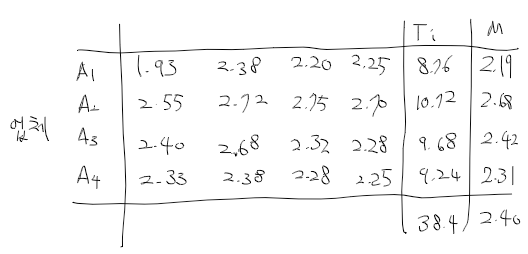분산분석 -> 요인의 수준이 이산형(100, 120)에 따른 종속변수의 영향
회귀분석 : x가 이산이 아닌 연속인경우 분석 방법
공분산분석 : x가 이산형인것도 있고 연속형인것도 두개다 있는 경우
회귀분석 regression analysis
- 독립변수들과 종속변수 간에 관계를 함수식으로 정리하여 분석하는 방법
- 독립/종속변수는 연속값
- 단순 회귀 simple regression : 독립변수가 하나
- 다중 회귀 multiple regression :독립변수가 여러개
다중 선형 회귀 multiple linear regression

다항 회귀 모형 polynomial regression model

상관계수 correation coefficient
- 두 변수간에 선형적 상관관계에 대해서 나타냄
- 1에 가까우면 양의 상관관계
- -1에 가까우면 음의 상관관계
- 0에 가까우면 선형적 상관관계가 존재하지 않음

단순 선형 회귀 분석 simple linear regresion analysis
- 모형 model

- 관측치 measurements

- 추정식 estimator

- 잔차 residual

최소제곱법 least squared method LSM

다음 데이터가 주어질떄 단순선형회귀를 수행하라


R로 테스트
- 추정량 -0.28928
- 기울기 0.45664 -> pvalue = 3.21e-07로 매우작다 =>유의하다.
- R-squared : 0.9338로 유의함

회귀선의 유의성 검정
- 두 변수 사이에 회귀 관계가 없다면 beta1는 0이되어 다음의 식이 성립합.

- 총제곱합과 잔차제곱합, 회귀제곱합 사이의 관계

결정계수 coefficient of determination R^2
- 회귀식이 얼마나 의미있는지
- R square가 크면 클수록 유의하다.

- 회귀 계수 beta1의 유의성
-> H0: 회귀관계가 없다. vs H1 : 회귀관계가 있다.
H0: beta1 = 0 vs H0: beta1 !=0
분석분석표
- 회귀분석의 유의성 검정

분산분석표 분석
유의확률 pvale가 매우 작으므로 h0 기각. 매우 유의

공분산 분석
- 분산분석 + 회귀분석
- 일원 배치 분산분석 : 기계(3대) -> 섬유 제품 강도
- 이원 배치 분산분석 : 기계(3대), 원사두께(얇음,두꺼움) -> 섬유제품 강도
- 공분산 분석 : 기계(3대), 원사 두께(연속적인값, 공변수 covariate) -> 섬유제품 강도
공분산 분석 예시
- 일원배치 예시 : 두개의 사료 (A,B) => 섭취후 체중 y
- 공분산 분석 예시 : 두 사료(A,B), 초기체중 x(연속적인값) => 섭취후 체중 y
'수학 > 통계' 카테고리의 다른 글
| 회귀모형 - 2. (다)중회귀모형 (0) | 2020.10.30 |
|---|---|
| 회귀모형 - 1. 단순 회귀 모형 (0) | 2020.10.30 |
| 실험계획 - 4. 이원배치 분산분석 (0) | 2020.10.29 |
| 실험계획 - 3. 일원배치 분산분석 (0) | 2020.10.29 |
| 실험계획 - 2. 두 모집단 비교 (0) | 2020.10.29 |