728x90
pi 계산 순차 코드
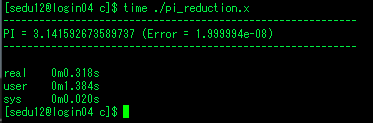
- 실행결과 1.326s 소요


어떻게 고칠까
- for문이 로드가 걸릴거같다 -> 병렬 처리
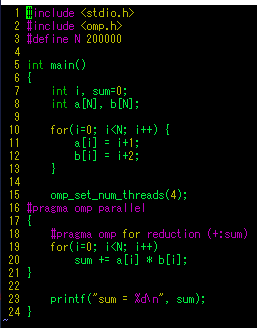
- private 할지 shared할지 결정해야함 : x 는 private, sum은 누적이므로 reduction 사용
병렬화 결과
- 일단 사용할 스래드 갯수 5개로 설정
- sum은 각 스래드별로 계산후 다합칠것이므로 reduction
- x는 각 스래드마다 개별로 가져야하므로 private
* private을 안하면 다른 스레드의 x값이 덮어씌워줄수 있음.
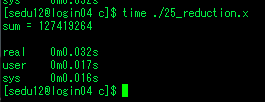
- 순차 코드에서 1.326s가 소요됬으나, 병렬 코드에서는 0.318s가 소요

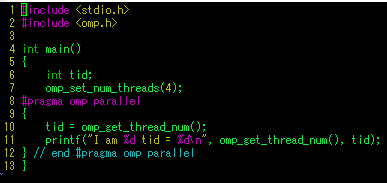
* #pragma omp parallel 과 parallel for의 차이
- prallel만 있는 경우 { } 병렬영역을 괄호로 지정해주어야 함
- parallel for의 경우 #pragma 바로 아래의 for문에만 영향을 줌
300x250
'컴퓨터과학 > 기타' 카테고리의 다른 글
| openmp - 19. 중첩 스레드 (0) | 2020.07.30 |
|---|---|
| openmp - 18. 병렬 블록, 포크 조인, 동기화 문제 (0) | 2020.07.30 |
| openmp - 16. reduction과 factorial (0) | 2020.07.29 |
| openmp - 15. reduction (0) | 2020.07.29 |
| openmp - 14. 동기화 (0) | 2020.07.29 |