728x90
2020-07-31
- 지난 시간에는 개선된 어셈블리어 코드를 이용한 부팅 가능한 이미지 파일 구현 방법과 병렬 처리 프로그래밍 openmp를 마무리 하고, 기술자에 대해서 조금 더 깊이 학습하여 주성분 분석과 얼굴 인식을 위한 고유 얼굴 검출 등 까지 과정들을 살펴보았습니다.
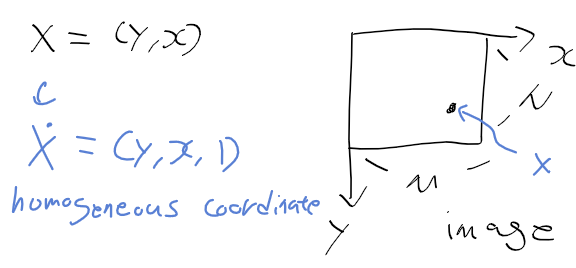
- 이번 시간에는 영상 위주로 학습을 진행하면서, 영상의 한 점에 대한 좌표와 특징 벡터로 이루어진 키포인트들 간에 매칭에 관한 전반들을 다루었습니다. 여기서 동일한 물체가 나오나 서로다른 영상에 존재하는 특징들을 매칭 시켜주기 위한 쌍을 찾고 어떠한 방식으로 최적의 쌍과 기하 정렬을 구하는지 살펴보았습니다.
- 우선 가장 처음으로 매칭에 대해서 학습하였습니다. 매칭이란 서로 다른 영상 간에 존재하는 특징점 쌍이 서로 동일한 것인지 확인하는 과정이라 할수 있는데 이를 위해 유사도나 거리를 측정하여 매칭한 것인지 찾게 됩니다. 대표적인 특징으로 에지와 지역특징, 영역 등이 있으나 주로 매칭시에는 지역 특징이 사용되며 서로 다른 영상에 존재하는 특징들 간에 거리를 계산하기 위한 방법으로 유클리디안 거리와 마할라 노비스 거리가 있었습니다.
- 유클리디안 거리는 두 벡터 사이 요소 간의 차에 대한 노름으로 정리 할수 있었습니다. 하지만 유클리디안 거리는 데이터 분포에 대한 요소를 고려하지 못해 올바르지 않은 특징을 대응쌍으로 판단할수 있었습니다. 이를 개선한 마할라 노비스 거리는 유클리디안 거리 계산 중간에 데이터의 공분산 행렬을 추가하여 데이터 샘플 분포를 반영시킨 것으로 더 정확한 거리라고 할수 있었습니다. 추가적으로 매칭 성능을 판단하는 ROC 곡선에 대해서도 간단히 살펴보고 다음으로 kd 트리에 대해서 살펴보았습니다.
- 컴퓨터 비전에서 kd트리는 최근접 이웃인 특징을 빠르게 찾기위한 자료구조로 활용되었습니다. 한 영상에서 루트 노드로부터 분기해 나가면서 kd 트리를 만든다면, 다른 영상에서 구한 특징 즉 새로운 입력 특징이 주어질때 kd 트리를 이용하여 고속으로 최근접 이웃인 특징을 찾을수 있었습니다.
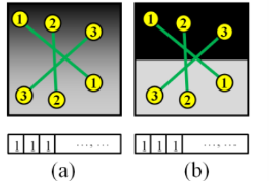
- 하지만 더 자세히 살펴보면 kd 트리를 이용해 최근접 이웃을 구하는 과정에서 지역 특징을 사용하다보면 기하 정렬 조건이 고려되지 않아 잘못된 형태의 매칭을 만들수 있습니다. 이러한 기하 정렬을 고려한 대표적인 알고리즘으로 최소 제곱법과 RANSAC 알고리즘을 사용하여 매칭을 수행하는 경우가 있었습니다. 최소 제곱법은 두 영상에서 구한 특징들 간에 오차를 최소한으로 하는 기하 변환 행렬을 구할수 있었으며, RANSAC에서는 거짓 긍정 오류가 존재하는 영상에 대해서 잘못된 특징쌍 즉, 노이즈를 제거하여 실제와 가까운 모델을 구할수 있었습니다.
- 이번 시간에는 매칭에 대한 거리 개념과 자료 구조, 최근접 이웃, 그리고 이를 기하 정렬을 고려하여 매칭을 하기 위한 알고리즘들 까지 전반에 대해서 살펴보았습니다. 사실 수식도 정리하고 더 깊이 살펴볼수 있는 내용들이기는 하나 깊이 있는 학습은 다음에 진행하고, 우선은 컴퓨터 비전 전체적인 범위를 살펴보는게 우선인 만큼 매칭에 관련된 개념과 알고리즘, 동작 과정이 어떻게 수행되구나 정도 까지만 학습하였습니다. 다음 시간에는 본격적으로 컴퓨터 비전에서의 인공지능, 기계학습 알고리즘과 활요에 대해서 학습해가고자 합니다.
300x250
'미분류' 카테고리의 다른 글
| 2020-08-02 (0) | 2020.08.02 |
|---|---|
| 카이스트 vr-ar (0) | 2020.08.01 |
| 2020-07-30 (0) | 2020.07.31 |
| 2020-07-29 (0) | 2020.07.30 |
| 2020-07-28 (0) | 2020.07.30 |