opcode의 한계
- opcode는 기계어와 1:1 대응 -> 모든 프로그램 작성 가능
- 프로그래밍 언어의 변수, 함수 같은 요소를 못써 과정이 매우 불편
어셈블리어
- Assembly language
- opcode보다 상위 프로그래밍 언어
- 어셈블리코드 -> opcode -> 기계어
어셈블리어의 추상화
- 추상화 정도가 낮은 경우 -> opcode와 유사 -> 기계어로 바로 번역
어셈블러
- asembler
- 에셈블리어를 기계어로 번역하는 프로그램
- 어셈블리어는 어셈블러에 종속됨 -> 에셈블러에 따라 문법이 다름
opcode와 어셈블러
- opcode는 cpu 제조사에서 정함 -> 특정 cpu의 opcode는 어셈블러와 상관없이 모두 똑같음.
- 어셈블러 개발사가 어셈블리 문법을 정함.
어셈블리어의 복잡도
- 문법의 정의에 따라 복잡 or 단순
- (추상화 수준을 낮춤) 단순 해질수록 opcode와 유사
- (추상화 수준을 높임) 복잡 해질수록 프로그래밍 언어에 가까워지며, 어셈블러 구현 힘듬
CPU 확장(데이터 버스를 16비트에서 32비트로)
- 접근 가능 메모리 용량이 32KB(2^16) -> 4GB(2^32)로 증가
- 여유 비트가 증가 -> 다양한 opcode 정의 가능
- 레지스터 확장 가능 : A, B, PC 3개 -> 16개(이 중 4개는 데이터 저장, 연산이 아닌 특수 용도)
레지스터 추가
- LR(Link register) : 하위 함수나 보조 루틴에서 작업을 마친 뒤 호출 위치로 복귀해야할때 호출 지점의 위치를 저장
- SP(Stack pointer) : 스택 레지스터 - 현재 사용하는 스택의 메모리 주소
- ST(Status) : 상태 레지스터 - ALU의 연산 결과를 저장하는 레지스터로 연산 결과와 같이 새 opcode에 사용
상테 레지스터(Status Register)
- 32비트 중 LSB 방향의 4비트만 사용
- 연산 결과가 32비트를 넘을 시 오버플로(overflow)에 1이 쓰임.
- 덧셈 or 곱셈 연산으로 자리넘김이 발생 시 캐리에 1을 씀.(ALU의 carry out 핀이 직접 연결됨)
- 연산 결과가 0일때 Zero에 1 써짐(ALU 출력 핀 전체가 연결된 32-input-NAND 게이트에 연결)
- 연산 결과가 음수일때 Negative에 1을 쓰기

특수 레지스터와 범용 레지스터
- 레지스터 16개 중 특수 목적의 LR, SP, ST, PC을 제외한 12개 레지스터는 데이터 처리용
- 범용 레지스터의 이름은 A ~ L
어셈블리어 정의
- 이후 고급언어를 다룰것이므로 추상화 저수준 어셈블리어를 다룸
이동 명령
- MOV Rd, {Rs | Value}
- Rd : 데이터가 들어갈 레지스터
- Rs : 원본 데이터가 있는 레지스터
- Value : 그냥 값
- 이동 명령은 즉시 주소 지정 방식만 사용하므로 레지스터 이름이나 값을 직접 사용해야함.
*{A | B} 는 A나 B 둘중 하나를 선택
산술 명령
- 덧셈, 뺄셈, 곱셈, 나눗셈, 나머지 연산 5가지
- 주소 지정 방식을 어디까지 허용할 것인지 정해야 함
- ADD Rd, R1, {R2 | Value}
- SUB Rd, R1, {R2 | Value}
- MUL Rd, R1, {R2 | Value}
- DIV Rd, R1, {R2 | Value}
- MOD Rd, R1, {R2 | Value}
- 레지스터 끼리 or 레지스터와 값을 계산
- Rd는 값이 저장되는 레지스터
ex) ADD B, C, D => B = C + D
* 로드/스토어
로드 : SRAM -> 레지스터
스토어 : 레지스터 -> SRAM
로드/스토어 명령
- LDR Rd, { Rs | #Rs | [Rs] | [#RS] | Address | #Address | [Address] | [#Address] }
- STR Rd, { Rs | #Rs | [Rs] | [#RS] | Address | #Address | [Address] | [#Address] }
- 로드/스토어 명령에는 모든 주소 지정방식이 가능하도록 순서대로 지정
1. 레지스터 직접 주소 지정 방식
2. 레지스터-프로그램카운터 연관 직접주소지정방식
3. 레지스터 간접 주소지정방식
4. 레지스터-프로그램카운터 연관 간접주소지정방식
5. 단순 직접 주소 지정 방식
6. 프로그램 카운터 연관 직접 주소 지정방식
7. 단순 간접 주소 지정방식
8. 프로그램 카운터 연관 간접 주소 지정방식
로드/스토어 명령 예시
1. LDR A, [B] (레지스터 B에 0x2324가 저장 됨)
-> 주소 0x2324의 데이터를 읽어 레지스터 A에 저장
2. STR A, [B] (레지스터 B에 0x2000가 저장 시)
-> 레지스터 A의 값을 B의 값이 주소인 메모리(0x2000 번지)에 저장
논리 연산 명령
- AND Rd, R1, {R2 | Value}
- OR Rd, R1, {R2 | Value}
- XOR Rd, R1, {R2 | Value}
- Not Rd, {Rs | Value}
- 논리 연산은 즉시 주소 지정방식만 사용
- R1과 R2/Value을 연산하여 결과를 Rd에 저장
비트 시프트 명령
SHL Rd, R1, {Rc | Count}
SHR Rd, R1, {Rc | Count}
- 비트 시프트 명령도 즉시 주소 지정 방식만 사용
- R1의 데이터를 Rc 레지스터 혹은 count 만큼 왼쪽/오른쪽 시프트
* 이후 상태 레지스터를 사용하는 명령
비교 명령
- CMP R1, {R2 | Value}
- 연산 결과가 상태 레지스터에 저장 -> Rd, Rs 쓰지 않음
- CMP 명령으로 R1-R2가 0이 되거나 음수 인 경우 상태레지스터의 zero/negative 비트가 1이 됨
* SUB 명령 연산 결과에 따라 상태 레지스터는 변하지 않음
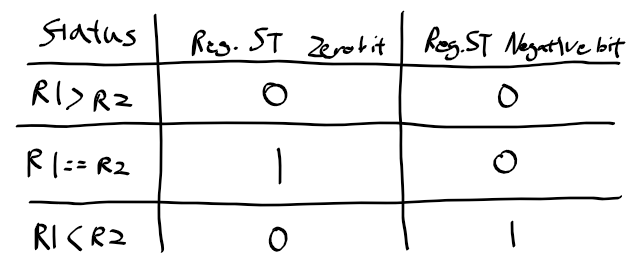
분기 명령의 종류
- BR { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BSUB { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BEQ { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BGT { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BLT { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BGET { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
- BLET { Reg | #Reg | [Reg] | [#Reg] | Address | #Address | [Address] | [#Address] }
분기 명령
- 분기 명령은 프로그램 카운터 레지스터의 값을 바꾸는 명령
-> 주기억 장치 메모리 주소 만큼 데이터 처리가 필요
-> 8개 주소 지정 방식 모두 사용
- BR : 조건 없는 분기. 해당 메모리 주소로 PC 값 변경
- BSUB : 분기 전 당시 PC 값을 링크 레지스터에 저장
* 분기 명령은 함수 호출 등 구현에 자주 사용. 함수 처리 후 원래 위치 돌아갈때 그 원래 위치를 기억(링크 레지스터)
- BEQ : CMP 명령에서 R1, R2가 같을 때 분기 -> Status Reg : Zero bit 1 or Negative Bit 0
- BGT : R1이 R2보다 클때 분기 -> Status Reg : Zero bit 0 and Negative Bit 0
- BLT : R1이 R2보다 작을 때 분기 -> Status Reg : Zero bit 0 and Negative Bit 1
- BGET : R1이 R2보다 같거나 클때 분기 -> Status Reg : Zero bit 1 or Negative Bit 0
- BLET : R1이 R2보다 같거나 작을때 분기 -> Status Reg : Zero bit 1 or Negative Bit 1
*** 이전의 내용은 opcode 연관 어셈블리어 문법 ****
순수 어셈블리어 문법
- 상수 선언, 변수 선언, 레이블 정의 (분기 문법은 고급 언어에서 구현 예정)
상수 선언 문법
- 기호와 값을 정의 -> 어셈블리가 기호를 값으로 변경
- DEF symbol content
- content에 레지스터 이름, opcode, 다른 기호나 주소가 될 수 있음
변수 선언 문법
- BYTE symbol 초기값 : 1바이트 선언문
- WORD symbol 초기값: 4바이트 선언문
- STRING symbol "초기값" : 문자열 변수
- 상수 선언은 기호를 content로 변경, 변수 선언은 메모리 특정 위치에 변수 값이 저장
- 변수의 symbol이 변수 값이 저장된 메모리 주소 표현
레이블
- symbol:
- 어셈블러가 알아서 해당 위치 주소로 변경
어셈블러와 어셈블리어의 발전
1. (최초)기계어로 어셈블러 구현
2. 어셈블러로 어셈블리어 구현
3. 어셈블리어로 어셈블러 구현 ...
심벌 테이블(symbol table)
- 변수와 레이블 처리를 위해 어셈블러 수준에서 심벌 테이블을 만들어야 함.
심벌 테이블 만들기
- 어셈블리어 코드 한줄씩 읽기 -> 기계어로 변환
- 기호 정보(변수, 레이블) 만남 -> 기호 이름과 주소 오프셋 위치 심벌 테이블에 기록 -> 끝까지 읽어 심벌 테이블 완성
- 심벌 테이블의 참조 정보를 이용해 실제 값/주소로 대치하여 기계어 완성
심벌 테이블
- 기호 이름으로 구분 + 대치할 값이나 주소 등록
- 기호를 참조 위치 주소 오프셋은 ref에 기록
- 여러 번 참조 가능하므로 ref가 여려개 일수 있음
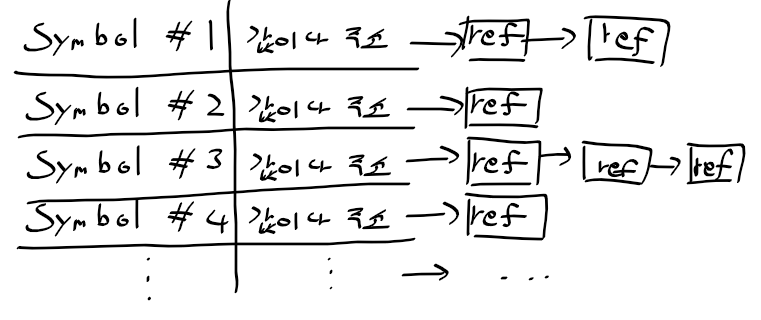
심벌 테이블 사용
- DEF symbol content -> content 값 자체로 대치
- [레이블] symbol : ->코드 영역 메모리 주소로 대치
메모리 영역 활용과 어셈블러
- BYTE, WORD, STRING으로 선언되는 변수는 메모리의 데이터 영역에
- opcode가 어셈블러로 기계어로 번역되는 데이터는 메모리의 코드 영역으로 구분 필요
- 메모리에서 코드 영역과 데이터 영역을 어떻게 배치할 것인지 정책 필요.
메모리에 변수 영역 배치 방법
1. 변수 선언부에 두기
- 변수 선언부에 데이터 영역 배치
- 어셈블리어 코드 중간마다 변수 선언 시 코드 영역과 데이터 영역이 섞임
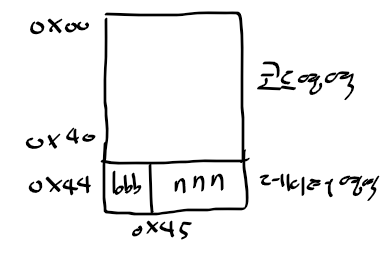
2. 데이터 영역을 한 곳에 모으기
- 코드 영역의 앞이나 뒤 가능
- 코드 끝난 후 데이터 영역 배치시 중간 마다 변수 선언 되어도, 변수 선언 전에 참조되어도 상관 없음
- 변수 선언과 함께 심벌 테이블에 등록 순간에 실제 메모리 주소를 알 수 없다.
-> 코드 영역 번역 후 데이터 영역 할당 완료 후 심벌 테이블의 주소 공간 값 등록
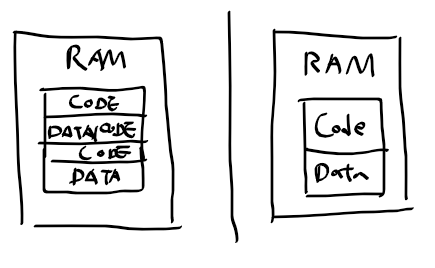
어셈블러 동작
- 상수/변수 선언을 지나 코드 영역 만나면 opcode를 기계어로 번역
- 기호 참조시 심벌 테이블에서 해당 기도의 참조 위치 목록에 opcode의 프로그램 카운터 값을 넣음
-> 심벌 테이블 완성 후 참조 위치 목록 찾아 실제 값 넣음
two-pass 어셈블러
- 선언이 코드 보다 늦게 해석 -> 코드 해석시 심벌 테이블에 기호 정보가 없어 참조 위치 등록 불가
- 대부분 어셈블러는 두번 해석
- 첫 해석에서 코드는 무시하고, 데이터 정보만 해석하여 테이블 구성
two-pass 어셈블러 심벌 테이블 구성
1. opcode 건너 뛸때마다 어셈블러 내부 PC를 opcode 길이 만큼 늘림
2. opcode 건너 뛴 간격 만큼 데이터 영역 주소가 확정 -> 완전한 심벌 테이블
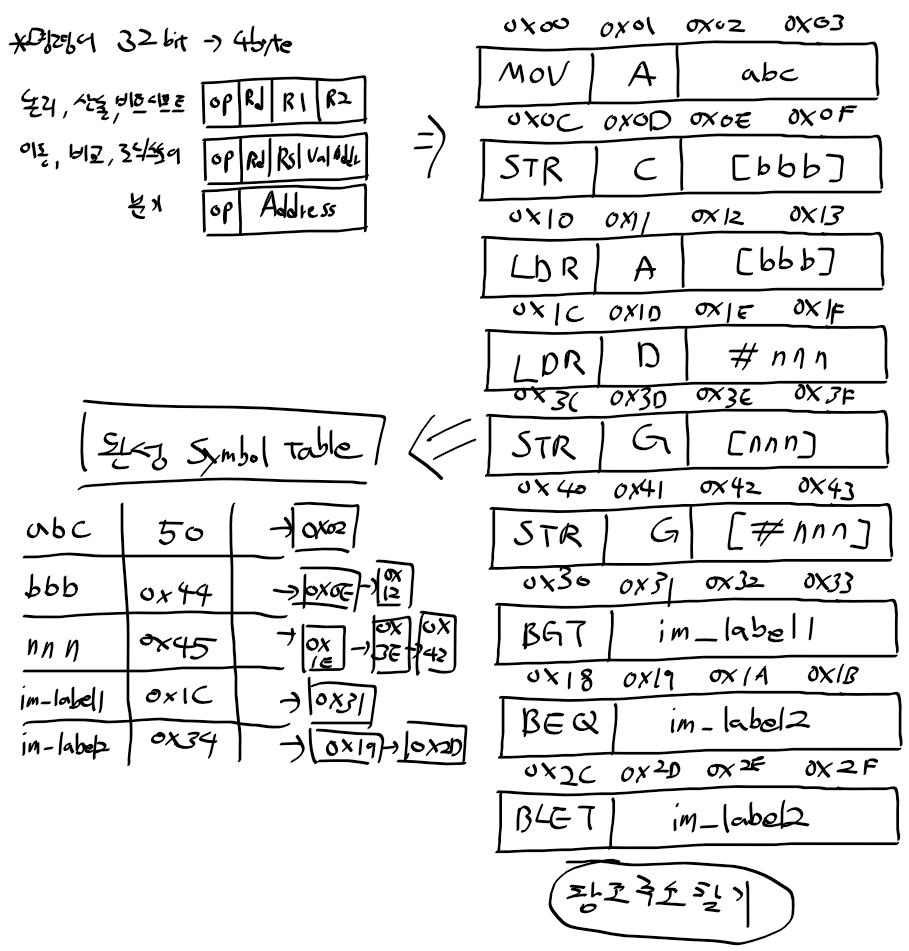
two-pass 어셈블러로 해석 예시
DEF abc 50
BYTE bbb 0xFF
MOV A, abc
MOV B, 0x33
ADD C, A, B
STR C, [bbb]
WORD nnn 0x10EF
LDR A, [bbb]
CMP A, C
BEQ im_label2
im_label1:
LDR D, #nnn
LDR E, [#D]
CMP D, E
SUB F, D, E
BLET im_label2
BGT im_label1
im_label2:
SUB F, E, D
SHR G, F, 0x4
STR G, [nnn]
STR G, [#nnn]
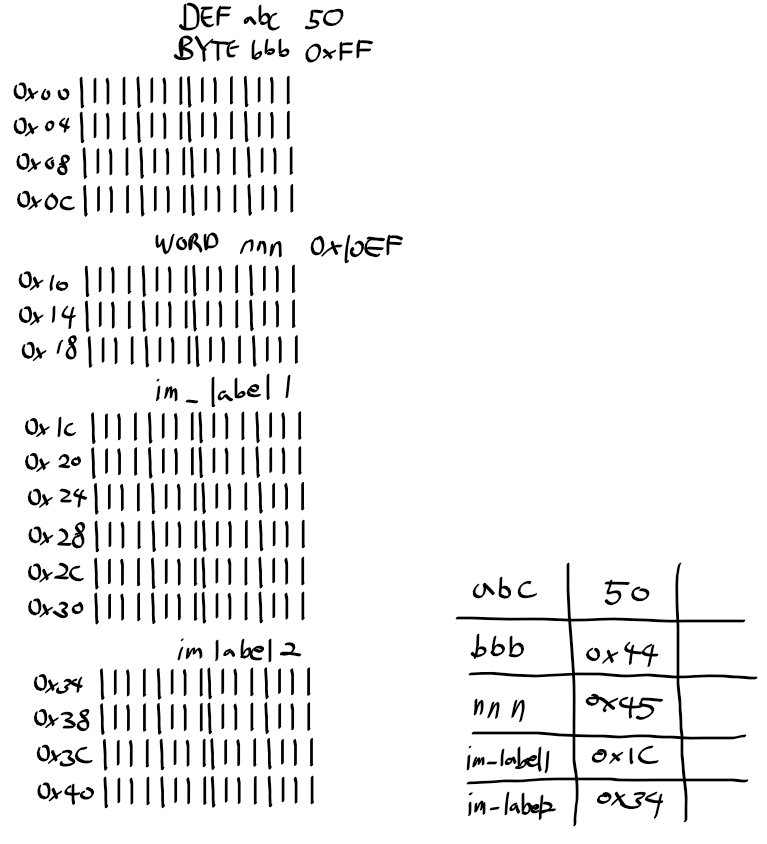
two-pass 어셈블러 첫 해석
1. DEF abc는 값 50을 등록
2. 데이터 영역은 코드 영역 다음에 두므로 BYTE bbb의 주소로 0x44가 등록
3. nnn은 bbb 다음인 0x45로 주소가 등록
4. 레이블 im_label1/2는 코드 영역 주소 그대로 등록
5. 이후 주소, 갑, 해당 기호 참조 주소 기록 필요
* 주의) 명령어도 데이터 공간을 차지하므로 참조 주소의 값이 각 명령어의 시작 주소가 아님
심벌 테이블 완성하기
- 명령어는 32비트 -> 4바이트
- 명령어는 아래와 같이 분할되며 심벌 테이블에 참조 주소들이 등록됨
two-pass 어셈블러의 두 번째 해석
- 변수, 상수 등 기호 정보는 무시하고 기계어로 번역
- 기호 정보를 사용한 명령어를 만날시 심블 테이블에서 값/주소 찾아 사용
- 심벌 테이블에 없는 기호 사용 -> 에러 발생
'컴퓨터과학 > 컴퓨터, OS' 카테고리의 다른 글
| os만들기 - 1. 바이너리 에디터 (0) | 2020.07.28 |
|---|---|
| 오브젝트 파일 ~ 고급 언어 (0) | 2020.05.01 |
| 주소 지정방식 (0) | 2020.04.29 |
| Nand2Tetris 2 - 불 연산 (0) | 2020.04.29 |
| NAND2Tetris 1 - 불 논리 (0) | 2020.04.25 |