타이타닉 생존자 예측에 있어서 할 일은 대강 다음으로 정리할수 있을것 같다.
- 전처리
- 모델 선정
- 교차검증, 하이퍼 파라미터 조정
- 시각화
1. 라이브러리 임포트
- 대강 생각나는 라이브러리들
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
2. 데이터 읽고 훑어보기
train_df = pd.read_csv("res/titanic/train.csv")
test_df = pd.read_csv("res/titanic/test.csv")
train_df.head()
- info로 보니 891 x 12 형태

- 기초 통계량

- 결측치 조회 및 삭제
* Cabin의 경우 결측치가 687개라 그냥 결측치를 삭제하는경우 891개 중 687개가 삭제되어버렸다.
=> Cabin과 Age의 결측치는 삭제하지 말고, fillna()로 채워주자
print(train_df.isnull().sum())
train_df = train_df.dropna()
print()
print(train_df.isnull().sum())
print(train_df.info())
- 결측치 채우고, 나머지 삭제
-> "age"는 나이 평균, "cabin"은 N으로 대체
train_df = pd.read_csv("res/titanic/train.csv")
train_df["Age"].fillna(train_df["Age"].mean(), inplace=True)
train_df["Cabin"].fillna("N", inplace=True)
train_df = train_df.dropna()
print()
print(train_df.isnull().sum())
print(train_df.info())
탐색적 데이터 분석
1. 단순 확인
- 일단 각 컬럼 별 분포를 해보자
- 우선 해당 데이터프레임의 컬럼 조회

- 아까 결측치를 채운 카빈부터 보자
-> 호실이다보니 수가 적은 경우가 많아보인다.

- 남여 비율과 생존여부, 등급
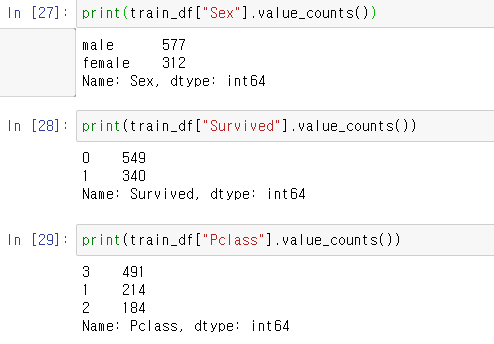
2. 그룹별 조회
- 성별에 따른 생존 여부
train_df.groupby(["Sex", "Survived"])["Survived"].count()
- 선실등급별 생존여부
train_df.groupby(["Pclass", "Survived"])["Survived"].count()
- 나이별 생존여부.
* 나이의 경우 나이대별로 보지않다보니 힘들다. 그룹화가 필요해보이고, 이번에 시각화해서 보자
train_df.groupby(["Age", "Survived"])["Survived"].count()
3. 시각화
- 성별에 따른 생존여부
sns.barplot(x="Sex", y="Survived",data=train_df)
- 성별과 선실 등급에 따른 생존여부
sns.barplot(x="Sex", y="Survived", hue="Pclass", data=train_df)

* DataFrame.apply() 함수를 이용한 나이대별 그룹화
-> 25 ~ 35인 Young Adult가 가장 많은걸 확인할 수 있음.
(아마 아까 Age의 결측치를 평균으로 채운 영향으로보임)
def get_categroy(age):
cat = ""
if age <= -1: cat = "Unknown"
elif age <= 5: cat = "Baby"
elif age <= 12: cat = "Child"
elif age <= 18: cat = "Teenager"
elif age <= 25: cat = "Student"
elif age <= 35: cat = "Young Adult"
elif age <= 60: cat = "Adult"
else : cat = "Elderly"
return cat
train_df["AgeGroup"] = train_df["Age"].apply(lambda x : get_categroy(x))
train_df["AgeGroup"].value_counts()
- 나이대 그룹과 성별에 따른 생존 여부를 살펴보자
-> 아기, 어린이와 여성의 경우 생존률이 높게 나옴
sns.barplot(x="AgeGroup", y="Survived", hue="Sex", data=train_df)
- 선실 등급과 나이 그룹에 대해서도 살펴보면 -> 1등실 사람일수록 생존률이 높음

- 다른 변수로 Parch(탑승 부모, 어린이인원), SibSp(탑승 형재, 배우자 인원)도 살펴보면
-> PClass, Age에 비하여 균등하게 나옴 => 좋은 변수는 아님


4. 인코딩 하기
- 아까 Sex, Cabin, Embarked 변수가 문자열로 되어있는걸 보았으니 인코딩이 필요
def encoding(df):
features = ["Cabin", "Sex", "Embarked"]
for feature in features:
encoder = LabelEncoder()
df[feature] = encoder.fit_transform(df[feature])
return df
train_df = encoding(train_df)
train_df.head()
* 아까 잊었는데 값이 고유한 변수들은 삭제해주자
-> Age, Ticket 는 삭제
train_df.drop(["Name", "Ticket"], axis=1, inplace=True)
train_df.head()
GridSearchCV를 이용한 최적의 분류기와 하이퍼 파라미터 찾기
- 데이터는 loc로 X, y 선택
- random forest와 결정 트리 사용
X = train_df.loc[:,train_df.columns != "Survived"]
y = train_df.loc[:,train_df.columns == "Survived"]
rf_clf = RandomForestClassifier()
dt_clf = DecisionTreeClassifier()
param = {
"max_depth" : [3, 4, 5, 6],
"min_samples_split" :[2, 3, 4, 5]
}
rf_gs = GridSearchCV(rf_clf, param_grid=param, cv=5, refit=True)
dt_gs = GridSearchCV(dt_clf, param_grid=param, cv=5, refit=True)
rf_gs.fit(X, y)
dt_gs.fit(X, y)
print("Random Forest")
print(rf_gs.best_score_)
print(rf_gs.best_params_)
print("\n\ndecision tree")
print(dt_gs.best_score_)
print(dt_gs.best_params_)- 최적의 성능과 하이퍼 파라미터는 아래의 사진과 같음
-> 랜덤 포레스트로 깊이 5, min_sample_split이 2일때 0.829로 좋았음.

'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 7. 피마 인디언들의 당뇨병 여부 예측하기 (0) | 2020.11.24 |
|---|---|
| 파이썬머신러닝 - 6. 성능 평가 지표 (0) | 2020.11.24 |
| 파이썬머신러닝 - 4. 데이터 전처리 : 인코딩/피처 스케일링 (0) | 2020.11.23 |
| 파이썬머신러닝 - 3. 교차 검증/하이퍼 파라미터탐색 (0) | 2020.11.23 |
| 파이썬머신러닝 - 2. 붓꽃 문제 다루기 (0) | 2020.11.23 |