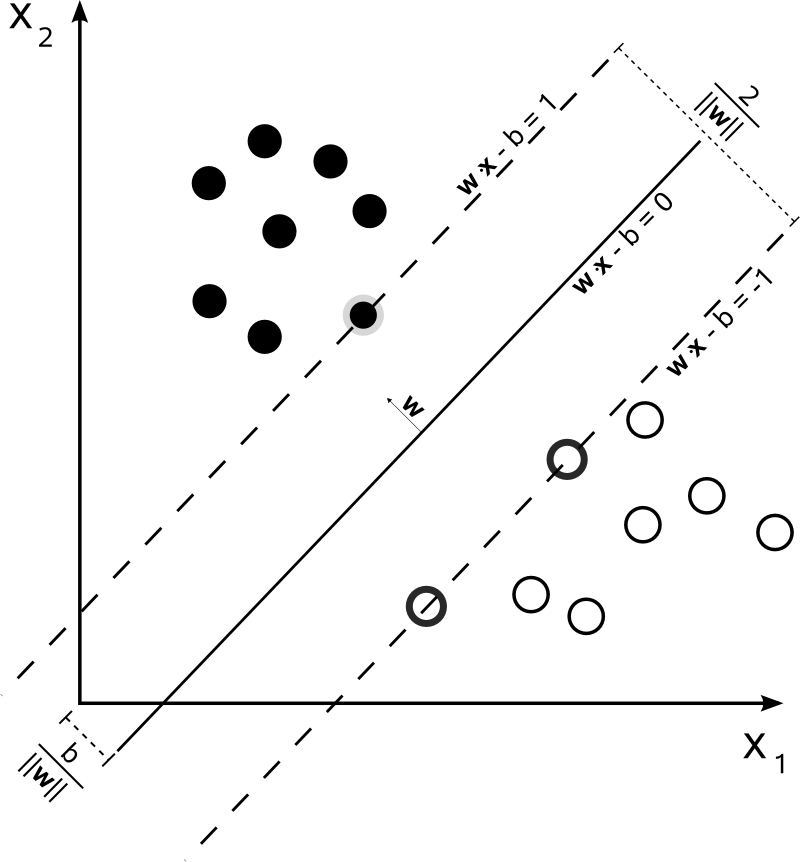
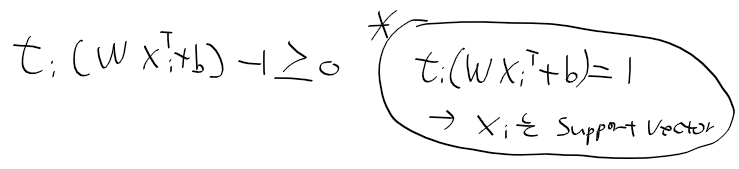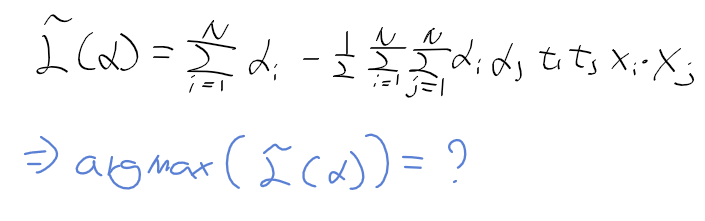728x90
텍스트 에디터
- Scite 사용

준비하기
- tolset 안에다가 hellos3 폴더를 복붙하고
- helloos.nas를 열자

한글깨짐
- 이건 일본어 원문 자료에서 그대로 가져오다보니 주석들이 다깨진듯 하다..

- utf-8로 고쳐주고
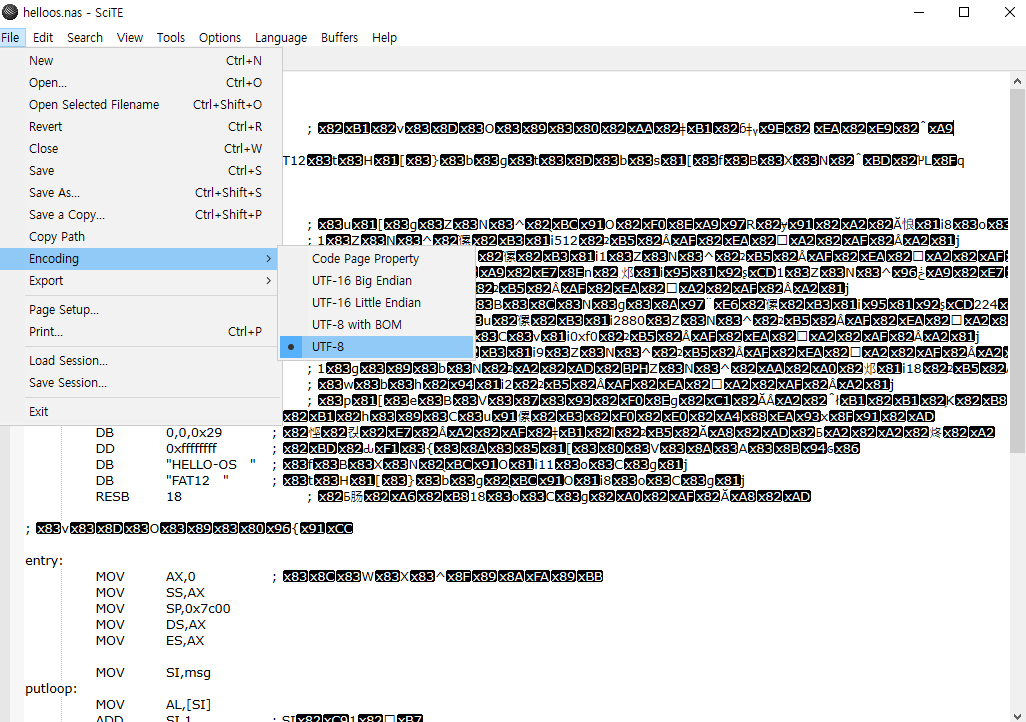
- 불편해서 안되겠다. vscode 쓰자

다고친 결과
- 파일 열때 깨진 주석들을 다 한글로 고침

- 고친 결과
; hello-os---------------------------------------------------------
; TAB=4
ORG 0x7c00 ; 메모리 안에서 로딩되는 곳
; 아래는 표준 FAT12 포맷 플로피 디스켓을 위한 내용들
JMP entry
DB 0x90
DB "HELLOIPL" ; 부트섹터 이름. 마음대로해도 ok
DW 512 ; 1섹터 크기(바이트 단위, 512)
DB 1 ; 클러스터 크기(1로 해야됨)
DW 1 ; 예약된 섹터수
DB 2 ; 디스크 FAT 테이블 수
DW 224 ; 루트 디렉토리 엔트리 수 (보통 224엔트리)
DW 2880 ; 디스크 총섹터수
DW 0xf0 ; 미디어 타입
DW 9 ; 하나의 FAT 테이블 섹터 수
DW 18 ; 1트랙에 몇 색터가있는지
DW 2 ; 헤드의 수
DD 0 ; 파티션 없으므로 0
DD 2880 ; 드라이브 크기 한번더씀
DB 0, 0, 0x29 ; 필요하다고함
DD 0xffffffff ; 볼륨 시리얼 번호
DB "HELLO-OS " ; 디스크 이름
DB "FAT12 " ; 포멧이름
RESB 18 ; 18바이트 남김
; 프로그램 본체
entry:
MOV AX,0 ; 레지스터 초기화
MOV SS,AX
MOV SP,0x7c00
MOV DS,AX
MOV ES,AX
MOV SI,msg
putloop:
MOV AL,[SI]
ADD SI,1 ; SI에 1 더함
CMP AL,0
JE fin
MOV AH,0x0e ; 한 문자 표시 기능
MOV BX,15 ; 컬러 코드
INT 0x10 ; 비디오 BIOS 호출
JMP putloop
fin:
HLT ; CPU 정지 시킴
JMP fin ; 무한 루프
msg:
DB 0x0a, 0x0a ; 줄바꿈 문자 2개
DB "hello, world"
DB 0x0a ; 줄바꿈
DB 0
RESB 0x7dfe-$ ; 나머지칸 0채우기
DB 0x55, 0xaa
; 부트섹터 이외 부분에 적을 내용들
DB 0xf0, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x00
RESB 4600
DB 0xf0, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x00
RESB 1469432
300x250
'컴퓨터과학 > 컴퓨터, OS' 카테고리의 다른 글
| os만들기 - 8. 어셈블리 명령어들과 부트섹터 이미지 생성 (0) | 2020.08.01 |
|---|---|
| os만들기 - 7. 어셈블리어 기본 명령어와 레지스터 (0) | 2020.08.01 |
| os만들기 - 5. 첫 어셈블러 고치기 (0) | 2020.07.30 |
| os만들기 - 4. 어셈블러 체험 (0) | 2020.07.30 |
| os만들기 - 3. 글자찍히는 부팅가능한 바이너리 이미지 만들기 (0) | 2020.07.29 |