728x90
스캐줄링 정책 scheduling clauses
- 루프 실행에서 분배 방식을 지정
- 기본적인 스캐줄링 정책은 : 실행 횟수를 균등 분배
- 작업 균등 분배를 하기 위해서 스캐쥴링 정책을 사용
스캐줄링 정책 종류
- 정적 정책 static [, chunk_size] : 반복 실행 횟수를 스레드 마다 균일하게 할당(기본 스캐줄링 정책)
- 동적 정책 dynamic [, chunk_size] : 반복 실행 회수를 chunk_size로 나누어 chunk 생성.
먼저 작업 끝난 스레드에 다음 chunk 할당
- 안내 정책 guided [, chunk_size] : 동적 스캐줄링으로, 반복 중에 chunk의 크기가 변함
- 실행 시간 정책 runtime : 프로그램 실행중에 환경변수 OMP_SCHEDULE 값을 참조하,
재컴파일 없이 여러 스캐줄링 방식 사용
=> ex. export OMP_SCHEDULE="dynamic"
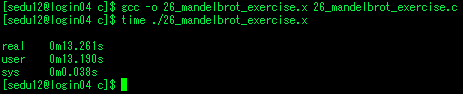
만델브로트
- 순차 프로그램
- 13.261s 소요
#include <stdio.h>
#define X_RESN 4000 /* x resolution */
#define Y_RESN 4000 /* y resolution */
#define X_MIN -2.0
#define X_MAX 2.0
#define Y_MIN -2.0
#define Y_MAX 2.0
typedef struct complextype
{
float real, imag;
} Compl;
int main ( int argc, char* argv[])
{
/* Mandlebrot variables */
int i, j, k;
Compl z, c;
float lengthsq, temp;
int maxIterations;
int res[X_RESN][Y_RESN];
maxIterations = 1000;
for(i=0; i < Y_RESN; i++) {
for(j=0; j < X_RESN; j++) {
z.real = z.imag = 0.0;
c.real = X_MIN + j * (X_MAX - X_MIN)/X_RESN;
c.imag = Y_MAX - i * (Y_MAX - Y_MIN)/Y_RESN;
k = 0;
do {
temp = z.real*z.real - z.imag*z.imag + c.real;
z.imag = 2.0*z.real*z.imag + c.imag;
z.real = temp;
lengthsq = z.real*z.real+z.imag*z.imag;
k++;
} while (lengthsq < 4.0 && k < maxIterations);
if (k >= maxIterations) res[i][j] = 0;
else res[i][j] = 1;
}
}
}
- 정적 병렬 프로그램
-> 1.305s 소요
#include <stdio.h>
#define X_RESN 4000 /* x resolution */
#define Y_RESN 4000 /* y resolution */
#define X_MIN -2.0
#define X_MAX 2.0
#define Y_MIN -2.0
#define Y_MAX 2.0
typedef struct complextype
{
float real, imag;
} Compl;
int main ( int argc, char* argv[])
{
/* Mandlebrot variables */
int i, j, k;
Compl z, c;
float lengthsq, temp;
int maxIterations;
int res[X_RESN][Y_RESN];
maxIterations = 1000;
#pragma omp parallel for shared(res,maxIterations) private(i,j,z,c,k,temp,lengthsq) schedule(static)
for(i=0; i < Y_RESN; i++)
for(j=0; j < X_RESN; j++) {
z.real = z.imag = 0.0;
c.real = X_MIN + j * (X_MAX - X_MIN)/X_RESN;
c.imag = Y_MAX - i * (Y_MAX - Y_MIN)/Y_RESN;
k = 0;
do {
temp = z.real*z.real - z.imag*z.imag + c.real;
z.imag = 2.0*z.real*z.imag + c.imag;
z.real = temp;
lengthsq = z.real*z.real+z.imag*z.imag;
k++;
} while (lengthsq < 4.0 && k < maxIterations);
if (k >= maxIterations) res[i][j] = 0;
else res[i][j] = 1;
}
}

- 병렬 프로그래밍 동적
-> 0.507s 소요
#include <stdio.h>
#define X_RESN 4000 /* x resolution */
#define Y_RESN 8000 /* y resolution */
#define X_MIN -2.0
#define X_MAX 2.0
#define Y_MIN -2.0
#define Y_MAX 2.0
typedef struct complextype
{
float real, imag;
} Compl;
int main ( int argc, char* argv[])
{
/* Mandlebrot variables */
int i, j, k;
Compl z, c;
float lengthsq, temp;
int maxIterations;
int res[X_RESN][Y_RESN];
maxIterations = 1000;
#pragma omp parallel for shared(res,maxIterations) private(i,j,z,c,k,temp,lengthsq) schedule(dynamic,5)
for(i=0; i < X_RESN; i++)
for(j=0; j < Y_RESN; j++) {
z.real = z.imag = 0.0;
c.real = X_MIN + j * (X_MAX - X_MIN)/X_RESN;
c.imag = Y_MAX - i * (Y_MAX - Y_MIN)/Y_RESN;
k = 0;
do {
temp = z.real*z.real - z.imag*z.imag + c.real;
z.imag = 2.0*z.real*z.imag + c.imag;
z.real = temp;
lengthsq = z.real*z.real+z.imag*z.imag;
k++;
} while (lengthsq < 4.0 && k < maxIterations);
if (k >= maxIterations) res[i][j] = 0;
else res[i][j] = 1;
}
}

300x250
'컴퓨터과학 > 기타' 카테고리의 다른 글
| openmp - 25. 테스크 데이터 유효범위와 피보나치 (0) | 2020.07.30 |
|---|---|
| openmp - 24. 테스크 (0) | 2020.07.30 |
| openmp - 22. ordered, lock (0) | 2020.07.30 |
| openmp - 21. nowait (0) | 2020.07.30 |
| openmp - 20. 작업 분할 지시어들 (0) | 2020.07.30 |