 가지는 자세 설정을 결정하는 그래프 최적화 작업이 있습니다.
그래프 생성 작업을 프론트 엔드라고도 부르며, 매우 센서에 의존적인 작업입니다. 두번째의 것을 백엔드라고 부르며, 이는 데이터의 추상적인 표현이나 센서에는 자유롭습니다. 2차원 레이저 SLAM에서 프론트 엔드의 간단한 예시가 5번째 장의 A에서 볼수 있습니다.
그림 5. MIT 킬리언 재판소에서 기록한 데이터 셋으로 만든 자세 그래프로 오른쪽은 최적화 후를 보여주고 있습니다. 이 지도는 그래프 상에 로봇의 자세들에 따른 레이저 스캔으로 만들었습니다.
이 튜토리얼에서는 쉽게 구현할수 있으나 효율적인 백엔드로 구성된 그래프 기반 SLAM에 대해서 소개하겠습니다. 그림 5번은 올바르지 않은 자세 그래프와 올바르게된 경우를 보여주고 있습니다.
그림 2는 이 논문에서 설명할 SLAM알고리즘으로 추정할수 있는 2차원 3차원 지도를 보여주고 있습니다.
그림 2. (a) 센서를 내장한 차로 취득한 스탠포드대 주차장의 3차원 지도(아래)와 위성 뷰(위). 이 지도는 차후에 자율 주차 동작을 하는대 사용됩니다. (b) Freiburg 대에서 취득한 점군 지도와 위성 뷰, (c) Freiburg 병원에서 얻은 점유 격자 지도. 위 : 버드아이뷰, 아래 : 점유 격자 표현. 여기서 회색 공간은 관측되지 않은 영역이고, 흰 부분은 움직일 수 있는 공간, 검은 점들은 점유된 공간을 나타냅니다.
SLAM 문제를 다루기 위한 직관적인 방법을 그래프 기반 방법이라 하겠습니다. 이 그래프 기반의 SLAM을 푸는 것에는 로봇의 자세나 랜드마크를 나타내는 노드와 노드 사이에서 연결된 자세들을 제약하는 센서 관측을 부호화하는 에지를 만드는 것을 포함합니다.
이러한 제약들은 센서가 노이즈에 항상 영향을 받으니 모순될수 있겠지만, 그래프가 생성이되면 이 치명적인 문제는 관측이 일관되게 최대가 되도록 노드의 형태를 찾아 해결할 수 있습니다.
그래프 기반 SLAM 문제는 1997년 Lu와 Milios가 제안했지만, 표준 기술을 사용해서 오차 최소화 문제를 풀기에는 높은 복잡도때문에 이 방법이 대중화되기 까지는 오랜 세월이 걸렸습니다. 최근 SLAM 문제의 구조에 대한 통찰과 희소 선형 대수 분야의 진보로 최적화 문제를 효율적으로 풀게 되었습니다.
결과적으로 그래프 기반 SLAM 방법은 르네상스기를 겪는 중이고, 현재 빠르고 정확한 최신 알고리즘이라고 할수 있습니다. 이 튜토리얼의 목적은 SLAM 문제를 확률적인 형태로 소개하고, 독자들에게 최신 그래프 기반의 SLAM 방법을 안내하고자 합니다.
이 튜토리얼을 이해하기 위해서 선형 대수와 ㄷ변수 최소화, 확률 이론에 대해서 이해하고 있어야 합니다.
운동이나 탐색, 구조, 자동 청소와 같이 이동 로봇을 사용하여 할수있는 많은 작업들을 하기 위해서는 주변의 지도가 필요합니다. 정확한 지도가 사용가능하다면 GPS와 같은 외부 참조 시스템 없이, 내장된 센서만으로 복잡한 환경에서도 동작하는 시스템을 설계할수 있게 됩니다. GPS를 사용할수 없는 실내 환경에서 지도를 얻는 것은 로봇 공학 커뮤니티에서 최근 10년간 주요 관심사가 되어왔습니다.
자세가 불확실한 와중에 지도를 얻는것을 동시적 위치 추정 및 지도작성 SLAM 문제라고도 합니다. 이 문제를 다루기 위한 수많은 방법들이 존재하는데, 이러한 방법들은 필터링이나 스무딩으로 분류할수 있을것같습니다.
1.1 SLAM의 분류
필터링 방법은 이 문제를 현재 로봇 위치와 지도로 이루어진 시스템의 상태들을 온라인으로 추정하는 문제로 설계하는것이고, 대표적인 기술로 칼만 필터와 정보 필터, 파티클 필터 같은게 있습니다. 이들의 증가하는 성질을 강조하기 위해 필터 방법들을 종종 온라인 슬램 방법이라고도 합니다.
반대로 스무딩 방법은 전체 관측치 데이터로부터 로봇의 완전한 궤적을 추정하는 방법이며, 이러한 방법들을 완전 슬램 문제라고도 합니다. 이들은 일반적으로 최소 제곱 오차 최소화 기술들에 의존합니다.
그림 1. SLAM의 응용. (a) 스탠포드대에서 개발한 자율주행차. 이 차는 내장된 센서로만 지도를 작성할 수 있고, 이 지도는 자율 주행에 사용됩니다. (b) 토요타대에서 개발한 박물관 안내 로봇으로, 박물관이 매시간 바뀌면서 새로운 지도를 얻습니다. (c) 매니퓰레이터가 장착된 자율주행 로봇으로, 내장된 센서만을 사용해서 주위 환경에서 동작됩니다.
그림 1은 SLAM 기술을 사용하는 현실에서의 로봇 시스템 예시 3지로 자율주행차와 여행 가이드로봇, 산업용 매니퓰레이션 로봇을 보여주고 있습니다.
지도를 만들고, 동시에 이 지도로 위치 추정을 수행할수 있는 능력은 이동로봇이 GPS같은 외부 참조 시스템이 없는 모르는 환경에서 주행하기 위해 필수적인 능력이 됩니다.
이 기술을 동시적 위치 추정 및 지도 작성 SLAM이라고 부르며, 이동 로봇공학에서 20년 동안 가장 많이 연구된 분야중 하나입니다. SLAM을 공식화하는 직관적인 방법 중 하나는 로봇의 자세에 해당하는 노드와 이 자세들간에 제약을 나타내는 에지로 나타내는 그래프를 사용하는것입니다.
에지는 주위 환경에대한 관측이나 로봇이 수행한 동작으로부터 얻을수 있는데, 이 그래프가 만들어지면, 지도는 측정에 대해 일관적인 노드들의 공간적인 형태를 찾아 계산해낼수 있습니다.
이 논문에서는 그래프 기반 문제에 대한 소개를 할 것이며 더나아가 최소 제곱 오차 최소화에 기반하는 최신 알고리즘을 살펴볼 것이고, 최적화가 수행되는 SLAM 구조 문제를 다뤄보겠습니다.
최근 이동 로봇 플랫폼을 사용하여 물리적인 환경에 대한 지도를 작성하기 위한 연구가 많이 수행되고 있습니다. 기존에 수행되던 연구로 하늘에서의 지도작성(konecy, 2002), 땅에서의 지도작성(Elfes 1987), 수중에서의 연구(William, 2001) 등이 있습니다. 또한 실내 환경에서나 (el-Hakim, 1997) 실외 환경에서(Teller, 2001), 그리고 지하에의 지도 작성(Baker, 2004)도 수행되기도 하였습니다.
그러한 지도를 얻기위한 기술 개발은 다양한 목적에서 시작되었는데, 사실적인 광학 랜더링(Allen and Stamos 2000), Nocera, 2000), 감시 (Thrun 2003), 연구 측정(Baker, 2004), 로봇 가이던스(Williams, 2001) 등이 있습니다.
놀랍게도, 이 영역에서의 몇몇 주요 연구들이 수많은 다른 연구 분야에서도 있었는데, 예를들면 광학기하학과 컴퓨터 비전(Tomasi and Kanade 1992), 컴퓨터 그래픽스(Levoy 1999), 로봇 공학 (Dissanayake, 2001)이 있었습니다.
SLAM 커뮤니티에서는 널리 알려진 확장 칼만필터 같은 필터 기술들이 모델을 얻기위한 방법이 되어왔습니다. 확장칼만필터 EKF는 19986년 치즈만과 스미스로 처음 수학적으로 소개되었으며, 1989년 Moutalier가 구현하였습니다. 이 연구는 최근 수백가지로 확장되었으며, 이러한 방법들 중 일부 연구들은 필터 처리 과정에서 계산 효율성을 얻기 위해 희소 그래프 구조로 사상하기도 하였습니다.(Bosse 2003, Thrun 2002).
하지만 이러한 필터 기술의 주요 단점은 데이터가 처리되고 버려진다는 점인데, 이로 인해 지도 작성 중에 모든 데이터를 재사용할수 없게 됩니다. 오프라인 기술이 Lu와 Milos가 1997년에 소개하고 수많은 후속 연구들이 진행되었는데, 모든 데이터를 저장하고, 지도 작성을 이 작업이 끝날때까지 미룸으로서 개선된 성능을 보여주고 있습니다. 1998년 Golfarelli의 연구는 완전 슬램 문제의 사후확률을 희소 그래프로 구성하였습니다. 이 그래프는 비선형 이차 제약의 합이되어, 이러한 제약 조건들 사이에 최적화하는것으로 최대 우도의 지도와 이에 대한 로봇 자세들의 집합을 얻을 수 있었습니다.
이 논문에서는 희소 제약 그래프를 사용하는 새로운 알고리즘을 소개할것이고, GraphSLAM이라 부르겠습니다. GraphSLAM의 기본 개념은 단순합니다. GraphSLAM은 데이터로부터 제약조건의 집합을 추출할것이고, 희소 그래프로 표현하겠습니다. 이 알고리즘은 이러한 제약조건들을 전역 일관 추정으로 풀어내어 지도와 로봇의 경로를 얻게 됩니다. 이 제약조건들은 일반적으로 비선형이지만, 그들을 풀기위한 과정은 선형화되어지고, 표준 최적화 기술로 풀수 있는 최소 제곱 문제가 됩니다. 이후에는 GraphSLAM을 비선형 제약조건들의 희소 그래프를 만드는 기술과, 선형 제약조건의 희소 정보 행렬을 구하는 기술로 나누어 보겠습니다.
넓은 공간에서의 지도 작성 문제에 적용할때, GraphSLAM은 수많은 특징들을 다룰수 있고, 심지어 GPS 정보를 지도 작성 과정에 반영시킬수 있습니다. 이러한 능력들은 3차원 지도작성을 위한 이동로봇으로 획득한 데이터를 기반으로 하고 이습니다.
이 논문은 다음과 같은 순서대로 살펴보겠습니다. 우선 관련 연구들을 살펴볼것이고, GraphSLAM에 대해 직관적으로 설명한 다음에 그래프 이론과 정보 이론을 사용하여 자세히 보겠습니다. 기본 알고리즘을 소개할것이고, 이를 수학적으로 어떻게 구했는지 정리하겠습니다. 그러고나서 데이터 연관 문제를 다루어 보겠습니다. 마지막으로 실험 결과를 보여주고 이후 연구방향으로 마치겠습니다.
이번에 정리할 자료는 오프라인 슬램 문제를 다루는 알고리즘인 GraphSLAM에 대해서 살펴보겠습니다. 그래프 슬램은 최적화 기술들을 SLAM 문제에 적용한 것이라고 할 수 있는데, SLAM 사후확률을 그래프 네트워크로 변환한 것으로 데이터의 로그 우도를 보여줍니다. 이를 통해 변수 제거 기술들을 사용하여 GraphSLAM은 기존의 최적화 기법들로 풀수 있는 차원 축소 문제가 발생하는것을 막아줍니다.
그 결과 GraphSLAM은 10^8 개나 그 이상으로 이루어진 지도를 생성할수 있습니다. 이 자료에서는 데이터 연관을 이ㅜ해 탐욕 알고리즘을 소개하고 있으며, GPS 데이터와 함께 도시 공간에서 SLAM한 결과를 보여주고 있습니다.
def update_with_observation(particles, z):
for iz in range(len(z[:, 0])):
lmid = int(z[iz, 2])
for ip in range(N_PARTICLE):
# new landmark
if abs(particles[ip].lm[lmid, 0]) <= 0.01:
particles[ip] = add_new_lm(particles[ip], z[iz, :], Q)
# known landmark
else:
w = compute_weight(particles[ip], z[iz, :], Q)
particles[ip].w *= w
particles[ip] = update_landmark(particles[ip], z[iz, :], Q)
return particles
관측 갱신 함수에서는 관측된 관측치들만큼 반복을 수행합니다.
해당 관측된 랜드마크의 아이디 lmid를 구하고,
모든 파티클에 대해 루프를 돌립니다.
인덱스가 ip인 파티클에서
lmid 번째 랜드마크의 x 좌표의 절댓값이 0.01보다 작은 경우
새로운 랜드마크로 판단하여,
ip번째 파티클에 랜드마크 추가 함수가 수행됩니다.
잠깐 랜드마크 추가 함수에는
해당 랜드마크 관측과 이 랜드마크를 추가시킬 파티클이 사용됩니다.
def add_new_lm(particle, z, Q):
r = z[0, 0]
b = z[0, 1]
lm_id = int(z[0, 2])
s = math.sin(pi_2_pi(particle.yaw + b))
c = math.cos(pi_2_pi(particle.yaw + b))
particle.lm[lm_id, 0] = particle.x + r * c
particle.lm[lm_id, 1] = particle.y + r * s
# covariance
Gz = np.matrix([[c, -r * s],
[s, r * c]])
particle.lmP[2 * lm_id:2 * lm_id + 2] = Gz * Q * Gz.T
return particle
랜드마크 추가 함수에선
관측의 0번째 값이 거리, 1번째 값이 방위, 2번째 값이 아이디이므로 이들을 초기화 해주고,
해당 파티클에 대한 랜드마크의 사인각과 코사인 각을 구한 다음
파티클의 랜드마크 리스트에 해당 아이디의 랜드마크 위치 값을 추가시켜 줍니다.
그다음 파티클의 랜드마크 공분산을 계산하여 추가 시켜줍시다.
이제 관측 갱신으로 돌아값시다.
def update_with_observation(particles, z):
for iz in range(len(z[:, 0])):
lmid = int(z[iz, 2])
for ip in range(N_PARTICLE):
# new landmark
if abs(particles[ip].lm[lmid, 0]) <= 0.01:
particles[ip] = add_new_lm(particles[ip], z[iz, :], Q)
# known landmark
else:
w = compute_weight(particles[ip], z[iz, :], Q)
particles[ip].w *= w
particles[ip] = update_landmark(particles[ip], z[iz, :], Q)
return particles
def update_with_observation(particles, z):
for iz in range(len(z[:, 0])):
lmid = int(z[iz, 2])
for ip in range(N_PARTICLE):
# new landmark
if abs(particles[ip].lm[lmid, 0]) <= 0.01:
particles[ip] = add_new_lm(particles[ip], z[iz, :], Q)
# known landmark
else:
w = compute_weight(particles[ip], z[iz, :], Q)
particles[ip].w *= w
particles[ip] = update_landmark(particles[ip], z[iz, :], Q)
return particles
def update_with_observation(particles, z):
for iz in range(len(z[:, 0])):
lmid = int(z[iz, 2])
for ip in range(N_PARTICLE):
# new landmark
if abs(particles[ip].lm[lmid, 0]) <= 0.01:
particles[ip] = add_new_lm(particles[ip], z[iz, :], Q)
# known landmark
else:
w = compute_weight(particles[ip], z[iz, :], Q)
particles[ip].w *= w
particles[ip] = update_landmark(particles[ip], z[iz, :], Q)
return particles
fast_slam1의 관측 갱신 함수로 모든 파티클과 각 파티클들의 랜드마크들을 갱신시킨뒤에
리샘플링을 수행하여야 합니다.
def resampling(particles):
"""
low variance re-sampling
"""
particles = normalize_weight(particles)
pw = []
for i in range(N_PARTICLE):
pw.append(particles[i].w)
pw = np.matrix(pw)
Neff = 1.0 / (pw * pw.T)[0, 0] # Effective particle number
# print(Neff)
if Neff < NTH: # resampling
wcum = np.cumsum(pw)
base = np.cumsum(pw * 0.0 + 1 / N_PARTICLE) - 1 / N_PARTICLE
resampleid = base + np.random.rand(base.shape[1]) / N_PARTICLE
inds = []
ind = 0
for ip in range(N_PARTICLE):
while ((ind < wcum.shape[1] - 1) and (resampleid[0, ip] > wcum[0, ind])):
ind += 1
inds.append(ind)
tparticles = particles[:]
for i in range(len(inds)):
particles[i].x = tparticles[inds[i]].x
particles[i].y = tparticles[inds[i]].y
particles[i].yaw = tparticles[inds[i]].yaw
particles[i].lm = tparticles[inds[i]].lm[:, :]
particles[i].lmP = tparticles[inds[i]].lmP[:, :]
particles[i].w = 1.0 / N_PARTICLE
return particles
리샘플링 단계에서는 우선 파티클들의 가중치 정규화 과정을 수행하는데
def normalize_weight(particles):
sumw = sum([p.w for p in particles])
try:
for i in range(N_PARTICLE):
particles[i].w /= sumw
except ZeroDivisionError:
for i in range(N_PARTICLE):
particles[i].w = 1.0 / N_PARTICLE
return particles
return particles
모든 파티클들의 가중치를 모두 합한 후에
기존의 파티클 가중치에 가중치 합을 나누어 정규화 해줍니다.
def resampling(particles):
"""
low variance re-sampling
"""
particles = normalize_weight(particles)
pw = []
for i in range(N_PARTICLE):
pw.append(particles[i].w)
pw = np.matrix(pw)
Neff = 1.0 / (pw * pw.T)[0, 0] # Effective particle number
# print(Neff)
if Neff < NTH: # resampling
wcum = np.cumsum(pw)
base = np.cumsum(pw * 0.0 + 1 / N_PARTICLE) - 1 / N_PARTICLE
resampleid = base + np.random.rand(base.shape[1]) / N_PARTICLE
inds = []
ind = 0
for ip in range(N_PARTICLE):
while ((ind < wcum.shape[1] - 1) and (resampleid[0, ip] > wcum[0, ind])):
ind += 1
inds.append(ind)
tparticles = particles[:]
for i in range(len(inds)):
particles[i].x = tparticles[inds[i]].x
particles[i].y = tparticles[inds[i]].y
particles[i].yaw = tparticles[inds[i]].yaw
particles[i].lm = tparticles[inds[i]].lm[:, :]
particles[i].lmP = tparticles[inds[i]].lmP[:, :]
particles[i].w = 1.0 / N_PARTICLE
return particles
pw 변수에다가 파티클들의 모든 정규화된 가중치들을 담아주고,
파티클 계수 Neff를 구합니다.
리샘플링 단계는 Neff가 NTH보다 작으면 리샘플링 단계가 수행되는데,
우선 가중치를 누적한 wcum과 base, 그리고 리샘플 아이디들을 구합니다.
모든 파티클에 대해 반복을 수행하는데
아래의 로직은 저분포 리샘플링 알고리즘 내용을 확인해야해야 하지만
0111222222222222222222와 같은 식으로 파티클들에 인덱스가 지정됩니다.
그 다음 임시 파티클 집합을 생성해주고,
위 인덱스 리스트의 경우 2가 4번쨰부터 20번째 까지 온다고 가정하면,
4~20번째 파티클들의 값이 2번째 파티클의 값으로 복사가 됩니다.
이와 같은 식으로 가장 인덱스가 많은 파티클 위주로 살아남고,
인덱스가 적은 파티클의 경우 소멸하게 됩니다.
위와 같은 과정을 통해 파티클 리샘플링이 수행됩니다.
while SIM_TIME >= time:
time += DT
u = calc_input(time)
xTrue, z, xDR, ud = observation(xTrue, xDR, u, RFID)
particles = fast_slam1(particles, ud, z)
xEst = calc_final_state(particles)
x_state = xEst[0: STATE_SIZE]