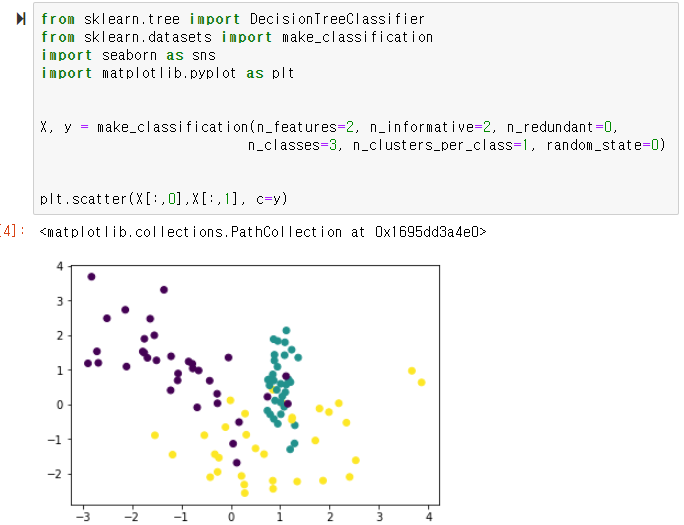
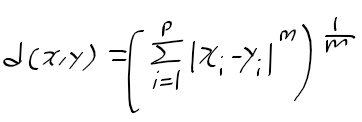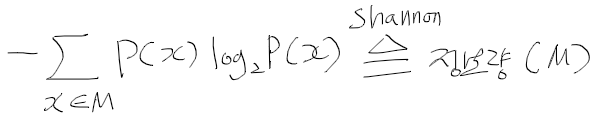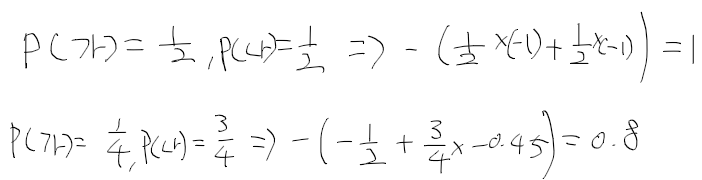UCI 대학교에서 휴대폰 데이터로 사용자 행동 인식에 대한 데이터셋을 공개하고 있다.
Human Activity Recognition Using Smartphones Data Set
archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones

대강 훑어보면
데이터는 1만개, 속성수는 561개 ...,
분류하려는 행동 갯수는 6개로 걷기, 계단 올라가기, 계단 내려가기, 앉아있기, 서있기, 눕기 정도가 있다.
데이터들은 갤럭시 S2의 가속도/자이로계에서 선각속도 등 정보들을 50Hz로 받았다고 한다.
전체 데이터 중 70%가 훈련용, 30%는 테스트 용이라고 하내..
일단 속성수만 해도 장난아니게 많다..
csv형태도 아니다보니
피처명 파일이랑 데이터 파일이 별도로 나누어져 있다.

피처 목록

훈련용 데이터들
- 독립 변수 데이터들과 종속 변수 데이터도 분리되있고

- 피처 데이터도 장난아니게 길다. 뒤에 보니 이 데이터는 ,가 아니라 \n으로 행이 구분되있는것같다.

일단 피처명들부터 읽어야하는데
피처 인덱스와 피처명이 스페이스로 구분되어있고, 해더가 존재하지 않는다.

일단 이 데이터들을 읽고 보자
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
path = "./res/UCI HAR Dataset/features.txt"
features_df = pd.read_csv(path,sep="\s+",
header=None, names=["column_index", "column_name"])
features_df.head()
여기서 column_name은 피처 데이터를 읽을때 컬럼으로 필요하니 리스트로 변환하자
feature_names = features_df["column_name"].values.tolist()
print(type(feature_names))
print(feature_names)

이제 훈련, 테스트 데이터를 읽자
* 아까 본 피처 데이터들은 스페이스로 구분되어있었으니 세퍼레이터를 지정하자
+ 라벨 데이터도 읽고
path = "./res/UCI HAR Dataset/"
X_train = pd.read_csv(path+"train/X_train.txt",sep="\s+", names=feature_names)
X_test = pd.read_csv(path+"test/X_test.txt",sep="\s+", names=feature_names)
y_train = pd.read_csv(path+"train/y_train.txt", sep="\s+", header=None,
names="action")
y_test = pd.read_csv(path+"test/y_test.txt", sep="\s+", header=None,
names="action")
데이터도 많고 속성 갯수도 장난아니다보니, info도 평소 보던거랑 조금 다르게 나온다.

라벨 데이터는 속성이 1개 뿐이고, 대부분 행동들 갯수가 균일하게 나온다.
y_train["action"].value_counts()
일단 기본 결정트리로 학습하고 성능을 살펴보자
기본 설정대로 한 경우 0.857482 정도의 성능이 나온다.

이번에 그리드 탐색 교차 검증으로 최적 하이퍼 파라미터를 찾아보려고 한다.
이전 글에서 파람 썻던걸 참고해서 사용해보자
ref: throwexception.tistory.com/1038
데이터는 많지만 다음과 같이 파라미터들을 지정해서 동작시켜보면 ..
데이터 수도 많은데다 파라미터도 다양하게 주다보니 조금 오래걸린다.
from sklearn.model_selection import GridSearchCV
param = {
"max_depth" : [10, 20, None],
"min_samples_leaf" : [1, 6],
"max_features" : [100, None]
}
gs = GridSearchCV(dt,param_grid=param,cv=5, refit=True)
gs.fit(X_train, y_train)
최적의 하이퍼 파라미터와 성능

다른 경우들을 비교해보면 0.84~ 0.85대 정도 나오고 있다.
gs_result_df = pd.DataFrame(gs.cv_results_)
gs_result_df[["params", "mean_test_score", "mean_train_score"]]

분류에서 가장 중요한 변수들을 살펴보자
best_dt = gs.best_estimator_
feature_importances = best_dt.feature_importances_
ftr_importances = pd.Series(feature_importances, index=X_train.columns)
ftr_top10 = ftr_importances.sort_values(ascending=False)[:10]
plt.title("Feature importance top 10")
sns.barplot(x=ftr_top10, y=ftr_top10.index)
'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 11. 보팅 분류기로 유방암 악성여부 판단하기 (0) | 2020.11.26 |
|---|---|
| 파이썬머신러닝 - 10. 앙상블 모델 개요 (0) | 2020.11.26 |
| 파이썬머신러닝 - 8. 결정 트리 (0) | 2020.11.25 |
| 파이썬머신러닝 - 7. 피마 인디언들의 당뇨병 여부 예측하기 (0) | 2020.11.24 |
| 파이썬머신러닝 - 6. 성능 평가 지표 (0) | 2020.11.24 |