ref : arxiv.org/abs/1311.2901
Visualizing and Understanding Convolutional Networks
Matthew D. Zeiler Dept. of Computer Science, Courant Institute, New York University
Thu, 28 Nov 2013
합성곱 신경망의 시각화와 이해
요약
- 이미지넷 밴치마크에서 분류성능이 좋은 합성곱 신경망 모델들이 많아짐
- 왜 이렇게 성능이 좋고, 개선되는지 잘 몰라서 연구
- 중간 특징 계층과 분류기 동작을 시각화하여 영감을 얻음
-> 이 방법으로 Krizhevsky보다 좋은 모델을 만듬
- 모델 계층 하나를 없애면서 성능 변화를 살펴보기도 하고, 다른 데이터셋에서도 잘 동작하는걸 확인함.
소개
- 일찍이 LeCun(1989)이 소개했을때부터 손글씨, 얼굴 인식에 합성곱 신경망이 좋은 성능을 보임
- 작년(2012)년에 7논문이 좋은 분류 성능이 좋았는데, 그 중 Krizhevsky께 가장 좋았음.
* 2012년 이미지넷 분류 벤처마크에서 2등의 에러율이 26.1%인데 16.4% 에러율이 남.
- Hinton에 따르면 1. 큰 훈련 데이터 셋, 2. 좋은 GPU 성능, 3. 새로운 정규화 기법이 성능 개선의 요인이라고 한다.
하지만 여전히 내부 동작에 대해서는 잘 모르고, 어떻게 좋은 성능이 나오는지는 잘 몰라서 답답하다. 동작 원리를 모르고서는 시행 착오 때문에 더 나은 모델이 나오기는 힘들어질것 같다. 이 논문에서는 입력이 어떻게 신경망의 피처 맵을 자극, 영향을 주는지 시각화해서 보여 주고자한다. 이 덕분에 훈련되는 과정에 특징들이 어떻게 변화되는지 볼수 있었고, 모델에 존재하는 잠재적인 문제들을 분석해볼수 있었다.
우리가 제안한 시각화 방법을 특징 활성이 입력 픽셀로 역방향으로 가도록 하기 위해 다층 디컨벌루션 신경망에 사용했다. 입력 이미지에 따라 분류기 출력이 얼마나 민감한지 분석하였는데, 이미지의 일부분이 분류에 중요하다는 사실을 알 수 있었다. 이런 방법들로 Krizhevsky보다 더 나은 모델을 만들어서 이미지넷에서 좋은 결과를 보였다.
관련 연구
신경망에대해 이해하기 위해서 특징을 시각화하는건 어려운 문제. 픽셀 공간으로 사영이 쉬운 1층을 제외하구요. 계층이 깊어 질수록 더 어려워지며, 변화를 이해하기가 힘들어 집니다. 이미지 공간 상에서 신경이 최대로 활성하는 경사 하강을 수행하여 최적의 신경을 찾았습니다. 이때 신경들을 잘 초기화하고 불변성에 대한 다른 정보를 주어서는 안됩니다. 후에 나온 연구에선 어떻게 불변성에 대한 정보가 주어진 신경의 헤시안이 수치적으로 최적과 반대되도록 계산하는것을 보여주며, 불변성에 대해 잘 고려해보아야 합니다. 이 문제는 고층으로 갈수록 불변성이 매우 복잡하고, 단순 이차 근사만으로는 확인하기가 어려워 집니다.
우리의 방법은 불변성에 대한 비모수적인 관점에서 보는게 아니라 훈련 집합이 활성시키는 특징 지도의 패턴을 보여주고자 합니다. Donahue은 모델의 고층 레이어에서 강한 활성을 시키는 패치들을 시각화하여 보여주었습니다. 하지만 우리는 입력 이미지의 조각 만이 아니라 여러 개의 구조물과 각각의 패치들을 탑다운으로 사영하면서 보여주고있습니다.
접근 방법
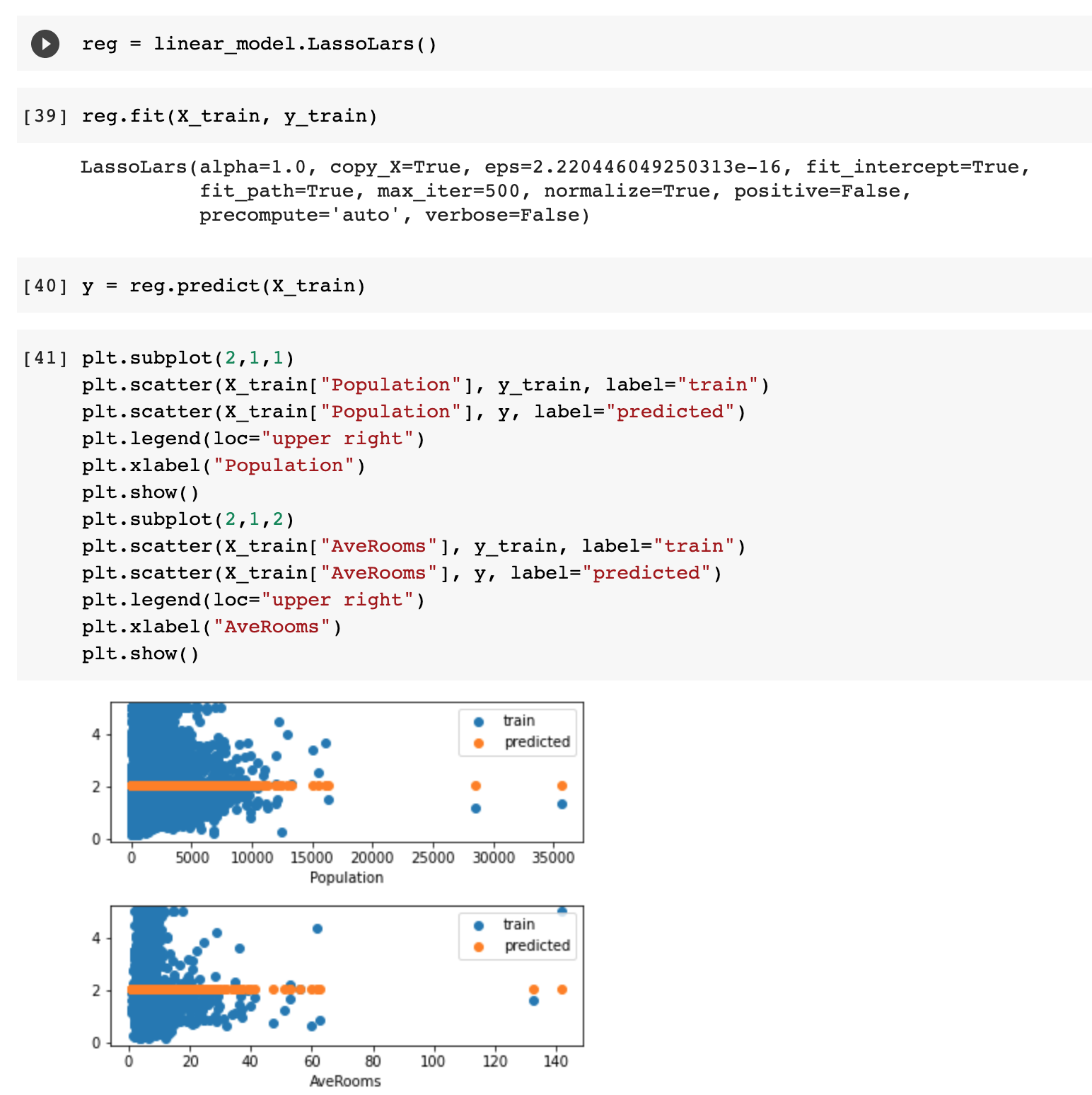
기본적으로 LeCun과 Krizhevsky의 합성곱 신경망 모델을 사용.
이 모델들은 2차원 이미지 x_i를 입력으로 받으며 각 층의 출력은 확률 벡터 hat{y_i} 이고, 클래스는 C개가 있음.
-> 그림 3이 우리가 쓴 모델

그림 3. 8계층 레이어 합성곱 신경망 모델. 이미지(3색)를 224 x 224 조각을 내서 입력으로 받음.
1층 : 96개의 필터(빨강)로 합성곱 연산, 각 필터는 7 x 7 크기, 스트라이드는 2
1) relu 함수를 통과,
2) 3x 3 맥스 풀링. 스트라이드 2
3) 55 x 55의 96개의 특징 지도(정규화된)
2, 3, 4, 5도 비슷하게 동작. 마지막 2개의 계층은 완전연결. 6 x 6 x 256 =9216차원을 입력백터로
마지막 계층은 C개 분류를 위한 소프트맥스 함수. (모든 필터와 특징은 정방 형태)
N 개의 라벨 이미지로 학습. -> y_i는 진짜 클래스
이미지 분류에 적합한 교차 엔트로피 비용 함수 사용( y_i와 hat{y_i})
신경망은 역전파로 학습했고, 파라미터들을 호가률적 경사 하강으로 갱신.
2.1 디컨브넷 시각화
합성곱 신경망 동작을 이해하기 위해서는 중간 계층들의 특징들 변화를 해석해야함.
우리가 제안하는 방법 : 특징 변화를 입력 픽셀 공간으로 사상하여 특징 맵의 변화를 입력 패턴으로 보여줌.
디컨브넷은 합성곱 신경망 모델을 역으로 만든거라 생각할수 있는데,(이미지를 특징으로 맵핑이아니라 반대로)
우리가 제안한 디컨브넷(2011)에서는 비지도 학습을 함.
* Adaptive deconvolutional networks for mid and high level feature learning.
컨브넷을 살펴보기위해, 그림 1의 위처럼 디컨브넷을 각 레이어에 연결함.
-> 결과를 이미지 픽셀을 되돌려줌.
시작하여 입력 이미지를 컨브넷에 주고, 각 레이어마다 피처들이 계산됨.
컨브넷 활성을 보기 위해서 다른 활성함수들을 0으로 설정하고, 특징 맵을 부착된 디컨브넷 레이어에 입력으로 줌
1. 언풀, 2. 개정 , 3. 필터링 과정으로 복원 시킴. 이 과정은 입력 픽셀 공간에 도달할떄까지 반복

그림 1
위 : 컨브넷 계층(오른쪽)과 연결된 디컨브넷 계층(왼쪽)
- 디컨브넷은 컨브넷 피쳐들을 재구성 할것임.
아래 : 전환을 통한 디컨브넷에서의 언풀링. 전환 당시 각 풀링 영역에서 지역 최대치의 위치를 기록.
언풀링
- 컨브넷에서 맥스 풀링 연산은 역행할수는 없었음.
- 전환(스위치) 변수 집합에 각 풀링 영역의 최대지점 위치를 기록해놓으면, 근사적으로 역행시킬순 있음.
- 디컨브넷에서 이러한 전환을 통해 언풀링을 수행해서 레이어를 복원시킬 수 있음.(그림 1 아래것 처럼)
개정
- 컨브넷은 렐루 함수의 비선형성을 사용하는데, 특징 맵이 항상 양의 값을 갖도록 고쳐주기 때문.
- 올바른 특징 복원 결과물을 얻기위해 relu 함수를 사용
필터링
- 컨브넷은 이전 층으로부터 특징 맵을 컨볼루션시킨 학습된 필터를 사용.
- 이를 역행하기위해서 디컨브넷은 전치된 필터를 사용.(대상은 relu 함수 적용된 맵에, 레이어 출력 x)
높은 층에서 아래로 사영하면서, 최대 풀링 당시 전환 설정을 사용.
이 전환 설정들은 주어진 입력 이미지에 대한 것으로 , 한 활성으로부터 얻은 복원물은 원본 이미지의 일부를 닮음
3. 훈련 상세 사항
- 우리의 컨브넷은 그림 3과 비슷하지만 다른점은 3, 4, 5계층에서 우리 모델을 연결시킴
- 또 다른건 1, 2 레이어는 4.1에서 설명할것이고 그림 6에서 볼수 있음.
이 모델은 이미지넷 2012 훈련 셋을 사용.
이미지 256 x 256으로 축소. 코너, 센터 10씩 잘라서 224 x 224 이미지 만듬.
128미니배치 사이즈로 확률적 경사 하강법 사용하여 파라미터 갱신. 학습률은 0.01, 모맨텀항은 0.9
0.5 레이트로 6,7계층에 드롭아웃 함. 모든 가중치들은 0.01로 초기화, 평향은 0으로 설정
훈련후 첫번제 레이어 필터 시각화한 결과는 그림 6.(a)에서 볼 수 있음.
소수의 특징이 좌우하고 있으므로, 각 필터를 재정규화함.
70에폭 훈련 후 중지함. GTX580으로 12일이 걸림.

그림 6. (a) 1번째 레이어로 특징 스케일 클리핑을 하지않은 특징들.
(b) Krizhevsky의 1층
(c) : 우리 모델의 1층 특징들. 스트라이드 ( 2, 4), 필터 사이즈 (7x7, 11x11) 작을 수록 특징들이 더 명확하고, 죽은 특징이 적었음.
(d) :Krizhevsky의 2층 특징들
(e) : 우리 모델 2층 특징들. 앨리어싱도 없이, 더 깨끗하고 보기좋음.
4. 컨브넷 시각화
3장에서 설명한 모델로 특징 활성을 보여주기위해 디컨브넷을 사용하겠음.
특징 시각화
그림 2는 훈련된 모델로 특징을 시각화한 걸 보여주고있음.
주어진 특징 지도에 대한 가장 강한 활성을 보여주기 보다는, top 9개를 보여주고 있음.
픽셀 공간으로 사영시킨 것을 보면, 여러 가지 형태로도 해당 특징 맵을 만들수 있는 것을 알 수 있고,
입력이 변형되더라도 불변함을 알 수 있음
게다가 특징 활성에 해당한느 이미지를 같이 보여주고 있는데,
각 패치가 초점을 맞추는 판별 구조에 따라 여려 변형이 나올 수 있습니다.
예를들어 5 레이어의 1행 2열의 패치들을 보면 공통점이 없어보이는데, 시각화를 해본 결과 특징지도가 앞에있는 물체가 아닌 뒤에있는 잔디에 초점을 맞추었음을 알 우 있따.




그림 2. 완전 훈련 모델의 특징 시각화.
2-5 레이어는
특징 지도의 일부분 중에서 가장 좋은경우 9개씩 보여주고 있음, 디컨볼루션 신경망 방법으로 픽셀 공산으로 사영시킴
우리 방법은 모델에서 샘플링뿐만이아니라 특징 지도상에 강한 활성을 시키는 이미지들에 대한 패턴으로 복원 시킴.
각 특징 지도에 대해 이에 대응되는이미지 패치들도 같이 보여줌.
정리
많은 합성곱 신경망 모델들을 다양한 방법으로 살펴보았습니다.
첫째, 모델의 활성을 시각화하는 방법을 소개했으며, 특징들이 해석할수 없는 특징들이 아니라 층이 올라갈수록 클래스를 판별할수 있는 성질들을 이 나타나는것을 확인하였습니다. 그리고 시각화로 모델이 더 나은 성능을 얻을수 있도록 고칠수 있는지 문제를 찾는데 사용할 수 있었습니다.
--------------
으아ㅏㅏㅏ
전부터 논문 정리해야지 싶었는데
부족한 영어 실력으로 시간만 오래걸리고 제대로 해석하지도 못했다.
계속하기는 질리고
일단 대강 내용을 정리하면
이 논문 저자는
합성곱 신경망의 필터(특징 맵)을 시각화 하는 방법을 고안해냈는데,
이 방법으로 2012년 우승자 모델의 문제점을 찾아내고, 분류 성능을 개선해 내었다고 한다.
파스칼, 칼텍 데이터셋으로 훈련해서도 사용해보고 만든 모델이 성능이 더 잘나왔다.
특징 시각화 하는 방법으로
8계층 합성곱 신경망의 2, 3, 4계층에 디컨브넷을 붙였는데,
언 풀링 -> relu -> 컨볼루션(전치) 연산으로, 컨브넷 레이어의 피처맵을 픽셀 맵으로 복원시킨다는것같다.
어떻게 경쟁자 모델을 개선시켰는지 부분도 안보고
논문좀 잘 볼줄 알아야 하긴 하는데 어렵네 ㅋㅋㅋ
내일 마저 정리해봐야겟다.
'그외 > 논문' 카테고리의 다른 글
| 물체 인식을 위한 선택적 탐색 (0) | 2020.11.19 |
|---|---|
| 중, 고 레벨 특징 학습을 위한 적응적 디컨볼루션 신경망 (0) | 2020.11.18 |
| ORB-SLAM 대강 (0) | 2020.08.16 |
| ORB SLAM 개요 (0) | 2020.08.16 |
| 논문 정리 (0) | 2020.08.16 |