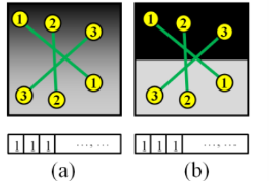
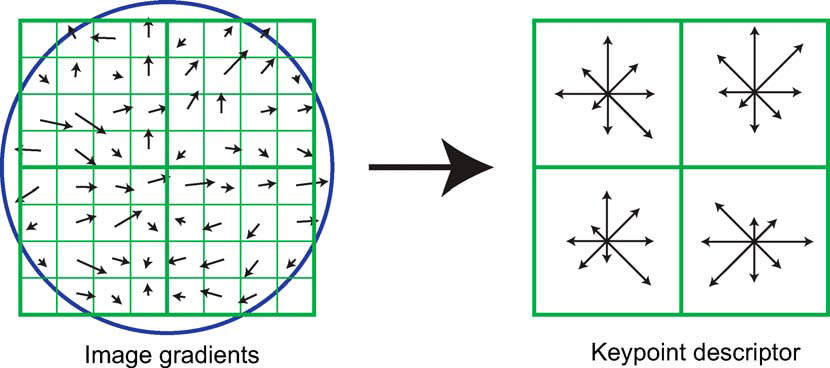
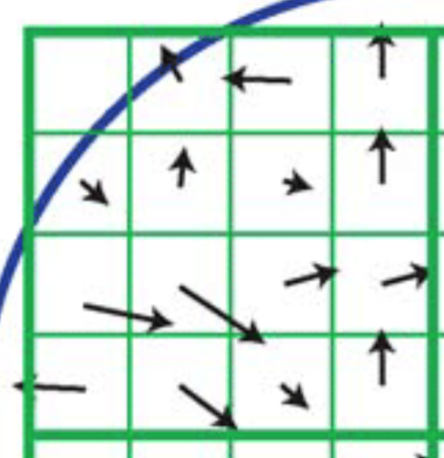
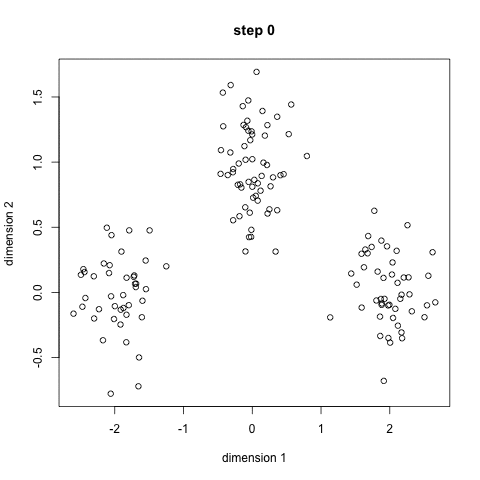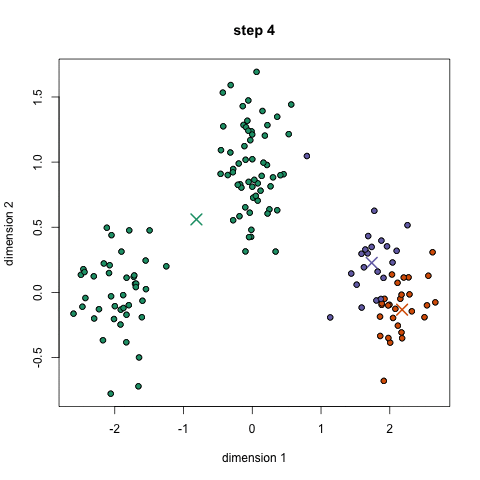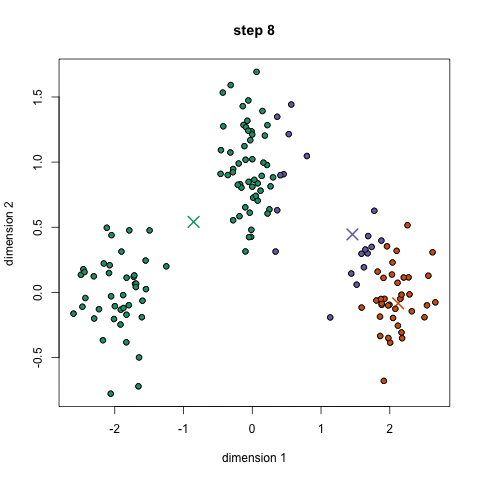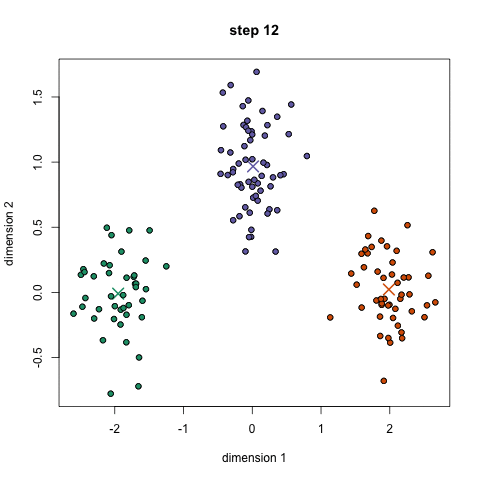
kd트리 매칭
- 지역 정보만 사용
=> 첫 영상의 특징 벡터와 둘째 영상의 특징 벡터에서 최근접 이웃을 탐색하여 대응쌍 구함
기하 변환 Geometry Transform의 예시
- 같은 물체인 다른 대응쌍이 존재시. 기하 변환은 비슷해야함
- 예시 : Rigid Transform, Affine Transform, Perspective Transform 등

kd트리 매칭과 기하 변환
- kd트리 최근접 이웃 탐색을 이용한 매칭에서는 기하 정렬 조건 고려 x, 지역 정보만 사용
=> 기하 정렬 필요
기하 정렬 알고리즘의 사용 예시
- 잡음, 가림, 섞임에도 강건한 알고리즘으로 다음들이 존재
-> 최소제곱법(거짓 긍정이 없는 상황), RANSAC(거짓 긍정이 존재하는 경우). 상황에 맞게 적절히 사용함
- 아래의 그림은 다양한 특징에다가 기하 정렬 알고리즘을 통해 매칭한 예시들을 보여줌

최소제곱법 least square method
- 주어진 샘플들을 가장 잘 표현하는 모델을 구함
- 아래의 예시는 점 집합이 주어질때 오차가 가장 적은 직선을 구하는 그림

컴퓨터 비전에서의 최소제곱법
- 일반 최소 제곱법에서 점 집합이 주어졌으나, 컴퓨터 비전에서는 특징 집합 X가 주어짐
- 대응 쌍이 같은 물체에 존재한다면, 같은 기하 변환을 가짐.
- 기하 변환 행렬(동차 변환 행렬) : 회전, 평행이동, 크기 변환 등을 포함

- 특징의 변환 : 아래의 동차 좌표가 주어질때, 동차 좌표와 동차 변환 행렬의 곱으로 기하 변환 결과 좌표를 구함.
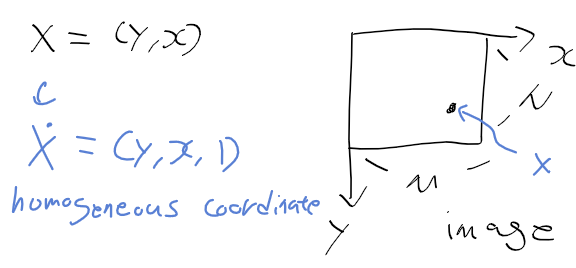
- 실제 측정한 점 b와 기하 변환을 통해 얻은 점 b' = x_dot H_dot이 주어질때,
b와 b'의 최소 제곱 오차가 가장 줄여주는 기하 변환 행렬을 구해야 함.
최소제곱법을 이용한 매칭 예시
- 두 영상과 특징들이 주어질때, 매치 오차를 최소화 하는 기하 변환 행렬을 구한 예시

RANSAC을 이용한 매칭
- 두 영상의 특징 매칭 쌍 중에 거짓 긍정이 포함된 경우. 이를 노이즈로 보고 노이즈를 제거해야함
=> RANSAC 사용

'로봇 > 영상' 카테고리의 다른 글
| 컴퓨터 비전 - 27. SVM (0) | 2020.07.31 |
|---|---|
| 컴퓨터 비전 - 26. 기계학습 (0) | 2020.07.31 |
| 컴퓨터 비전 - 24. kd 트리를 이용한 매칭 (0) | 2020.07.31 |
| 컴퓨터 비전 - 23. ROC 곡선과 매칭 전략 (0) | 2020.07.31 |
| 컴퓨터 비전 - 22. 매칭과 거리 (0) | 2020.07.31 |