분류
- 주어진 데이터가 어느 카테고리에 속하는지 판단하는 일
- 나이브 베이즈, 로지스틱 회귀, 결정 트리, SVM, 앙상블, 신경망, 최근접 등
- 영상, 음성 등 대용량 비정형 데이터 -> 딥러닝
- 정형 데이터 -> 머신러닝. 최근 앙상블 기법이 애용
앙상블
- 여러 알고리즘들의 활용(앙상블)
- 약 분류기들을 결합하여 상호 보완
- 배깅/부스팅
결정 트리 decision tree
- 데이터의 규칙을 트리 형태로 분할해 나가는 모델
- 장점 : 피처 스케일링이나 정규화 필요가 없음
- 단점 : 과적합으로 성능이 떨어짐. 트리 크기 제한 필요.
사이킷런의 결정트리
- CART Classification And Regression Tree 알고리즘 기반(ref : throwexception.tistory.com/1030?category=857655)
- DecisionTreeClassifier/Regressor 제공
- 다음 파라미터가 있음
1. min_samples_split : 노드 분할을 위한 최소 샘플 데이터 수, 과적합 제어용. 작을수록 과적합 가능성 증가
2. min_samples_leaf : 리프 노드가 되기위한 최소 샘플 데이터수. 과적합 제어용. 작을수록 좋음
3. max_features : 최적 분할을 위해 다룰 최대 피터 갯수. 기본값 "None" 모든 피처 고려
4. max_depth : 최대 깊이. 기본값 "None"는 완전 분할될때까지 분할 or 리프 노드 최소 샘플까지 분할
결정 트리 과적합 개선하기
- min_samples_leaf : 리프 노드(말단 노드)가 되는 하한 데이터 갯수를 높이면 과적합 문제가 개선됨.
1. datasets 모듈의 make_classification 함수로 데이터 셋 생성
- make_classification() : 분류를 위한 데이터 셋 생성 함수
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
import seaborn as sns
import matplotlib.pyplot as plt
X, y = make_classification(n_features=2, n_informative=2, n_redundant=0,
n_classes=3, n_clusters_per_class=1, random_state=0)
plt.scatter(X[:,0],X[:,1], c=y)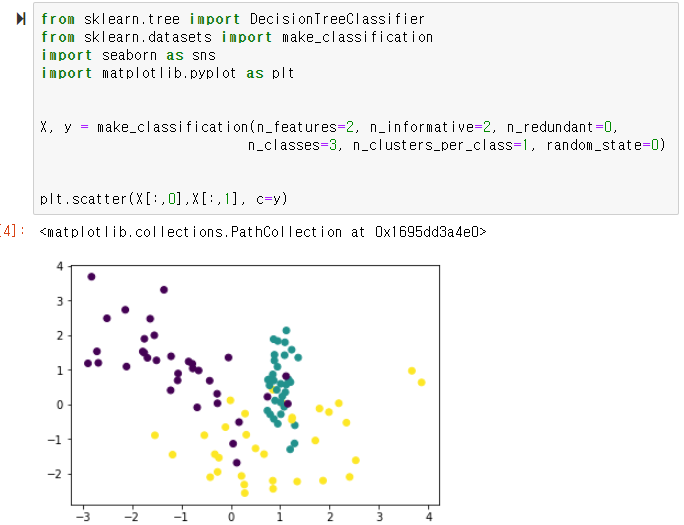
2. min_samples_leaf 디폴트(None) 인 상태에서의 성능
- 훈련용 데이터에는 100% 정확하나, 테스트 데이터는 85% 정확도를 보임
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
df = DecisionTreeClassifier()
df.fit(X_train, y_train)
print("train_score : {} ".format(df.score(X_train, y_train)))
print("test_score : {} ".format(df.score(X_test, y_test)))
3. min_samples_leaf=6일때 성능
- 훈련 데이터 정확도는 떨어졋으나, 테스트 정확도는 90%로 증가함
df = DecisionTreeClassifier(min_samples_split=6)
df.fit(X_train, y_train)
print("train_score : {} ".format(df.score(X_train, y_train)))
print("test_score : {} ".format(df.score(X_test, y_test)))
4. GridSearchCV로 최적 하이퍼 파라미터 찾아보기
- 결정 트리 파라미터를 다음과 같이 다양하게 주었을때, 최적 분류기의 파라미터와 성능 보기
=> 훈련 점수는 0.8875로 떨어졋으나, 테스트 점수가 1.0으로 상승했다..?
* max_depth=4, min_samples_leaf=1, min_samples_split=2 일때,
from sklearn.model_selection import GridSearchCV
param={
"min_samples_leaf":[1, 2, 3, 4, 5, 6, 7, 8, 9],
"max_depth":[2, 3, 4, 5, 6, None],
"min_samples_split":[2, 3, 4, 5, 6, 7, 8, 9, 10]
}
df = DecisionTreeClassifier()
gs = GridSearchCV(df, param_grid=param, cv=5, refit=True)
gs.fit(X, y)
df = gs.best_estimator_
print("train_score : {} ".format(df.score(X_train, y_train)))
print("test_score : {} ".format(df.score(X_test, y_test)))
print(gs.best_score_)
print(gs.best_params_)
'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 10. 앙상블 모델 개요 (0) | 2020.11.26 |
|---|---|
| 파이썬머신러닝 - 9. 결정 트리를 이용한 사용자 행동 인식 분류하기 (0) | 2020.11.25 |
| 파이썬머신러닝 - 7. 피마 인디언들의 당뇨병 여부 예측하기 (0) | 2020.11.24 |
| 파이썬머신러닝 - 6. 성능 평가 지표 (0) | 2020.11.24 |
| 파이썬머신러닝 - 5. 타이타닉 생존자 예측 (0) | 2020.11.23 |