머신 러닝의 대표적인 문제
- 분류와 회귀 문제가 있음.
- 분류 : 주어진 데이터가 있으면 이 데이터가 어떤 카테고리에 속하는가에 대한 문제
- 회귀 : 데이터가 주어지면 이 데이터로 연속적인 값을 추정하는 문제
선형 회귀
- 독립 변수들과 하나의 종속 변수가 주어지고, 이에 대한 데이터들이 있을때 종속 변수를 가장 잘 추정하는 직선을 구하는 문제
- 새로운 데이터가 주어지면 학습 과정에서 구한 회귀선으로 연속적인 값을 추정할 수 있음.
- 선형 회귀 모델은 계수 벡터 beta = [beta0, . . ., beta_p], 독립 변수 벡터 x = [0, x1, ...., x_p]의 선형 결합의 형태가 됨.
- e는 오차 모형으로 기본적으로 평균 0, 분산이 1인 정규 분포를 따르고 있음.
-> 회귀 선과 추정한 y 사이의 오차를 의미함.

- 실제 종속 변수를 y, 주어진 독립변수를 통해 예측한(추정한) y를 y hat로 표기
- 오차 e는 y - y_hat으로 아래와 같은 관계를 가지고 있음.

단순 선형 회귀 모형
- 독립 변수가 1개인 선형 회귀 모형
- 아래의 좌측과 같이 2차원 공간 상에 점들이 주어질때, 우측과 같은 선형 회귀 모델을 구할 수 있음
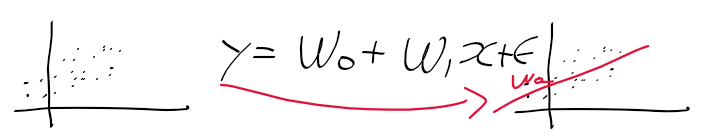
- 기존의 회귀 계수 beta를 여기선 가중치의 의미로 w로 표기함.
- 오차 = 실제 값 - 추정 값의 관계를 가짐.

최소 제곱 오차 MSE : Mean Sqaured Error
- 실제 결과(y_i) - 추정 결과(y_i hat)의 제곱한 것을 모든 데이터에 대해 합한 후 데이터 갯수(N) 만큼 나누어 구한 오차

- 위의 산점도 데이터가 주어질떄 MSE를 최소가 되게하는 회귀 계수들로 선형 회귀 모델을 만듬

회귀 계수 구하기 기초
- MSE를 최소로 만드는 회귀 계수는 편미분을 통해 구할 수 있음.
- y = x^2라는 그래프가 주어질때, argmin(y)를 구하는 x를 얻으려면, y를 x로 편미분하여 0이 나오게하는 x를 구하면됨.
- d/dx y = 2x = 0 => x = 0일때 기울기는 0으로 y는 최소 값을 가짐
- 단순 선형 회귀 모델의 회귀 계수 구하는 방법 : MSE를 w0, w1에 편미분 한 후 0이 되도록 하는 w0, w1를 구함.

회귀 계수 구하기
- MSE를 w0, w1로 편미분하여 0이되는 w0, w1을 구하자

- n제곱 다항식의 미분에 대한 공식을 이용하여 w0, w1에 대해 편미분을 하면 아래와 같이 정리할 수 있음.

w0 회귀 계수 구하기
- 회귀 계수는 초기에 특정 값(주로 1)로 초기화 후 오차의 크기에 따라 갱신 값을 빼 조금씩 조정됨
- MSE를 w0로 편미분(갱신 값)하여 0이 되게 만드는 w0는 아래와 같이 구할 수 있음.
=> 기존의 회귀 계수(w0) - 기존 회귀 계수의 오차(갱신 값, d MSE/ d w0) = 새 회귀 계수(w0)
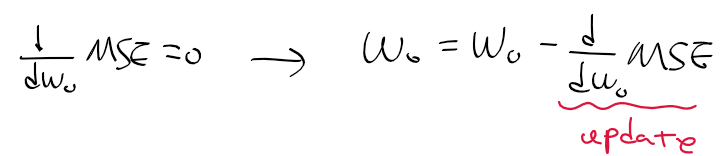
- 갱신 값이 너무 큰 경우, 올바른 회귀 모델을 구하기 힘들어짐
-> 학습률 learning rate를 통해 조금씩 오차를 조정해 나감.
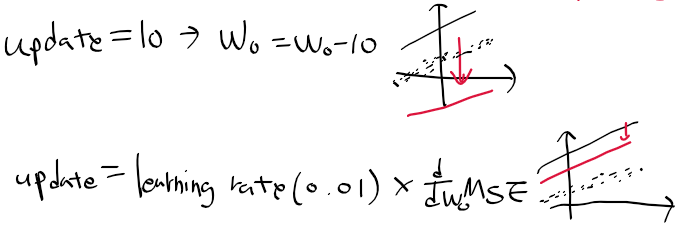
2차원 데이터로 부터 단순 선형 회귀 모델 구하기
1. 데이터 준비

import numpy as np
import matplotlib.pyplot as plt
# y = w0 + w1 * x 단순 선형 회귀 식
# y = 4x + 6(w0 = 6, w1= 4)에 대한 선형 근사를 위해 값 준비
x = 2 * np.random.rand(100, 1) # 0 ~ 2까지 100개 임의의 점
y = 6 + 4 * x + np.random.randn(100, 1) # 4x + 6 + 정규 분포를 따르는 노이즈
plt.scatter(x, y)
2. 주어진 데이터에 적합한 회귀 모델 구하기
- 가중치(회귀 계수) 1로 초기화 -> 가중치 갱신 과정 수행(get_weight_update)
- x에 대한 추정한 y를 구함 -> 실제 y - 추정 y로 오차 diff 구함.
- 위에서 구한 가중치 갱신 공식에 따라 w0, w1의 갱신 값을 구함(w0/w1_update)
- 가중치 - 가중치 갱신 값. 이 연산을 지정한 횟수 만큼 수행
=> 회귀 계수는 일정한 값으로 수렴함 : 선형 회귀 모델의 회귀 계수.

def get_weight_update(w1, w0, x, y, learning_rate=0.01):
# y는 길이가 100인 벡터, 길이 가져옴
N = len(y)
# 계수 w0, w1 갱신 값을 계수 w0, w1 동일한 형태로 초기화
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 주어진 선형 회귀 식을 통한 값 추정
y_pred = np.dot(x, w1.T) + w0
# 잔차 y - hat_y
diff = y - y_pred
# (100, 1) 형태의 [[1, 1, ..., 1]] 행렬 생성, diff와 내적을 구하기 위함.
w0_factors = np.ones((N, 1))
# 우측의 식은 MSE를 w1과 w0에 대해 편미분을 하여 구함.
# d mse/d w0 = 0 이 되게하는 w0이 mse의 최소로 함
# d mse/d w1 = 0 이 되게하는 w1이 mse를 최소로 함
# 급격한 w0, w1 변화를 방지 하기 위해 학습률 learning_rate 사용
w1_update = -(2/N) * learning_rate * (np.dot(x.T, diff))
w0_update = -(2/N) * learning_rate * (np.dot(w0_factors.T, diff))
return w1_update, w0_update
def gradient_descent_steps(X, y, iters= 10000):
w0 = np.zeros((1, 1))
w1 = np.zeros((1, 1))
for idx in range(0, iters):
w1_update, w0_update = get_weight_update(w1, w0, X, y, learning_rate=0.01)
# 갱신 값으로 기존의 w1, w0을 조정해 나감
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y- y_pred))/N
return cost
w1, w0 = gradient_descent_steps(x, y, iters=1000)
print("w1:{0:.4f}, w0:{0:.4f}".format(w1[0, 0], w0[0, 0]))
y_pred = w1[0, 0] * x + w0
print("gradient descent total cost : {0:.4f}".format(get_cost(y, y_pred)))
확률적 경사 하강법 stochastic gradient descent
- 위의 경사 하강법을 이용한 계수 추정 과정에서 주어진 모든 데이터를 사용함
-> 반복 횟수, 변수, 데이터 량이 많을 수록 느려짐
- 전체 데이터가 아닌 임의로 추출한 일부 데이터만 사용
- 아래의 경우 위(전체 데이터 100개)와 달리 10개만 추출하여 회귀 계수를 구함

def stochastic_gradient_descent_steps(x, y, batch_size=10, iters=1000):
w0 = np.zeros((1,1))
w1 = np.zeros((1,1))
prev_cost = 1000000
iter_idx = 0
for idx in range(iters):
# x의 크기만큼 임의의 인덱스 추출
stochastic_random_idx = np.random.permutation(x.shape[0])
# 임의의 인덱스의 x, y를 배치 사이즈만큼 샘플링
sample_x = x[stochastic_random_idx[0:batch_size]]
sample_y = y[stochastic_random_idx[0:batch_size]]
w1_update, w0_update = get_weight_update(w1, w0, sample_x, sample_y,learning_rate=0.01)
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
w1, w0 = stochastic_gradient_descent_steps(x, y, iters=1000)
print("w1:{0:.4f}, w0:{0:.4f}".format(w1[0, 0], w0[0, 0]))
y_pred = w1[0, 0] * x + w0
print("gradient descent total cost : {0:.4f}".format(get_cost(y, y_pred)))'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 20. 다항 회귀 (0) | 2020.12.06 |
|---|---|
| 파이썬머신러닝 - 19. 선형 회귀 모델과 선형 회귀를 이용한 보스턴 주택 가격 예측 (0) | 2020.12.04 |
| 파이썬머신러닝 - 17. 스태킹 모델로 유방암 분류하기 (0) | 2020.11.30 |
| 파이썬머신러닝 - 16. 캐글 신용카드 사기 검출 (0) | 2020.11.30 |
| 파이썬머신러닝 - 15. LightGBM을 이용한 캐글 산탄데르 고객 만족도 예측하기 (0) | 2020.11.28 |