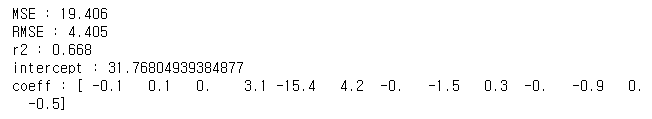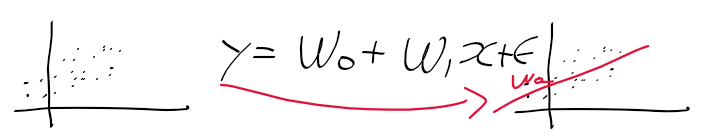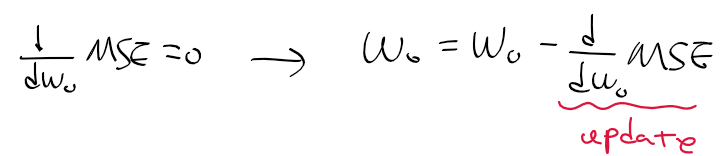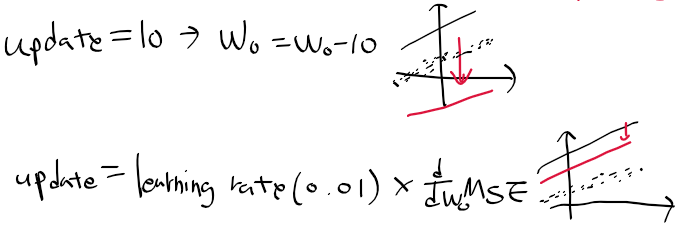- 입력 벡터(독립 변수) x와 계수 벡터(가중치 벡터) w의 선형 결합으로 종속 변수 y를 예측하는 모델
- x = [0, x1, x2, x3 ..., x_p]
- w = [w0, w1, w2, ..., x_p]
- y = w.dot(x) = w0 + w1 x1 + . . . + w_p x_p
Linear Regression
- MSE를 최소화 하는 계수 벡터로 구한 선형 회귀 모델
- 독립 변수 간의 상관 관계가 높을 수록 분산, 오류가 커짐 : 다중 공선성 multi collinearity 문제
=> 독립적이고, 중요한 변수, 피처 위주로 남기거나 규제 or PCA 수행
회귀 모델 평가 지표
- MAE Mean Absolute Error : sum(|y - y_hat|) -> 일반 오차 합
- MSE Mean Sqaured Error : sum( (y - y_hat)^2 ) -> 오차가 클수록 크게 반영됨
- RMSE Root Mean Squared Error : root(MSE) -> MSE가 과하게 커지는것을 방지
- R2 : var(y_hat) / var(y) = 예측 분산/ 실제 분산 -> 1에 가까울수록 잘 예측
회귀 모델에서 평가 지표 사용시 유의할 점
- 회귀 평가 지표들은 분류 평가 지표들과는 달리 오차의 합이므로 값이 작을 수록 오차가 작아 더 좋은 모델임
-> -1하여 음수로 만듬
- 회귀 모델 스코어링 사용 시 "neg_mean_squared_error"와 같이 앞에 "neg_"를 붙여서 명시 해야 함.
1. 라이브러리 임포트
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
from sklearn.datasets import load_boston
2. 데이터 로드
boston = load_boston()
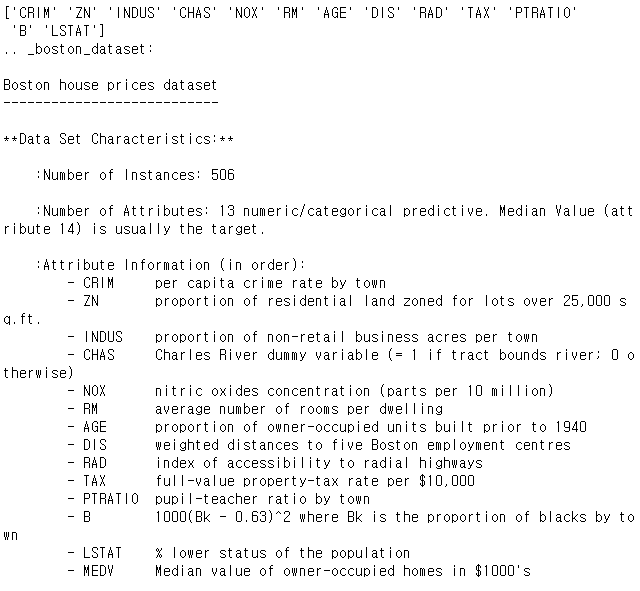
print(boston.feature_names)
print(boston.DESCR)
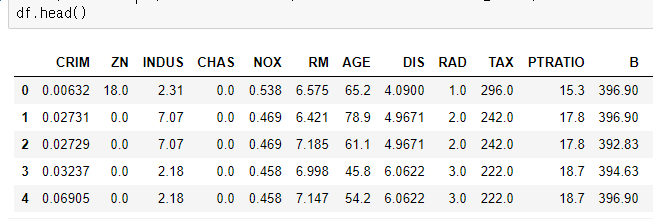
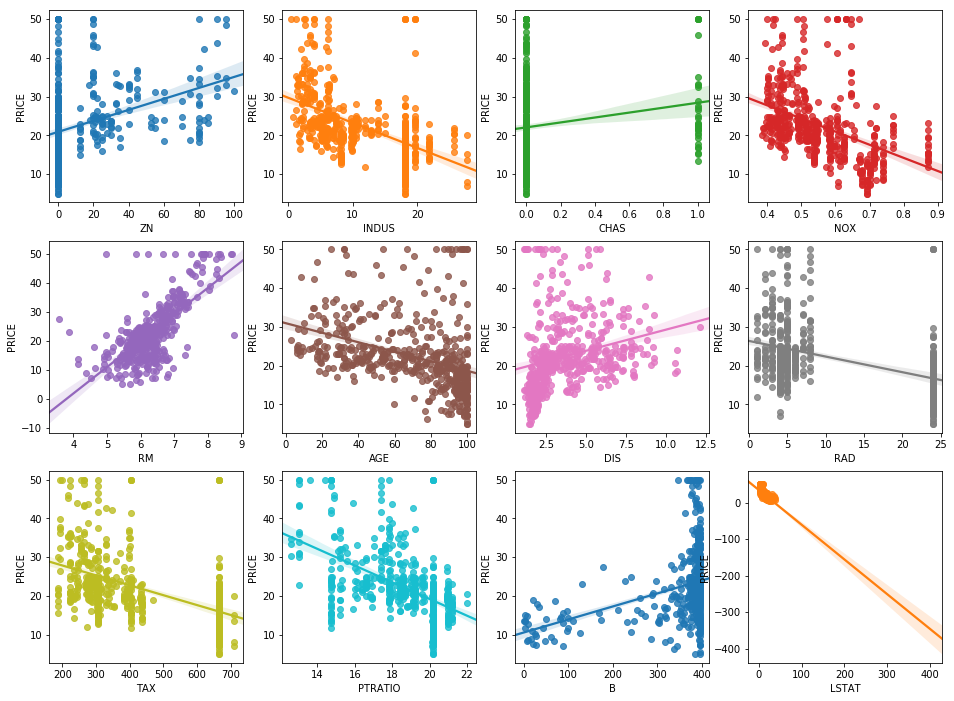
# ZN ~ LSTAT까지 각 변수들과 PRICE의 선형 관계를 sns.regplot으로 살펴보자
fix, axs = plt.subplots(figsize=(16, 12), ncols=4, nrows=3)
features = df.columns[1:-1]
for i, feature in enumerate(features):
row = int(i/4)
col = i%4
sns.regplot(x=feature, y="PRICE", data=df, ax=axs[row][col])
6. 학습 및 평가 지표 살펴보기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
y = df["PRICE"]
X = df.iloc[:,:-1]
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2)
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("MSE : {0:.3f}".format(mse))
print("RMSE : {0:.3f}".format(np.sqrt(mse)))
print("r2 : {0:.3f}".format(r2))
print("intercept : {}".format(lr.intercept_))
print("coeff : {}".format(np.round(lr.coef_,1)))
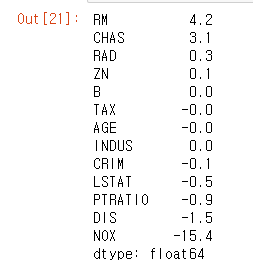
7. 피처 별 회귀 계수 살펴보기
- lr.coef_를 시리즈로 만들어 정렬 후 출력
- sns.regplot에서 본대로 RM은 강한 양의 상관 관계, LSTAT은 음의 상관관계를 가짐
- 독립 변수들과 하나의 종속 변수가 주어지고, 이에 대한 데이터들이 있을때 종속 변수를 가장 잘 추정하는 직선을 구하는 문제
- 새로운 데이터가 주어지면 학습 과정에서 구한 회귀선으로 연속적인 값을 추정할 수 있음.
- 선형 회귀 모델은 계수 벡터 beta = [beta0, . . ., beta_p], 독립 변수 벡터 x = [0, x1, ...., x_p]의 선형 결합의 형태가 됨.
- e는 오차 모형으로 기본적으로 평균 0, 분산이 1인 정규 분포를 따르고 있음.
-> 회귀 선과 추정한 y 사이의 오차를 의미함.
- 실제 종속 변수를 y, 주어진 독립변수를 통해 예측한(추정한) y를 y hat로 표기
- 오차 e는 y - y_hat으로 아래와 같은 관계를 가지고 있음.
단순 선형 회귀 모형
- 독립 변수가 1개인 선형 회귀 모형
- 아래의 좌측과 같이 2차원 공간 상에 점들이 주어질때, 우측과 같은 선형 회귀 모델을 구할 수 있음
- 기존의 회귀 계수 beta를 여기선 가중치의 의미로 w로 표기함.
- 오차 = 실제 값 - 추정 값의 관계를 가짐.
최소 제곱 오차 MSE : Mean Sqaured Error
- 실제 결과(y_i) - 추정 결과(y_i hat)의 제곱한 것을 모든 데이터에 대해 합한 후 데이터 갯수(N) 만큼 나누어 구한 오차
- 위의 산점도 데이터가 주어질떄 MSE를 최소가 되게하는 회귀 계수들로 선형 회귀 모델을 만듬
회귀 계수 구하기 기초
- MSE를 최소로 만드는 회귀 계수는 편미분을 통해 구할 수 있음.
- y = x^2라는 그래프가 주어질때, argmin(y)를 구하는 x를 얻으려면, y를 x로 편미분하여 0이 나오게하는 x를 구하면됨.
- d/dx y = 2x = 0 => x = 0일때 기울기는 0으로 y는 최소 값을 가짐
- 단순 선형 회귀 모델의 회귀 계수 구하는 방법 : MSE를 w0, w1에 편미분 한 후 0이 되도록 하는 w0, w1를 구함.
회귀 계수 구하기
- MSE를 w0, w1로 편미분하여 0이되는 w0, w1을 구하자
- n제곱 다항식의 미분에 대한 공식을 이용하여 w0, w1에 대해 편미분을 하면 아래와 같이 정리할 수 있음.
w0 회귀 계수 구하기
- 회귀 계수는 초기에 특정 값(주로 1)로 초기화 후 오차의 크기에 따라 갱신 값을 빼 조금씩 조정됨
- MSE를 w0로 편미분(갱신 값)하여 0이 되게 만드는 w0는 아래와 같이 구할 수 있음.
=> 기존의 회귀 계수(w0) - 기존 회귀 계수의 오차(갱신 값, d MSE/ d w0) = 새 회귀 계수(w0)
- 갱신 값이 너무 큰 경우, 올바른 회귀 모델을 구하기 힘들어짐
-> 학습률 learning rate를 통해 조금씩 오차를 조정해 나감.
2차원 데이터로 부터 단순 선형 회귀 모델 구하기
1. 데이터 준비
import numpy as np
import matplotlib.pyplot as plt
# y = w0 + w1 * x 단순 선형 회귀 식
# y = 4x + 6(w0 = 6, w1= 4)에 대한 선형 근사를 위해 값 준비
x = 2 * np.random.rand(100, 1) # 0 ~ 2까지 100개 임의의 점
y = 6 + 4 * x + np.random.randn(100, 1) # 4x + 6 + 정규 분포를 따르는 노이즈
plt.scatter(x, y)
2. 주어진 데이터에 적합한 회귀 모델 구하기
- 가중치(회귀 계수) 1로 초기화 -> 가중치 갱신 과정 수행(get_weight_update)
- x에 대한 추정한 y를 구함 -> 실제 y - 추정 y로 오차 diff 구함.
- 위에서 구한 가중치 갱신 공식에 따라 w0, w1의 갱신 값을 구함(w0/w1_update)
- 가중치 - 가중치 갱신 값. 이 연산을 지정한 횟수 만큼 수행
=> 회귀 계수는 일정한 값으로 수렴함 : 선형 회귀 모델의 회귀 계수.
def get_weight_update(w1, w0, x, y, learning_rate=0.01):
# y는 길이가 100인 벡터, 길이 가져옴
N = len(y)
# 계수 w0, w1 갱신 값을 계수 w0, w1 동일한 형태로 초기화
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 주어진 선형 회귀 식을 통한 값 추정
y_pred = np.dot(x, w1.T) + w0
# 잔차 y - hat_y
diff = y - y_pred
# (100, 1) 형태의 [[1, 1, ..., 1]] 행렬 생성, diff와 내적을 구하기 위함.
w0_factors = np.ones((N, 1))
# 우측의 식은 MSE를 w1과 w0에 대해 편미분을 하여 구함.
# d mse/d w0 = 0 이 되게하는 w0이 mse의 최소로 함
# d mse/d w1 = 0 이 되게하는 w1이 mse를 최소로 함
# 급격한 w0, w1 변화를 방지 하기 위해 학습률 learning_rate 사용
w1_update = -(2/N) * learning_rate * (np.dot(x.T, diff))
w0_update = -(2/N) * learning_rate * (np.dot(w0_factors.T, diff))
return w1_update, w0_update
def gradient_descent_steps(X, y, iters= 10000):
w0 = np.zeros((1, 1))
w1 = np.zeros((1, 1))
for idx in range(0, iters):
w1_update, w0_update = get_weight_update(w1, w0, X, y, learning_rate=0.01)
# 갱신 값으로 기존의 w1, w0을 조정해 나감
w1 = w1 - w1_update
w0 = w0 - w0_update
return w1, w0
def get_cost(y, y_pred):
N = len(y)
cost = np.sum(np.square(y- y_pred))/N
return cost
w1, w0 = gradient_descent_steps(x, y, iters=1000)
print("w1:{0:.4f}, w0:{0:.4f}".format(w1[0, 0], w0[0, 0]))
y_pred = w1[0, 0] * x + w0
print("gradient descent total cost : {0:.4f}".format(get_cost(y, y_pred)))
- 기본 모델로 knn, random forest, adaboost, decisiont tree 4가지
- 마지막 모델로 logistic regression
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from utils.common import show_metrics
2. 데이터 로드 및 조회
- 행 569, 열 30개 데이터
- 악성과 양성사이 큰 비율 차이는 없음
data = load_breast_cancer()
X = data.data
y = data.target
print(data.DESCR)
import pandas as pd
print(pd.Series(y).value_counts())
3. 각 분류기 학습, 성능 확인
- 각 분류기 학습 및 성능 출력, 예측 데이터 쌓기
- lr_final에 학습 용 데이터를 만들기 위해 예측 데이터 shape가 (4, 114) 인것을 전치. 114행 4열 데이터로 변환
The datasets contains transactions made by credit cards in September 2013 by european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
언더 샘플링, 오버샘플링
- 불균형 레이블 분포를 적절한 학습데이터로 만드는 방법, 오버 샘플링이 유리
- 언더 샘플링 : 클래스가 많은 데이터를 클래스가 적은 데이터 만큼 축소
ex. 정상 10,000건, 비정상 100건시 정상을 100건으로 줄임. *너무 많은 정상 데이터를 제거
- 오버 샘플링 : 클래스가 적은 데이터를 클래스가 많은 데이터 만큼 증가
* 단순 증강 시 오버피팅이 발생. 원본 데이터 피처를 약간씩 변형하여 증감
ex. SMOTE(Syntheic Minority Over sampling techinuqe : knn으로 적은 클래스 데이터 간의 차이로 새 데이터 생성
* imbalanced-learning 사용
1. 데이터로드
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
path = "./res/credit card fraud detection/creditcard.csv"
df = pd.read_csv(path)
df.head()
2. 전처리 및 훈련, 테스트 데이터 셋 분리 정의
from sklearn.model_selection import train_test_split
def get_preprocessed_df(df=None):
"""
input
df : before preprocessing
output
res : after dropping time columns
"""
res = df.copy()
res.drop("Time", axis=1, inplace=True)
return res
def get_train_test_datasets(df=None):
df_copy = get_preprocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target= df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target,
test_size=0.2,
stratify=y_target,
random_state=100)
return X_train, X_test, y_train, y_test
3. 로지스틱 회귀 모델로 성능 확인
- 정확도는 좋으나 재현률과 F1 스코어가 크게 떨어짐
X_train, X_test, y_train, y_test = get_train_test_datasets(df)
from sklearn.linear_model import LogisticRegression
from utils.common import show_metrics
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
show_metrics(y_test, y_pred)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from lightgbm import LGBMClassifier
from sklearn.model_selection import GridSearchCV
path = "./res/santander-customer-satisfaction/"
test = pd.read_csv(path+"test.csv")
train = pd.read_csv(path+"train.csv")
일단 info를 보면
총 76020개, 371개 속성
마지막 컬럼이 타겟으로 되어있다.
결측치가 존재하는지 보려고, 했으나
속성이 너무많아 잘 보이지가 않는다.
sum에 또 sum해보니 없다고 한다.
일단 타겟으로 만족여부를 살펴보자.
불만족 고객이 매우 적어보인다.
이 문제에서 대부분 고객들이 만족하므로 정확도 대신 ROC-AUC를 사용하여야한다.
train["TARGET"].value_counts()
lgbm 모델로
accuracy_score와 roc_auc_score를 살펴보았는데
roc-auc score가 많이 낮더라
데이터 전처리를 제대로 안해서 그런것같다.
from sklearn.metrics import roc_auc_score,accuracy_score
from sklearn.model_selection import train_test_split
X = train.iloc[:,:-1]
y = train.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
lgbm = LGBMClassifier()
lgbm.fit(X_train, y_train)
y_pred = lgbm.predict(X_test)
print("accuracy Score : {}".format(accuracy_score(y_test, y_pred)))
print("ROC-AUC Score : {}".format(roc_auc_score(y_test, y_pred)))
전처리 단계에서
결측치를 확인했다.
트리 모델이니 스케일링은 필요없고,
이상치 문제인것같았다.
train.describe()로 다시 살펴보았더니 일부 기술통계량이 이상한 값들이 존재한다.
var3의 경우 min인 -9999999인 데이터가 존재하는데 평균과 표준편차를 고려하면 너무 엇나간 값이다.
imp_ent_var16_ult1도 마찬가지다.
이상치를 다루는 방법은 제거하거나 이 값을 대치시켜주어야 한다.
한 변수에 이상치가 많으면 제거 대신, 평균을 구하여 넣어주곤 한다.
평균 +- 3 * std를 기준으로 이상치 갯수부터 살펴보자
var3 변수의 경우 이상치가 116개가 존재한다.
var = train["var3"]
var_mean = train["var3"].mean()
var_std = train["var3"].std()
lower_bound_idx = var < var_mean - 3* var_std
upper_bound_idx = var > var_mean + 3* var_std
print(lower_bound_idx.sum())
print(upper_bound_idx.sum())
이 외에 다른 변수들은 이상치가 몇개씩 있을까 확인해보자
mean +- 3* std를 넘어가는걸 아웃라이어로 볼때
이상치가 100개 넘어가는 변수들이 총 187개가 있다고 한다.
num_over_th = 0
num_outlier_th = 100
columns = train.columns
for col in columns:
var = train[col]
var_mean = train[col].mean()
var_std = train[col].std()
lower_bound_idx = var < var_mean - 3* var_std
upper_bound_idx = var > var_mean + 3* var_std
num_outliers = lower_bound_idx.sum() + upper_bound_idx.sum()
if num_outliers > num_outlier_th:
num_over_th += 1
print(" columns : {}".format(col))
print(" -> num of oulier : {}\n".format(num_outliers))
print("num over th : []".format(num_over_th))
- GBM Gradient Boost Machine이나, XGBoost보다 학습 시간이 적은 모델
- 데이터가 적은 경우(10000개 이하) 과적합이 발생하기 쉬움
- 기존의 트리 기반 알고리즘들은 균형 트리 분할 방식을 따르나 LightGBM은 리프위주 분할을 함.
-> 손실이 큰 리프 노드를 분할해나감. 트리구조가 비대칭적이나 손실을 최소화할수 있음.
- XGBoost와 마찬가지로 병렬 처리 수행 가능.
LightGBM 하이퍼 파라미터
- num_iteration : 디폴트 100, 반복 수행하는 트리 개수
- learning_rate : 디폴트 0.1
- max_depth : 디폴트 -1
- min_data_in_leaf : 디폴트 20, 리프노드 최소 데이터 개수
- num_leaves : 디폴트 31, 한 트리의 최대 리프개수 등
=> num_leaves를 중심으로, min_data_in_leaf, max_depth 위주로 하이퍼파라미터 조정
pip로 설치하여
유방암 데이터를 교차 검증 수행
!pip install lightgbm
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
data = load_breast_cancer()
X = data.data
y = data.target
lgbm = LGBMClassifier()
res = cross_val_score(lgbm, X, y, cv= 5, n_jobs=-1, scoring="accuracy")
print(res)
print(np.mean(res))
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
load_breast_cancer()로 유방암 관련 데이터를 읽어줍시다.
sklearn.dataset에서 load 혹은 fetch 함수로 가져온 데이터들은
sklearn.utils.Bunch 타입으로
이 데이터는 기본적으로
데이터셋에 대한 설명인 DESCR, 타겟변수명 target_names, 피처명 feature_names, data, target 등 변수들을