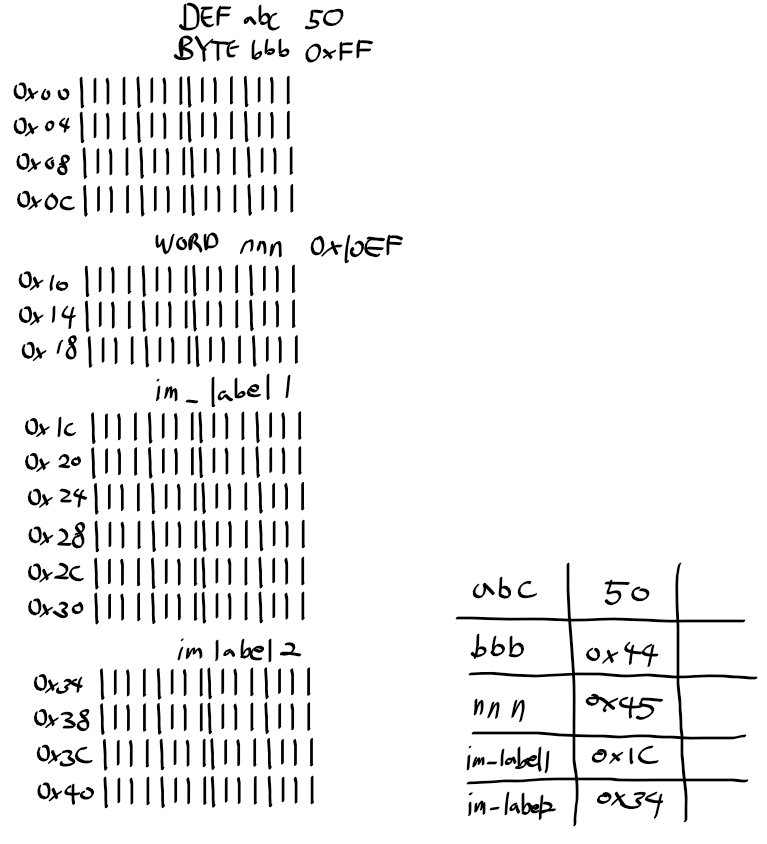
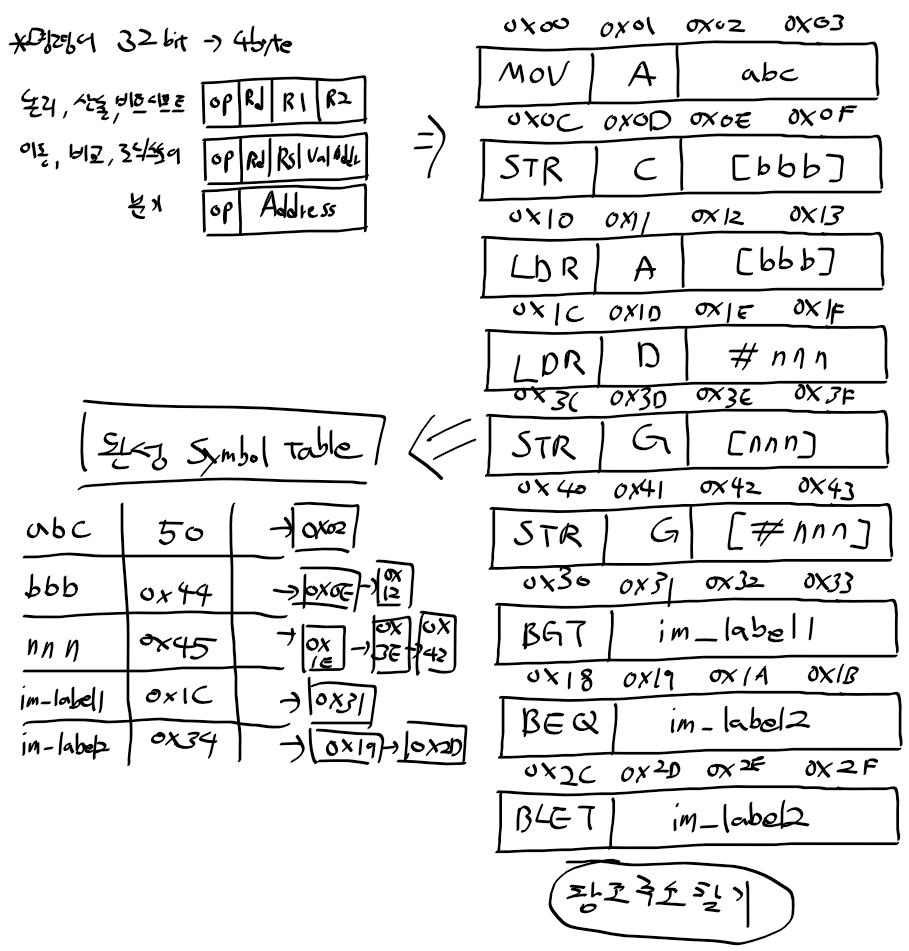
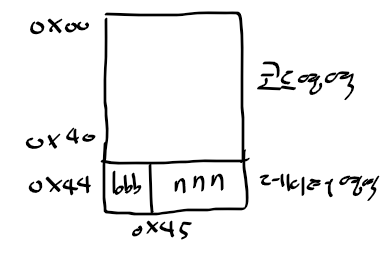
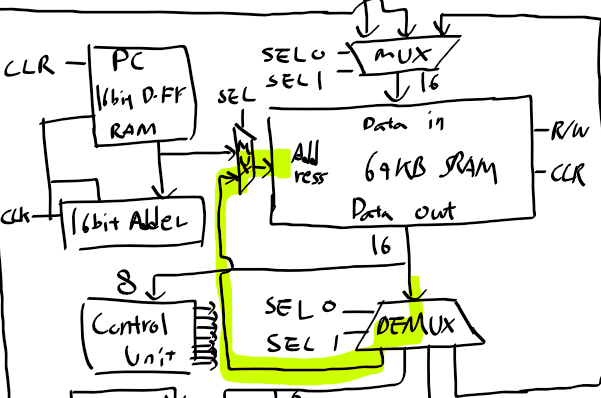
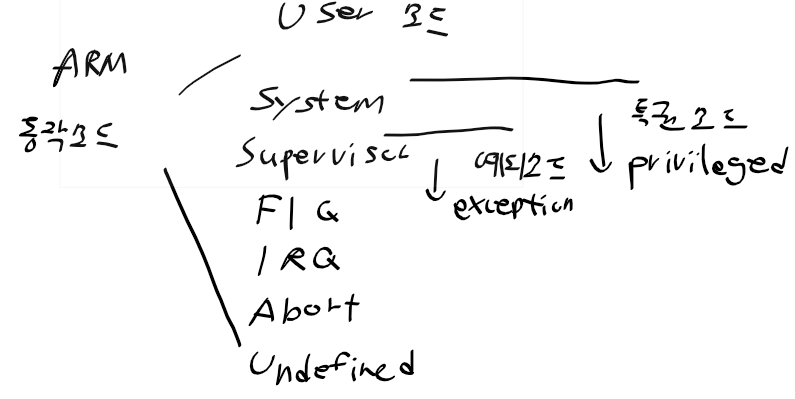
ARM 프로세서 동작 모드
- USER 모드 : 일반 사용자 프로그램 모드
- SYSTEM 모드 : CPSR을 완전히 읽기 쓰기 가능
- Supervisor 모드 : 운영체제를 위한 예외, 커널이나 디바이스 드라이버 처리
- FIQ 모드 : 긴급한 인터럽트 발생시 진입. 빠른 인터럽트 처리를 위한 모드
- IRQ 모드 : 일반 인터럽트 발생시 진입.
- Abort 모드 : 데이터 또는 명령어 거부시 진입
- Undefined 모드 : 패치된 명령어가 정의되지 않을시 진입
* CPSR : Current Program Status Register
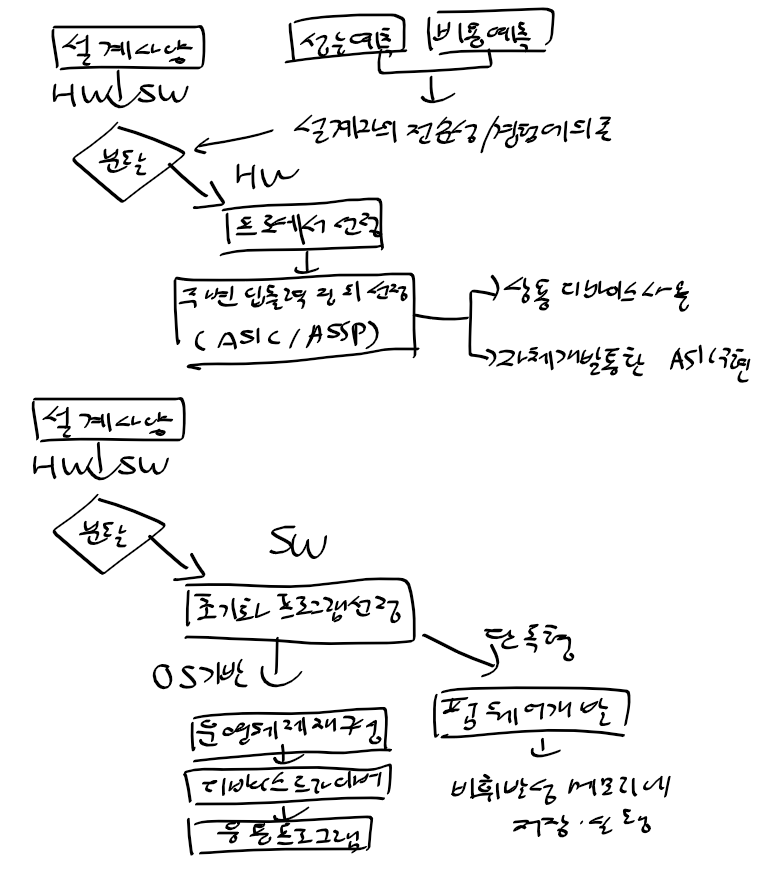
(1) ARM 프로세서 동작모드
1) 프로그래머 모델
2) 프로세서 동작모드
3) 특권 모드
4) 예외 모드
5) 동작 모드 변경
1) 프로그래머 모델
프로그래머 모델이란?
- 컴퓨터 시스템 구조와 동작을 표현한 추상적 개념모델
- 프로그래머가 코드 작성위해 알아야한 최소한 프로세서에 대한 정보
- 프로그램 최적화를 위한 중요 정보
프로그래머 모델 구성
- 프로세서 동작모드 : 운영체제를 하드웨어적으로 지원하는 모드
- 레지스터 구성방법 : CPU가 사용가능한 효율적인 저장장소
- 메모리접근방법 : 메모리서 데이터 읽거나 쓸때 적용
- 명령어 셋 : 프로세서가 실행할수있는 명령어 셋
- 예외처리방법 : 시스템의 실사간 처리에 큰 영향을 줌. 실시간 처리 성능 예측과 성능향상에 중요
2) 프로세서 동작모드
ARM 프로세서 동작 모드
- 프로세서가 프로그램 실행시 권한 설정
- 7개 동작 모드 : 6개 특권 privileged mode + 1개 사용자 모드 user mode
특권 모드 : 예외 처리, 시스템 자원에 접근 - system 모드, supervisor 모드, fiq 모드, irq 모드, abort 모드 등
사용자 모드 : 사용자 프로그램 실행 상태, 시스템 자원 접근 제한. 필요시 운영체제에 요청. 동작모드 변경불가
3) 사용자 모드
사용자 모드
- 시스템 자원 접근 제한하여 시스템 자원 보호
- 다른 동작 모드 진입 불가
- 변경 시 소프트웨어 인터럽트로 특권모드 진입후 가능
- 사용자 모드서 레지스터 사용 : R0 ~R12 범용레지스터 R13 스택 포인터 R14 링크레지스터 R15 프로그램카운터
4) 특권 모드
- 예외 처리하거나 시스템 자원에 접근가능모드
- 시스템 모드 : 운영체제를 위한 모드 운영체제 커널 작업 실행. 시스템 자원 접근 가능. 예외 발생 없이 진입.
- 슈퍼바이저 모드 : 운영체제를 위한 보호모드로 시스템 리셋이 진입시 초기 동작모드. 전원 공급시 가장 먼저 진입
- IRQ 모드 : 일반 인터럽트 모드시 진입
- FIQ 모드 : 고속 인터럽트 발생시 진입. 레지스터 뱅킹 세트 확장. R8~R12까지 5개레지스터 추가하여 8개 레지스터 추가사용
- Abort 모드 : Abort 예외발생시 진입. 명령어나 데이터 메모리 접근 오류시 발생.
명령어 접근 오류 : 명령어 pre-fetch 과정서 발생 오류
데이터 접근 오류 : 데이터 alignment 오류, 가상 어드레스 변환오류, 메모리 도메인/ 접근권한 위반 오류 등
- Undefined 모드 : Undefined 예외 발생시 진입. 정의 되지 않은 명령어가 디코딩 시
5) 예외 모드
- 특권 모드 중 예외와 관련있는 동작 모드
- 시스템 모드를 제외한 5가지 -> 슈퍼바이저, IRQ, FIQ, Abort, Undefined
- 하드웨어 또는 소프트웨어 예외발생시 진입
- 동작 모드 전확 속도 향상을위해 레지스터 셋 뱅킹
- 시스템 자원에 접근
6) ARM 프로세서 동작 모드 설정
- ARM 프로세서 동작 모드 설정은 상태레지스터 CPSR의 동작 모드 필드 M[4:0] 사용

- 사용자 모드 : 10000
- 시스템 모드 : 11111
- 슈퍼바이저 모드 : 10011
- FIQ 모드 : 10001
- 동작 모드 값 변경은 특권 모드에서만 변경가능
7) 동작 모드변경
프로세서 동작 모드 변경
- 동작모드 설정 : 상테레지스터의 동작모드 필드 값 변경하여 변경 -> 특권모드서 가능
- 예외 발생하여 특권모드 진입 -> 특권모드에서 동작모드 필드 변경하여 가능
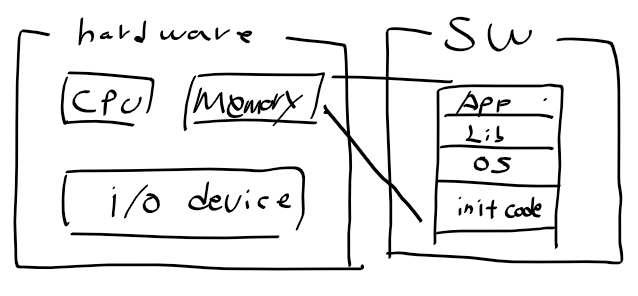
(2) 레지스터 구성
1) 레지스터 구성
2) 프로그램 상태 레지스터
1) 레지스터 구성
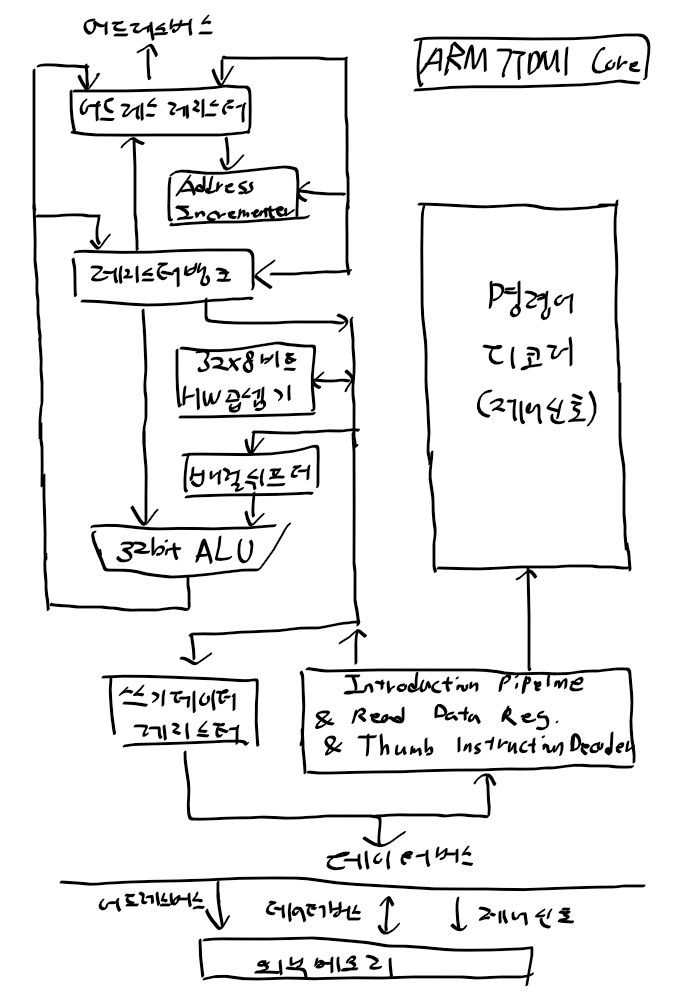
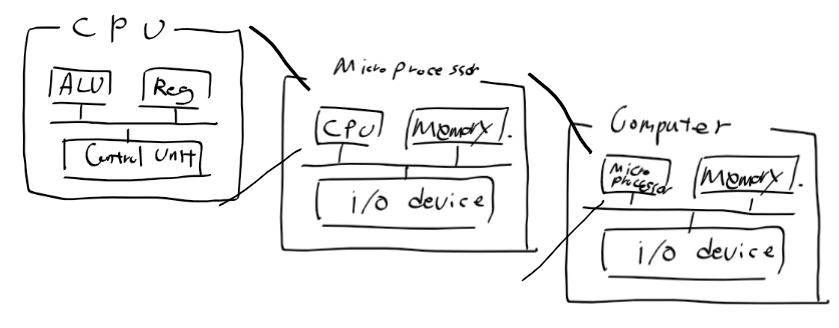
ARM 프로세서 구성
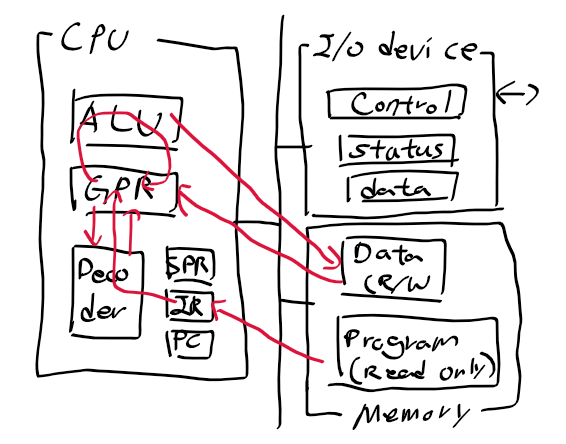
- 레지스터 : 모드 37개 32비트 레지스터로 31개 범용, 6개의 상태 레지스터. 프로세서 모드에 따라 사용가능한레지스터가 바뀜
특수용도 레지스터
- R13 : 스택 포인터로 각 동작 모드에 사용되는 스택 위치 정보를 저장. R13을 이용하여 스택 관리
- R14 : BL명령어로 실행. 링크 레지스터 PC 내용 복사해서 복귀 위치 저장.
- R15 : 프로그램 카운터
- CPSR : 현재 상태 레지스터 . 상태표시 플래그, 동작모드 설정비트, 제어비트 등 포함. SPSR(이전 CPSR 값저장)
Thumb state 레지스터 구성
- 레지스터 사용이 크게 재한
- R8 ~ R12 까지 범용 레지스터는 사용 불가
- ARM state처럼 범용 레지스터 뱅킹 이점을 갖지 못함
2) 프로그램 상태 레지스터
프로그램 상태 레지스터
- 1개의 CPSR
- 5개의 SPSR : CPSR의 뱅킹 레지스터. 예외 처리 함수에서 사용. 모드 변경시 CPSR 내용을 SPSR로 복사
- condition code flag, control bits
컨디션 코드 플래그 필드
- CPU 연산 결과를 반영하는 플래그 필드
- nzcv 4개의 플레그 사용
- N : 연산 결과가 음수
- Z : 연산 결과가 음수
- C : 캐리 발생, 자리빌림, 최상위 비트로 쉬프트되어 나온값
- V : 연산결과가 오버플로시 표시
컨트롤 비트 필트
- 인터럽트 허용 여부 결정 -> T/I비트
- 프로세서 동작모드설정 -> 모드설정비트
- 프로세서 상태 표시 -> T 비트
- 예외 발생시 변경
- 특권 모드에서 소프트웨어적으로 변경 가능
* T 비트 : 프로세서의 state 표시. 0이면 ARM state, 1이면 thumb state
* I 비트 : 인터럽트 disable 비트. 1설정시 인터럽트 불허
동작 모드 필드
- 동작 모드 필드 값에 따라 프로세서의 동작 모드가 결정됨
'컴퓨터과학 > 임베디드' 카테고리의 다른 글
| ARM을 활용한 임베디드 시스템 설계 7 - ARM 명령어 구조 (0) | 2020.05.04 |
|---|---|
| ARM을 활용한 임베디드 시스템 설계 6 - 레지스터 (0) | 2020.05.04 |
| ARM을 활용한 임베디드 시스템 설계 4 - ARM 프로세서 구조 (0) | 2020.05.03 |
| ARM을 활용한 임베디드 시스템 설계 3 - 개발 (0) | 2020.05.03 |
| ARM을 활용한 임베디드 시스템 설계 2 - 구성 (0) | 2020.05.03 |