상태공간 트리
백트래킹
한정분기
A*알고리즘
상태공간 트리
1. 상태공간 트리의 개요
2. 상태공간 트리를 이용한 여행자 문제 풀이
상태 공간 트리 state-space tree
- 문제 해결 과정 중간 상태를 각각 한 노드로 나타낸 트리
- 세 가지 상태 공간 탐색 기법
1. 백 트래킹
2. 한정 분기
3. A*알고리즘
상태공간 트리를 이용한 여행자 문제 풀이
- 그래프에서 모든 정점을 순회하고 돌아오는 싸이클을 해밀토니안 싸이클이라고 함
- 완전 그래프에서 해밀토니안 싸이클은 수 없이 많은데 여행자 문제는 그 중 가장 짧은 것을 찾는 문제

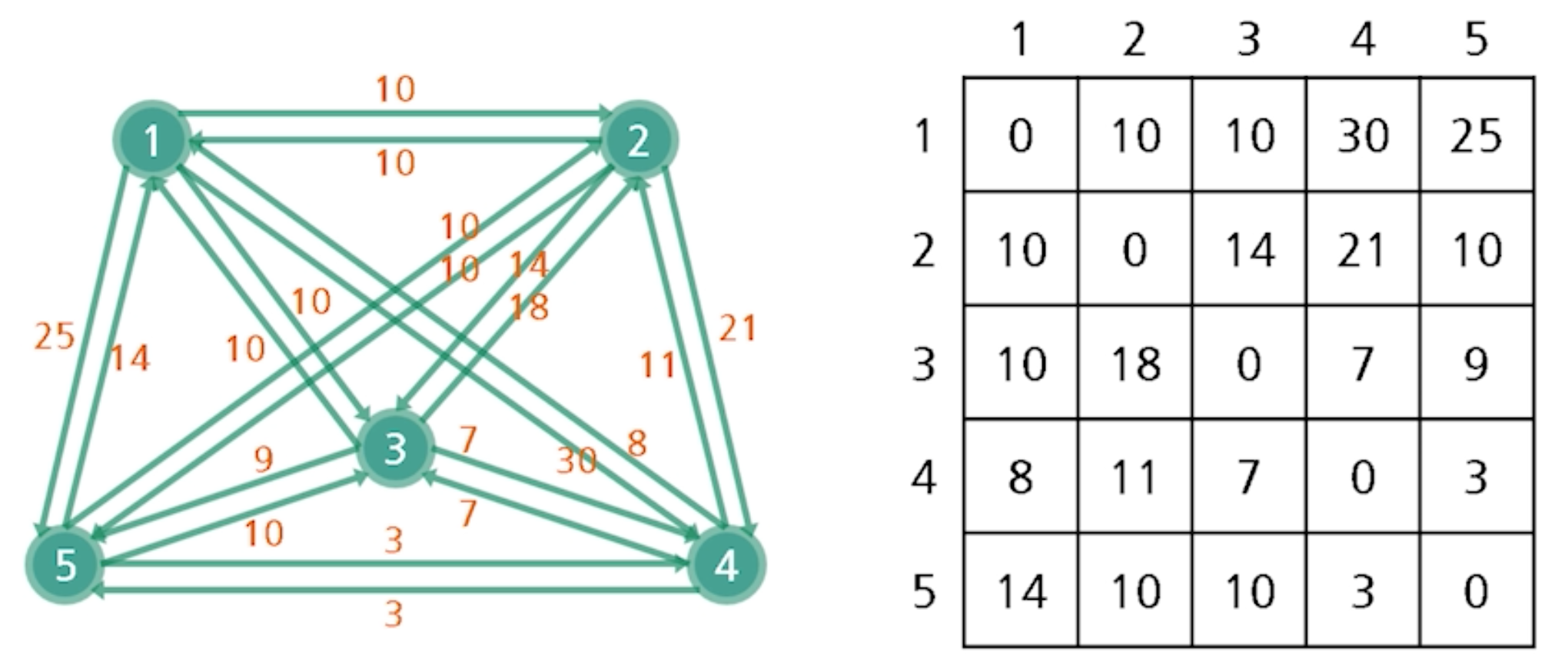
TSP와 인접행렬의 예
사전식 탐색의 상태공간 트리
- 다섯 개의 도시를 가진 TSP의 최적해를 찾으려면 -> 모두 4!(24)개의 해를 검사해보아야함

백트래킹
- DFS 또는 그와 유사한 스타일의 탐색을 총칭. 가능한 지점까지 탐색하다 막히면 되돌아감. 주로 재귀적으로 ㄱ현
- ex : 미로 찾기 문제, 8퀸 문제, 색칠 문제(map coloring)
미로찾기 문제
- S : 시작점
- T : 목표지점
- S에서 시작하여 T까지 이동하는 경로 찾기

미로찾기 문제의 탐색 과정을 상태 공간 트리로 표현하는 방법
1. S에서 시작해 정점 1로 이동, 정점 2 또는 정점 3중 하나를 선택함
2. 임의의 정점 2를 선택함, 막다른 골목에 다다름
3. 정점 2로 오기위해 거쳤던 정점 1로 되돌아감 정점 3으로 감
4. 정점 3으로 이동함, 정점 4와 정점 5중 하나를 선택함
5. 정점 5에 이름, 정점 6과 정점 7중 하나를 선택함
6. 정점 6에 이름, 막다른 골목에 다다름
7. 정점 6으로 오기위해 거쳤던 정첨 5로 되돌아감
8. 정점 7에 이름, 정점 8과 정점 T중 하나를 선택

미로찾기 문제 해결방법 유사코드
mave(v)
{
visited[v] <- YES;
if (v = T) then {print "성공!"; exit();}
for each x in L(v) L(v) : 정점 v의 인접 정접 집합
if (visited[x] = NO) then{
prev[x] <- v;
maze(x);
}
}
한정 분기 branch & bound
- 분기와 한정의 결합 -> 분기를 한정시켜 쓸데없는 시간 낭비를 줄이는 방법
- 기존의 상태공간트리에서 사전식 탐색시 (n - 1) ! 시간이 소요됨 => 지수시간 이상
백트래킹과 공톰정과 차이점
- 공통점 : 경우들을 차례로 나열하는 방법이 필요함
- 차이점
백트래킹 : 가보고 더이상 진행되지않으면 되돌아옴
한정분기 : 최적해를 찾을 가능성이 없으면 분기하지 않음
-> 지금까지 얻은해보다 더 좋은해가 아니라면 분기를 하지 않음
가지치기의 원리

TSP 예제를 대상으로 한 한정분기 탐색의 예시

A* 알고리즘
1. A*알고리즘 개요
2. 최단 경로 문제
3. A*알고리즘 작동예
4. TSP 예쩨를 대상으로 한 A* 알고리즘 탐색의 예
최적 우선 탐색 BFS Best First Search
- 각 정점이 매력 함숫값 g(x)를 가짐.
- 방문하지 않은 정점들 중 g(x)값이 가장 매력적인 것부터 방법
A* 알고리즘
- 최적 우선 탐색을 이용하여 목적점까지 이르는 잔여 추정 거리를 고려하는 알고리즘
- 정점 x로부터 목적점에 이르는 잔여거리의 추정치 h(x)는 실제치보다 크면 안됨
Remind : 다익스트라 알고리즘
- 시작점은 하나
- 시작점으로부터 다른 모든 정점에 이르는 최단 경로를 구함 -> 목적점이 하나가 아님
<-> A* 알고리즘에서는 목적점이 하나임
다익스트라 알고리즘으로 최단경로 찾기





A*알고리즘을 이용한 최단 경로 찾기
- 추정 잔여거리 h(x): 각 정점에서 목적지 까지 직선 거리

- 시작점을 0, 모든 정점을 무한대로 초기화
- 시작점 주위의 거리 값을 구하고 g(x)라 함.
- g(x) + h(x)하여 우측 그림과 나타낼 수 있음
=> 이 중에서 g(x) + h(x)가 가장 작은 정점 23을 포함시킴

- 정점 41의 g(x) + h(x)값이 60으로 가장 작으므로 포함시킴
=> 추정 잔여거리를 사용하여 탐색의 단계가 현저히 줄어들음

TSP 예제를 대상으로 한 A* 알고리즘 탐색의 예
- 상태 공간 트리
- A* 알고리즘이 첫 리프 노드를 방문하는 순간 종료되는 이유
* 방금 본 그래프는 모든 정점에 대해서 h(x) 값을 미리 계산해둠. 일반적인 상태 공간 트리 문제에서는 미리 주어지지 않고 만들어지면서 탐색이 진행됨 -> 따라서 각 노드에서 목적점에 이르는 길이의 추정치는 그 때 그 때 계산하여야함
상태공간 트리
- 모든 정점을 지나서 시작정점으로 돌아오는지. 가중치의 합이 최소가 되는지 알아봄
- 하한선 33은 모든 정점에서 가장 작게 나가는 값들의 합(1 : 10, 2: 10, 3: 7, 4: 3, 5 : 3 -> 10 + 10 + 7 + 3 + 3 = 33)
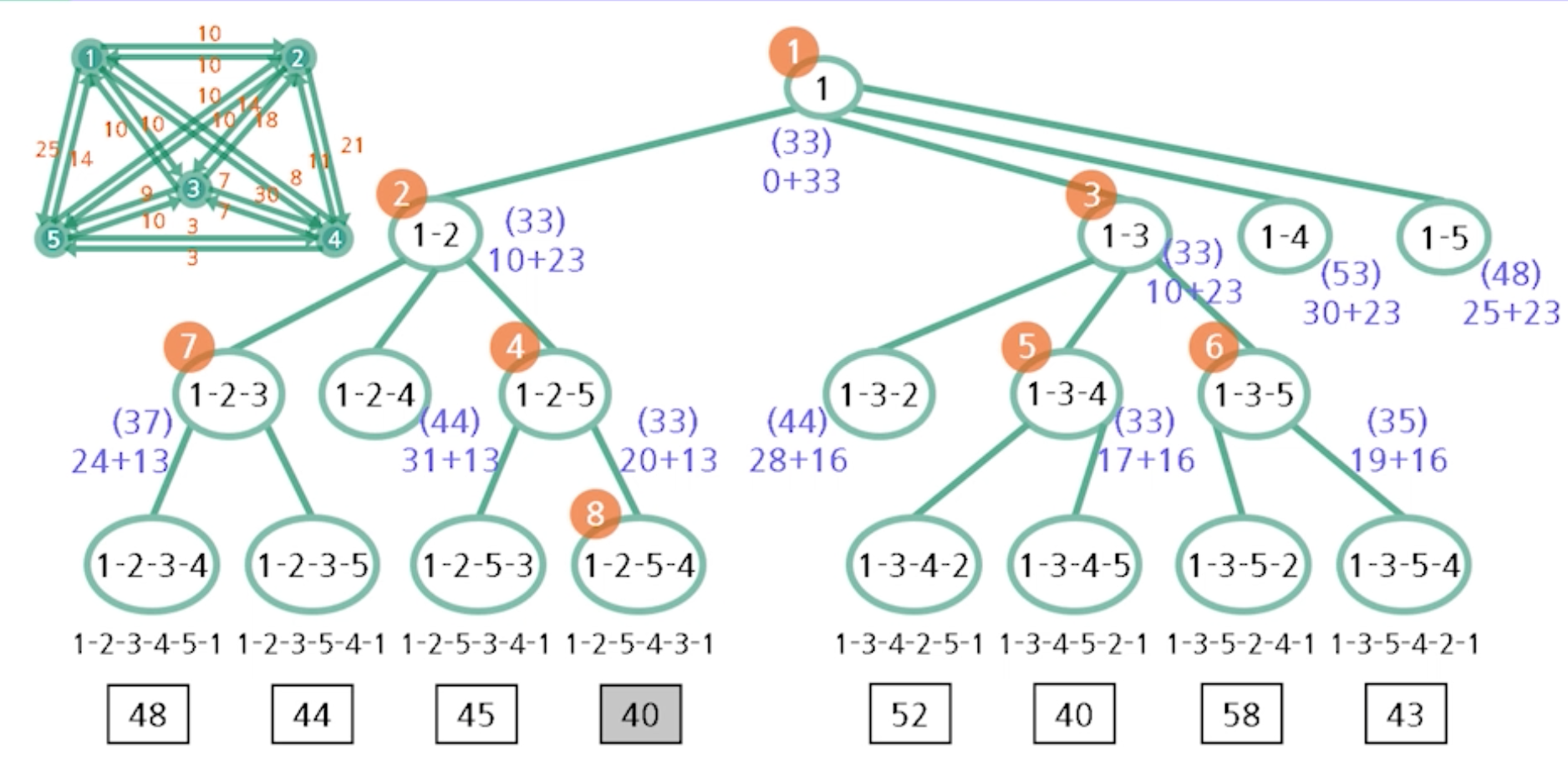
A* 알고리즘이 첫 리프 노드를 방문하느 순간 종료되는 이유
- 계산되지 않은 리프 노드들은 조상 노드의 추정치가 큰편이라 종료 된 것들임

'수학 > 알고리즘' 카테고리의 다른 글
| 파이썬 알고리즘 - 2 탐색 문제 (0) | 2020.07.02 |
|---|---|
| 파이썬 알고리즘 - 1 작은 문제들 (0) | 2020.07.01 |
| 알고리즘 - 25 근사 알고리즘 (0) | 2020.06.17 |
| 알고리즘 - 22 NP-완비 문제 (0) | 2020.06.16 |
| 알고리즘 - 21 P와 NP 문제 (0) | 2020.06.16 |