void Dijkstra()
{
S = {1};
for (i=2; i <= n; i = i + 1)
{
D[i] = C[1, i];
// D[i]는 노드 i에서 노드 j까지의 최단 거리
// C[i, j]는 노드 i에서 노드 j까지의 거리
// 노드 i에서 노드 j로 가는 연결선이 없다면 C[i, j] = inf
}
for (i = 1; i <= n - 1; i = i + 1)
{
V - S에 있는 노드 중에서 D[w]가 최소인 노드 w를 선택;
w를 S에 추가;
V - S에 있는 각 노드 v에 대해 D[v] = min(D[v], D[w] + C[w, v]);
}
}
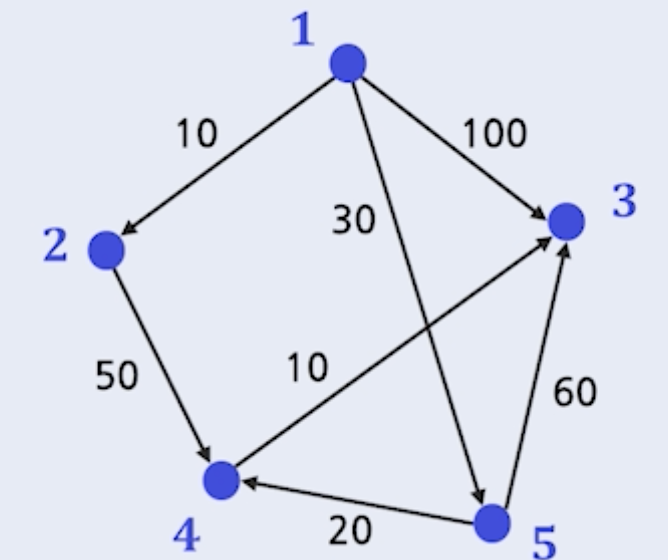
다익스트라 알고리즘의 적용 예시
- 1에서 2까지 최단거리 = 10
- 1에서 3까지 최단거리 = 60
- 1에서 4까지 최단거리 = 50
- 1에서 5까지 최단거리 = 30
그래프의 탐색
1. 탐색 정의
2. 깊이 우선 탐색
3. 너비 우선 탐색
그래프 탐색
- 그래프의 모든 노드를 체계적으로 방문하는 방법
ex) 깊이 우선 탐색, 너비 우선 탐색
메모리 구조
- 스택
- 큐
스택
- LIFO(Last In First Out) 구조를 가지는 메모리 한 형태
큐
- FIFO(First In First Out) 구조를 가지는 메모리 한 형태
깊이 우선 탐색 Depth First Search, DFS 과정
1. 임의의 시작 노드 v를 선택하고 탐색
2. v에 인접한 노드 중
-> 방문하지 않는 노드 w가 있으면 v를 스택에 push하고 w를 방문, 그리고 w를 v로 설정한 뒤 2를 반복
-> 방문하지 않은 노드가 없으면 스택을 pop하여 받은 가장 마지막 방문 노드를 v로 설정한 뒤 2를 방문
3. 스택이 공백이 될 떄 까지 2를 반복
깊이 우선 탐색 과정 예
- A를 우선 탐색 -> 스택
- B를 탐색 -> 스택 A
- D를 탐색 -> 스택 A B
- G를 탐색 -> 스택 A B D
- F를 탐색 -> 스택 A B D G
- F에 인접한 노드가 없음 -> G를 Pop
- E를 탐색 -> 스택 A B D
- C를 탐색 -> 스택 A B D E
- C에 인접한 탐색할 노드 없음 -> E Pop -> 스택 A B D
- D에서 탐색할 노드 없음 -> D pop -> 스택 A B
- B에서 탐색할 노드 없음 -> B pop -> 스택 A
- A에서 탐색할 노드 없음 -> A Pop -> 스택
너비 우선 탐색(Breadth First Search, BFS)
1. 인의의 시작노드 v를 선택하고 이를 탐색한다.
2. v에 인접한 노드 중
- 방문하지 않는 노드를 차례로 방문하여 큐에 enQueue 한다.
- 방문하지 않은 인접한 노드가 없으면 큐에서 deQueue한 노드를 가지고 2를 계속 반복
3. 큐가 공백이 될 때 까지 2를 반복한다.
너비 우선 탐색 과정 예
1. A를 우선 탐색 . v = A
2. B를 탐색 -> enQueue B -> Queue B
3. C를 탐색 -> enQueue C -> Queue B C
4. v에 더이상 인접한 노드 없음 -> deQueue B -> v = B -> Queue C
5. D를 탐색 -> enQueue D -> Queue C D
6. E를 탐색 -> enQueue E -> Queue C D E
7. v(B)에 인접한 노드 없음 -> deQueue C -> v = C -> queue D E
8. v(C)에 인접한 노드 없음 -> deQueue D -> v = D -> queue E
9. G를 탐색 -> enQueue G -> Queue E G
10. v(D)에 인접한 노드 없음 -> deQueue E -> v = E -> queue G
11. F 탐색 -> enQueue G -> Queue G F
12. v(E)에 인접한 노드 없음 -> deQueue G -> v = G -> queue F
13. v(G)에 인접한 노드 없음 -> deQuque F -> V = F -> queue
- f(p1)이 f(a1)과 같은 부호를 갖는 경우 -> p는 p1과 b1사이에 존재하게 되므로 a2= p1, b2=b1라 가정
- f(p1)이 f(b1)과 같은 부호를 가지는 경우 -> p는 a와 p1 사이에 존재하므로, a2 = a1, b2 = p1이라 놓고 구간 (a2, b2)에서 앞의 과정을 반복
멈춤 과정
-매트랩을 이용할 때 시행되는 반복 횟수에 대한 조건을 결정하는 것이 좋음
- 코딩을 잘못한 경우 무한번 반복 시행에 대한 가능성을 제거하기 위해 N은 최대 한계치를 결정하고 횟수를 더 초과하면 멈춤 과정을 실시함
매트랩으로 근사해 구하기
- f(x) = x^2 - 4
clc;
clear all;
f='x^2 - 4';
n =0;
a=1;
b=2;
c = (a+b)/2;
eps = 0.000001;
fprintf(' n a b c f(c) \n');
while b-c >= eps
n = n + 1;
x = b;
fb = eval(f);
x = c;
fc = eval(f);
if fb * fc <= 0
a = c;
c = ( a + b)/2;
else
b=c;
c = (a+b)/2;
end
fprintf("%2.0f %2.10f %2.10f %2.10f %2.5f \n", n, a, b, c, fc);
end