728x90
2020-07-29
- 지난 시간에는 영상에 존재하는 경계점인 에지와 선분 검출 알고리즘, 그리고 지역 특징에 대한 개요에 대한 내용을 살펴보면서 비전 분야 학습을 진행하였고, 이외에 해킹 관련 기본 개념들과 바이너리 에디터로 기계어 코딩을 직접하여 부팅 가능한 이미지를 구현해보았습니다. 이번 시간에는 대표적인 지역 특징 검출 알고리즘인 SIFT와 SURF에 대해서 살펴보고, 영역 분할 알고리즘 그리고 이러한 특징에 대한 추가 정보인 특징 기술자가 무엇인지 살펴보았습니다. 또 병렬 프로그래밍 플랫폼인 openmp에 대한 개요적인 내용과 사용법을 학습하고, 키보드 후킹과 이미지 파일을 해킹하는 윈도우 어플리케이션 해킹 예제들을 통한 학습을 진행하였습니다.
- 우선 대표적인 지역 특징 검출 알고리즘인 SIFT와 SURF에 대해서 학습하였습니다. 우선 SIFT는 영상의 크기에 불변하는 지역 특징 알고리즘이라 할수 있는데, 입력 영상이 주어지면 이를 다양한 스캐일로 만들고, 여러 분포에 대한 가우시안 영상을 차분한 차분 영상을 획득합니다. 다중 스케일 차분 영상들에서 구한 특징들이 SIFT 키포인트가 되었습니다. 하지만 SIFT 알고리즘에서는 여러개의 영상에 대해 가우시안 마스크를 적용하고 차분 영상을 얻기까지에 대한 과정은 상당히 많은 계산량을 요구하여 시간이 오래걸리는 단점이 있었습니다. 이러한 문제를 극복한 SURF 알고리즘은 가우시안 필터를 박스 필터로 근사화하여 적분 영상을 이용해 박스필터들을 적용하는 방법을 사용하여, 기존의 SIFT 검출 알고리즘보다 훨씬 빠른 시간에 크기에 불변한 특징점들을 검출할수 있었습니다.
- SIFT와 SURF 지역 특징 검출 알고리즘 다음으로 이미지의 영역을 분할하는 방법에 대해서 살펴보았습니다. 가장 간단한 것으로 임계치를 이용한 이진화, 색상 영역을 이용한 분할, 최소 신장 트리나 정규화 영상을 사용한 그래프 기반 방법 그리고 민시프트로 대표되는 클러스터링 알고리즘 기반 영역 분할 방법들이 존재하였습니다. 그래프 기반 방법 중에 최소 신장 트리 방법에서는 영상을 그래프의 형태로 구현하고, 이 그래프에 대한 최소 신장 트리를 만듦으로서 영상 영역들을 구분하는 방법이었습니다. 정규화 절단 방법의 경우 입력 영상을 유사도 그래프와 인접 행렬로 표현하고 연결 요소들을 분할되도록 계산하는 과정을반복하여 비슷한 영역들을 분할하는 방법이었습니다.
- 이 외에 추가적인 클러스터링 기반 영역 분할 방법들도 살펴보았습니다. 일단 클러스터링에 앞서 샘플들과 이 샘플들을 나타내는 확률 밀도 함수 그리고 그 함수의 봉우리인 모드의 개념을 보고, 클러스터링 문제를 다루기 시작하였습니다. 클러스터링 알고리즘 중 가장 대표적인 알고리즘이 kmeans 부터, 물체 추적에 자주 사용되는 민시프트, 그리고 DBSCAN까지 각 클러스터링 알고리즘의 특성과 장단점을 살펴보고, 민시프트 알고리즘이 물체 추적과 영상 분할에 어떻게 사용되는지 이해하는데 도움되었습니다.
- 영상처리의 마지막으로 특징 기술자에 대해서 학습을 진행하였습니다. 기술자란 지역 특징이 제공하지 못한 특징에 관한 추가적인 정보로 지역 특징이 해당 점의 위치와 스케일 정보만 제공한다면 기술자는 방향과 특징 벡터를 제공한다고 할수 있습니다. 이전에 살펴본 SIFT, SURF 특징은 스케일에 불변하는 특징이나 회전 불변에 필요한 정보들을 가지고 있지 않습니다. 그런 문제를 개선하기 위해서 특징 기술자가 필요하게 됩니다. 특징 기술자는 키포인트를 중심으로 커널을 씌워 윈도우 내부에 있는 픽셀들의 그라디언트 영상을 만들고, 이를 8단계로 양자화하여 그라디언트 방향 히스토그램을 만들어 주요방향을 찾습니다. 이 그라디언트 방향 히스토그램이 기술자 특징 벡터가 됩니다. 그래서 SIFT 기술자를 추출한다는 것은 기존의 키포인트, 특징점이 주어지면 이 키포인트에 주요 방향과 특징 벡터가 추가된 키포인트를 기술자라고 할수 있겠습니다.
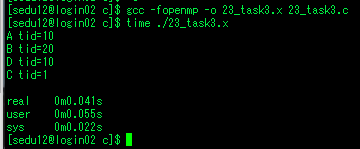
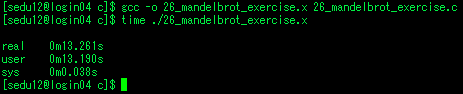
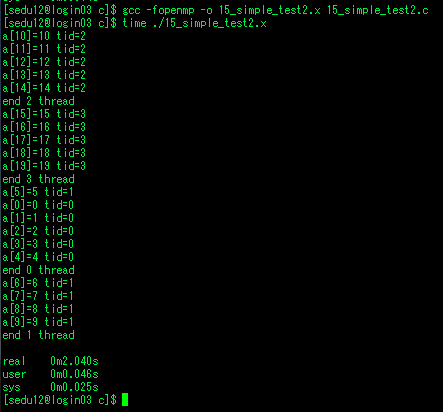
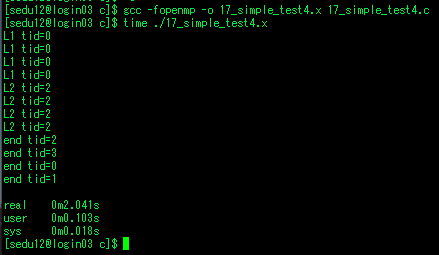
- 오늘 영상 학습 하는 동안 영상 특징과 기술자, 분할 기술에 대해서 살펴보고, 나머지 시간에는 병렬 프로그래밍 플랫폼인 openmp와 윈도우 해킹에 대해서 학습을 했습니다. 이전에 openmp는 opencv를 빌드하거나 다른 오픈소스를 빌드하면서 종종 본 이름이고, 병렬프로그래밍을 수행한다는것은 알고 있었으나 이게 어떻게 한다는것인지 잘 몰랐습니다. 우연히 openmp 수업에 참여할수 있는 기회를 얻게 되어 수업에 참관하면서 openmp가 무엇인지 병렬프로그래밍을 어떻게 하고, 성능 개선이 이루어지는지 등에 대해 배울수 있었습니다.
- 마지막으로 윈도우 해킹과 관련된 내용들을 학습하였습니다. 32비트 윈도우에서는 자원을 제어하기 위한 WIN32API를 제공하고 있었습니다. 이 API와 제공하는 DLL을 통해 메시지를 후킹을 해보았으며, 별개로 이미지 파일을 임의로 수정하여 자바스크립트를 삽입하는 실습을 진행하였습니다. 먼저 키보드 후킹 예제를 연습해 보았습니다. kernel32.dll로부터 후킹 함수를 가져와 키로거 클래스를 정의하여 키 입력들이 오면 출력하고 ctrl을 누르면 종료되도록 구현하였습니다. 이미지 해킹 과정으로 기존의 비트맵 이미지를 파일 입출력 함수로 읽어들여 데이터 부분들을 주석처리하고 뒤에 알람을 띄우는 js 코드를 추가하도록 수정하였습니다. 이 수정된 비트맵 파일을 간단한 html에서 로드하면 이미지 파일 내에 존재하는 js코드가 실행되는 모습을 확인하였고, 악의적인 코드를 입력한다면 상당히 위험할수도 있을것 같아보였습니다.
- 이번시간에는 특징점, 영상분할, 기술자 등 비전 분야 내용들과 openmp의 기본사용법 그리고 간단한 윈도우 어플리케이션 해킹 실습을 해보았습니다. 내일은 openmp 나머지 내용을 학습하고, 이전에 기계어로 부팅 이미지를 만들었던것을 개선하여 어셈블리어로 구현하기, 영역 기술자, 주성분 분석 등 영상 파트 내용들을 학습할 예정입니다.
300x250
'미분류' 카테고리의 다른 글
| 2020-07-31 (0) | 2020.07.31 |
|---|---|
| 2020-07-30 (0) | 2020.07.31 |
| 2020-07-28 (0) | 2020.07.30 |
| 2020-07-27 (0) | 2020.07.30 |
| 2020-07-26 (0) | 2020.07.26 |