from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
y = train["count"]
X = train.drop(columns=["count"], axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
lr = LinearRegression()
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
eval_reg(y_test, pred)
오차가 가장 큰 값들 비교
실제 값과 예측 값사이 상당히 큰 오차
-> 타겟 값의 분포가 왜곡될 가능성이 큼
"""
종속 변수 count 값을 생각하면 오차가 상당히 크게 나옴
오차가 가장 큰 경우를 비교해보자
"""
def get_top_error_data(y_test, pred, n_tops = 5):
res = pd.DataFrame(data=y_test.values, columns=["real"])
res["predicted"] = pred
res["diff"] = np.abs(res["real"] - res["predicted"])
print(res.sort_values("diff", ascending=False)[:n_tops])
get_top_error_data(y_test, pred, n_tops=5)
라벨 분포 히스토그램으로 시각화
로그 변환을 통해 정규분포에 가깝게 변환
"""
예측 오류가 매우 큰것을 보면 타깃이 왜곡된 분포를 따르는지 확인해야함
"""
y.hist()
이전에 0을 중심으로 하던 분포가
5~6을 중심으로 정규 분포와 유사해짐
"""
로그 변환을 통해 y를 정규분포 형태로 바꾸어 주자
"""
y = np.log1p(y)
y.hist()
변환된 데이터로 재학습 및 성능 평가
rmse, mae는 크게 줄어들었으나 rmlse는 여전히 큼
-> 계수 확인해보자
"""
로그 변환을 수행 후
오차 척도들이 크게 줄어들었다.
"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
lr = LinearRegression()
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
eval_reg(y_test, pred)
get_top_error_data(y_test, pred, n_tops=5)
트리 모델에서 feature_importances_로 보았으나
회귀 모델에서 coef_로 볼수있음
"""
회귀 모델에서 피처 중요도로 보았던것과는 달리
선형 회귀 모델에선 회귀 계수로 어떤 피처가 중요하게 판단되었는지 몰수 있음
"""
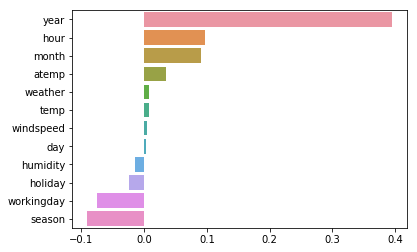
coeff = pd.Series(data=lr.coef_, index=X.columns)
coeff_sort = coeff.sort_values(ascending=False)
sns.barplot(x=coeff_sort.values, y=coeff_sort.index)
카테고리형 데이터들을
원핫 인코딩으로 변환 후
학습, 결과 출력
rmlse도 어느정도 줄어듦
"""
상대적으로 큰 값을 갖는 year가 높은 중요도를 가진것으로 나오고 있음
year 간에는 큰 의미가 없는데도 영향을 주고 있으니
카테고리형 변수들을 인코딩 필요
"""
X_ohe = pd.get_dummies(X, columns=["year", "month", "hour", "holiday", "workingday",
"season", "weather"])
X_train, X_test, y_train, y_test = train_test_split(X_ohe, y, test_size = 0.3)
lr = LinearRegression()
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
eval_reg(y_test, pred)
get_top_error_data(y_test, pred, n_tops=5)
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from lightgbm import LGBMRegressor
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, roc_auc_score
import pandas as pd
import numpy as np
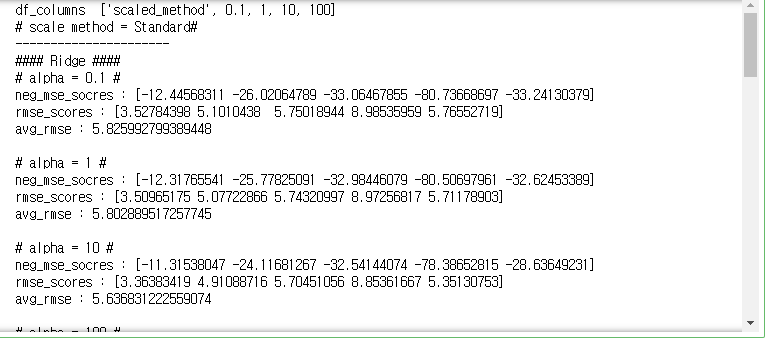
- 아래의 경우와 같이 가중치 벡터의 제곱에 패널티를 주는 경우를 L2 규제, L2 규제를 적용한 선형 회귀(릿지 회귀)
- 아래의 경우처럼 가중치 벡터의 절대값에 패널티를 주는 경우 L1 규제, L1규제를 적용한 선형 회귀(라쏘 회귀)
릿지 회귀를 통한 보스턴 주택 가격 예측하기
라이브러리 임포트하고 출력
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso, ElasticNet
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import PolynomialFeatures
from sklearn.datasets import load_boston
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
warnings.filterwarnings("ignore")
%load_ext autotime
특징과 라벨 데이터 준비
df = pd.DataFrame(data=boston.data, columns=boston.feature_names)
df["PRICE"] = boston.target
df.head()
X = df.iloc[:,:-1]
y = df.iloc[:, -1]
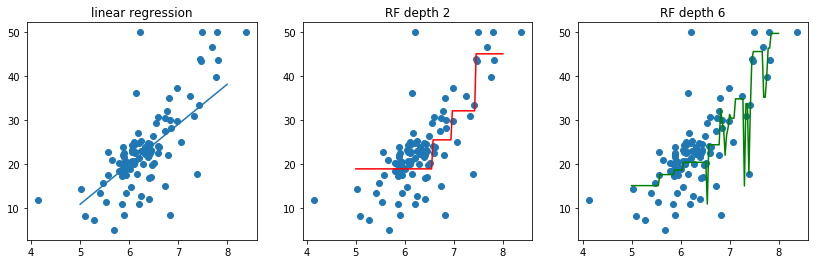
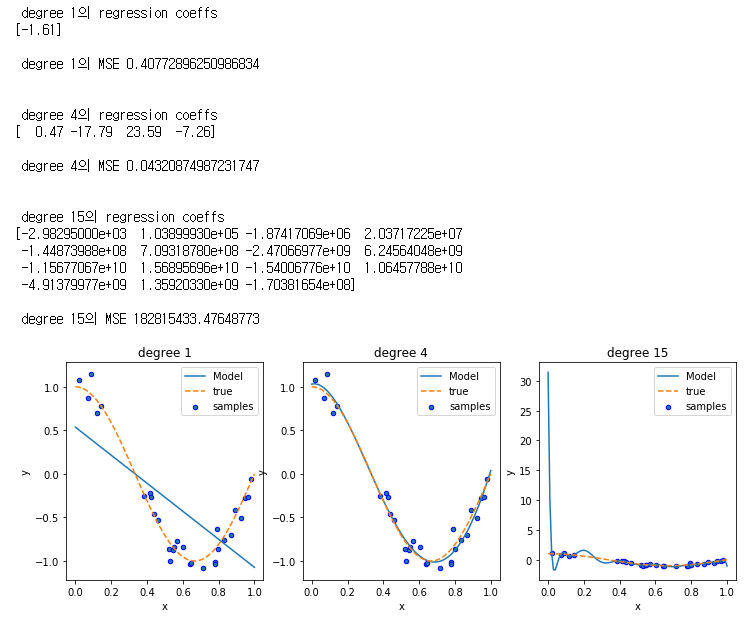
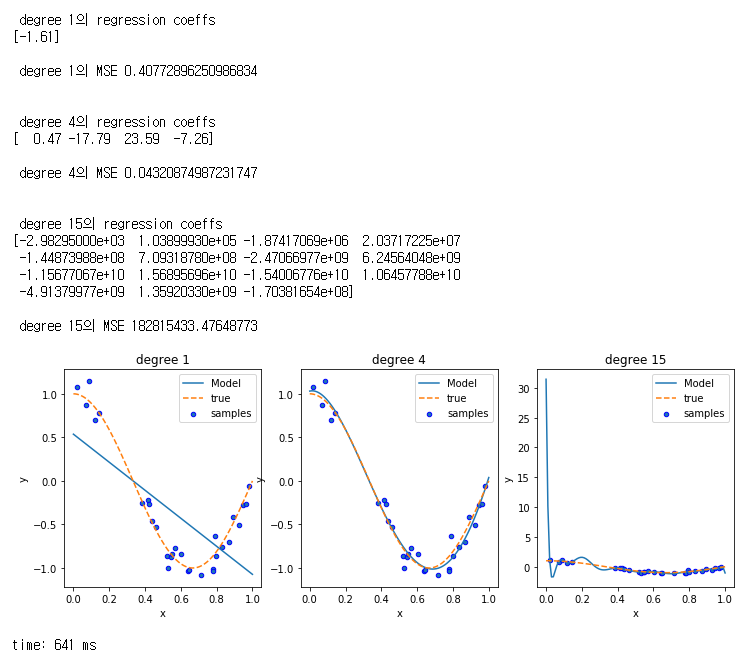
노이즈가 추가 된 cos( 1.5 * pi * x) + N(0, 0.1)으로 부터 샘플 값을 얻을때
이 때 1차 다항식, 4차 다항식, 15차 다항식의 결과를 비교해보자
우선 필요한 라이브러리들을 가져오고
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
import warnings
warnings.filterwarnings("ignore")
%load_ext autotime