분류 앙상블 classifier ensemble
- 하나의 분류기만으로는 성능이 부족.
- 여러 분류기들을 활용하여 더 나은 성능으로 문제 해결하는 개념
기본 분류기 base classifier
- SVM, 신경망 등 분류기 -> 강한 분류기
앙상블과 약한 분류기
- 분류 앙상블에서는 여러개의 약한 분류기들을 사용
ex. 기초 분류기 : 신경망 -> 약한 분류기 : 성공률이 50%인 퍼셉트론
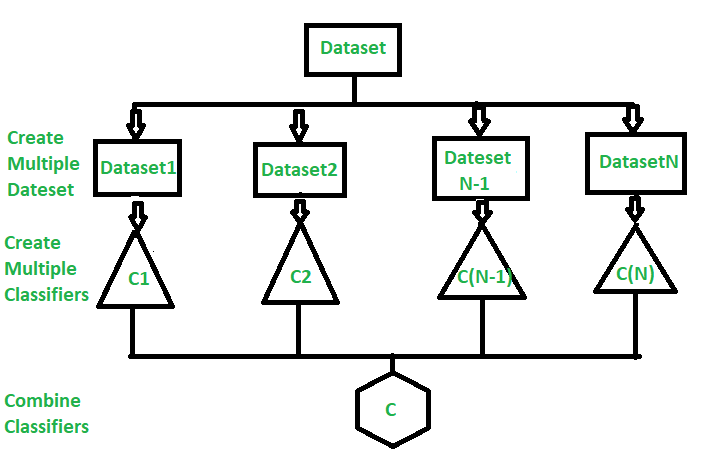
앙상블에서 분류기들의 결합 방법
- 분류기들 간 투표 -> 가장 많은 표를 받은 분류기 결과 반영
샘플링 방법
- 리샘플링 : 동일한 샘플들을 어러번 사용
- k겹 교차 검증 : 전체 샘플들을 k 등분 하고, k-1개 부분집합을 학습, 나머지 1개 부분집합으로 성능 평가
- 부트스트래핑 : k겹 교차 검증과 동일하나 샘플들 사이 중복을 허용

부트스트랩
- 샘플들을 k개로 나눌 시 샘플들의 중복을 허용하여 훈련

분류 앙상블 기법
1. 배깅
2. 부스팅
3. 아다부스팅
4. 랜덤 포래스트
배깅 bagging
- 확장한 부트스트랩 bootstrap aggregating => 부트스트랩을 다중 분류기에 적용한 기술
- 사용한 샘플들을 다시 넣어(재샘플링) 학습에 사용
- 부트스트랩핑으로 재샘플한 데이터셋으로 약한 분류기들을 학습 -> 투표하여 결과를 선정

부스팅 boosting
- 배깅보다 정교하게 재샘플링을 수행한 앙상블 기법
* i번쨰 분류기와 i + 1번쨰 분류기간 연관성을 가진 샘플들로 학습 수행
- 처음에는 맞는 샘플들, 틀린 샘플들로만 분류하다가 이후에 이들이 혼합된 복잡한 데이터셋으로 학습
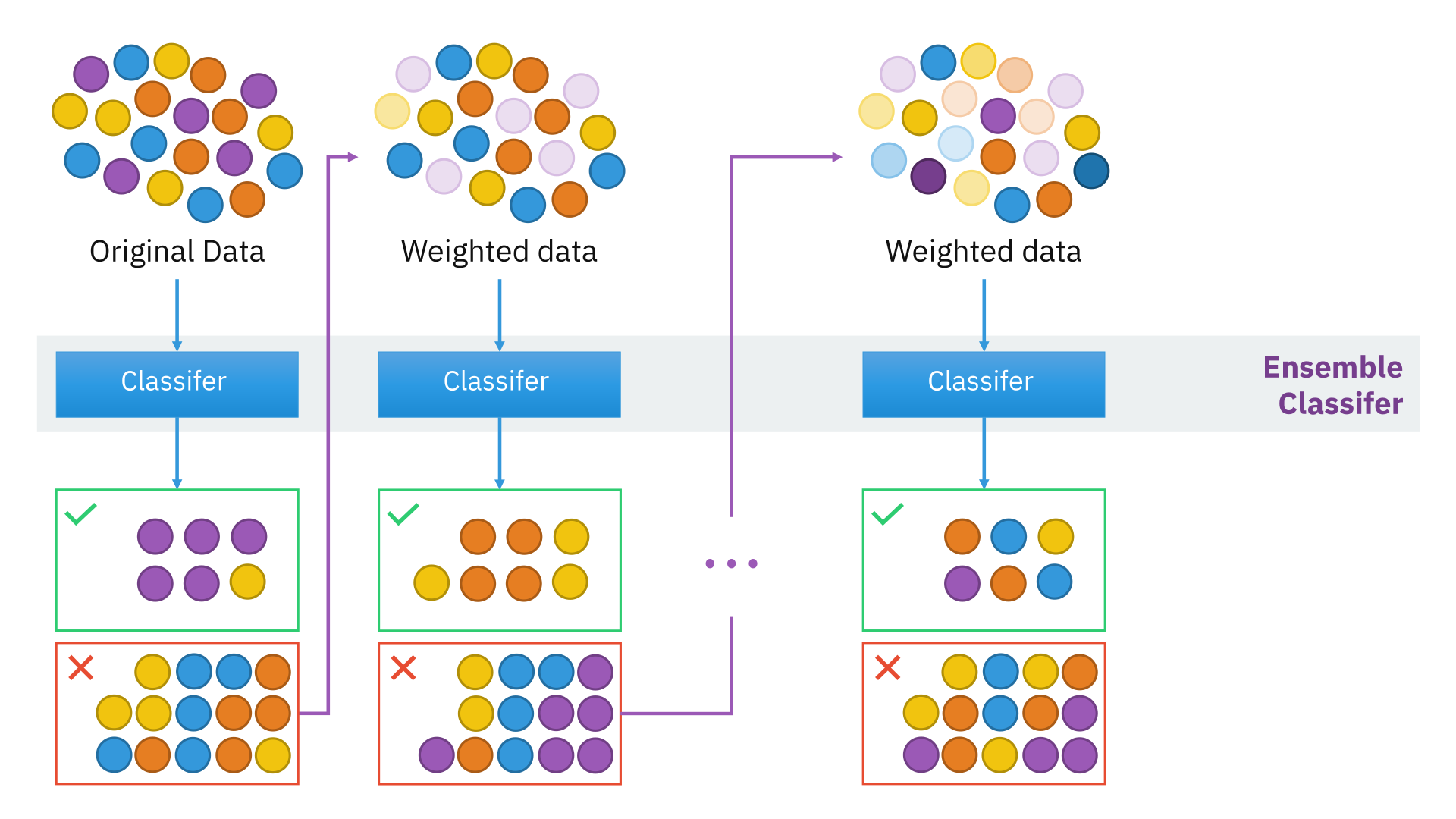
아다부스트 Adaboost
- 각 분류기 마다 가중치가 큰 샘플들을 잘 맞출수 있도록 학습
1. 아래의 그림과 같이 +와 -가 가능한 가장 잘 구분되도록 분류기들을 학습
2. 맞춘 샘플들은 가중치를 낮추고, 틀린 샘플들의 가중치를 높임
3. 약한 분류기들의 틀린 샘플 오류 합을 구하여 강한 분류기 취득
=> 틀린 샘플들은 높은 가중치를 가지면서 격리됨

랜덤 포레스트 random forest
- 부스팅 기법에서 분류기들은 상호 보완
- 랜덤 포레스트에서 분류기들은 서로 독립됨
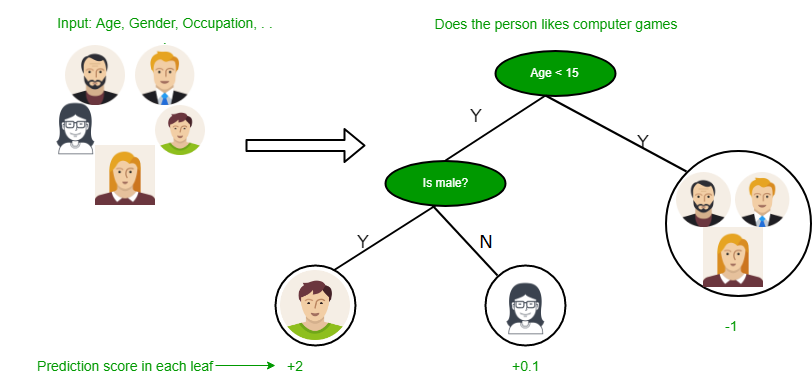
- 기본 분류기는 트리 분류기 사용. 트리의 각 노드들은 특징 하나를 비교하여 분기 시킴.
- 아래의 그림은 특징 벡터가 주어질떄 분류하는 과정
'로봇 > 영상' 카테고리의 다른 글
| 컴퓨터 비전 - 30. 사례 인식을 위한 기하 정렬과 단어 가방 (0) | 2020.08.01 |
|---|---|
| 컴퓨터 비전 - 29. 얼굴 인식 (0) | 2020.07.31 |
| 컴퓨터 비전 - 27. SVM (0) | 2020.07.31 |
| 컴퓨터 비전 - 26. 기계학습 (0) | 2020.07.31 |
| 컴퓨터 비전 - 25. 기하 정렬과 매칭 (0) | 2020.07.31 |