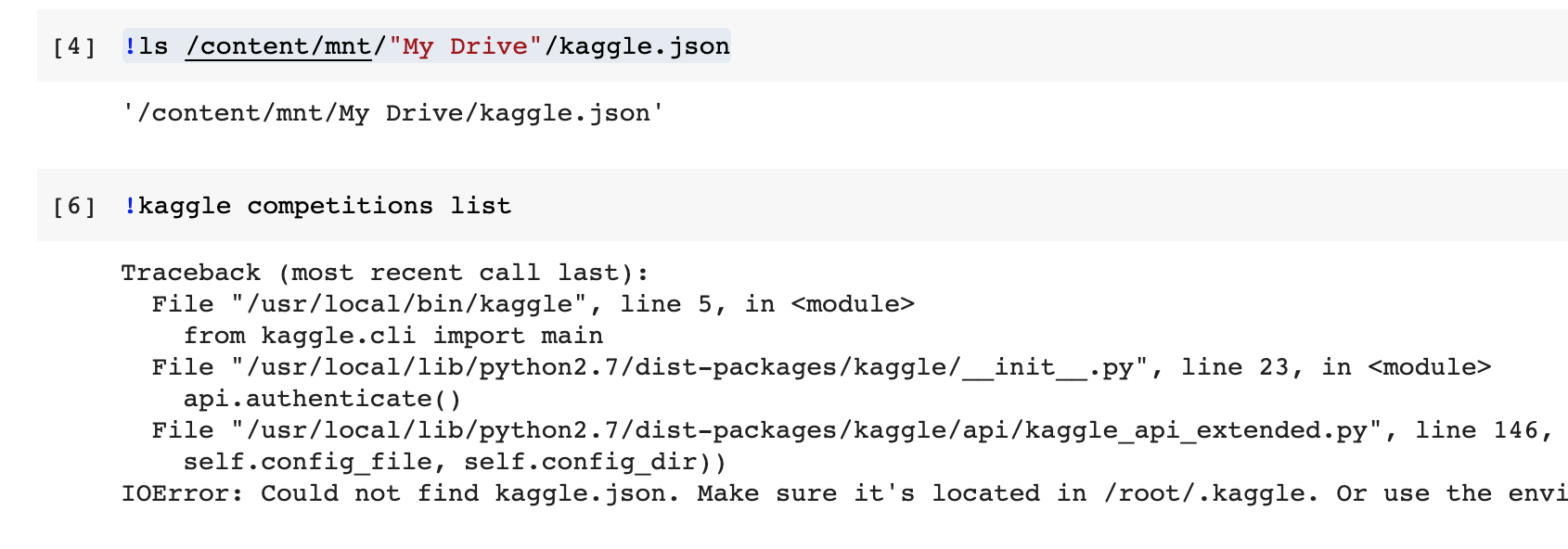
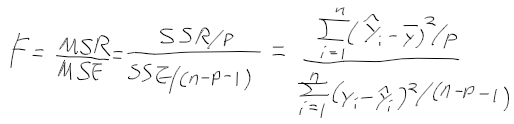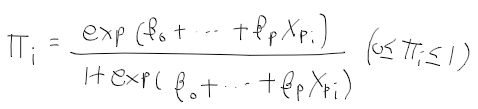Selective Search for Object Recognition 물체 인식을 위한 선택적 탐색
J. R. R. Uijings et al, IJCV13
요약
- 이 논문은 물체 인식에서 사용하기 위한 물체 위치를 찾기 위한 방법을 다룸.
- exhaustive search(완전 탐색)과 세그먼테이션의 강점을 합친 선택적 탐색 방법을 소개
- 세그먼테이션처럼 샘플링 과정에서 이미지 구조를 사용함.
- 완전 탐색 방법과 같이 모든 가능한 물체 위치들을 캡처함.
- 가능한 물체 위치를 만드는데 하나의 기술만 사용하기 보다는, 가능한 많은 이미지 분할 경으로 다각화해서 탐색함.
- 선택적 탐색 방법은 적은 수의 데이터에, 클래스 독립적이며.. 아무튼 좋은 성능을 보임.
- 완전 탐색 방법과 비교해서 이 방법으로 더좋은 머신 러닝 기법이나 물체인식 모델을 사용할수 있게 되었다.
- 선택적 탐색 방법 덕분에 단어 가방도 사용할수 있게 되었음.
* 단어 가방 bag of words : 정보 검색에서의 경우 문서를 단어 벡터로 만들어 표현하는 방식
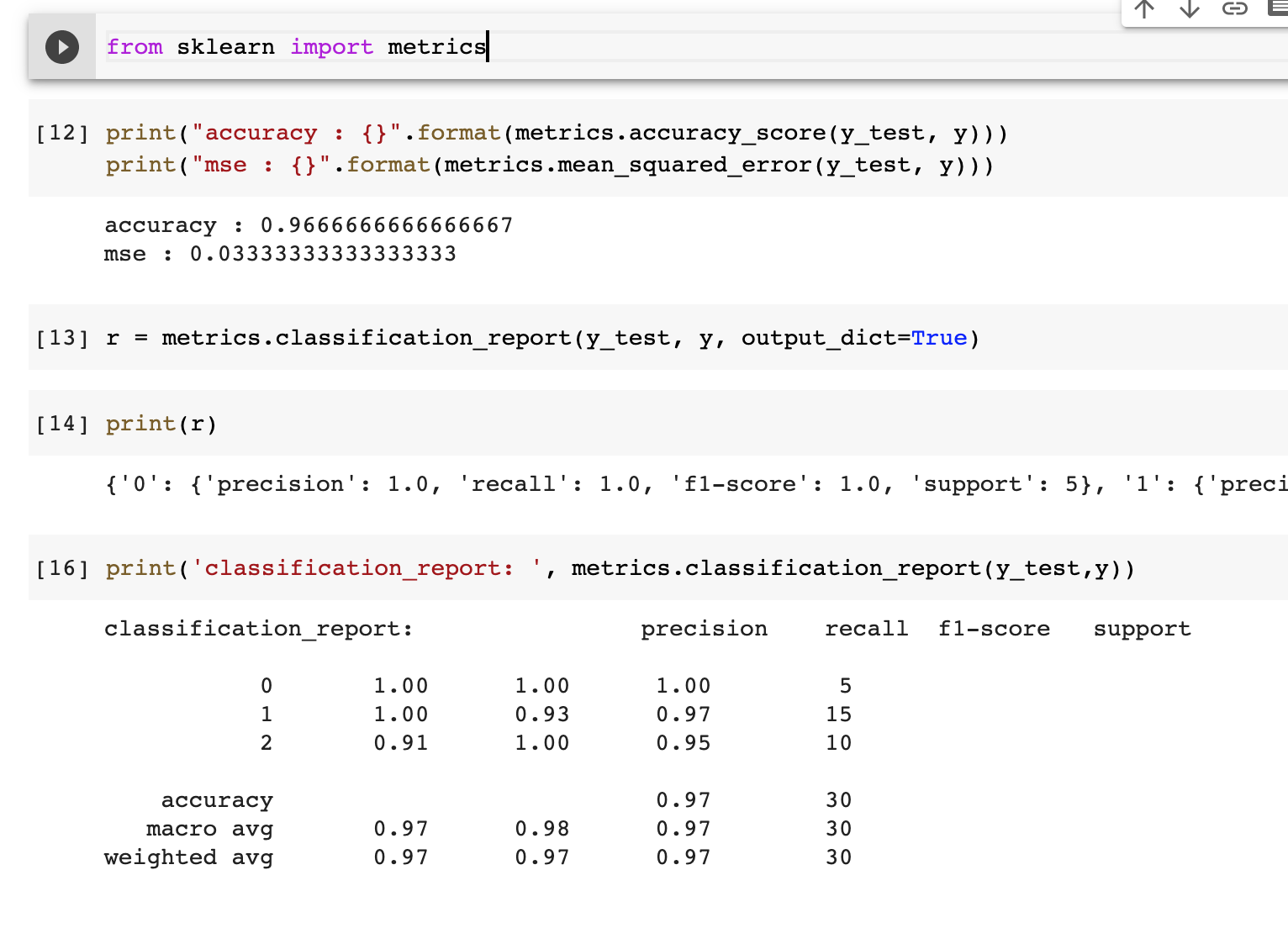
소개
- 오랜 시간동안, 물체 인식보다 어디있는지 찾는게 오래 다루어짐.
- 유전 알고리즘으로 이미지 영역 분할하고자 하는 세그먼테이션이 뜨게됨.
* 유전 알고리즘 : 적응적으로 최적해를 찾아내는 알고리즘
- 하지만 이미지는 본질적으로 계층적임. 그림 1a 샐러드와 스푼은 샐러드볼 안에 있음. 샐러드볼은 테이블위에있고
- 그래서 자연 이미지나 다른 용도의 물체들은 계층적으로 있음.
- 이 문제 때문에 특정 목적용을 제외하고 모든 물체가 고유의 영역을 갖도록 분할하기가 힘듬.
- 세그먼테이션에서 여러개의 척도가 필요함.
- Arbelaez가 이에 대해서 계층적 분할을 다루는 연구를 함.

그림 1. 물체를 이루는 다양한 이미지 영역들
b) 고양이는 색으로 구분할 수 있지만 질감으론 힘듬.
c) 카멜래온은 질감으로 구분할수 있으나 색상으로 힘듬.
d) 바퀴는 차에 붙어있는 일부분이지만, 색상이나 질감은 다름.
그러므로 물체를 찾기 위해서는 다양한 전략들을 사용해야함. 그러므로 이미지는 본질적으로 계층적이라 할수 있음.
a)에서 테이블, 샐러드볼, 샐러드 스푼은 한가지 척도만으로 다 찾아낼수는 없음.
- 세그먼테이션은 계층적이기 때문에, 단일 전략으로 세그먼테이션을 위한 유전적 해결법은 존재하지 않음.
- 이러한 이유로 영역들을 하나의 그룹으로 묶여야만함.
- 그림 1b서 고양이들은 색상으로 분리할수 있지만, 질감은 같음
- 반대로 그림 1c 카멜레온은 주변의 잎과 색상이 비슷하지만 질감이 다름.
- 그림 1d의 휠은 차와 색상, 질감 둘다 다름.
- 개별적인 시각적 특징으로 세그먼테이션의 애매함을 풀기는 힘들다.
각 물체가 하나의 물체로 인식하는 경우
- 여기에다 더 구조적인 문제가 존재하는데, 서로 다른 특성을 가진 영역들(물체가 사람으로 인식된 후에 스웨터 위에 얼굴은)은 하나의 물체로 묶일수도 있음.
- 그래서 사전 인식 없이 얼굴과 스웨터가 한 물체의 일부인지 결정하기가 힘듬.
Z. Tu, X. Image parsing: Unifying segmentation, detection and recognition. IJCV, Marr Prize Issue, 2005. 1
- 이 문제 때문에, 다른 방법으로 물체 인식을 통한 위치를 찾아보게 되었음.
- 이 방법 덕분에 물체 인식 분야가 최근에 크게 진보함.
N. Dalal. Histograms of oriented gradients for human detection. In CVPR, 2005
P. F. Felzenszwalb, Object detection with discriminatively trained part based models. TPAMI, 2010. 1,
H. Harzallah. Combining efficient object localization and image classification. In ICCV, 2009. 1,
P. Viola. Rapid object detection using a boosted cascade of simple features. In CVPR, 2001.
완전 탐색 방법의 한계
- 완전 탐색 방법은 이미지내 존재하는 모든 위치를 잠재적인 물체 위치를 놓치지 않도록 검사함.
- 하지만 완전 탐색 방법은 많은 결점을 가짐.
- 가능한 모든 위치를 탐색한다는것은 계산하기 불가능함.
- 탐색 공간은 격자와 고정 크기, 고정 종횡비에 따라 줄일수 있어야함.
- 많은 경우 탐색할 공간이 크므로 제약 조건들이 필요함.
- 분류기는 간편하며, 외형 모델 appearance은 빨라야만함.
- 균일 샘플들이 너무많은 박스들을 찾아내서 객체를 찾는대 도움되지 않음.(?)
Furthermore, a uniform sampling yields many boxes for which it is immediately clear that they are not supportive of an object.
- 탐색적 방법을 사용한 위치 샘플링 보다는 데이터 기반 분석으로 샘플링을 할수 있지는 않을까?
선택적 탐색적 방법의 목표
- 이 논문은 세그먼테이션과, 완전 탐색을 합하여 데이터 기반인 선택적 탐색을 제안함.
- 바텀업 세그먼테이션을 참고하여 이미지 구조를 활용하여 물체 위치들을 생성하고,
- 완전 탐색을 참고하여, 가능한 모든 객체 위치를 찾아내고자함.
- 단일 위치 샘플링 기술쓰기 대신에 가능한 많은 이미지에 사용할수 있도록 샘플링 기술들을 다각화하고자함.
- 특히, 데이터 주도 그루핑 전략를 사용.
-> 다양한 상호보완적인 그룹 기준과 불변성을 가진 다양한 색상 공간을 사용하여 다양성을 높여냄.
- 파티션들의 위치를 합쳐 위치들을 얻음.
- 목표 클래스 독립이며, 데이터 주도, 선택적 탐색 방법으로 적은 종류의 고퀄리티 물체 위치들을 만들어내는것임.
- 선택적 탐색 방법의 주요 활용 분야는 물체 인식임. 그래서 평가에는 파스칼 VOC 대회 데이터를 사용함.
- 데이터셋의 크기는 선택적 탐색을 사용하기에는 비용적으로 제약이 되나.
- 이 데이터셋을 사용하여 바운딩 박스의 위치 퀄리티를 주로 평가했엇음.
- 우리 방법은 잘 영역들을 분할함.
- 물체 인식을 위한 선택적 탐색 방법을 제안.
- 주요 연구에 대한 질문으로 다음의 3가지가 있음
- 1) 적응적 분할을 위해 좋은 다양화 전략이 무엇이 있을까?
- 2) 어떻게 선택적 탐색이 이미지 안에 존재하는 작은 고퀄리티의 위치를 찾아낼까.
- 3) 물체 인식을 위해 선택적 탐색 방법을 좋은 분류기와 외형 모델에 사용할수 있을까?
관련연구
- 물체 인식 분야에 대해 3가지 카테고리로 보고자 함.
- 완전 탐색 방법, 분할, 다른 샘플링 전략
완전 탐색 방법 exhaustive search 관련 연구
- 물체는 이미지의 어느 위치나 척도상에 존재.
H. Harzallah Combining efficient object localization and image classification. In ICCV, 2009. 1
- 하지만 시각적인 탐색 공간은 너무 큼, 완전 탐색 방법을 하기에는 계산 비용이너무 큼
- 그래서 위치나 고려해야하는 위치의 개수에 따라서 평가 비용을 제한을 함.
- 대부분 경우 슬라이딩 윈도우 방식은 격자형, 고정비의 그리드를 사용함.
- 약 분류기와 HOG 같은 이미지 특징 추출기 사용함.
- 이 방법은 폭포수 분류기의 선 선택 단계에서 자주 사용.
P. Viola and M. J. Jones. Robust real-time face detection. IJCV, 57:137–154, 2004.
- 슬라이딩 윈도우 관련 기술은 성공적인 파트 기반 물체 위치찾기 방법이었음.
P. F. Felzenszwalb. Object detection with discriminatively trained part based models. TPAMI, 2010. 1
- 이 연구에선 선형 SVM, HOG 피처를 사용한 완전 탐색을 사용함.
- 하지만 물체와 물체의 파트들을 찾아냄. 이들의 조합은 좋은 물체인식 성능을 보임.
Lampert의 외형 모델
- Lampert는 탐색을 위한 외형 모델을 사용하는 방법을 제안.
- 이 방법에서 고정 규격 그리드, 스케일, 종횡비제약을 완화함.
- 동시에 찾아야할 위치 수를 줄여냄
- 분기 한정 기술로 이미지내에 최적의 윈도우로 탐색을 수행했음.
- 선형 분류기로 좋은 결과를 얻었고, alexe는 비선형 분류기를 사용했는데 100,000개 윈도우를 찾음.
B. Alexe, T. Deselaers, and V. Ferrari. What is an object? In CVPR, 2010. 2, 6
- 맹목적 완전 탐색 방법이나 분기 한정법(branch and boung)탐색 대신 우리는 선택적 탐색 제안
- 이미지 구조로 물체 위치들을 생성.
- 앞의 방법들과는 달리 이 방법은 클래스에 독립 적으로 생성.
- 고정된 종횡비를 사용하지 않으므로 우리 방법은 물체에 한정하지 않고, "잔디"나 "모래" 같은 것들도 찾아낼수 있음.
- 마지막으로 적은 위치들을 찾기를 원하므로, 샘플을 다양성을 낮춤으로서 할수 있다.
- 더 중요한건 계산량을 크게 줄여 강한 머신러닝 기술이나 외양 모델을 사용할 수 있음.
세그먼테이션
- Carreira나 Endres는 세그먼테이션을 이용한 클래스에 독립적인 물체 가설들을 생성하는 방법들을 제안
J. Carreira. Constrained parametric mincuts for automatic object segmentation. In CVPR, 2010.
I. Endres and D. Hoiem. Category independent object proposals. In ECCV, 2010. 2
- 이 방법 둘다 다중으로 전경/배경 세그먼테이션들을 만듦.
- 전경의 세그먼트가 완전한 객체일 가능성을 예측하는 방법을 배우고, 이로 세그먼트의 순위를 매김
- 두 알고리즘다 이미지에 있는 물체들이 얼마나 정확한지에 대한 정도를 보여줌.
- 세그먼테이션에서 공통적으로, 두가지 방법다 좋은 영역들을 식별하는데 한가지 강한 알고리즘에 의존함.
- 이 방법들은 임의로 초기화된 전경과 배경으로 다양한 위치를 찾아냄.
- 반대로 우리의 방법은 다른 그룹 기준과 다른 표현들을 사용하여 다양한 이미지 상태에서 대처할수 있음.
- 비싼 윤곽선 검출기 같은 단일한 최적의 분할 방법을 하는것이 아니라 적은 계산 비용을 가짐.
- 우리건 이미지 상태를 분할해서 다룰수 있고, 일관성 있는 위치를 구할 수 있게됨.
중간 생략
- 정리하자면, 우리의 새로운 방법은 완전 탐색을 사용하는 대신, 세그먼테이션으로 클래스 독립인 물체 위치들을 구함.
- 세그먼테이션과는 달리. 하나의 강한 세그먼테이션 알고리즘(윤곽선을 이용한 이미지 분할같은)을 사용하기 보다는
P. Arbelae. Contour ´ detection and hierarchical image segmentation. TPAMI, 2011.
- 많은 이미지조건을 다룰수 있는 다양한 방법들을 사용
- 계산 비용은 줄이고, 더 많은 잠재적인 물체들을 찾아낼수 있었음.
- 임의로 샘플링된 박스에 객관성 측정을 학습하는 대신, 좋은 물체 위치를 구하기 위해 바텀업 그룹방식을 사용.
--------------------------------------
한 2시간 동안 보면서
겨우 2페이지 밖에 보지 못했다.
하지만 컴퓨터 비전 분야에서
한창 뜨고 있는 다중 물체 인식 기술의 바탕이라 할수 있는
물체 분할에서
물체 분할의 한 방법인 selective search 방법에 대해 보니
기존 교재나 영상 강의로는 부족했던 깊은 내용들을 배울수 있었다.
이전에 오일석 교수님의 교재를 보고나서
이미지 분할 방법으로 물체 분할시 색상으로 분할할수 있는건 알았지만
질감으로도 분할 할수 있다는 방법은 잊고 있었다.
이미지 분할에 있어서
이미지가 계층적인지도 몰랐고,
색상 기준으로만, 질감 기준으로만 할수도 없이 다양한 방법들을 혼합해야되는걸 알았다.
계속 이 내용들을 번역해 가면서
선택적 탐색 방법의 기반이 되는
완전 탐색과 세그먼테이션에 대해서 살짝 살펴볼수 있어서 좋았다.
이미지 분할 연구에 대한 10년간의 역사를
간단하게 훑어봤다고 생각하면
2시간 동안 2페이지를 본 거지만 위안삼아도 될까..?
이런 내용들을 훨신 간결하게 정리해 놓은 사람들은 많다.
개인적으로는 나도 시간없어서 대충 적으면서 넘어가지만 좋아하지는 않는다.
이미 아는 사람들이야 생략하고 넘어가도 되지만
모르는 사람에게 한 기술에 대해 간결하게 설명하고 넘어가면
대강 어떻게 동작하는구나는 이해시키고 넘어갈 수는 있어도
어떻게 활용을 할수 있는지, 구현을 할지, 좀더 큰 범위에서 활용하기는 힘들 것이다.
기술에서 만들어진 배경과 맥락들을 파악하지 않고서는 답답한게 너무 많다.
그래서 정리하면 다 하거나 너무 대충대충할떄가 많다.
아무튼 오늘은 개요와 관련 기술에 대해 정리하였으니
내일 선택적 탐색 방법 위주로 하고자 한다.