소스 코드 파일을 여러개 만드는 이유
- 큰 프로그램을 하나의 코드로 만들 시 -> 복잡, 분량이 너무 큼 -> 작업 불가 -> 논리/기능 단위로 분리
- 라이브러리 활용 : 자주 쓰는 함수를 파일에 모아 여러 프로그램에서 같이 사용
- 소스 코드 + 라이브러리 소스 코드 전체 같이 컴파일은 비효율 적
외부 기호 참조 문법 - EXTERN 문법
- EXTERN symbol
- EXTERN 기호는 심벌 테이블에 등록, 외부에서 선언된 기호라 표시
- opcode에 임의의 값을 넣었다가 나중에 다른 파일에서 심벌 테이블을 읽어 대치함.
EXTERN 대치 시 주의 사항
- EXTERN 기호가 대치 시 다른 파일의 주소 값을 사용 x
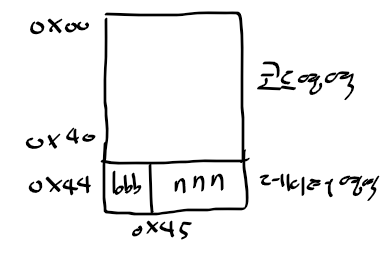
- 모든 파일의 기계어 코드 + 변수 데이터가 결국 하나로 합쳐 바이너리 생성됨
- 코드/데이터 영역 크기 고려 필요
오브젝트 파일 Object file
- 모든 소스코드가 매번 컴파일은 비효율 -> 필요한 코드면 컴파일 + 변경 없는 코드는 컴파일 x
-> 변경 없는 파일을 미리 컴파일 해둠
<-> 미리 컴파일 시 변경된 코드와 병합 시 주소 영역 등이 일치 x
- 중간 파일 역활
오브젝트 파일로 바이너리 만들기
- opcode는 모두 기계어로 바꿈. 기호 정보는 오브젝트 파일에 기록
- 각 오브젝트 파일의 기호/참조 정보 조합 -> 바이너리 파일 생성
링커 Linker
- 오브젝트 파일을 합쳐 바이너리 만드는 프로그램
- 정적 링킹, 동적 링킹
링킹 Linking
- 오브젝트 파일 간 기호 참조 정보를 모아 분석, 정리
정적 링킹 static linking
- 라이브러리 오브젝트 파일과 프로그램 오브젝트 파일을 합쳐 단일 바이너리 파일 생성
- 링커 동작하기 간단
동적 링킹 dynamic linkiing
- 라이브러리 특정 영역을 필요한 순간 재배치하여 프로그램 동작 하는 방식
- 정적 링킹에 비해 바이너리가 작고, 컴파일 빠름
- 구현 어려움
오브젝트 형식 설계 시 주의 사항
- 기호 정보와 참조 정보를 어떻게 유지할 것가
- EXTERN은 외부 파일 참조 의미 -> 다른 파일에서 해당 값을 찾지 못할 수 있음 -> 링킹 실패
EXPORT 기호를 사용하는 방법
- 외부에서 사용하는 기호에 EXPORT 선언 키워드 쓰기
- EXTERN은 타 파일 심벌 테이블에서 EXPORT만 찾아 링커 구성
- 오브젝트 파일에 EXPORT 기호만 포함시키므로 간단 <-> 불일치 시 에러 발생, 자유도 저하

EXTERN만 사용하는 방법
- EXTERN 만으로 외부 참조 기호를 찾을 수 있도록 링커 설계
- 다른 오브젝트 파일 심벌 테이블에 있는 모든 기호/참조 정보로 본체를 찾아야 함.
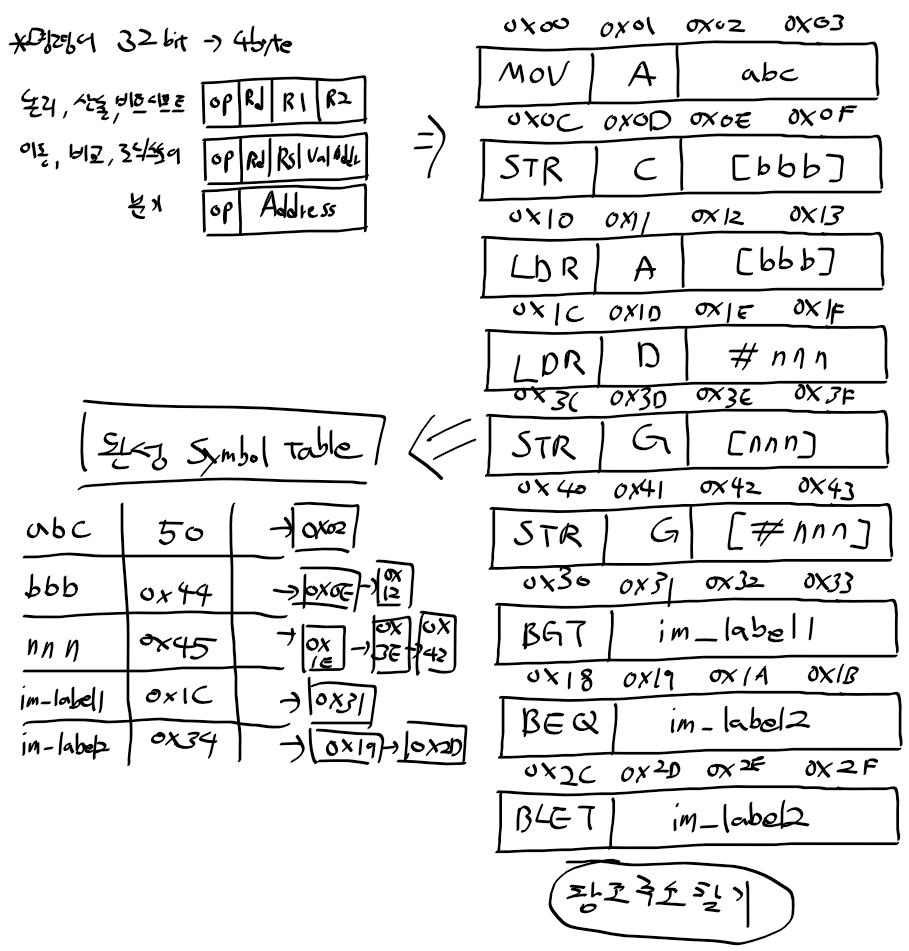
오브젝트 파일 형식
- 헤더 : 어디에 어떤 심블 테이블이 있는지 표시. 링커는 헤더의 기계어 시작부터 읽고 합쳐 바이너리 완성
- 내부 심벌 참조 테이블 : EXTERN 제외한 모든 기호의 심벌 테이블 정보. 심벌테이블을 오브젝트 파일에 기록한것.
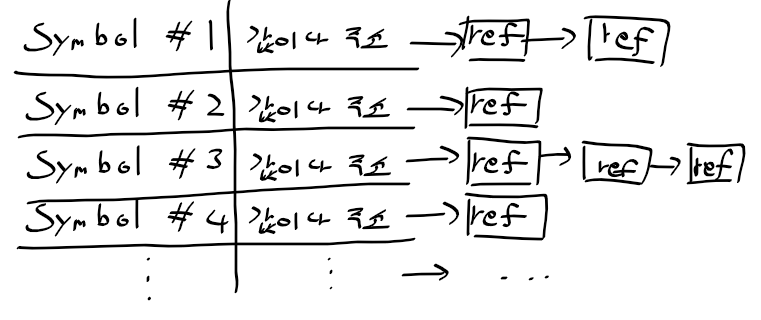
타 오브젝트 파일의 EXTERN이 참조하는 대상
- 외부 심벌 참조 테이블 : EXTERN 선언 기호 기록. 타 오브젝트 파일의 내부 심벌 참조 테이블에서 주소/값 읽어
opcode 인자에 씀

오브젝트 파일이 서로 참조하는 방법
- 한 오브젝트 파일의 외부 심벌 참조 테이블은 타 오브젝트 파일 내부 심벌 참조 테이블 참조
-> 링커는 모든 오브젝트 파일의 내부 심벌 참조 테이블로 통합 심벌 테이블을 만듬
-> 통합 심벌 테이블에서 각 오브젝트 파일의 외부 심벌 참조 테이블의 기호를 찾아 값/주소를 전달
오브젝트 파일 -> 바이너리
- 기계어 코드 : 코드 영역 + 데이터 영역이 위치한 곳
- 기계어 코드 내 심벌이 참조하는 opcode 인자를 심벌 테이블의 값/주소로 대치
-> 바이너리 완성

재배치 relocation
- 링커가 오브젝트 파일을 합칠 때 배치되는 순서
- 이 순서에 따라 기계어 코드에서 참조 주소 절댓값이 변경됨 -> 주소 값을 정해주는 작업
- 오브젝트 파일 = 재배치 가능 파일 형식
- 링커는 주소 절대 값이 바뀌어도 해당 주소 기호를 참조하도록 함

재배치 시 주소 지정 방식
- PC/Reg-PC 연관 주소 지정 방식을 제외한 모든 방식은 메모리 특정 위치를 절대값으로 주소 지정
- 절대 주소 지정 방식은 재배치로 기호/참조 정보의 주소가 바뀔 시 opcode의 주소 영역도 바뀌어야함.
- 연관(상대) 주소 지정 방식은 opcode 주소 영역 수정 필요 x
번역
- 코드의 체계가 바뀌는 과정
ex) 어셈블리어 -> opcode, opcode -> 기계어
컴파일 compile
- 상위 언어에서 하위 언어로 번역
- 최종 결과는 기계어
컴파일러 compiler
- 컴파일 하는 프로그램
빌드 build
- 컴파일 + 링킹해서 최종 프로그램을 만드는 전 과정
컴파일러 만들기
- 문법 정의가 필요
-> 대표적으로 BNF(backus-naur form) 베커스 나우어 형식
BNF
- 문법 체계가 있는 간단한 규칙 표현
BNF 예시
- ::= 은 프로그래밍 언어의 =처럼 우변을 좌변에 대입
- |은 또는
- <>는 확장
-> 문장에 대해 BNF로 아래처럼 정의
<문장> ::= <주어> <서술어>.
| <주어> <목적어> <서술어> .
| <문장> <접속사> <문장>.
BNF 정의 추가
- <>이 없는 경우 종결 기호
-> BNF 모든 규칙은 종결기호로 결과가 나옴
<주어> ::= <명사> <조사>
| <명사>
<서술어> ::= <부사> <동사>
| <동사>
<목적어> ::= <명사> <조사>
<명사> ::= 내 | 너 | 그
<동사> ::= 가다 | 오다
<부사> ::= 빨리 | 늦게
<조사> ::= 을 | 를 | 이 | 가
<접속사> ::= 그리고 | 그러나 | 그런데 | 하지만
BNF로 만들 수 있는 문장
내가 가다.
내가 오다.
너가 가다.
너가 오다.
그가 가다.
그가 오다.
내가 가다. 그리고 너가 오다. 그러나 그는 가다.
BNF 언어 설계
<program> ::= <block-list>
//프로그램은 하나의 블록 리스트
<block-list> ::= <ident>(<ident-list>) {<decl> <statement>}
| <block-list> <ident> (<ident-list>) {<decl> <statement>}
/*
<ident> : 블록 이름
<decl> : 변수/상수 선언
<statement> : 연산/ 제어부분
*/
<ident-list> ::= <ident>
| <ident-list>, <ident>
/*
ident-list 예시
* ,를구분자로 사용
a, b, c, d, .., g
this_is_param
*/
<ident> ::= <ident> <ident-letter>
| <ident> <digit>
| <ident-letter>
/*
- ident의 예시
a
abbb
adasfwq53163
*/
<ident-letter> ::= a | b | c | ... | z | A | B | ... | Z
<digit> ::= 1 | 2 | 3 | ... | 9 | 0
<decl> ::= <def-decl> <var-decl>
| <decl> <def_decl> <var-decl>
<def-decl> ::= <ident> <number>
<var-decl> ::= <ident-list>;
| <var-assignment-list>;
/*
변수 선언부
<ident-list>; -> 변수명만 쓰고 ;로 끝냄
<var-assignment-list>; -> 변수명, 변수명, ... 변수명;
*/
<var-assignment-list> ::= <ident>=<number>
| <var-assignment-list>, <ident>=<number>
/*
변수 선언 문법
a=10
a=10, b=20, c=30
*/
<number> ::= <number> <digit>
// number : 십진수의 연속
<statement> ::= <ident>=<expression> //a=3, c=a+b
| <ident>(<ident-list>) //func(), func(a, b, c, d, e)
| (<statement-list>)
| if <condition> then <statement>
| while <condition> do <statement>
<statement-list> ::= <statement>
| <statement-list>; <statement>
<ident>=<expression>
<expression> ::= <term>
| <adding-operator> <term>
| <expression> <adding-operator> <term>
<adding-operator> ::= + | -
<term> ::= <factor>
| <term> <multiplying-operator> <factor>
<multiplying-operator> ::= * | /
<factor> ::= <ident>
| <number>
| (<expression>)
<codition> ::= not <expression>
| <expression> <relation> <expression>
<relation> ::= = | <> | < | > | <= | >= | ==
/*
if A > B then
C = A - B;
if A <= B then
C = B - A;
위 if문은 어셈블러어로 아래와 같이 컴파일 된다.
*/
if:
CMP A, B
BGT sub_a_b
BLET sub_b_a
sub_a_b:
SUB C, A, B
B end_if
sub_b_a:
SUB C, B, A
B end_if
end_if:
:
빌드 과정
1. 컴파일러는 BNF 정의에 따라 소스코드 파싱(구문분석)
2. 최적화 된 어셈블리어로 번역 -> 고급언어의 결과 파일
3. 어셈블러가 오브젝트 파일로 변환
4. 링커가 오브젝트 파일 결합 -> 바이너리 완성
'컴퓨터과학 > 컴퓨터, OS' 카테고리의 다른 글
| os만들기 - 2. 에뮬레이터에서 돌리기 삽질기 feat.msys (0) | 2020.07.29 |
|---|---|
| os만들기 - 1. 바이너리 에디터 (0) | 2020.07.28 |
| 어셈블리어 ~ 심벌 테이블 (0) | 2020.05.01 |
| 주소 지정방식 (0) | 2020.04.29 |
| Nand2Tetris 2 - 불 연산 (0) | 2020.04.29 |