캐글 신용사기 검출 대회
- 2013년 9월 유럽 신용카드 트랜잭션 데이터
- 2일간 284,807 트랜잭션중 492건이 사기로 전체중 0.172%뿐으로 데이터가 매우 불균형함
ref : www.kaggle.com/mlg-ulb/creditcardfraud
The datasets contains transactions made by credit cards in September 2013 by european cardholders.
This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
언더 샘플링, 오버샘플링
- 불균형 레이블 분포를 적절한 학습데이터로 만드는 방법, 오버 샘플링이 유리
- 언더 샘플링 : 클래스가 많은 데이터를 클래스가 적은 데이터 만큼 축소
ex. 정상 10,000건, 비정상 100건시 정상을 100건으로 줄임. *너무 많은 정상 데이터를 제거
- 오버 샘플링 : 클래스가 적은 데이터를 클래스가 많은 데이터 만큼 증가
* 단순 증강 시 오버피팅이 발생. 원본 데이터 피처를 약간씩 변형하여 증감
ex. SMOTE(Syntheic Minority Over sampling techinuqe : knn으로 적은 클래스 데이터 간의 차이로 새 데이터 생성
* imbalanced-learning 사용
1. 데이터로드
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
path = "./res/credit card fraud detection/creditcard.csv"
df = pd.read_csv(path)
df.head()
2. 전처리 및 훈련, 테스트 데이터 셋 분리 정의
from sklearn.model_selection import train_test_split
def get_preprocessed_df(df=None):
"""
input
df : before preprocessing
output
res : after dropping time columns
"""
res = df.copy()
res.drop("Time", axis=1, inplace=True)
return res
def get_train_test_datasets(df=None):
df_copy = get_preprocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target= df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target,
test_size=0.2,
stratify=y_target,
random_state=100)
return X_train, X_test, y_train, y_test
3. 로지스틱 회귀 모델로 성능 확인
- 정확도는 좋으나 재현률과 F1 스코어가 크게 떨어짐

X_train, X_test, y_train, y_test = get_train_test_datasets(df)
from sklearn.linear_model import LogisticRegression
from utils.common import show_metrics
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
show_metrics(y_test, y_pred)
4. 모델, 데이터를 줄때 학습 및 성능을 출력하는 함수 정의
def get_model_train_eval(model, ftr_train=None, ftr_test=None,
tgt_train=None, tgt_test=None):
model.fit(ftr_train, tgt_train)
y_pred = model.predict(ftr_test)
show_metrics(y_test, y_pred)
return model
5. LightGBM 성능 확인
- LR 보다 평가 지표들이 좋은 결과를 보임

from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators=1000, num_leaves=32,
n_jobs=-1, boost_from_average=False)
lgbm = get_model_train_eval(lgbm, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test = y_test)
6. 거래 금액 시각화
- df의 time, amount를 제외한 컬럼들은 PCA를 통해 얻은 주성분 요소들
- 로지스틱 회귀는 정규분포를 따르는 데이터를 사용하는것이 좋음 -> 표준화 정규기 사용

sns.distplot(df["Amount"])
7. amount 정규화 후 성능 비교
- 로지스틱 분류기나 LGBM이나 큰 성능 차이가 생기지는 않음

from sklearn.preprocessing import StandardScaler
def get_preprocessed_df(df=None):
res = df.copy()
scaler = StandardScaler()
#res["Amount_Scaled"] = scaler.fit_transform(df["Amount"].values.reshape(-1,1))
amount_scaled = scaler.fit_transform(df["Amount"].values.reshape(-1,1))
res.insert(0, "Amount_Scaled", amount_scaled)
res.drop(["Time","Amount"], axis=1, inplace=True)
return res
X_train, X_test, y_train, y_test = get_train_test_datasets(df)
lr = LogisticRegression()
print("logistic regression classification evaluation")
get_model_train_eval(model=lr, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
lgbm = LGBMClassifier(n_estimators=1000, num_leaves=64,
n_jobs=-1,boost_from_average=False)
print("\nLGBM classification evaluation")
get_model_train_eval(model=lgbm, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
8. 로그 변환후 성능 비교
- 라벨 분포가 심하게 왜곡된 경우 사용
- log 연산을 통해 매우 큰값도 작은 값으로 변환
-> 큰 변화는 생기지 않아보임. 교차 검증 필요

def get_preprocessed_df(df=None):
res = df.copy()
amount_scaled = np.log1p(res["Amount"])
res.insert(0, "Amount_Scaled", amount_scaled)
res.drop(["Time","Amount"], axis=1, inplace=True)
return res
X_train, X_test, y_train, y_test = get_train_test_datasets(df)
lr = LogisticRegression()
print("logistic regression classification evaluation")
get_model_train_eval(model=lr, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
lgbm = LGBMClassifier(n_estimators=1000, num_leaves=64,
n_jobs=-1, boost_from_average=False)
print("\nLGBM classification evaluation")
get_model_train_eval(model=lgbm, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
9. 이상치 제거를 위한 히트맵 시각화
- 클래스와 가장 강한 음의 상관 관계를 갖는 변수로 V17이 있는걸 확인할수 있음.
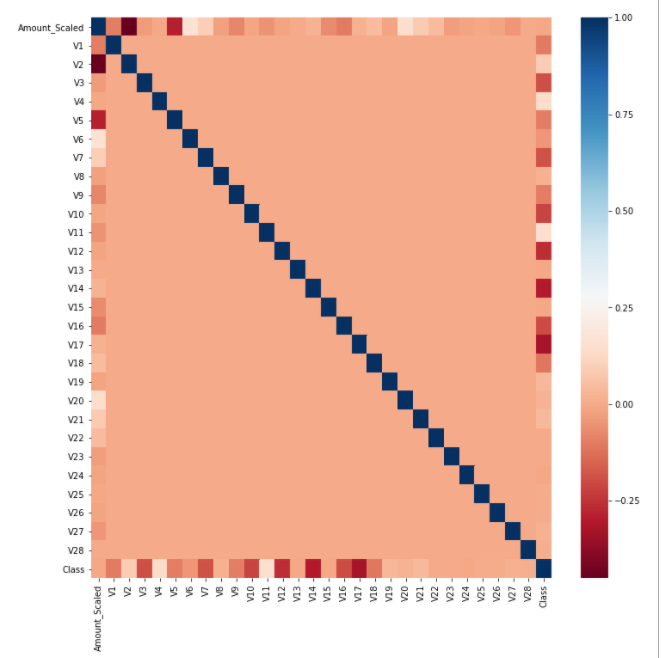
card_df = get_preprocessed_df(df)
plt.figure(figsize=(12,12))
corr = card_df.corr()
sns.heatmap(corr, cmap="RdBu")
10. 이상치 제거 후 성능 비교
- 25% - 1.5 * IQR보다 작거나 75% + 1.5 * IQR보다 큰 경우 아웃라이어판단.
- V17의 아웃라이어들 제거 후 성능 평가.
- LGBM의 평가 지표들이 약간 개선됨

def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df["Class"] == 1][column]
quatile_25 = np.percentile(fraud.values, 25)
quatile_75 = np.percentile(fraud.values, 75)
iqr = quatile_75 - quatile_25
iqr_weight = iqr * weight
lowest_val = quatile_25 - iqr_weight
highest_val = quatile_75 + iqr_weight
outlier_idx = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_idx
def get_preprocessed_df(df=None):
res = df.copy()
amount_scaled = np.log1p(res["Amount"])
res.insert(0, "Amount_Scaled", amount_scaled)
res.drop(["Time","Amount"], axis=1, inplace=True)
outlier_index = get_outlier(df=res, column = "V14", weight=1.5)
res.drop(outlier_index, axis=0, inplace=True)
return res
X_train, X_test, y_train, y_test = get_train_test_datasets(df)
lr = LogisticRegression()
print("logistic regression classification evaluation")
get_model_train_eval(model=lr, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
lgbm = LGBMClassifier(n_estimators=1000, num_leaves=64,
n_jobs=-1, boost_from_average=False)
print("\nLGBM classification evaluation")
get_model_train_eval(model=lgbm, ftr_train=X_train, ftr_test=X_test,
tgt_train=y_train, tgt_test=y_test)
11. SMOTE 사용하기 위한 imblanced-learn 설치. cannot import six 에러 해결(버전 매칭)
원랜 아래와 같이 하면되나
pip install imbalanced-learn
pypi.org/project/imbalanced-learn/#description
최신 imbalanced-learn이 scikit-learn 0.23 이상 버전을 요구
-> 자동 업그레이드 중 문제 발생했는지 cannot import six 에러로 사용불가
pip install -U imbalanced-learn==0.6.2
pip install -U scikit-learn==0.22.2
로 다운그레이드 하여 해결
12. over sampling
- SMOTE oversampling을 통해 작은 라밸을 큰 라밸과 크기를 맞춤
- lr의 경우 재현율은 좋아졌으나 정밀도와 f1 score는 크게저하
- lgbm은 성능 지표들이 대채로 저하

from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=100)
X_train_over, y_train_over = smote.fit_sample(X_train, y_train)
print("berfore smote : ",X_train.shape, y_train.shape)
print("after smote : ", X_train_over.shape, y_train_over.shape)
print("label distribution after smote \n", pd.Series(y_train_over).value_counts())
13. 성능 지표 정리
'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 18. 선형 회귀 모델과 경사 하강 법 이론과 구현 (0) | 2020.12.03 |
|---|---|
| 파이썬머신러닝 - 17. 스태킹 모델로 유방암 분류하기 (0) | 2020.11.30 |
| 파이썬머신러닝 - 15. LightGBM을 이용한 캐글 산탄데르 고객 만족도 예측하기 (0) | 2020.11.28 |
| 파이썬머신러닝 - 14. LightGBM (0) | 2020.11.27 |
| 파이썬머신러닝 - 13. GBM로 사용자 행동 분류 (0) | 2020.11.26 |