용어
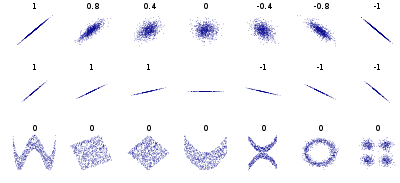
- 기댓값 expectation : 확률 변수 평균. 중심의미의 지표
- 분산 variance : 확률 변수의 변동성. 즉 흩어진 정도를 나타냄
- 표준 편차 standard deviation : 분산을 제곱근하여 확률 변수와 같은 단위로 표준화한것
기댓값
- 확률 분포의 중심
- 확률 변수 기댓값을 모집단 평균 \mu로 표기
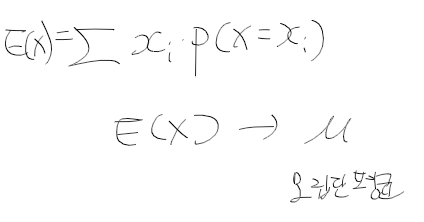
기댓값 구하기- 복권

주사위 기댓값

연속 확률 변수/ 이산 확률 변수의 기댓값

연속 확률 변수 기대값 계산 예시

분산
- 확률 변수 값들이 기댓값을 중심으로 퍼져있는정도로 \sigma^2


표준편차 standard deviation
- 분산을 제곱근하여 구함

동전을 한번 던져서 나오는 확률에 대한 분산과 표준 편차를 구하시오

주사위 눈금 변수와 분산의 표준 편차

연속 확률 변수의 분산과 표준편차를 구하라

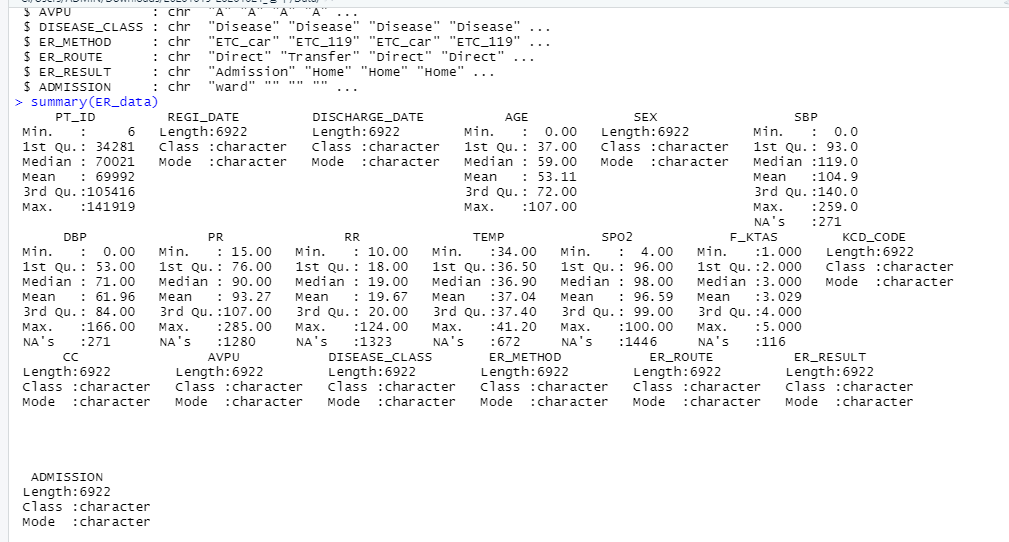
이산 확률 분포
- 이산 균일 분포 : 이산 확률 변수 모든 값의 확률이 같은 확률 분포. ex : 동전 던지기, 주사위 던지기
- 초기하 분포 : 2개의 군으로 구성된 모집단에서 표본을 비복원 추출시 분포. ex 불량품 갯수
- 베르누이 분포 : 한 실험이 두 배반사건으로 구분될떄 사건 발생 여부에 대한 확률 분포
이산확률 변수
- 셀수있는 값인 확률 변수
- 주사위 눈, 앞/뒤, 불량품 개수
<-> 연속형
- 이산 확률 분포 : 이산 균등분포, 초기하 분포, 이항 분포, 포아송 분포
이산 균일 분포

초기하분포
- 모집단에서 표본을 비복원 추출하는 분포
-> 불량여부, 공색깔, 실패여부

- 모집단 크기 N, 표본 갯수 n, 불량 수 D 인 경우 불량품 갯수에 대한 확률 분포

초기하 분포 예제

베르누이 시행
- 실험이 두가지 서로배반인 사건 뿐일때 시행
-> 동전 앞면 뒷면, 성공/실패, 합격/불합격
베르누이 분포

이항 분포
- 베르누이 분포를 따르는 시행이 독립적으로 이루어졌을때 성공 횟수에 대한 분포

이항분포와 초기하 분포의 관게
- 초기하 분포에서 표본수가 커질수록 이항분포로 근사화됨
- 비복원 추출을 하면 초기화 분포, 복원하면 이항분포.
포아송 분포
- 이항 분포의 특이한 경우. 일정 기간동안 희귀하게 발생하는 사건 건수의 분포
- 발생 가능성 p은 매우 작으나 시행 횟수 n이 굉장히 큰 경우에 대한 확률 분포
ex. 교통사고 사망자, 희귀질병 사망자 등


'수학 > 통계' 카테고리의 다른 글
| 데이터분석 - 12. 확률기초 3 (0) | 2020.10.22 |
|---|---|
| 데이터분석 - 11. 확률기초 2 (0) | 2020.10.21 |
| 데이터분석 - 10. 다양한 분석 방법과 검정 (0) | 2020.10.21 |
| 데이터분석 - 9. 회귀모형 (0) | 2020.10.21 |
| 데이터분석 - 8. 베이즈 이론 (0) | 2020.10.20 |