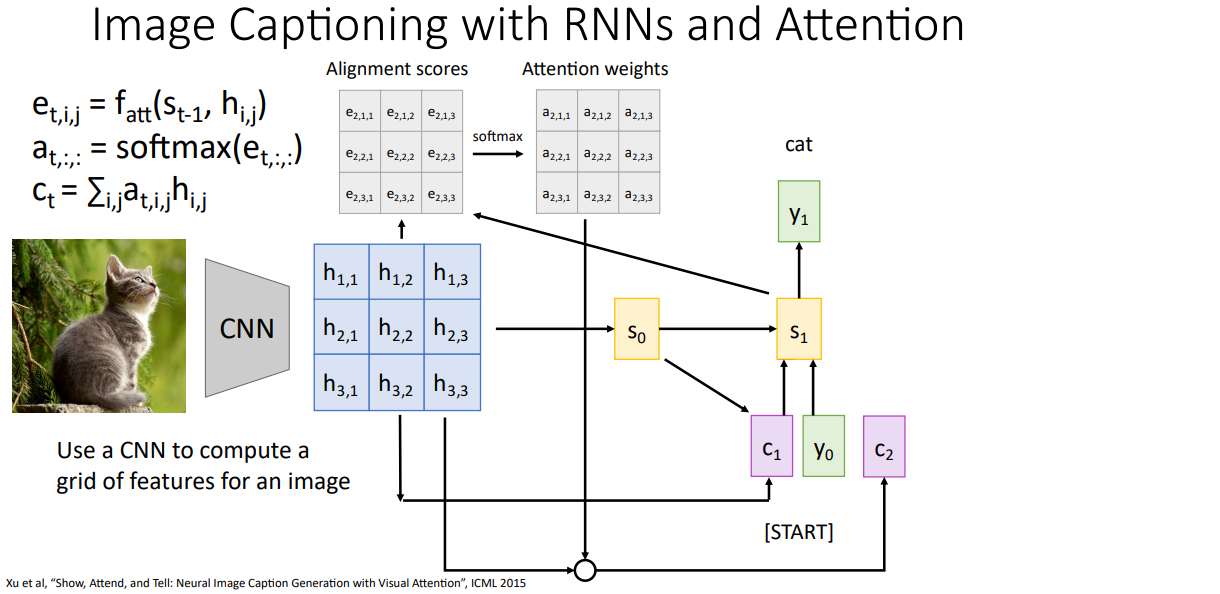
이 슬라이드 왼편을 보면 고양이 이미지를 입력으로 받는다고 하고, 합성곱 신경망을 돌려보겠습니다. 그러면 이 합성곱 신경망의 마지막 합성층의 출력을 격자로 된 특징 백터로 볼수 있습니다. 그러면 다음 이미지도 격자로된 특징 벡터를 얻을수가 있으며 각 격자 특징 벡터들은 이미지의 공간적 위치에 해당한다고 볼수 있겠습니다.
-> 격자 특징 벡터 하나 하나는 이미지의 어느 위치에 대한 특징 계산 결과임.
다음으로 할일은 시퀀스 모델에서 했던것 처럼 어텐션 매커니점을 적용시켜볼건데, 은닉 상태로 그리드 벡터를 사용해서 디코더의 초기 은닉 상태 s0를 추정하겠습니다. 그러면 이제 디코더는 초기 은닉 상태 s0를 비교함수 f_att로 격자 특징의 모든 위치와 초기 은닉 상태 s0 사이의 쌍 배정 스코어 pairwise alignment score를 계산하는데 사용하겠습니다.
모든 출력 결과는 스칼라 값이 나올것이고, 이 값은 해당 벡터 부분을 크게 중요하게 본다면 크고, 해당 벡터 부분을 덜 중요하게 본다면 낮은 값을 가지게 됩니다. 이런식으로 격자/그리드 배정 스코어를 얻을수가 있어요. 그래서 배정 스코어에 대한 그리드의 각 원소는 다시말하면 하나 하나가 f_att로 구한 스칼라값이 되겠습니다.
그래서 이렇게 격자 어텐션 스코어를 구하였으면 이들을 확률 분포로 정규화해주기위해 소프트 맥스 함수를 사용하겠습니다. 이 결과는 출력 캡션의 첫번째 단어를 만들어낼 때 입력 이미지의 모든 위치에서 모델이 어느 부분에 집중을하였는지를 확률 분포로 나타내게 됩니다.
그러면 이제 가중화된 은닉 벡터를 사용할건데, 어텐션 확률 스코어와 격자 벡터를 선형 결합을 시켜서 구할수가 있고 이 값이 첫번째 컨텍스트벡터 c1이 되겠습니다.
이 컨텍스트벡터는 출력 시퀀스의 첫번째 토큰을 만드는데 사용할것이며, rnn 디코더 1층을 지나가면서 첫번째 단어로 cat을 만들어 냅니다.
이제 다음으로 넘어가서 이 과정을 다시 반복하겠습니다.
이번에는 (디코더의) 다음 은닉 상태인 s1을 격자 특징의 모든 지점과 비교하는데 사용해서 새 배정 스코어 격자를 만들어내고,
소프트맥스로 정규화시켜 이미지 전체 위치에 대한 확률 분포를 만들어 냅니다.
그러면 이것으로 디코더의 두번째 타임스탭에서 사용할수 있는 새 컨텍스트 벡터를 구할수가 있겠고,
이걸로 다음 단어를 만드는데 사용하겠습니다.
이미지에 있는 내용들을 계속 순방향으로 정리해가면서 캡션 "cat sitting outside <stop>"을 만들어 냅니다. 지금 본 이 구조는 시퀀스 투 시퀀스로 번역했을때 경우와 매우 비슷한 구조인걸 알수 있습니다. 그래서 이 덕분에 모델이 입력 이미지의 격자 특징을 가중치를 주며 재조합을하여 새 컨텍스트백터를 생성할수 있게 만들었습니다.
한번 이 새 이미지에 대해서 한번 고민해보면, 이 모델은 새 이미지를 입력으로 받고 있고 출력으로 단어 시퀀스 "a bird is flying over a body of water"를 만들어 내고 있다.
출력 시퀀스를 만들어내는 모든 타임 스탭에서 모델은 어텐션 가중치들을 추정하며, 합성곱 신경망으로 입력 이미지를 처리하여 얻은 격자 특징의 위치들에 대한 확률 분포를 알려준다.
모델이 "bird flying"이란 단어를 추정해낼때 모델은 입력 이미지에서 새에 집중하고 있으며, "water"라는 단어를 추정할때는 어텐션 가중치가 새를 제외한 나머지 부분들 수면에 집중하는걸 볼수 있겠습니다.
왜 이런 매커니즘을 이미지 캡셔닝에서 사용해야하는지를 정리하자면 생물학적으로 생각해보면 좋겠는데, 왼쪽의 사람 눈 그림을 보자. 사람의 눈은 원형이고, 한쪽 면에는 빛이 들어올 수 있는 렌즈가 있고, 렌즈를 통해서 들어온다. 눈의 뒤에는 망막이라고 부르는 영역이 있는데, 렌즈를 통해 들어온 빛이 망막에 맺히게 된다. 망막은 광각 세포? photosensitive cells를 가지고 있는데 여기서 빛을 감지하여, 광각 세포로 얻은 신호는 두뇌로 보내져서 우리가 보고 있는 것을 해석/보여준다.
그런데 밝혀진 사실은 망막은 모든 부분들이 신호를 동등하개 만들어내지 않고, 특히 망막의 중간에 있는 포비아 phobia라고 부르는 영역이 망막의 다른 부분보다 가장 민감합니다.
이 오른쪽 그래프에서 말하고자 하는것은 그래프의 y축은 시각적 활성, x축은 망막의 위치를 나타내는데, 멀리 있는 것일수록 시각 활성이 낮고, 포비아에 가까워질수록 시각활성이 증가하게 되다가, 포비아에서 가장 활성되었다가 다시 멀어지고 망막 끝에 다가가면서 내려가 시각 활성이 매우 작아지게 됩니다.
이것이 의미하는것은 눈에서 아주 좁은 영역에서만 고해상도로 세상을 볼수 있다는 것이고, 손을 우리 바로 앞에 놓으면 자세히 볼수 있지만 옆면으로 이동시키면, 옆에 뭔가 있다고 말할수는 있지만 정확히 그게 뭔지, 손가락이 몇 개인지 새어보기도 어렵게 됩니다. 이는 망막의 위치별로 서로 다른 민감도를 가졌기 때문입니다.
사람의 망막 구조로 인한 이 문제에 대처하기 위해서, 우리의 눈은 매우 빠르게 움직이고 있으며 어떤 물체를 정상적으로 보고 있는것처럼 느껴지더라도, 계속 움직이면서 여러 시각적 장면들을 가져옵니다. 이러한 눈의 매우 빠른 동작을 psychotics라고 부릅니다. 이들은 의식적으로되는 행동이 아니라 망막의 아주 일부만 민감한 문제를 극복하기 위해서 몸이 기본적으로 하는 메커니즘이 되겠습니다.
이번에 rnn을 이용한 이미지 캡셔닝같은 경우는 사람의 빠른 눈동작의 효과가 적은 방법이지만 무언가를 볼때 그 장면의 다양한 부분들을 보게되는걸 알고 있는것 처럼, 비슷하게 어텐션을 이용한 이미지 캡셔닝 모델을 사용할때도 매 타임 스탭마다 빠르게 다양한 위치들을 훑어보게 됩니다. 이는 사람의 눈이 하는 약간의 정신적인 동작같은 거에요.
이 아이디어가 처음으로 소개된 논문에서는 show, attend, tell이라고 부르고 있는데 이 이유는 모델은 입력 이미지를 받고, 이미지의 여러 부분들에 집중해서, 그 시점에 무엇을보았는지 단어를 생성하였기 때문입니다. 이 논문 제목이 워낙 기억하기 쉽다보니 다른 사람들도 어텐션을 다른 방향으로 사용한 모델에 대해서 이런 식으로 제목을 짓기 시작하였습니다.
ask, attend, answer나 show, ask, attend, and answer 같은 경우에 어떤 걸 연구했는지 알수 있겠죠. 이런 모델들은 이미지를 보고, 이미지에 대한 질문이 주어질때, 이미지의 여러 부분에 집중하거나 혹은 질문의 다른 부분에 집중해서, 그 질문에 대해서 대답하는 식이겠습니다.
"Listen, attend, and spell"의 경우 음성을 처리해서 이 소리가 어떤 단어를 발음한것인지 만들어낼것인데, 매 타임 스탭마다 단어를 만들어낼때 입력 오디오 파일의 어느 부분에 집중을 하는 식이겠습니다.
이번에는 13번째 강의를 할 차례가 되었습니다. 이번 시간에는 어텐션 Attention에 대해서 다루게 될건데 "집중하세요" pay attention 같은 엉터리 조크는 하지 않을게요. 지난 번 중간 고사 이전에 순환 신경망에 대해서 다뤘습니다.
한번 다시 떠올려보면 순환 신경망은 다른 작업을 가능하도록 만든 다양한 벡터 시퀀스들을 처리 할수 있는 유용한 구조인걸 배웠습니다.
우선 순전파 신경망 feed forwad neural network에서 시작해서 순환 신경망 recurrent neural network로 고치면서 풀수 있는 다양한 문제들을 살펴보았는데, 예시로 기계 번역에 대해서 봤었습니다. 이 기계번역의 경우 한 시퀀스를 다른 시퀀스로 바꾸는 문제였어요. 다른 예시로는 이미지 캡셔닝이 있었는데, 입력 이미지가 주어질때 그에 대한 단어들의 시퀀스를 예측하는 문제였습니다.
이번 시간에는 지난 시간 배운 순환 시긴경망에 대해서 하나하나 짚어보면서 어탠션에 대해서 다뤄보겠습니다.
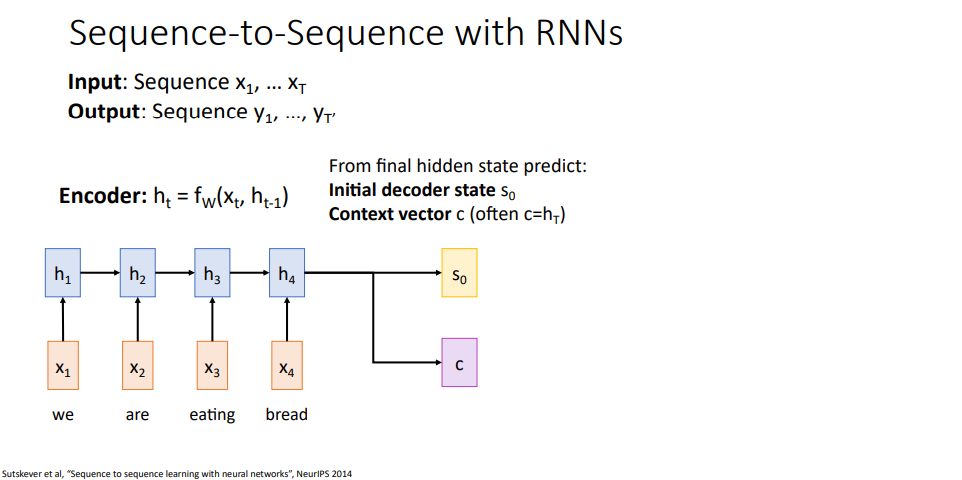
일단 순환 신경망에서 시퀀스 투 시퀀스 문제로 돌아가서 다시 살펴봅시다. 이 과정에서는 입력 시퀀스들 그러니까 x1에서 xt까지 받는데, 이걸 가지고 y1에서 yt까지의 출력 시퀀스를 만들게 됩니다. 여기서 x들은 영어 문장의 단어 하나하나라 볼수 있겠고, y들은 스패인어 문장에서 그에 해당하는 단어들이라고 할수 있겠습니다.
그래서 우리가 하고자 하는건 한 언어로 된 문장의 단어들을 다른 언어의 문장으로 변환을 시키는것이 되겠습니다. 다른 언어들은 서로 다른 개념들을 사용하다보니 두 시퀀스의 길이는 다를수 있습니다. 그래서 입력 시퀀스 x의 길이를 t, 출력 시퀀스 y의 길이를 t'으로 나타낼게요.
지난 강의때 순환 신경망 아키텍처로 시퀀스 투 시퀀스 모델에 대해서 다뤄보면서 이 아키텍처는 번역 문제에서 사용할수 있다고 했었습니다. 이게 동작하는 과정을 다시 떠올려보면 인코더라고 부르는 순환 신경망이 있었는데, 인코더는 벡터 x들을 받아서 은닉 상태들의 시퀀스 h1 ~ ht를 만들어 냅니다.
매 타임 스탭마다 순환 신경망에 대한 수식/함수 fw로 이전의 은닉 상태와 현재 입력 벡터 xi를 받아가지고 현재 은닉 상태를 만들어 냈습니다. 이 과정을 순환 신경망이 전체 입력 벡터 시퀀스에다가 적용시킬수가 있었습니다.
여길 보면 어떻게 동작하는지 조금 더 자세한 사항내용들을 볼수 있겠는데, 입력 벡터를 처리하고 나서 전체 입력 시퀀스 내용들을 두 벡터로 정리하고자 한다고 합시다. 디코더, 출력 문장을 만들어냄,라고 부르는 다른 순환 신경망을 쓸거다보니 입력 문장을 두 백터로 정리할수 있어야 해요.
이들 중 하나는 디코더의 초기 은닉 상태 initial hidden state로 이 그림 상에서는 s0로 표기되고 있습니다. 그리고 컨텍스트 벡터 c를 계산해야해요. 이 벡터 c는 디코더의 매 타임스탭마다 흘러/통과하겠습니다. 가장 일반적으로 구현시 컨텍스트 벡터는 최종 은닉 상태를 사용하고, 초기 은닉 상태를 가장 흔하게 선정하는 방법은 순전파 계층이나 완전연결 계층 같은 것으로 예측한 결과를 사용합니다.
-> 인코더는 디코더에서 사용할 벡터 2개를 만들어낸다. 초기 (디코더) 은닉 상태 벡터와 컨텍스트 벡터
-> 컨텍스트 벡터는 디코더의 모든 타임 스탭에서 사용되며, 인코더의 최종 은닉 상태가 주로 사용된다.
-> 초기 (디코더) 은닉 상태는 인코더의 최종 은닉 상태로부터 예측한 결과를 사용한다.
이제 디코더를 다뤄보면 디코더가 하는일은 어느 입력 시작 토큰을 받아서 출력 시퀀스를 만들어 나가게 됩니다. 첫 타임 스탭 디코더의 출력을 구하기 위해서는 초기 은닉 상태 s0과 컨텍스트 벡터 c 그리고 시작 토큰 y0을 입력받아서 출력 문장의 첫번째 단어가 만들어 집니다.
시간에 따라 계속 반복할건데, 디코더의 두번째 타임 스텝에서는 이전 타임 스탭의 은닉 상태 s1와 문장의 첫번째 단어 "estamos" 그리고 컨텍스트 벡터 c를 받아서 동작하고,
여러 타임스탭을 진행하면서 입력 문장을 번역해서 "we are eating bread"가 스패인 번역기를 통해서 바뀌어지겠다. 이 구조에서 살펴봐야할 부분은 분홍색 상자의 컨텍스트 백터를 사용하고 있다는 점인데, 이 벡터는 인코딩 시퀀스와 디코딩 시퀀스 사이에서 정보를 전달하기 위한 목적으로 사용한다.
이 컨텍스트 벡터는 디코더가 문장을 만들어내는데 필요한 모든 정보를 요약한 것이며, 이 컨택스트 백터는 디코더의 모든 타임 스탭에서 사용된다. 이 아키텍처는 꽤 합리적이기는 하지만 문제점을 가지고 있다.
이렇게 만든 아키텍처는 짧은 문장을 다루는 경우에 잘 동작할거고, 슬라이드의 예시와 같이 약간 긴 경우에도 잘 동작할것이다. 하지만 실제로 아주 긴 문장을 다루는 sequence to sequence 아키텍처를 사용한다고 할때, 짧은 문장을 번역하는게 아니라 책의 전체 문단을 번역하고자 하는 경우 문제가 발생할 수 있다.
여기서 발생하는 문제는 입력 문장, 입력 텍스트에대한 전체 정보가 하나의 컨텍스트 벡터 c로 병목화/압축해서 나타내려하기 때문인데, 벡터 하나를 가지고 짧은 문장 전체를 표현하는건 괜찬겠지만 텍스트북의 문단 전체를 하나의 컨텍스트 벡터 c로 요약하는건 어렵기 때문이다.
이 문제를 극복하기위해서 모든 정보를 하나의 벡터 c에다가 다 집적? 요약시키기지 않는 매커니즘을 찾고자했으며, 간단한 해결책으로 하나의 컨텍스트 벡터 c로 정리하는게 아니라
디코더의 모든 타임 스탭마다 새로운 컨텍스트 백터를 계산해 내는데, 이 새 컨텍스트 벡터는 디코더의 모든 타임 스탭에서 입력 시퀀스의 어느 부분에 집중을 할 건지 선택할수 있게 만들어 준다.
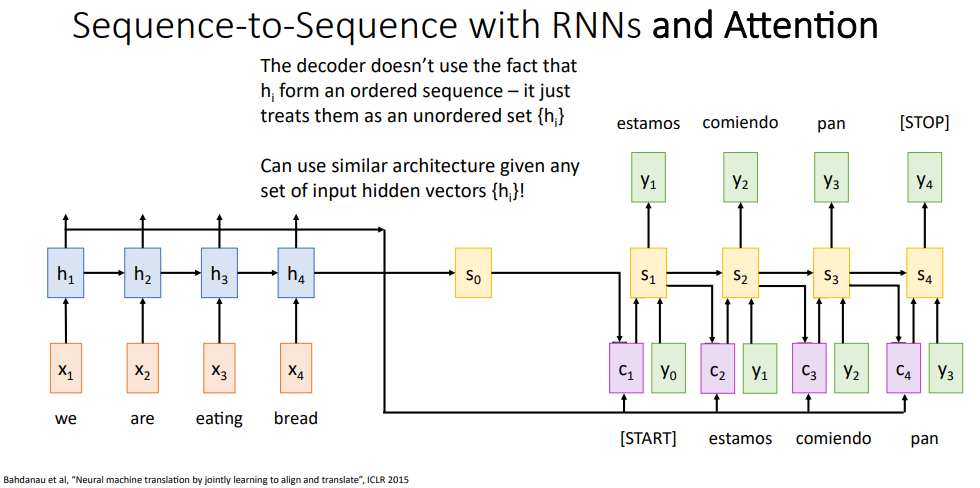
이 좋은 방법을 정리하였고, 어텐션 attention이라 부른다. 이 슬라이드를 보면 여전히 시퀀스 투 시퀀스 순환 신경망을 사용하고 있으며, 입력 시퀀스를 인코딩해서 은닉 상태 시퀀스를 만들어내는 인코더를 가지고 있고, 매 시간마다 출력을 만들어내는 디코더를 사용할건데 차이점이라면 이 신경망에다가 어텐션 매커니즘을 추가시키겠다.
어탠션 매커니즘은 디코더의 매 타임 스탭마다 새로운 컨텍스트 백터를 계산해내는데, 어떻게 되는지보자면 인코더는 그대로라 입력 시퀀스에 대한 은닉 상태 시퀀스들을 만들고, 디코더에서 사용할 초기 은닉 상태을 추정한다.
하지만 이전에 본 시퀀스 투 시퀀스 아키택처와 차이점을 볼수 있는데, 우측 상단에 배정 함수 alignment function (의미를 생각하면 위치를 배치한다?는 의미에서 배치가 맞을것같긴한데 이전에 본 배치와 햇갈리지 않게 그냥 위치를 배정한다는 의미에서 배정 함수라 하였다.)를 작성하였다. 이 배정 함수는 매개변수를 받는 완전 연결 신경망으로 작은 완전 연결 신경망이라 생각하면 되겠다.
그래서 이 신경망은 두 벡터를 입력으로 받는데, 하나는 디코더의 현재 은닉 상태와, 다른 하나는 인코더의 은닉 상태들 중 하나를 받는다. 그러면 이 배정 함수는 디코더의 현재 은닉 상태가 주어졌을때 인코더의 각 은닉 상태들 중에서 얼마나 주의를 기울이냐, 다시말하면 디코더의 현재 은닉 상태가 인코더의 각 은닉 상태들 중에서 얼마나 가까운가 집중하는가에 대한 스코어를 출력시키게 된다.
그래서 디코더의 매 타임스탭마다 새 컨텍스트 백터를 만들기 위해서 이 정보들을 사용할건데, 구체적으로 보자면 디코더의 맨 첫번째 타임 스탭에서 디코더 초기 은닉 상태 s0를 가지고 있겠다. 여기서 f_att 함수를 사용하여 s0와 h1이 주어질때 다른 값들이랑 비교하기위해서 일단 배정 함수 스코어로 e_11을 구하였다.
이 배정함수 스코어는 은닉 상태 h1가 출력 은닉 상태 s0 뒤에 어떤 단어가 올지 예측하는데 얼마나 필요하는가를 나타내며, 스칼라값 e_11이 출력으로 나오게 된다. 그래서 스칼라값인 e_12는 디코더의 첫번째 은닉 상태를 가지고 단어를 예측할때 h2를 얼마나 사용되는가로 볼수 있겠다.
그리고 이 배정 함수를 디코더의 한 은닉 상태가 주어질때 인코더의 모든 은닉상태에다가 돌려서, 인코더의 모든 은닉 상태에 대한 배정점수를 얻을수 있었다. 하지만 이 배정 스코어들은 순전파 신경망 f_att로부터 얻은것이다보니 실수값이고,
다은 단계에서 할일은 소프트 맥스 연산을 수행해서 이 배정 점수들을 확률 분포로 만들어 주겠다. 이 솦프트맥스 함수는 이전에 이미지 분류때 봤던것과 동일한 것으로 스코어들로 이뤄진 벡터를 입력으로 받아서 확률 분포를 출력하게되는데, 가장 큰 스코어는 가장 큰 확률값이 될것이고 각 출력된 값들은 0에서 1사이의 실수 값이 되며 이들을 모두 합하면 1이 된다.
그래서 우리는 디코더의 첫번쨰 은닉 상태에 대한 확률 분포를 예측했고, 이 확률 분포는 인코더의 각 은닉 상태들 중에서 얼마나 가중을 줄지를 알려주다보니 이들을 어탠션 가중치 attention weights라고 부른다.
다음에 할일은 얼핏보면 어려워보이지만, 은닉 상태 각각에대한 가중합을 가져와서 사용하겠다. 이들을 예측된 확률 스코어 만큼 가중을 줘서 더하여, 디코더의 첫번째 타임스탭에서 사용할 컨텍스트벡터 c1을 만든다.
이게 의미하는건 입력 시퀀스에대한 (인코더의)각 은닉 상태들을 얼마나 가중치를줘서 반영시킬지를 예측해서 디코더의 모든 타임스탭마다 동적으로 가중치를 변화시키면서 디코더의 매 타임 스탭마다 다른 컨텍스트 백터를 구할수가 있겠다.
그러면 이제 디코더의 첫 타임 스탭을 동작시킬수가 있겠고, 이 디코더 신경망은 방금 막 계산한 컨텍스트 벡터와 (이 슬라이드에는 빠트렸지만) <start> 토큰을 입력으로 받아서 문장에서 첫번째 예측되는 단어를 출력한다.
정리를하자면 문장의 각 단어들을 생성시키고자 할때, 출력 문장의 각 단어는 입력 문장의 하나 혹은 여러개의 단어에 대응된다. 그래서 디코더 신경망이 입력의 한 부분에 집중할수 있도록 해주는 컨텍스트 백터를 매 타임 스탭마다 동적으로 만들어낸게 되겠다.
그래서 여기서 보는 예시는 "we are eating bread"라고 하는 특정한 문장을 번역하는것으로 첫번째 단어 "estamos"는 스페인어로 "we are doing somthing"이란 뜻을 가지고 있다. 영어문장에서 첫, 두 단어에 가중을 두고 나머지 두 단어에는 가중치를 적게 준다면, 디코더 신경망이 단어들을 만드는데 입력 시퀀스에서 중요한 부분에 집중할수 있게 된다.
다른 중요한 점으로 이 모든 연산들은 미분 가능한것들이며, 우리가 신경망한태 디코더의 매 타임스탭마다 어디에 집중하라고 알려주기보다는 신경망이 스스로 어디를 집중해서 보도록 만들었다.
지금 보고 있는 계산 그래프의 모든 연산들은 미분가능하다보니 우리가 따로 지시하거나 신경망에게 어딜 보라고 할 필요없이, 이런 큰 연산을 하나의 계산그래프를 만들고 신경망의 모든 파츠들을 역전파를 통해서 최적화 시키면 되겠다.
다음 타임 스탭에서 이 과정을 반복해서, 디코더의 새 은닉상태 s1을 가져와서 이 은닉상태와 입력 시퀀스의 각 은닉 상태를 비교해서 새로운 배정 스코어 e21, e22, ... 등 시퀀스를 만들어낸다.
그리고 소프트맥스를 적용해서 입력 시퀀스에 대한 확률 분포들을 구해내고, 이 확률 분포는 출력 시퀀스에서 두 번째 단어를 만들어낼때 입력 시퀀스의 어떤 단어에 집중을 할것인가를 알려주며, 이 추정 확률로 입력 시퀀스의 은닉 상태에대해 가중 합으로 새 컨텍스트백터를 만들어내겠다.
이전의 과정을 다시 반복해서, 두번쨰 컨택스트 벡터와 첫 번째 단어, 이전 은닉 상태로 두 두번째 은닉 상태를 계산한뒤 두번쨰 단어를 생성해내겠다.
정리하자면 무언가를 먹다는 걸 의미하는 두번째 단어 "comiendo"가 생성된 것은 모델이 "eating"의 타임 스탭에 가중치를더 줘서 집중했으며, "we"나 "bread"같은 단어는 생성시키는게 적정하지 않은것으로 보고 무시했다고 할수 있겠습니다.
다시말하지만 이 모델은 미분가능해서 학습시킨것으로 우리가 모델에거 어떤 단어, 부분이 집중하라고 알려줬기보다는 모델이 출력 시퀀스를 생성할때 어떤 부분을 집중할지 학습한 것입니다.
그래서 이제 여러 타임 스탭으로 풀어나가서 이와 같이 어탠션으로 학습한 시퀀스 투 시퀀스 예시를 볼수 있겠습니다. 이 방법을 통해서 바닐라 시퀀스 투 시퀀스 모델이 가지고 있던 문제를 극복할수가 있었습니다.
왜냐면 이건 입력 시퀀스에 대한 전체 정보를 하나의 단일 벡터에 넣어서, 그 한 벡터를가지고 디코더의 모든 타임스탭에다가 반영시킨것이아니라 디코더에게 각 타임스탭마다 새로운 컨텍스트백터를 생성해서 줬거든요. 그래서 다시 정리하자면 우리가 아주 엄청 엄청 긴 시퀀스를 다루더라도 모델이 디코더의 각 출력때마다 입력 시퀀스에서 주의를 집중할 부분을 이동/바꿀수있게 되었습니다.
우리가 지금까지 기본적으로한것은 순환 신경망 모델인 시퀀스 투 시퀀스를 학습시켰고, 이 모델은 영어로된 단어들의 시퀀스를 입력받아 프랑스어 단어 시퀀스를 출력시킨다고 합시다. 그림에서 뒤집혓을수도 있긴한대 햇갈리니 넘어가겠습니다.
하지만 결국에 하는 일은 영어 단어들과 프랑스 단어들/문장을 번역하는 작업을 할 것인데, 이 어텐션을 이용한 시퀀스 투 시퀀스 모델을 학습시킨것이고, 디코더의 타임 스탭마다 출력 시퀀스를 만드는 과정에서 입력 시퀀스의 어떤 단어에 주의를 기울일것인지를 정리하는 입력 시퀀스의 모든 단어들의 확률 백터를 만들어 냅니다.
그래서 우린 여기서 어탠션 가중치를 이 모델이 번역 작업을 할 때 어떤 결정을 내렸는가, 어떻게 결정을 내렸는가로 이해/해석 할 수가 있어요.
위 슬라이드를 보면 위에 영어 문장으로 "the agreement on the european economic area was signed in august 1992"가 있고, 그 아래에 프랑스어로 동일한 의미를 나타내는 문장이 있어요.
여기서 재미있는 부분은 이 다이어그램은 출력의 모든 타임스탭에서 어탠션 가중치가 어떤지를, 즉 모델이 어떤 선택을 했는지를 보여주고 있어요. 그래서 이 그림으로 해석할수 있는 구조 부분들이 많은데, 첫번째로 볼수 있는 건 왼쪽 위 코너에서 어텐션 가중치의 대각 패턴을 볼수가 있어요. 이 패턴의 의미는 "the"라는 단어가 프랑스어 토큰 L'를 생성하는대서 가장 집중을 했다는 의미입니다.
그 다음 영단어 "agreement"는 프랑스 단어 "accord"를 만들때 가장 집중되었다는 것이고, 그래서 출력 시퀀스의 처음에서 네 번째 단어를 생성하는데까지 일대일 대응되었다고 이해/해석할수 있겠습니다. 그리고 이 대응관계는 모델이 스스로 찾아내는것이지 우리가 모델에게 문장의 어떤 부분이 배정/매칭되는지 알려준게 아니에요.
하지만 여기서 가장 놀라운 부분은 프랑스어로 "zone economique europeenne", 영어로는 "european economic area"인데, 여기서 세 단어는 같은 의미이지만 다른 순서로 되어있어요. 프랑스어 "zone"은 영어로 "area"이고, 영어로 "economic"은 프랑스어로 "economique", "european"은 "europeenne"와 대응되는 구조인것을 볼수 있고, 이 모델은 이 세 단어의 순서를 뒤집어서 대응시키고 있어요.
이 어텐션 매커니즘에서 좋은 점은 다른 신경망 아키텍처와는 달리 이 모델이 어떻게 결정을 내렸는지에 무엇을 골랏고 무엇을 안 골랐는지에 대해서 어느정도 해석할수있는 점이되겠습니다.
그래서 이 어텐션 매커니즘으로 시퀀스를 생성했고, 단어 생성시 매 타임스탭마다 입력 시퀀스의 서로 다른 부분들을 집중해서 보았습니다. 하지만 이 어텐션 메카니즘의 수학적인 구조에 대해서 알아차릴수 있는점은 입력이 시퀀스라는 사실을 신경쓰지 만들었다는 점입니다.
이러한 기계 번역의 작업에서 입력을 시퀀스로 받고 출력도 시퀀스가 되었지만, 어탠션 매커니즘의 목표는 시퀀스인 입력 벡터들을 사용하는것이 아니라, 시퀀스가 아니더라도 다른 종류의 데이터에도 집중할수 있도록 어텐션 메카니즘이 만들어졌어요.
지금까지 기본 바닐라 RNN의 그라디언트 플로우를 보면서 그라디언트 폭증, 소멸 문제에 대해 살펴봤다. 그라디언트 소멸 문제를 고치기 위해서 사람들은 이 Vanilla RNN대신 다른 아키텍처를 사용하기 시작하였으며
LSTM Long Short Term Memory 장단기 메모리라고 부르는 방법을 주로 사용하고 있다. 한번 보면 다소 복잡해보이고, 햇갈리게 생겼다보니 이 식을 보면 어떻게 돌아가고 이걸로 어떻게 문제들을 푸는지 명확하게 이해하기는 어렵겠다.
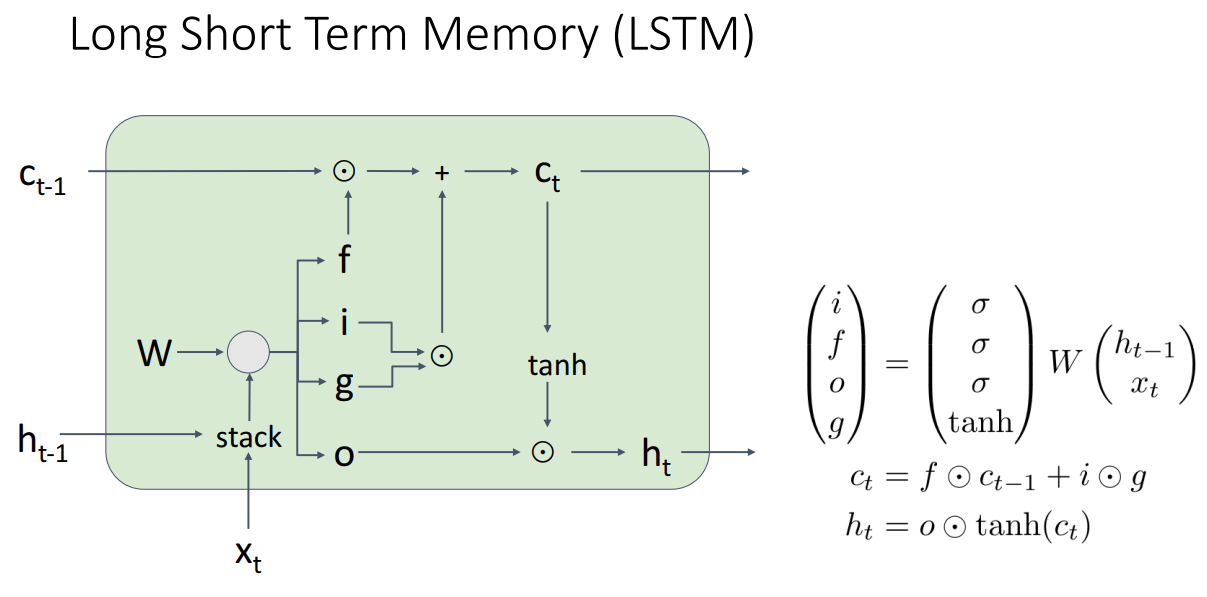
LSTM은 기본적으로 하나의 은닉 유닛 벡터만을 사용하는게 아니라 두 은닉 벡터를 사용하는데, 하나는 셀 상태 cell state라고 부르는 c_t와 은닉 상태 hiddent state h_t가 있겠다.
이전 은닉 상태와 현재 입력을 가지고 서로 다른 4개의 게이트 값 i, f, o, g를 계산을 하고, 이 들을 이용해서 갱신된(현재의) 셀 상태와 은닉 상태를 구한다. 여기서 짚고 넘어가고 싶은건 LSTM은 1997년에 나왔다는 점인데, 10년간 잘 알려지지는 않았지만 2013, 2014년경 사람들이 LSTM 아키텍처를 사용하기 시작하면서 점점 대중화되기 시작했고, LSTM 아키텍처가 현재 시퀀스처리에 가장 널리 사용되는 순환 신경망 아키텍처가 되었다.
LSTM에 대해서 조금 더 풀어서 매 타임스탭마다 어떻게 동작되는지를 살펴본다면, 입력 x_t와 이전 은닉상태인 h_t-1을 받겠다. 그리고 순환 신경망 처럼 입력 벡터 x_t와 이전 은닉 상태 h_t-1를 연결 concat시키고, 어떠한 가중치 행렬을 곱한다.
https://throwexception.tistory.com/1203
바닐라 순환 신경망 Elman RNN에서 이 행렬곱 연산의 결과에다가 tanh 비선형 함수를 적용해서 현재 은닉 상태값을 계산하였었지만
LSTM에서는 각각 크기가 H(H는 은닉층 유닛 개수)인 4개의 서로 다른 벡터를 출력할수 있도록, 행렬곱 연산을 다듬어서 출력을 계산하며 이 출력들을 게이트라고 부른다. 입력 게이트 input gate, 망각 게이트 forget gate, 출력 게이트 output gate, 더 나은 표현이 떠오른는게 없어서 게이트 게이트 gate gate로 4가지가 있다.
이 슬라이드에 행렬곱으로 출력(은닉 상태에 tanh 적용한것)을 바로 예측하기보다는 4개의 게이트를 예측한 다음에 이 4가지 게이트로 현재(갱신된) 셀 상태와 은닉 상태를 구한다.
여기서 주의해야할 점은 이 4개의 게이트들은 서로 다른 비선형 함수가 적용되는데, 입력 게이트, 망각 게이트, 출력 게이트는 전부 시그모이드 비선형 함수를 적용시키며, 그러면 0과 1사이 값을 가지게 되겠다. 게이트 게이트의 경우 tanh 함수를 통과 시키며 그러면 -1 에서 1 사이 값을 가지게 되겠다.
그 다음에 c_t에 대한 식을 보면 이전 셀 상태인 c_t-1과 망각 게이트를 원소 단위 곱샘을 하는데, 망각 게이트가 0 ~ 1사이 값을 가지고 있다보니, 망각 게이트는 셀 상태의 원소들을 0으로 리셋을 시키거나 셀 상태를 순방향으로 계속 전파를 시키는것으로 이해할수 있으며 이게 망각 게이트가 하는 일이 되겠다.
그리고 c_t에는 입력 게이트와 게이트 게이트의 원소 단위 곱을 더하고 있는데, 게이트 게이트는 -1 ~ 1 사이 값을 가지는 것으로 셀 상태에 쓰고자 하는 값(반영 하고자 하는 값)을 나타낸다. 입력 게이트는 0과 1사이 값을 가지는데 시그모이드 함수를 적용했기 때문이며, 게이트 게이트와 원소단위 곱샘을 함으로서 정리하자면 게이트 게이트는 1을 더하거나 -1을 빼는 역활을 하고, 입력 게이트는 그 셀의 모든 지점에서 실제로 값들 더할지 뺄지 판단하는 역활을 한다.
이제 최종 출력 상태를 계산하기 위해서는 셀 상태를 tanh 비선형 함수에 적용시키고, 출력 게이트와 원소 단위 곱샘을 하면 되며, 이 과정이 lstm이 lstm은 셀 상태의 일부를 출력 게이트로 조작하여 매 타임스탭마다 드러낼지 말지 를 선택할수 있다. 그래서 출력 게이트는 셀 요소들을 얼마나 밖으로 내보낼지 혹은 은닉 상태로 감출치
최종 출력 상태는 셀 상태를 tanh 비선형 함수에 적용 시키고나서 출력 게이트와 원소 단위 곱샘을 통해서 계산하며, 이 과정을 정리하자면 셀 상태는 lstm에서 처리되는 내부 은닉 상태로서 lstm은 매 타임 스탭마다 어떤 셀 상태를 밖으로 드러낼지 출력 게이트로 정할수 있겠다.
그래서 출력게이트가 ㅎ하는 일은 얼마나 많은 셀들을 드러내거나 은닉 상태로 나둘지를 정한다고 할수있겠다. 출력 게이트의 일부 원소들을 0으로 지정한다면 셀 상태의 원소들은 밖으로 나오지 못한채 은닉 될 것이고, 내부적인 변수로서 lstm에 유지되겠다.
LSTM을 설명하기위한 복잡한 그림들이 많긴한데, 이 걸 보면서 단일 LSTM의 처리 과정을 이해할수 있겠다. 이 그림을 보면 왼쪽에서 이전 셀 상태 c_t-1과 이전 은닉상태 h_t-1을 받고, 이전 은닉 상태와 현재 입력 x_t를 쌓은 다음에 가중치 행렬과 곱하고 있다.
그 결과 4개의 게이트로 나누어져 이 게이트들은 셀 상태 c_t와 은닉 상태 h_t를 계산하는데 사용 되겠다. LSTM을 이 방식으로 살펴보면서 흥미로운 점은 바닐라 RNN과 비교했을때, 그라디언트 플로우에 대해서 다른 관점으로 볼수 있겠다.
한번 현재 셀 상태 c_t로부터 이전 셀 상태 c_t-1로 역전파를 한다고 생각해보자. 그러면 위와 같이 꽤 깔끔하게 그라디언트 경로가 만들어진다. 왜냐면 역전파를 할때 덧셈 노드를 만나는 경우, 역전파에서 덧샘 노드는 그라디언트를 복사 하는 역활을 했지, 정보를 죽이지는 않았었다. 그래서 처음 덧샘 노드를 만났을때, 들어온 그라디언트는 LSTM 내부로 퍼지게 되겠다.
그 다음에 망각 게이트와 원소 단위 곱샘을 역전파하는 경우, 여기서 정보가 제거될 위험이 있다. 그 이유는 시그모이드 비선형 함수를 역전파 과정에서 통과하기 때문이 아니라, 비선형 함수 , 원소 단위로 0과 1사이의 상수값을 곱한것을 역전파하다보니 정보가 사라질 위험을 가지기 때문이다.
망각 게이트가 0에 가깝다면 정보가 사라질 위험이 있으나, 1에 가깝다면 현재 셀 상태에서 이전 셀 상태로 역전파시에 정보들이 사라질 위험은 없겠다. 그렇다보니 어떤 비선형 함수도 지나가지도 않고 행렬 곱 연산도 역전파 과정에서 지나가지 않다보니 LSTM의 탑 레벨 경로가 간단하게 흘러가는걸 볼수 있겠다.
-> 이 부분 내용을 정리하면
일단 LSTM의 탑래밸에서는 셀 상태 역전파를 보면, sum 노드에서의 역전파는 분배되다보니 그대로 지나가고,
(시그모이드 함수 역전파 때문이 아니라) 원소 단위 곱샘 노드 때문에 정보가 사라질수도 있는데,
망각 게이트는 0과 1사이값을 가지고 있으며, 0에 가까우면 순전파시 정보가 사라지지만 1에 가까울때 역전파시에는 정보가 사라지지 않는다
그래서 덧샘 노드와 원소 단위 곱샘 노드를 깔끔하게 지나가는 그라디언트 경로가 만들어지는것 같다.
여러개의 LSTM 셀들을 연결 시켰을때 시퀀스를 처리하고 나서 맨 위의 셀 상태들이 지나가는 통로를 보면 인터럽트 받지 않은 고속도로같이 되는걸 볼수 있다. 이 통로를 통해서 시간에 따라서 역방향으로 정보가 쉽게 통과할 수 있겠다.
LSTM 모델은 바닐라 RNN과 비교해보면 역전파 진행시 그라디언트 플로우가 더 잘 흘러갈거라고 볼수 있겠다 하지만 여전히 가중치 때문에 문제가 발생할수 있겠는데, 바닐라 RNN의 경우 그라디언트는 시간에 영향을 받아, 아주 긴 타임 스탭을 거친다면 정보들이 훼손되어 제대로 학습을 할수가 없다.
하지만 LSTM에서는 역전파 과정에서도 정보들이 보존되어 흘러갈수 있는 통로가 있다보니, 가중치로 역전파 후에 행렬곱이나 비선형 연산을 지나가더라도 고칠수가 있겠다.
하지만 행렬곱이나 비선형 함수를 지나가면서 역전파를 시킬 필요가 없는 경로가 있었는데, 학습 과정에서 정보가 계속 흘러가도록 하기 위해서 여전히 h_t를 가지고 있도록 하였다.
그래서 LSTM의 셀 상태는 LSTM의 프라이빗 변수라고 보면되고, 은닉상태 h_t는 LSTM의 출력을 내기 위해서/예측하기 위해서 사용한다.
LSTM을 보면 인터럽트 되지 않는 그라디언트 고속도로를 가지도록 설계되었는데, 이와 비슷한 아키텍처를 이전에 한번 본적이 있었습니다. ResNet으로 아주 심층 합성곱 신경망을 학습하는 문제를 해결하기 위해서 스킵 커낵션을 추가시켰고, 그 결과 그라디언트가 아주 많은 계층에서 잘 퍼져나갔습니다. LSTM에도 동일한 아이티어라고 보면 될거같습니다.
LSTM과 ResNet은 많은 부분에서 공통점을 가지고 있는다고 볼수 있겠고, 재미있는 신경망으로 고속도로 신경망이 있다. 이 신경망은 ResNet 이전에 나오기는 했지만 LSTM을 닮았으며 한번 확인해보면 좋겠다.
지금까지 단일 계층 RNN에 대해서 살펴보면서, 입력 시퀀스를 간편하게 처리해서 은닉 층 시퀀스를 만들고, 이 은닉 벡터들의 시퀀스로 출력 시퀀스를 만들어냈다. 지금까지 이미지 처리를 하는 경우를 봤는데 더 많은 계층을 사용하면 모델 성능을 개선 시킬수가 있겠는데 순환 신경망의 경우에도 그렇다.
다층을 쌓는 방법은 기존의 순환 신경망의 은닉 상태를 또다른 순환 신경망에다가 입력으로 넣으면 된다. 이렇게 만든 걸 다층 혹은 심층 순환신경망이라 부를수 있겠다. 과정은 첫 입력 시퀀스를 처리해서 은닉 상태 시퀀스를 만들고, 그 은닉 상태 시퀀스를 다음 순환 신경망의 입력 시퀀스로 사용해서, 두번째 은닉 상태 시퀀스를 만들어 낸다.
더 깊이 쌓고자 하는 경우 GPU 메모리가 되는 만큼 더 쌓으면 되겠다. 이런 순환 신경망을 여러 층으로 계속 쌓아서 사용해도 되겠지만, 순환 신경망을 실제로 쓴다면 3 ~ 5계층이면 충분하며, 합성곱 신경망 처럼 아주 깊은 모델은 잘 사용되지는 않는다.
(질문) 다른 순환 신경망 계층 마다 서로 다른 가중치 행렬을 사용하는가?
O. 다른 계층끼리 다른 가중치 행렬을 사용한다.
다루고 싶은 수많은 문제들이 있고, 현재 신경망을 고쳐서 더 나은 수식을 정리해서 문제를 해결할수 있으면 좋겠지만 수많은 다른 순환 신경망 아키텍처를 이용한 논문들이 나오고 있다.
여기서 중요한 방법중 하나로 위 슬라이드 왼편에 있는 gated reccurent unit GRU라고 부르는 방법인데, LSTM의 간편화 시킨 버전이라고 볼수 있겠다. 이 방법에 대해서 깊게 설명하지는 않겠지만 그라디언트 흐름을 개선시키기 위해서 가산 연결을 사용하였다.
그리고 컴퓨터 계산 비용이 점점 저렴해지기 시작하면서 사람들이 부르트 포스 방법을 싸용하기를 시작했는데, 최근 몇년전에 혁신적인 탐색방법을 사용하였는데, 부루트 포스 방법으로 수만개의 수식 공간들을 탐색해서 서로 다른 순환 신경망 모델을 만들어서 찾아보았다.
이 논문에서 찾은 갱신 공신 3가지를 볼수 있는데, LSTM보다 더 잘 동작한다고 볼수있을만한 건 없었다. 비슷한 성능을 보이는 수많은 수식들이 존재하지만 LSTM은 사람들이 가장 처음 발견한 것이고, 사람들이 지금까지 사용하는 역사적으로 좋은 모델이라 할수 있겠다.
이미 몇 강전에 신경망 아키텍처 탐색 방법에 대해서 살펴보았는데, 합성곱 분야에서 다른 신경망 아키텍처를 생성하는 신경망, 간단하게 소개만 하고 자세히 다뤄보지는 않았다. 사람들은 순환 신경망 아키텍처에도 이와 같은 방식을 적용해서 찾아보았다.
순환 신경망을 컴퓨터 비전 분야에 활용한 예시로 이미지 캡셔닝이 있겠다. 이 이미지 캡셔닝은 이미지 하나를 입력으로해서 문장을 출력시키는 일대다문제라고 할수 있는데,
이미지를 합성곱 신경망에다가 입력으로주어 특징들을 추출시키겠다. 그렇게 추출한 특징들을 순환 신경망 언어 모델에 대입하여 문장을 만들수 있도록, 이미지 데이터셋과 이미지에 대한 캡션들을 사용해서 이 언어 모델을 경사 하강법으로 학습 시키겠다.
이 그림은 이게 어떻게 생겻는지 보기위한 전이 학습의 구체적인 예시라고 할수 있는데, 우선 이미지넷으로 선학습시킨 CNN모델을 다운받아서 가져오고, 그 신경망 모델의 마지막 2계층을 제거시키겠다.
이제 유한한 임의 길이의 시퀀스를 절단 시간 역전파를 사용해서 처리한다고 해보자. 이미지 캡셔닝에서는 <start>와 <end>로 이뤄진 시퀀스를 가지고 처리하는데 항상 시퀀스의 첫번째 요소, 시작 요소는 <START>로 새로운 문장의 시작점을 의미한다.
이제 합성곱 신경망으로부터 얻은 데이터를 순환 신경망에서 사용해보자. 지난번에 이전 상태의 은닉 상태를 이용해서 현재 은닉 상태를 계산하는 공식을 약간 변환을 시켰는데, 이미지 정보를 반영해서 매 시점마다 세 입력을 받게 되었다.
시퀀스의 현재 요소와 이전 은닉 상태 그리고 선학습 합성곱 모델에서 얻어낸 특징까지 이 세가지 입력을 서로 다른 가중치 행렬 혹은 선형 사영을 한뒤 이들 모두를 합한 휘 tanh 함수를 적용시키는 형태로 기존의 순환 신경망 순환 함수를 변경시켰다. 이와 같이 변경 시킴으로서 이미지에 대한 특징 백터 정보를 추가적으로 반영할 수 있었고,
이 이후에는 언어 모델처럼 동작하게 되겠다.
훈련을 마치고나서 테스트 때 어떻게 동작하는지를 보면, 우선 첫번째 단어를 얻고자 사전에 있는 단어, 토큰에 대한 확률 분포를 예측하여 "man"이라는 단어를 얻을수가 있겠다.
이 단어 "man"을 순환 신경망의 다음 입력으로 사용해서 다음 단어인 in을 얻고
이 과정을 반복해나가면, "straw", "hat" 등 단어들을 얻을수가 있겠다.
그리고 마지막에는 <END> 토큰이 나오면서 멈추게 되겠다. 이 처럼 유한한 길이의 시퀀스를 처리하는경우 사전에 <START> 토큰을 시퀀스의 맨 앞에, <END> 토큰을 시퀀스의 맨 뒤에 추가시켜서 학습하는 과정에 사용하며, 테스트 시점에서 <END> 토큰을 구하는 순간 출력을 멈출 시점으로 판단하여 샘플링/예측 과정을 종료하게 된다.
(질문) 위 수식에서 파랑 항과 분홍 항의 차이는 무엇인가
위 변경된 함수를 보면 녹색, 파랑, 분홍 세 가지 항이 있는데, 녹색항은 현재 시점 시퀀스 입력으로 입력 토큰 값중 하나를 나타내며 이 예시에서는 <START>, man, in, straw, hat 중 하나가 사용되겠다. 파랑 항의 h는 이전 시점의 은닉 상태를 나타내며 예를들어 h2를 계산하는 경우 h1을 의마한다고 할수 있겠다. 이번에 분홍 항의 경우 합성곱 신경망으로부터 얻은 특징 벡터 v를 나타내는데, 순환 신경망의 모든 시점에서 사용되겠다.
이미지 데이터셋과 그에 대한 캡션들을 가지고 이미지 캡셔닝 모델을 학습시키켰을때 이미지를 아주 잘 설명하는 경우드를 한번 보자. 맨 왼쪽 위의 것을 보면, "고양이가 가방 안에 앉아있다."라는 결과가 나왔는데, 이전에 살펴보았던 단일 라벨만 출력시켰던 이미지 분류 모델보다 훨씬 자세하게 설명할수 있다.
다음으로 위의 맨 오른쪽을 보면 "하얀 곰인형이 잔디밭 위에 앉아있다."라면서 좋은 결과를 얻었고, 아래를 보면 "두 사람이 서핑 보드를 들고 해변가를 걷고 있다", "테니스 선수가 동작을 하고 있다"와 같이 이미지들을 상당히 잘 설명하고 있는걸 볼수 있겠다.
그래서 이미지 캡셔닝에 대한 첫 연구 결과가 나오면서 그동안 "고양이", "개", "트럭" 같은 단순한 단일 라벨이 아니라 주어진 이미지를 보고 의미있는 출력을 내면서 많은 사람들이 열광하곤 했었다.
하지만 얼마 안가서 이런 이미지 캡셔닝 모델이 생각 많큼 똑똑하지 못하다는게 드러났는데, 한번 실패한 경우들을 살펴보자.
왼쪽 위 이미지를 훈련된 이미지 캡션 모델에다가 주면, "한 여성이 고양이를 손에 쥐고있다"라는 결과가 나오고 있다. 아마 여성의 옷의 텍스처/질감이 훈련셋에 있는 고양이 털과 비슷해서 일수도 있겠다.
그 아래 이미지를 보면 "한 사람이 책상 위에서 컴퓨터 마우스를 쥐고 있다."라는 결과가 나온 경우인데 여기서 사용한 데이터셋이 아이폰이 나오기 전에 만들어지다보니, 여기 나오는 사람이 책상에서 뭘 쥐고 있던간에 컴퓨터 마우스나 다른 휴대폰으로 판단하게 되겠다.
이와 같이 이미지 캡셔닝 모델은 꽤 재미있을지는 몰라도 여전히 부족한 점이 많으며, 이런 문제들을 해결하려면 꽤 걸릴것으로 보인다.
다음으로 살펴봐야할것으로 순환 신경망의 그라디언트 플로우/흐름이 있겠다. 위를 보면 우리가 지금까지 다뤄온 바닐라 순환 신경망에 대한 그림이 있는데, 여기서 순환 신경망이 한 타임 스탭에서 어떻게 처리되는지를 보여주고 있다.
입력 x_t가 아래에서 들어오고, 왼쪽에서 이전 은닉상태 h_t-1이 들어온다. 이 두게를 연결시키고나서 가중치 행렬 W에 대한 선형 변환으로 정리 할수 있고, 여기다가 tanh 비선형 함수를 적용시켜서 현재 상태 h_t를 구할수가 있겠다.
여기서 우리가 알아야 하는 부분은 이 모델이 역전파 하는 과정에서 그라디언트가 어떻게 되는가인데
한번 역전파가 진행되는 과정에서 어떤일들이 생기는지 한번 생각해보면, 일단 출력 은닉 상태 h_t에 대한 비용함수의 미분치를 받을게 되겠다. 우리가 구하고자하는건 입력 은닉 상태 h_t-1에 대한 비용의 그라디언트를 계산해야 한다.
여기서 두가지 문제가 생기는데, 그 중 하나는 tanh 비선형 함수를 사용하는것으로 여러번 왜 tanh 함수가 안좋은지 이야기 했고 가능한 쓰지말아야하며, 문제가 생길 가능성이 있다고 보아야한다. 하지만 이 rnn모델이 90년대에 만들어진것이다보니 감안해야 되겠다.
https://throwexception.tistory.com/1184
이 순환 신경망 모델에서 역전파를 할때 생기는 또 다른 큰 문제로는 역전파시 행렬곱 부분인데, 역전파 과정에서 가중치 행렬의 전치 행렬을 곱해야 한다.
그러면 한번 단일 순환 신경망 셀이 아니라 여러 타임 스탭을 흘러간 순환 신경망을 다뤄보자. 그러면 여기서 전체 시퀀스를 역으로 흘러가는 그라디언트 플로우를 볼수 있겠다. 업스트림 그라디언트는 계속 계속 동일한 가중치 행렬의 전치행렬과 곱해나가게 된다.(순환 신경망에서는 하나의 가중치 행렬을 공유= 모든 시점의 가중치 행렬이 동일하므로)
이렇게 되면 아주 안좋은 결과를 얻을수 밖에 없는데, 이 슬라이드에서는 4개의 셀만 보여주고 있지만 100 혹은 200 혹은 수천 타임 스탭의 시퀀스를 풀어나가는 경우에 역전파 과정에서 동일한 가중치 행렬을 수천번 곱해나가면 두 가지 방향으로 잘못 동작하게 된다.
발생되는 문제들 중 하나는 행렬이 아주 크다면, 같은 행렬을 계속 곱하다보면 점점 커져 무한대로 커지게 될것이고, 가중치 행렬의 가장큰 특이 값이 1보다 작다면, 그라디언트는 급격히 줄어들어 0이되어 사라져버리게 되겠다.
다시 정리하면 가장큰 특이값이 1보다 크다면, 그라디언트가 무한대로 폭증할것이고, 가장 큰 특이값이 1보다 작다면 그라디언트가 0이 되어버리겠다. 그래서 이와 같은 그라디언트 폭증, 그라디언트 소멸 문제를 가지게 되므로, 아주아주 긴 시퀀스를 처리할때 안정적으로 학습시키기 위해서는 가중치 행렬의 모든 특이값이 정확히 1이 되도록 만들면 되겠다.
그래서 사람들이 그라디언트 폭증을 대처하기 위해서 사용하는 방법은 그라디언트 클리핑/다듬기?이라고 부르는 방법을 사용하는데, 역전파에서 실제 그라디언트를 사용하는것이아니라, 은닉 상태에 대한 그라디언트를 계산한 후에, 그라디언트의 유클리디안 노름이 너무 큰지 체크를해서 그렇다면, 그라디언트가 줄어들도록 위의 값을 곱해주는 방법이 되겠다.
그래서 이 그라디언트 클리핑을 사용한 덕분에 실제 그라디언트를 계산한것은 아니지만 적어도 그라디언트가 폭증하는건 막아 역전파를 계속할수 있게 되겠다. 하지만 이 방법은 실제 그라디언트를 계산해서 쓰는게 아니다보니 좋은 방법이라 할수 없고, 그저 그라디언트 폭증을 방지하기 위해서 사용했던 경험적인 방법이었습니다.
그리고 다뤄야 하는 또 다른 문제로는 그라디언트 소멸 문제로, 특이 값이 아주아주 작은 경우에 발생하는 이 문제를 피하기 위해서 사람들이 이 기본 아키텍처 대신 다른 순환 신경망 모델을 사용하였습니다.
여기서 재미있는 점은 순환 신경망 언어 모델을 학습시키는데 사용한 데이터에 따라서 사용한 데이터의 특성을 갖는 텍스트가 생성된다는 점이다. 예를 들어서 셰익스피어 전체 작품을 텍스트 파일로 다운 받으면 아주 긴 문자 시퀀스가 될건데, 셰익스피어 전체 작품으로 순환 신경망을 학습할수 있고, 그러면 어떤 문자들이 주어질때 다음에 올 단어가 어떤게 올지 예측하도록 시도해볼수 있겠다.
순환 신경망을 학습 시키킴으로서 목표는 세익 스피어의 전체 작품을 참고해서 다음에 올 단어가 어떤것인지 예측하기 위한것이다보니,
이 데이터를 학습시키고나면 훈련된 모델로부터 예측한 단어를 얻을 수가 있으나 첫 몇 반복만으로는 잘 동작하다고 보기 어려운 결과가 나온다. 여기서 동작하는 과정은 신경망으로 다음에 올 단어를 구하고, 이 단어를 다음의 입력으로 사용하고, 이 과정을 반복하여 위의 새로운 데이터를 생성시켰다.
하지만 첫 번째로 생성한 것은 학습이 충분히 길게 수행되지 않아서 텍스트의 구조를 파악하기전이다보니 가중치가 보다 고르게 되있지 않아 쓰래기 값들이 만들어 졌다.
이걸 조금 더 길게 학습을 시키면 텍스트 구조를 인지하기 시작하여, 단어 같은 것들이 만들어지고, 이 단어들 사이에 스페이스도 들어가고, 어떤 경우에는 따옴표가 들어가도록 생성하게 되었다.하지만 여전히 쓰래기값이 존재하는게 보인다.
여기서 더 학습을 시키면, 이제 문장이라고 볼수 있는 것들이 만들어지는데 aftair fall, unsuch 같이 스펠링 오류들이 존재 한다. 이게 뭔가를 설명하는것 같긴하지만 여기서 더 길게 학습시킨다면 더 좋고, 현실적인 텍스트가 만들어 진다.
"why do what that day," replied natasha and wishing to himself the fact the princess mary was eaiser ... 라는 텍스트가 생성되었는데, 문법은 완벽하지는 않지만 실제 영어 문장 처럼 만들어 졌다.
그리고 여기서 아주 오래, 더 긴 시퀀스로 학습을 시키면 훨씬 셰익스피어가 쓴것 같은 텍스트를 만들수가 있다. 위 슬라이드와 같이 대본이 만들어진것을 볼수 있는데,
"pandarus : alas, i think he shall be come approached in the day with little strain would be attain'd into being never fed' and who is but a chan and subjects of his death, i should not sleep "
훨씬 극적이고, 셰익스피어가 쓴것 처럼 만들어 졌다. 하지만 여전히 횡설수설하고 있다. 여기서 더나아가서 다른 타입의 데이터로 학습을 해나갈수도 있겠고, 이건 셰익스피어의 작품 전체만 사용한게 되겠다.
몇년 전에 이와 비슷한 일을 했었는데, 추상 대수 abstract algebra 과정이나 대수 기하학 algebraic geometry과정을 수강한 사람이라면 그 과목들이 수학의 추상화 부분을 다루는 것으로 알고 있을텐데 이 대수 기하학에 대한 오픈 소스 책이 만들어졌으며 이 책은 수천 페이지의 저차 기술들이 정리되어 있다.
(교수님이) 여기서 한 작업은 수천 페이지 짜리의 대수 기하학 책의 소스 코드를 다운받아서, 순환 신경망에다가 이책 소스코드 수백개 문자를 입력으로 주어 다음 라텍스 소스코드의 문자를 생성하도록 신경망을 학습시켰다. 그러면 학습된 순환 신경망으로 가짜 수학공식을 만들수 있었으나 불행히도 컴파일 할수는 없었다.
그래서 문법을 정확히 따르는 저 수준 소스 코드를 생성하기 어렵더라도 발생되는 컴파일 에러는 수동으로 고쳐질수 있고, 컴파일을 시켜볼수 있겠다.
위 슬라이드는 순환 신경망으로 대수 기하학 교제를 학습해서 생성한 텍스트의 예시를 보여주고 있다. 이 내용들은 추상 수학같은 것으로 보조 정의 lemma들이 있고, 증명 proof들이 있으며, 증명 끝에 소괄호로 증명을 마무리하려고 하는데, 이걸로는 증명이 된건지 안된건지도 모르겠고, 실제 수학 교재라고 하기에는 잘못된점이 많겠다. 이 증명들을 정리하고, 이해하려면 참고 서적들을 살펴봐야 되겠다.
대수 기하학에 대해서 조금 더 살펴보면 여기에 가환 다이어그램 commutative diagram을 볼수가 있는데, 이 그림은 수학적 공간 사이에서의 관계를 보여주고 있으며 저레벨 소스코드로 생성되었다. 그래서 이건 순환 신경망이 증명을 설명하기 위해서 가환 그림을 생성시킨것이라고 할 수 있겠다. 이 페이지에서 다루고 싶은 부분 중 하나는 보통 수학 책에서 자주 보는 증명이 생략되었다.
정리하면 이런 문자 수준의 순환 신경망 언어 모델은 우리가 사용하고자 생각하는 어떤 종류의 데이터로도 학습할수 있으며, 리눅스 커널 전체 소스 코드를 다운받아서 순환 신경망 언어 모델을 학습시켜서, 리눅스 커널의 C 소스코드를 만들어 낼수가 잇다.
이게 생성시킨 C 소스코드의 예시인데, 제대로 보지 않으면 꽤 실제 커널 C 소스코드처럼 보인다. 내용을 보면 괄호도 있고, static, void, 포인터, 왼쪽 시프트 등 같은것들있고, 주석을 보면 Free our user pages pointer to place camera if all dash라고 말이 안되지는 않지만 주석이 추가되긴 한걸 볼수 있겠다.
이번 예시에서는 C 파일의 맨 위에 카피라이트가 작성되어있는데, 이는 C 소스코드 파일의 구조를 알고 있다고 볼수 있겠다. 카피 라이트 내용 이후에는 include 들이 있고,
매크로도 정의되고, 상수도 정의되고 그 이후에 함수가 정의되고 있다.
다음에 올 문자를 예측하는건 꽤 간단한 작업이기는 하지만 순환 신경망이 복잡한 리눅스 커널 C 소스 코드로부터 많은 구조들을 캡처했다고 할수 있겠다. 이 과정이 어떻게 이뤄지는지 궁금할수 있겠는데,
이게 데이터를 학습하는 중간에 순환 신경망을 표현한것으로, carpathia johson과 feifei가 몇년전에 투고한 논문의 것인데 순환 신경망을 다른 타입의 시퀀스 데이터로 학습시킬때, 순환 신경망 언어 모델이 무엇을 학습중인지 이해를 하려고 했었다.
여기서 사용하는 방법론은 순환신경망을 가지고와서 시간 스탭에 따라 풀어나가고, 다음에 올 문자를 예측시킨다. 다음 단어 예측 처리 과정에서 순환 신경망은 은닉 상태 시퀀스가 생성이되는데, 입력의 문자 하나당 하나의 은닉 상태이며, 이 은닉 상태들/시퀀스로 출력/문자를 만든다.
여러 차원의 은닉 상태를 캡처해서 뭘 할수 있을까? 예를 들어 은닉 상태가 56 차원이라 하고 tanh 함수의 출력을 사용한다면, 은닉 상태 벡터의 각 원소는 -1 ~ 1사이의 값이 되겠다. 56개의 원소를 가진다는 이점을 가지고, 은닉 상태의 값 0 ~ 1에 따라서 색상을주면, 신경망의 처리과정에서
지금까지 시퀀스 투 시퀀스 모델에 대해서 살펴보았고, 이번에 어떻게 동작하는지 구체적인 예시로 언어 모델 language model에 대해서 살펴보자. 기본적으로 무한한 입력 데이터 스트림, 그러니까 데이터 길이 제한없이 입력을 받아서, 매 시점마다 다음에 올 문자를 예측하는 순환 신경망 모델을 만든다고 할때 이 모델을 언어 모델이라고 부른다.
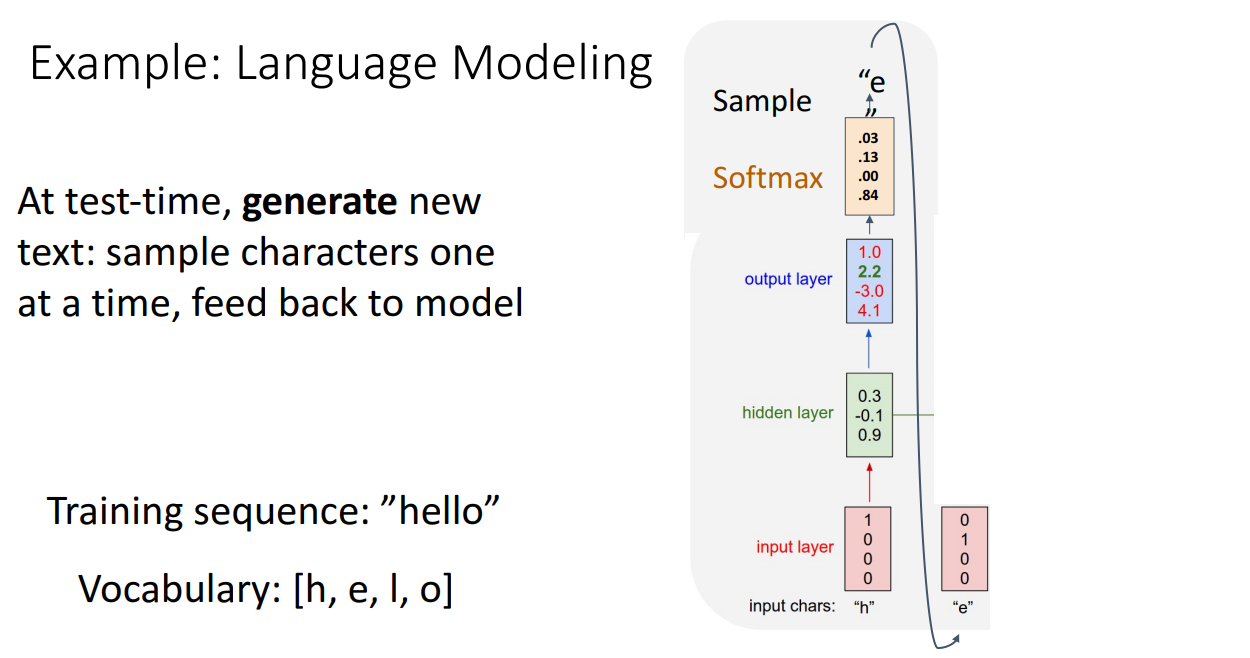
언어 모델을 다룰때는 기본적으로 고정 크기의 단어 집합을 가지고 있으며, 지금 우리가 다루는 경우에 단어 사전은 h, e, l, o로 이루어져 있으며 훈련 과정에서 사용하여야 한다. 오른쪽 그림을 보면 훈련 시퀀스로 "hello"라는 말을 처리하고자 하는경우인데, 이 입력 시퀀스의 각 문자들을 단어 사전 만큼의 길이를 가지는 원핫 인코딩 벡터로 변환시켜서 사용할 수 있다.
단어 사전 h, e, l, o와 사전의 길이를 알고 있고, 문자 h를 벡터로 바꾸고자 하는 경우 [1 0 0 0]이 되며, 이는 단어 사전의 첫번째 원소가 h를 나타내기 때문이다. 이 입력 시퀀스/원핫 인코딩 벡터를 순환 신경망에 입력으로 넣을수가 있겠다.
그래서 입력 벡터들의 시퀀스를 순환 신경망에 넣어서 은닉 상태들의 시퀀스를 구할수 있고,
-> 원 핫 인코딩 벡터로 해당 타임 스탭의 은닉 상태를 구한다.
그리고 이 순환 신경망이 다음 시퀀스 원소로 뭐가 올지 예측하는 작업을 하기 때문에, 매 타임 스탭마다 얻는 출력 행렬들로 단어 사전에 존재하는 각 원소들에 대한 분포를 예측하므로 그러니까 어떤 단어일 확률이 가장 높은지 찾아내는데 사용할수 있겠다.
-> 매 타임 스탭마다 다음에 올 단어가 뭔지 예측한다.
입력으로 시퀀스 첫번째 요소인 "h"를 받았을때, 다음에 올 원소/단어가 e여야 하는데 교차 엔트로피 비용을 사용한다.
다음으로 "he"를 입력으로 받은경우, 다음 단어가 세번째 단어로 "l"이 와야 하는것으로 예측해야 되겠다.
네번째 단어도 그렇게 진행해서
전체 타겟 출력들 "ello"을 보면 타겟 입력 "hell"에서 한칸 이동한것과 동일한게 되겠다. 훈련된 언어 모델을 얻으면, 언어 모델은 학습하는 과정에서 입력 시퀀스를 주고, 출력은 입력 시퀀스를 시프트 시킨것과 같은 형태가 된다.
* 입력 : hell -> 출력 : ello
그렇게 해서 매 타임스탭마다 다음 단어가 무엇이 올지 예측하도록 학습하게 된다. 일단 언어 모델을 학습해서 구하면, 꽤 다양한 일들을 할수 있겠는데, 학습 시킨 언어 모델로 새로운 텍스트를 만들어 낼수가 있다.
예를 들면 초기화 시드 토큰으로 문자 "h"를 주면, 순환 신경망이 주어진 초기화 시드 토큰에 따라 문자를 생성해내도록 한다고 할때 이게 처리 되는 과정은 일단 입력 토큰으로 "h"를 주자. 그러면 "h"에 대한 원 핫 인코딩이 한 층을 지나가면서 처리될것이고, 이 타임 스탭에서 다음 문자가 어떤게 올지 예측 확률 분포(softmax)를 얻을것이다.
이 모델은 다음 타임 스탭에 와야하는 단어에 대한 예측 분포를 가지므로, 이 분포로부터 다음 타임 스탭에 이 모델이 오는게 적합하다고 판단하는 단어를 구할수가 있겠다.
-> 출력 층에서 교차 엔트로피 비용이 나오고, 이 비용에 소프트 맥스를 취하여 예측 확률 분포를 구한다. 이 예측 확률 분포가 다음 타임 스탭에서 올 가능성이 높은 단어를 고를수가 있겠다.
* 다음 단어가 잘 오도록 학습 되야겠다.
이렇게 구한 문자를 가지고와서, 첫번째 타임 스탭의 출력이었던거를 다음 타임 스탭의 입력으로 사용하면 되겠다. 그래서 문자 e를 가지고 와서 다음 타임 스탭에 입력으로 넣고
이 순환 신경망의 다른 계층을 통과하여 새로운 은닉 상태를 계산하고, 출력에 대한 예측 분포를 계산하여 다음 단어가 무엇이 오는지 예측 할 수 있겠다.
이런 과정을 반복하게 되겠다. 학습된 언어 모델을 가지고 있으면 초기 토큰/단어을 가지고 그 다음으로 나올 가능성이 가장 큰 새 토큰/단어를 생성시킨다고 볼수 있다.
여기서 제대로 다루지 못한 부분이 있는데, 입력 시퀀스의 인코딩을 원 핫 벡터들의 집합이라고만 했다. 순환 신경망의 첫번째 계층에서 어떤 일들이 일어나는지 한번 살펴보자.
바닐라 순환 신경망을 다시 떠올려보면, 입력 벡터가 주어지고 가중치 행렬을 곱한다고 했었다.
그런데 입력 벡터가 원 핫 인코딩이라면 한 슬롯만 1이고, 나머지 슬롯들은 전체가 0이 되버린다. 그러면 가중치 행렬과의 곱은 너무 단순해지는데, 원 핫 벡터와 가중치 행렬을 곱한 결과 벡터의 한 컬럼(w_11, w_21, w_31)만 추출해버리게 된다.
이런 식으로 곱셈 연산을 구현하기 보다는 가중치 행렬의 행들을 더 효율적으로 추출할수 있도록 구현할수가 있는데, 가장 쉽게 사용하는 방법은 입력과 순환 신경망 사이에 임베딩 계층이라고 부르는 계층을 추가하는 방법이다.
여기 보면 임베딩 계층이 추가되어 있는데, 입력 시퀀스는 원핫 벡터의 집합으로 인코딩 되고, 임베딩 계층은 원핫 벡터와 희소 행렬을 묵시적으로 곱연산을 수행한다. 그렇게 해서 임베딩 계층은 주어진 임베딩 행렬의 각 열들을 따로 따로 학습하게 된다. (처음엔 w11, w21, w31, 다음엔 w12, w22, w32, 다음엔 ... 이런 식으로 각 열들을 따로 학습)
이게 순환 신경망에서 흔히 나타는 구조이며, 분리된 임베딩 계층을 가지고 이 분리된 임베딩 계층(열)은 은닉 상태를 계산하기 전과 원핫 벡터 사이에 위치한다.
그래서 지금까지 본 것들을 학습시키기 위해서, 순환 신경망 계산 그래프 예시를 살펴보았다. 순환 신경망을 학습하기 위해서 우선 본 건, 시간에 따라 펼쳐지는 계산 그래프가 필요하였으며, 매 타임 스탭/시점 마다 비용을 계산 후 전체 시퀀스 길이만큼 진행해서 하나의 비용으로 합해야 한다.
이 과정을 시간 흐름에 따른 역전파 backpropagation through time이라고 부르는데, 순전파를 하는 동안 시간도 흘러가고, 역전파를 하는 과정에서도 순전파에서 진행한대로 역으로 흘러가기 때문이다.
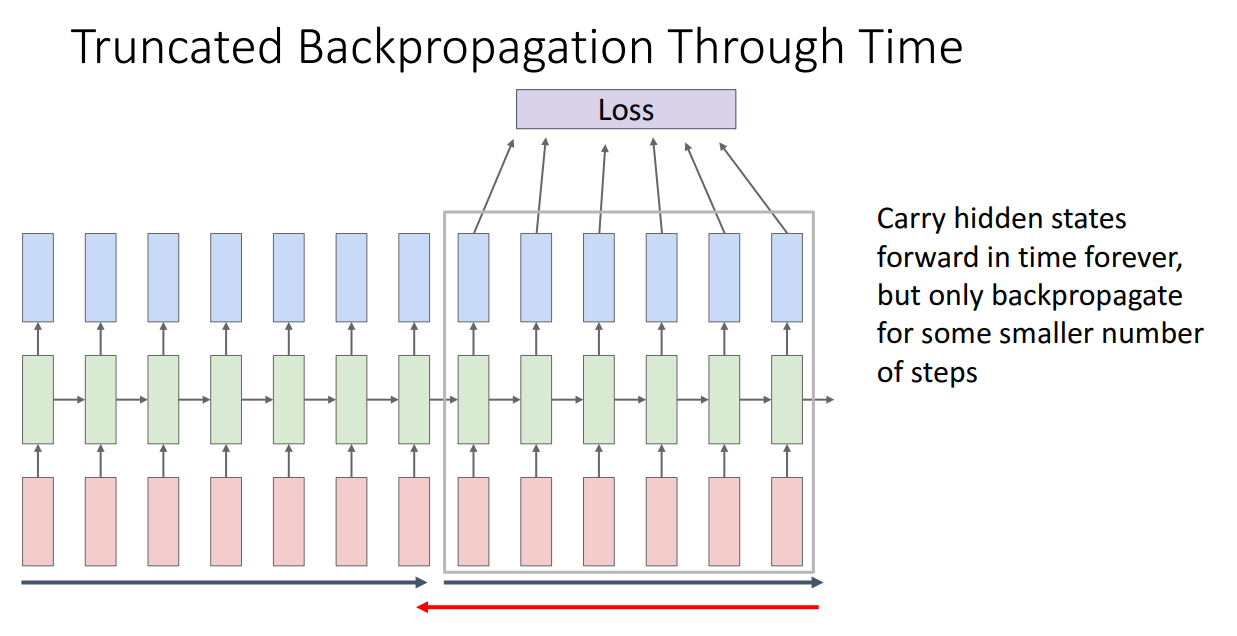
이 시간 흐름에 따른 역전파에서의 문제는 아주 긴 시퀀스를 다뤄야 하는 경우로 학습 시켜야할 시퀀스가 몇백만개의 단어라면 계산 그래프로 수백만 타임 스탭에 풀어나가려면 아주 많은 메모리 공간이 필요할것이고 우리가 가진 GPU로는 학습하기 어려울 것이다.
이런 이유로 순환 신경망을 학습하는 경우, 특히 아주아주 긴 시퀀스를 처리하는 순환 신경망 언어 모델을 학습하는경우 절단 시간 역전파 truncated back propagation through time이라고 하는 근사 알고리즘을 대안으로 사용한다.
위 슬라이드에 이 방법에 대한 아이디어를 볼수 있는데, 무한개의 시퀀스를 다루는 신경망을 학습하고자하는 경우로 시퀀스의 일부를 첫 토큰으로 수샙가내 수백개를 가지고와서 그 시퀀스 일부만큼 신경망을 풀어나가겠다. 그리고 시퀀스의 첫 덩어리의 비용만 계산하고, 시퀀스 초기 덩어리 진행한 만큼 역전파를 하여 가중치를 갱신하며 초기 시퀀스 덩어리 맨 끝에서부터 은닉 층 값을 고쳐나가겠다.
그 다음으로 시퀀스의 두번째 덩어리를 받아서 은닉 가중치들을 지나가는데, 이 가중치들은 첫번째 덩어리를 처리하고나서 수백개의 문자로 된 두번째된 시퀀스 덩어리를 풀어나가며 구한다.
그리고 이렇게 다음으로 들어온 수백개의 문자 시퀀스를 풀어나가면서 두번째 덩어리에 대한 비용을 계산하고, 전체 시퀀스가 아니라 두 번째 시퀀스 덩어리만큼 역전파를 진행하겠다. 그리고 이 비용으로 각 가중치 행렬들의 그라디언트를 계산하여 가중치 행렬을 갱신시키고 다음 시퀀스 덩어리로 넘어간다.
다음으로 진행을 하는데, 두번째 덩어리가 지나가면서 얻은 은닉상태로 순방향으로 세번째 시퀀스 덩어리를 풀어나가는데 사용하고, 시간 변화에 따른 절단 역전파를 해서 가중치는 갱신 되겠다.
이 시간 변화에 따른 역전파 알고리즘이 하는 일은 기본적으로 은닉 정보를 계속 순방향으로 이동 시키면서 무한개의 시퀀스를 처리할수가 있으나, 시퀀스의 일부 덩어리만 가지고 역전파를하면서 GPU 메모리 공간 사용량을 크게 줄임으로서, 이 절삭 역전파 알고리즘 truncated back propagation으로 유한한 메모리 공간을 가지고 있더라도 무한개의 시퀀스를 순환 신경망에 학습 시키는게 가능하도록 만들었다.
(질문 1) 시간 변화에 따른 절삭 역전파 방법을 사용할때 어떻게 두번째 덩어리의 h0를 설정할까요.
가지고 있는 최종 은닉 상태를 사용하겠다. 일단 첫번째 작업을 마치고 나서 첫번째 덩어리에 대한 최종 은닉 상태를 가지게 되는데, 이 은닉 상태가 두번째 덩어리에서 사용항 초기 은닉 상태가 되겠다. 은닉 상태를 통해서 정보를 시간에 따라 순방향으로 계속 전달하다보니 잠재적으로는 무한하게 처리할수 있겠다. 하지만 역전파는 시퀀스의 일부 덩어리만 가지고 한다.
(질문 2) 절삭 역전파 알고리즘 수행하는 동안 가중치 갱신이 어떻게 되는가?
한 덩어리 만큼 순전파를 하고, 그 덩어리만큼 역전파도 하고, 가중치 행렬을 갱신한 다음에 은닉 상태를 순방향으로 복사시키고 역방향을 갱신시키기도 한다. 다시말하면 순방향으로는 복사시키고 역방향으로는 가중치 행렬 갱신에 사용된다. 시퀀스 일부 덩어리를 역전파를 할때마다 그 덩어리 비용의 가중치 행렬에 대해서 미분치를 구하고, 이 그라디언트를 신경망 가중치 갱신에 사용하겠다.
시간 변화에 따른 절삭된 역전파 알고리즘을 정리하자면, 데이터들을 한 덩어리씩 처리함으로서 메모리 부족 문제를 해결하였다. 나머지 학습하는데 필요한 시퀀스의 모든 정보들을 그 순환 신경망의 최종 은닉 상태에 저장이 시킨 덕분이다.
이 전체 과정이 복잡해 보이기는 하지만, 112줄의 파이썬 코드만으로도 절삭 역전파 알고리즘 처리과정과 언어 모델 그리고 새로운 텍스트를 생성하기까지의 전체 처리과정을 구현할수가 있다. 여기서는 파이토치나 그라디언트를 계산하기 위해서 오토 그래프 같은 방법들이 사용하지도 않았지만, 파이토치를 사용한다면 4~50라인으로 만들수가 있겠다.
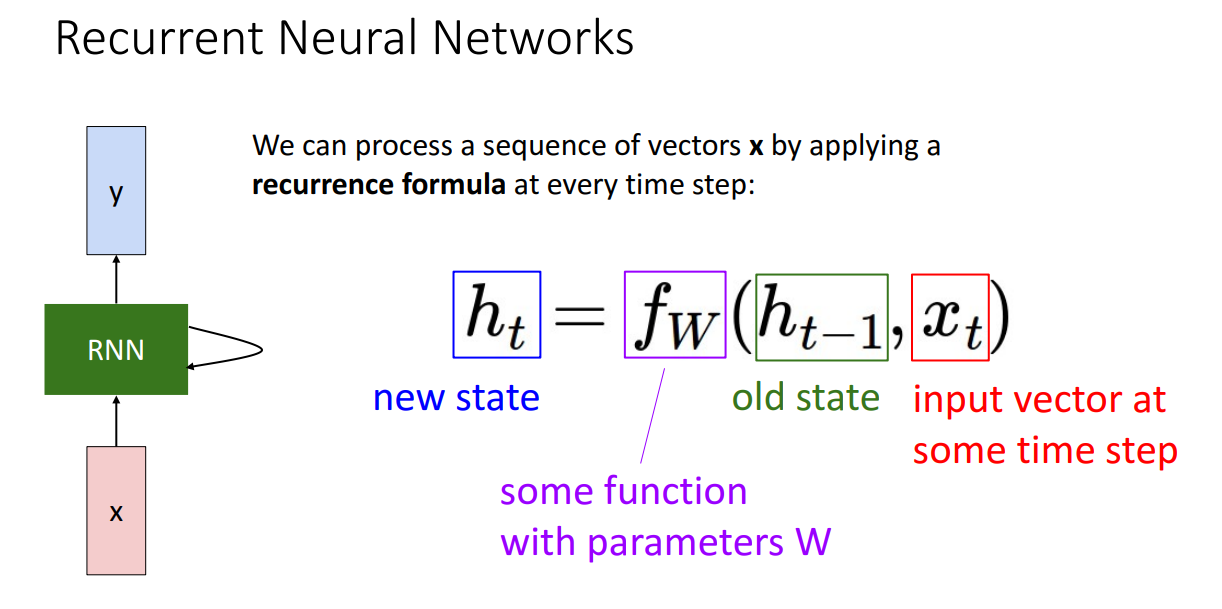
그래서 순환 신경망 recurrent neural network란 무엇이고, 어떻게 해야 그게 잘 동작할까. 기본적으로 순환 신경망은 순차적으로 처리한다고 말했었는데, 매 타임 스탭마다 순환 신경망은 위의 빨간색 상자 x와 같이 어떤 입력을 받고 파란색 상자에 나와있는 출력 y를 내보낸다.
거기다가 순현 신경망은 내부 은닉 상태 internal hidden state라고 하는 벡터를 가지고 있는데, 매 타임스텝마다 순환 신경망은 현재 타임 스탭의 입력을 어떤 공식에 따라 은닉 상태를 갱신시키는데 사용한다. 그러면 갱신된 은닉 상태는 현재 타임 스탭에대한 출력으로 내보내진다.
이게 어떻게 되는지 구체적으로 보자면, 순환 신경망 아키텍처를 정의하기 위해서 우선 순환에 대한 함수 $f_w$를 정의하여야 한다. 위 그림을 보면 $h_t$가 있고, 이 신경망은 은닉 상태에 대한 시퀀스를 처리하는걸 알수 있는데 여기서 $h_t$는 현재 타임스탭에서의 은닉 상태로 벡터 형태로 되어있으며 우리가 그동안 봐왔던 완전 연결 신경망의 은닉 층 활성 벡터 같은것이라고 보면 되겠다.
이제 순환 관계에 대한 함수 f를 정리하자면 f는 학습 파라미터 w의 영향을 받는 함수로 입력으로 이전 타임 스탭 $h_{t-1}$과 현재 타임 스탭에서의 입력 $x_{t}$를 입력으로 받아서 계산된 은닉 상태 $h_t$를 출력하게 된다.
$f_{W}$는 입력 벡터와 은닉 상대의 관계에 따라 대수적 방정식을 정의해서 사용하면 되겠다.
여기서 중요한건 매시간 스탭마다 시퀀스에대해서 동일한 가중치 W와 동일한 함수 $f_{W}$를 사용하는 것이며, 이렇게 함으로서 가중치를 공유하고 모든 각 시간에서 같은 가중치 행렬을 사용해서 처리할수 있겠다. 그래서 이 함수는 모두 같은 가중치 행렬로 매 시간마다 시퀀스를 처리하다보니 임의 길이의 시퀀스를 처리할수 있는 하나의 가중치 행렬을 가진다고 할수 있다.
이제 순환 신경망에 대한 일반적인 정의 형태를 가지고 첫번째로 구체적인 예시를 구현하여보자. 위 그림은 가장 간단한 순환신경망 버전으로 바닐라 순환 신경망 혹은 그냥 순환 신경망, 연구자의 이름을 따 Elman RNN이라고도 부른다.
여기서 은닉 상태는 하나의 벡터 $h_{t}$이며, 가중치 행렬들을 이용하여 학습하는데 가중치 행렬 중 하나인 $W_{hh}$는 이전 타임스탭의 은닉층과 곱하고, 다른 하나인 $W_{xh}$는 현재 타임 스탭의 입력과 곱한다. 여기서 현재 입력 $x_{t}$와 가중치 행렬 $W_{xh}$를 곱한 것과 $h_{t-1}$과 $W_{hh}$을 더하면 되는데 여기에 편의를 위해서 생략했지만 편향항 혹은 정규 편향항을 명확하게 정리한다면 추가할수 있겠다.
그리고 비선형성을 사용하기 위해서 계산 결과를 tanh 함수의 입력으로 사용하면 새로운 (현재 타임 스탭의) 은닉 상태 $h_t$를 얻을수가 있고, 출력 $y_t$는 현재 상태 $h_{t}$를 다른 가중치 행렬 $W_{ht}$와 곱함으로서 선형 변환하여 나오게 된다
지금까지 Elman RNN에 대한 정의를 보면서 어떻게 동작하는건지 이해할수 있겠다.
순환 신경망이 어떻게 동작하는지 보는 다른 좋은 방법으로 계산그래프를 이용해서 알아보면 좋겠다. 순환 신경망을 시간 변화에 따라서 쭉 풀어보면, 시퀀스 맨 처음에는 시쿼스 첫번째 원소인 $x_{1}$이 초기 입력으로 들어온다. 여기에 초기 은닉 상태 $h_{0}$가 필요한데 일반적으로 초기 은닉 상태는 0으로 설정하고, 어떤 경우에는 이것도 학습 가능한 파라미터로 놓고 학습해 나가기도 한다.
하지만 초기 은닉 상태 값을 모두 0으로 설정해도 잘 동작한다. 이렇게 초기 은닉 상태와 시퀀스의 첫번째 원소가 주어질때
이 초기 은닉 상태 $h_{0}$와 입력 $x_{1}$를 순환 관계 함수 $f_{w}$에 넣어서 첫번쨰 은닉상태인 $h_{1}$을 구할수가 있고,
이렇게 구한 첫번쨰 은닉 상태 $h_{1}$과 시퀀스의 다음 요소인 $x_{2}$를 동일한 함수 $f_{w}$에 넣어 다음 은닉 상태를 만들 수가 있겠다.
그리고 이런 식으로 계속 진행 되겠다.
여기서 중요한 건은 모든 타임 스탭, 시퀀스들은 동일한 가중치 행렬을 사용한다는 점이다. 위 그림의 계산그래프를 보면 확실하게 볼수 있는데 가중치 행렬 W 노드 하나가 모든 타임 스탭에서 사용되고 있다.
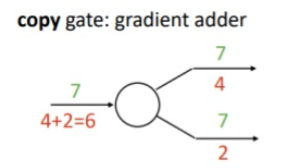
이번에는 역전파 과정에서 어떻게 되는지 생각해볼건데, 카피 노드의 경우 순전파 때는 한 노드를 여러개로 복사하는 역할을 했었고, 역전파때는 업스트림 그라디언트들을 합하여 다운스트림 그라디언트로 보내주는 역활을 하는데, 이 점이 이게 과제 4번 순환 신경망 구현에서 중요하다.
그리고 모든 타임 스탭에서 같은 가중치 행렬을 사용하다보니 어떤 길이의 시퀀스이던 간에 순환 신경망으로 처리할수가 있으며, 시퀀스 요소가 2개인 경우가 들어와도 이 그래프는 두번의 타임 스탭만 진행하면 되고, 시퀀스의 길이가 100이라면 이 그때는 100번 타임 스탭만큼 그래프가 진행되면 되겠다.
그래서 입력으로 받는 시퀀스의 길이가 중요하지 않으며 같은 순환 신경망, 특정 길이의 시퀀스 처리에 같은 가중치 행렬을 사용해서 처리할수 있겠다.
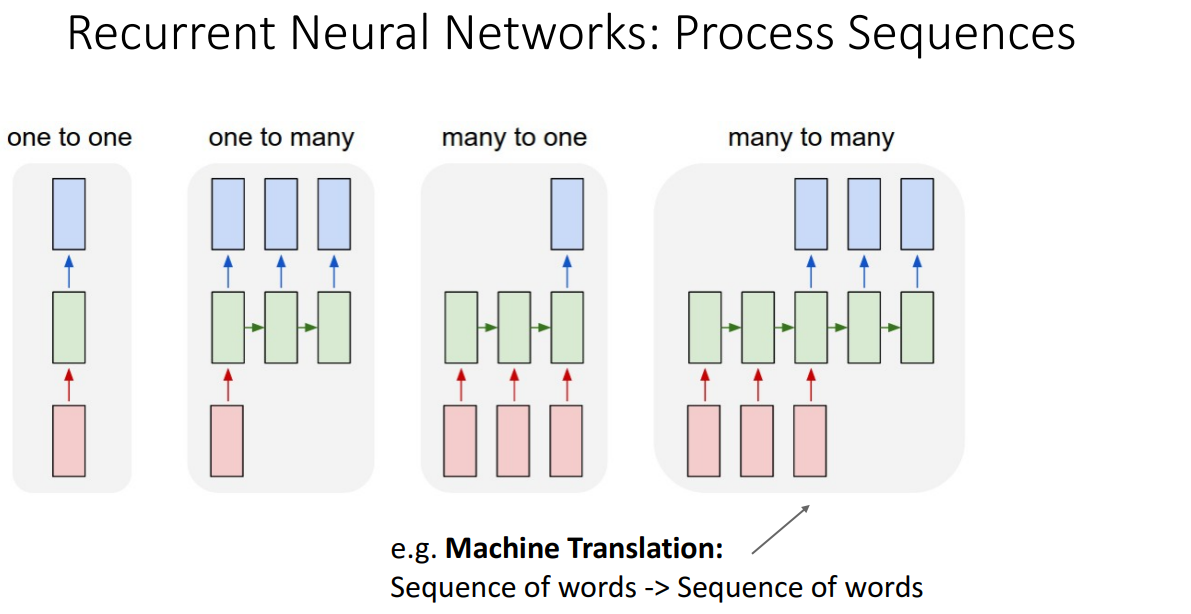
지금까지 본 내용들이 순환 신경망의 기본적인 연산 과정으로 아까 1 대 다, 다 대 다 같은 여러가지 종류의 시퀀스 문제들을 봤다시피 이제는 어떻게 다양한 시퀀스 문제들을 처리할수 있는 순환 신경망을 구현해서 사용하는지를 살펴보자.
이번 슬라이드는 입력 시퀀스를 받아서 각 시점에서 출력을 내보내는 다대다 문제로 예를 들어 비디오 문제가 있는데, 비디오의 모든 프레임을 분류하는 경우라고 할수 있겠다. 여기서도 가중치 행렬 W가 주어지고 이 가중치 행렬을 모든 타임 스탭에서 출력 y를 계산하는데 사용된다.
그리고 라벨을 가지고 있는 경우에 라벨을 가지고 학습시키기 위해서 시퀀스의 매 타임 스탭마다 비용 함수를 사용할 것이고, 비디오 분류같은 문제라면 시퀀스의 모든 시점에서 분류 결정을 하게 될건데, 교차 엔트로피 함수로 실제 라벨 ground truth와 예측 결과에 대한 비용을 계산하여 학습 시킬수가 있겠다.
최종 비용을 구하기 위해서 모든 시간 때의 비용들을 합하여 구할수가 있겠고 이 최종 비용을 역전파 하는데 쓸수 있겠다. 이 예시는 하나의 타임 스탭 때 하나의 출력을 내보내는 다 대 다 순환 신경망의 완전 계산그래프이다.
이번에는 다 대 일 상황을 다뤄본다고 하면 예를 들어 비디오 시퀀스를 입력받아 하나의 라벨로 분류하는 비디오 문제라는 경우를 다룬다고하자. 이 경우에는 시퀀스의 맨 끝에서 순환 신경망의 최종 은닉 상태를 가지고 연산해서 하나의 예측 값을 구하면 된다.
그리고 이 순환 신경망의 최종 은닉 상태는 전체 입력 시퀀스에 영향을 받으며, 우리가 구한 최종 은닉 상태는 신경망이 전체 시퀀스를 가지고 분류 결정을 하기위해서 알아야하는 모든 정보들을 정리 한 것이라고 보면 된다.
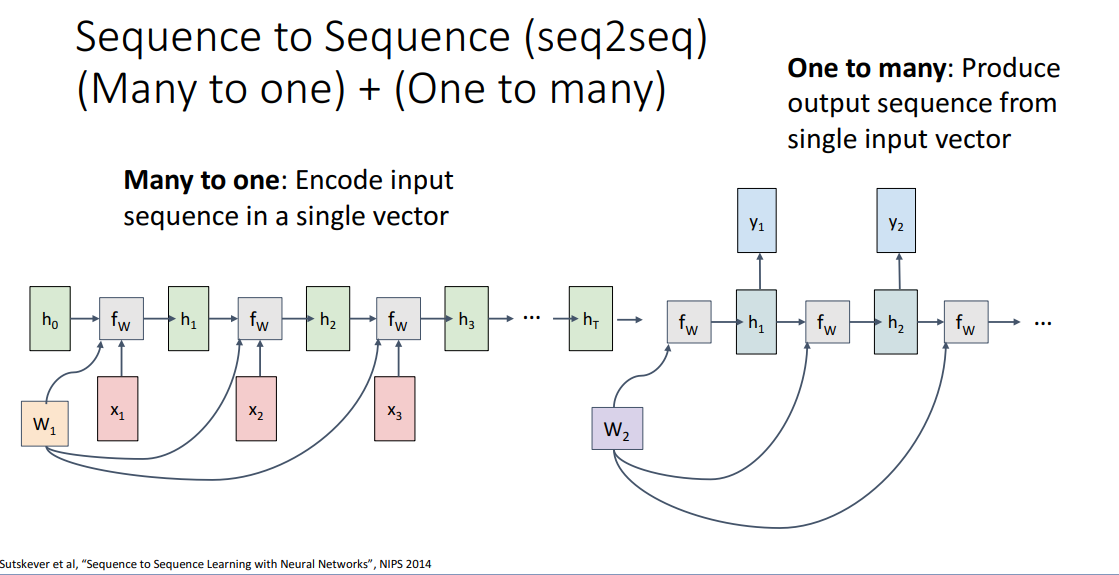
다른 경우로 이미지 캡셔닝 같이 하나의 이미지를 입력으로 받아 단어들의 시퀀스를 출력하는 일 대 다 문제가 있으며 순환 신경망을 이용해서 처리할수가 있다. 이 경우 단일 입력 x는 맨 앞에서만 들어가고, 순환 (관계) 함수를 사용해서 전체 출력 시퀀스를 만들어 낸다.
또 다른 순환 신경망을 이용한 예시로는 sequence to seqeuence seq2seq가 있는데, 입력 시퀀스를 처리해서 길이가 다른 입력 시퀀스를 만들어내는 것같은 기계 번역같은 경우가 있다. 여기서 입력으로 영어 단어 시퀀스가 들어오고 출력으로는 프랑스 단어 시퀀스가 내보내는 그러니까 문장 번역을 수행하도록 시킬수가 있다.
프랑스 말이랑 영어 말이나 항상 같은 길이의 문장으로 동일한 의미를 표현하도록 번역을 할수 없다보니, 입력 시퀀스를 처리해서 다른 길이의 출력 시퀀스를 만들어내는 순환 신경망을 만들어야 한다.
이런 서로 다른 길이의 입력, 출력 시퀀스를 내보내는 순환 신경망을보고 seq2seq rnn 아키텍처라고 부른다. 이 아키텍처는 기본적으로 다 대 일 순환 신경망 구조를 사용하여 구한 결과를 다른 일 대 다 순환 신경망에 전파함으로서 동작시킨다.
지금 보고있는 게 인코더라고 부르는 순환 신경망으로 시퀀스를 입력받아서 이 경우에는 영어 문장을 입력으로 받아서 매 시간마다 단어 하나 하나씩을 처리할것이고, 시퀀스 전체 내용을 처리한 후에 내용들은 맨 끝에 있는 은닉 벡터로 요약/정리가 된다.
이렇게 인코더의 맨 끝에서 구한 은닉 벡터는 디코더라고 부르는 두번째 순환 신경망의 단일 입력으로 사용되며, 이 디코더 신경망은 첫번째 인코더 신경망으로부터 단일 벡터를 입력받아 출력으로 여러 단어들, 시퀀스를 출력하다보니 일 대 다 신경망이 되겠다.
이 그림이 디코더에 대한 계산그래프로 인코더와 디코더는 서로 다른 가중치 행렬을 사용하며, 이런 형태가 대표적인 시퀀스 투 시퀀스 모델 형태라고 할수 있겠다.
(질문) 인코더와 디코더로 나눠서 처리하는 이유는 무엇인가?
여기서 문제는 출력 토큰의 개수가 입력 토큰의 개수와 얼마나 달라야하는지 모른다는 점인데 우선 영어 문장을 처리해서 프랑스 문장으로 만든다고 하자. 하지만 출력시킬 단어 갯수를 입력의 단어 개수와 얼마나 다르게/차이나게 할지 알 수 없으므로 나눠서 다루는게 중요하다.
한번 인코더와 디코더 둘다 동일한 가중치 행렬을 사용한다고 생각해보자. 전체 입력 시퀀스가 주어지고 k번 타음 스탭만큼 진행하고나서, 나머지 k번 타임 스탭에서는 별도의 입력 없이 진행되서 출력을 얻을수가 있겠다. 아까 질문은 디코더에서 얼마나 많은 토큰들이 필요하느냐인데, 이후에 나올 슬라이드를 보면서 자세히 다뤄보겠다.
그동안 이미지 분류가 무엇인지, 선형 분류기, 최적화 방법, 신경망 구성 요소과 신경망 학습 등 전반적으로 살펴보았고, 이제 순환 신경망에 대해서 살펴보고자 한다.
12번째 강의에서는 순환 신경망 recurrent neural network라고 부르는 신경망에 대해서 살펴볼건데, 그 전에 몇 강 전에 배웠던 내용들을 복습해 보자.
(보지 않고 넘어갔지만) 딥러닝 하드웨어와 소프트웨어에 관한 강의에서 다루었던 파이토치와 텐서플로에 대해서 정리한 내용인데, 그 강의에서 다뤘던 파이토치의 가장 큰 문제점은 TPU(구글에서 만든 전문 탠서 처리 유닛 Tensor Processing Unit)를 사용할수 없는 점과 모바일 장치에서 학습한 모델 사용을 지원하지 않는다는 점이었다.
파이토치는 (2019년 당시 기준) 현재 1.3버전이 배포되어있으며, 파이토치 새 버전의 주요 특징이라고 한다면 이 두 문제를 처리해서 모바일 장치에서 사용할수 있도록 모바일 API를 제공하고 있으며, TPU에서도 파이 토치 코드를 동작 시킬수 있도록 개선되었다.
아무튼 이런 이유로 딥러닝 분야에서 어떤 변화들이 일어나는지 꾸준이 주의하면서 보는게 좋겠다.
이제 이전 강의에서 본 내용들로 되돌아와서, 지난 두 강의에서는 어떻게 신경망을 학습할지에 대한 다양한 방법들에 대해서 살펴보았다. 신경망을 잘 학습하기위해서 필요한 활성화 함수와 데이터 전처리, 가중치 초기화와 다른 많은 방법들에 대해서 자세히 알아보았는데, 이들을 잘 이해하고 있으면 어떤 종류의 이미지 분류 문제들을 다루던간에 심층 합성곱 신경망을 학습시키는데 있어서 전문가가 되었다고 할수 있겠다.
이제는 심층 신경망을 가지고 다른 문제들도 풀어볼건데 오늘 다루고자하는 주제는 순환 신경망 recurrent neural networks이다.
일단 우리가 지금까지 심층 신경망을 가지고 다뤄왔던 모든 문제들, 모든 활용 예시들은 순방향 신경망 feed forward network라고 부르는 것인데, 이 순방향 신경망은 신경망의 바닥에서 어떤 단일 입력(이미지)을 받고, 하나나 여러 은닉층(합성곱이나 배치 정규화 계층 등)들을 지나가는데, 각 계층들은 입력을 처리하여 다음층으로 전달하여 신경망의 맨 끝에는 단일 출력을 하게 된다.
이런 순전파 신경망의 고전적인 예시로 이미지 하나를 입력받아 그 이미지가 무엇을 나타내는지 분류하여 카테고리 라벨을 출력하는 이미지 분류 신경망이 있겠다.
우리가 지금까지 이미지 분류 문제를 자세하게 다룬 이유는 이미지 분류가 딥러닝에 대한 수많은 중요한 특징들을 정리해서 다룰수 있었기 때문이다.
하지만 이미지 분류 이외에도 심층 신경망으로 풀고자 하는 수 많은 문제들이 있는데, 이미지 분류 때 처럼 1:1이 아닌 1:다 문제 그러니까 이미지를 입력받아서 하나의 라벨이 아닌 시퀀스를 출력하는 경우도 있다.
이러한 문제의 예시로 이미지 캡셔닝이 있는데, 이 문제에서는 인공 신경망에다가 이미지 한장을 주고 이 이미지에 대한 내용을 설명하는 단어 시퀀스를 출력하며 이것은 지금까지 다뤄왔던 단일 이미지에 단일 이미지 라벨을 출력하는것보다 일반화 시킨 경우로 볼수 있겠다.
다른 활용 예시로는 다 대 1, many : 1 문제로 단일 이미지 같은 단일 입력이 아니라 비디오 프레임 시퀀스 같이 여러개의 데이터 시퀀스를 입력받아 라벨을 할당하는, 분류하는 문제가 되겠다. 여기서 비디오 시퀀스를 입력으로 받아서 어떤 상황인지 판단하는 비디오 분류 문제를 다 대 일 문제라고 볼수 있다.
다 대 다, many : many 문제로 시퀀스를 입력받아 시퀀스를 출력하는 대표적인 문제 예시로 기계 번역이 있는데, 영어 문장 그러니까 영어 단어 시퀀스를 입력받아 프랑스 문장, 프랑스 단어 시퀀스를 출력하는 경우가 있겠다. 이때 입력 시퀀스의 길이도 다양하고, 출력 시퀀스의 길이도 다양할수 있다보니 이 문제를 다 대 다, many to many 문제라고 부른다.
또 다른 타입의 시퀀스 투 시퀀스 문제로 입력 시퀀스를 처리해서 시퀀스의 한 원소 마다 출력하고자 하는 경우도 있는데, 이러한 다 대 다 분류 문제의 예시로 비디오 프레임들을 입력받아 비디오 전체를 보고 하나로 분류하는게 아니라 비디오 프레임마다 각자 분류하는 경우가 있겠다.
자세히 예를 들면 처음 세 프레임에서는 어떤 사람이 농구공을 드리블링 한다고 판단하고, 다음 10 프레임동안은 농구공을 던지는 것으로, 다음 프레임은 공을 던졌으나 실패하는 상황을, 나머지 프레임에서 다른 팀원들에게 야유를 받는 상황으로 이와 같이 여러 이미지 시퀀스를 받아 각 시퀀스마다의 경우를 분류하고자 할수도 있다.
이런 시퀀스를 처리하는 신경망을 만들기 위해선 단일 입력을 받아 단일 출력을 하는 능력을 가질 뿐 만이아니라 입력 시퀀스를 처리해서 출력 시퀀스를 만들어내도록 해야한다.
딥러닝에서 입력과 출력이 시퀀스인 경우 처리하도록 사용할수 있는 일반적인 방법, 도구가 순환 신경망 recurrent neural network이며, 앞으로 다양한 순환 신경망을 가지고 입력/출력 시퀀스를 처리하는 문제들을 어떻게 풀어내는지 알아보자.
여기서 알아야할 중요한 점은 우리가 어떤 문제를 다루던간에 시퀀스의 길이를 모르더라도 임의의 길이(예를 들어 짧은 비디오 프레임이나 아주 긴 비디오 시퀀스)를 처리할수 있는 신경망을 만든다고 할때 순환 신경망이 매우 유용한 방법이며, 심층 신경망 문제에서 다양한 시퀀스를 처리할수 있겠습니다.
하지만 순환 신경망은 비 시퀀스 데이터 처리에도 효과적으로 사용할수가 있습니다. 어떤 연구원들은 순환 신경망을 비 시퀀스 데이터의 시퀀스 처리를 하는데 사용해보았는데, 다음 연구는 몇년 전에 진행된걸로 이미지 분류를 하고 있습니다. 지금까지 배운 내용을 생각해보면 이미지 분류에서는 시퀀스가 존재하지않고 단일 이미지를 입력으로, 단일 카테고리 라벨이 출력으로 되었었습니다.
하지만 이들은 단일 순전파 신경망으로 이미지 분류를 하지않고, 한 이미지가 주어질때 그 이미지를 응시glimpse한 여러개의 경우를 가지고, 한번은 이미지의 한 부분을 보고, 다른 응시때는 그 이미지의 다른 부분을 보고, 시간 변화에 따라 다른 지점을 본 응시들을 사용한 신경망을 만들었습니다.
이 신경망이 이미지에서 어느 부분을 볼지는 이전 타임 스탭으로부터 얻은 정보를 기반하여 판단하며, 아주 많은 부분들을 응시한후에 최종적으로 이 이미지의 물체가 무엇인지 판단을 하게 됩니다.
그래서 이 그림이 신경망 안에서 비 시퀀스 데이터를 가지고 시퀀스 처리를 사용한 예시로 숫자 분류하는 걸 보여주고 있는데, 작은 녹색 사각형들이 신경망이 이미지의 어디를 볼지 선정한 응시 영역이며, 이 응시한 것들을 모아 최종 결정을 하게 됩니다.
비시퀀스 데이터를가지고 시퀀스 처리하는 다른 예시로는 역변환 중 하나인 이미지 생성을 살펴봅시다. 이전 슬라이드에서는 이미지 하나를 입력으로 가지고 와서 여러 응시 결과들을 모아 분류를 했었는데, 이번에는 그와 달리 숫자 이미지를 생성하는 신경망을 만들고자 하며 매 타임 스탭마다 출력 시퀀스로 숫자 이미지를 그려봅시다.
이 신경망에서는 매 시간 마다 어디 다가 그릴것인지, 무엇을 그릴것인지, 어떻게 그릴것인지를 선택해야하며 이러한 비 순차적인 하부 작업들을 한번에 순차적으로 처리하여 숫자 이미지를 출력하도록 신경망을 설계하면 되겠습니다.
이 연구 내용은 (교수님이 강의하기) 2주전에 트위터에서 찾은 건데, 비순차 작업인 이미지 생성을하는 신경망을 만든것으로 오일 페인팅 시뮬레이터와 신경망을 합쳐 순차처리를 하는것을 보여주고 있습니다.
이 연구에서는 사용할 붓을 고르고, 매 시간마다 이전 타임 스탭에서 본것에 따라 어디다가 붓으로 그릴지를 판단하며, 시간이 지남에 따라 이런식으로 예술가가 그린듯한 얼굴 그림이 만들어지게 됩니다.
이런 것들이 순환 신경망을 사용한 예시들로 지금까지 순환 신경망을 통해서 순차적인 데이터를 처리할수도 있고, 기존에 비 순차적으로 처리되던 옛날 문제들을 순차 처리를 통해서 풀수도 있는것을 보았습니다. 그래서 이것들을 보면서 왜 우리가 순환 신경망을 배워야하는지를 충분히 동기 부여가 되었으면 좋겠습니다.
지난번에 전이 학습에 관한 내용들을 마무리 하고싶었는데 생각보다 내용들이 많아 마무리하지는 못했다.
이번에 전이학습 내용을 마무리해보자
그래서 이전까지 본 내용들이 선학습된 신경망을 이용한 가장 간단한 경우들로서, 특징 벡터들을 추출해서 이 벡터를 다른 알고리즘에 적용을 시켜보았다.
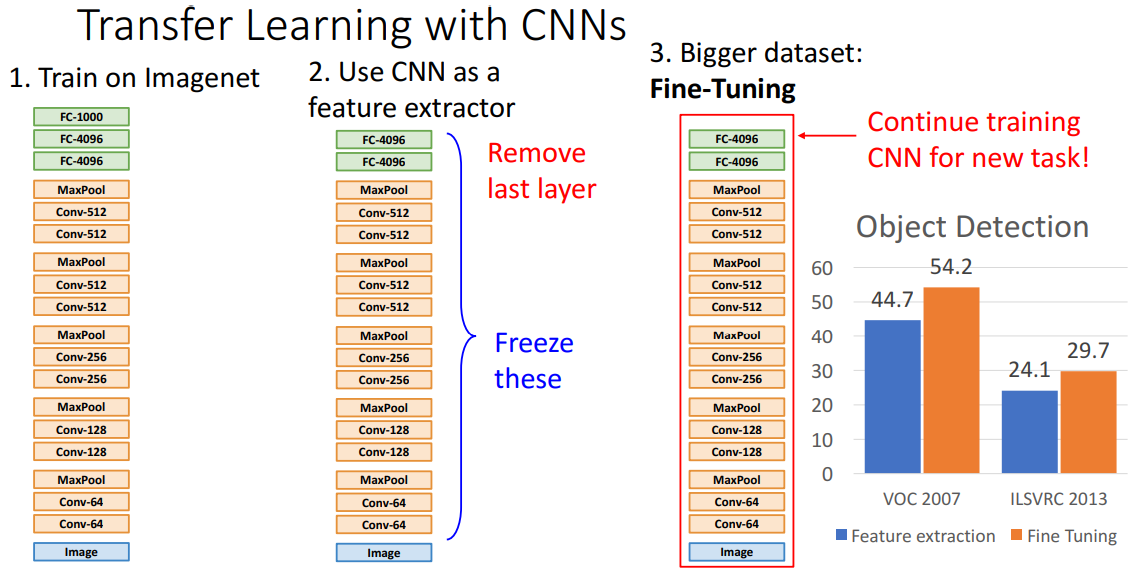
하지만 우리가 사용하고자하는 데이터셋이 더 크다면 미세 조정 fine tuning이란 과정을 통해서 더 나은 성능을 얻을수가 있는데, 일단 이미지넷 데이터셋으로 이미 학습된 모델을 가지고오고 맨 마지막 계층을 버린다음, 남은 마지막 계층을 새로운 데이터셋 데이터들의 카테고리를 분류할 수 있도록 재초기화를 시키자.
새 분류 데이터셋을 가지고 학습과정을 진행하면, 특징 추출기로 사용되던 모델이 역전파를 통해서 가중치가 갱신되고 분류작업을 더 잘할수 있도록 성능이 개선된다.
사용할 데이터셋이 선 학습 모델의 데이터셋보다 더 큰 경우 정리
- 기존의 전이 학습 : 이미지넷을 선학습한 알렉스넷 모델의 마지막 계층을 제거하여 특징 추출기로 사용하였다.
- 남은 마지막 계층을 새 데이터셋의 분류 카테고리를 다룰수있도록 다시 초기화하고, 새 데이터셋으로 학습 진행한다.
- 기존의 선학습 모델이 새 데이터셋에 맞게 갱신되어, 성능이 향상된다.
위 예시는 미세 조정을할때 가끔식 필요할수도 있는 방법들의 예시인데, 어떤 경우에는 학습률을 줄여야 할수도 있을거고, 다른 경우는 특징 추출한 이후 선형 모델을 학습시키고나서 전체 모델을 미세 조정 하는 경우도 있겠다.
이런 미세 조정에서 추가적으로 사용하는 방법들은 실제로도 사용되고 있으며, 다양한 작업 성능을 크게 올려주었다. 위 그림은 물체 인식의 인데, 앞으로 몇 강 안에 이에 대해서 자세하게 다룰 예정이다보니 이게 어떻게 동작하는지나 수직 축의 숫자가 뭘 의미하는지 자세히 알 필요는 없다.
아무튼 여기서 파란색 막대는 서로 다른 두 데이터셋으로 물체 인식을한 전이 학습의 예시인데, 이미 학습을 마친/고정된 특징 추출기(모델)를 가지고 얻은 결과를 보여준다. 주황색 막대의 경우 새로운 데이터셋으로 전체 신경망을 학습시킨 경우로 미세 조정을 함으로서, 신경망이 특징 추출기로 사용된 전자의 경우보다 훨씬 성능이 개선되는걸 볼수 있다.
다른 관점으로 전이학습을 보자면, 이미지넷 데이터셋으로 한 모델을 학습시켜서 사용했는데, 어떤 모델을 학습시키느냐도 중요한 문제라고 할수 있겠다. 이미지넷셋에서 일반화 성능이 좋은 모델일수록 다양한 컴퓨터 비전 문제들을 더 좋은 성능으로 해결할수가 있다.
여기서 컴퓨터 비전 분야를 연구하는 사람들이 이미지넷에 대한 모델들을 다루고자하는 이유는 이미지넷을 좋아해서가 아니라, 수년간 이미지넷 셋으로 좋은 성능을 보인 모델들이 보통 다른 모든 문제들에서도 잘 동작했기 때문이다. 그래서 이미지넷을 다루는 가장 최신, 좋은 성능을 보이는 최적의 모델을 사용해서 우리가 다루고자 하는 문제에서 사용할때 더 좋은 성능을 얻을수가 있겠다.
이번 예시로 다시 객체 인식 문제로 돌아와서 보면, 이미지넷 데이터셋을 학습한 다양한 모델들을 비교한 논문을 찾기 어려워서 틀릴수도 있긴한데 물체 인식 성능 비교한 그림을 보여주고 있다. y축은 물치 인식 성능으로 0인 경우 나쁘고, 100에 가까울 수록 좋은 성능이라고 할수 있다.
2011년부터 시작하여 딥러닝 이전의 방법 Pre DL을 사용한 경우 5 정도를 얻었고, 알렉스넷을 학습후 같은 객체 인식 방법을 사용한 경우 15를 얻었으며, 알렉스넷보다 더 큰 신경망인 VGG-16으로 바꾸었을때 19로 증가하였다. Faster R-CNN이라고 부르는 새로운 방법을 사용한 경우에는 29로 증가하였고, ResNet-50을 사용시 36으로 증가하였다.
이런 추세가 계속 진행되서 이미지넷에서 더 나은 성능을 보이는 모델을 사용할수록 적은 노력을 들이고도 수많은 컴퓨터 비전 문제를 풀수가 있겠다.
어떻게 CNN에서 전이학습을 다룰지를 한번 살펴본다고하면, 우리가 풀고자하는 문제를 사용하고자 하는 데이터셋이 이미지넷과 비슷하냐 아니냐와 새로운데이터셋이 큰지 작은지에 따라 다음의 2 x 2 행렬로 분류하여 다뤄보자.
우리가 사용하는 데이터셋이 이미지넷과 비슷한경우, 그러니까 이미지넷과 비슷한 물체들을 포함한 셋인경우이나, 한 카테고리당 수십 ~ 수백개로 데이터가 적은 경우라고해보자. 그러면 선 학습된 특징 추출기 맨 위에다가 선형 학습기 같은것을 적용시키면 잘 동작하게 되겠다.
이번에는 한 카테고리당 수백 ~ 수천개의 샘플로 꽤 큰 데이터셋을 가진경우, 이미지넷으로 학습한 모델을 새 데이터셋으로 미세조정을 시킬것이고 더 잘 동작하게 된다.
하지만 이번에는 사용하려는 데이터셋이 이미지넷과 다른 경우를 보면, 데이터셋이 다르지만 많이 가지고 있는 경우에는 어떻게 해야할지 명확하게 구분되어있지는 않지만 이미지넷 모델을 초기화해서 미세조정을 하면 되겠다.
다음으로는 이미지가 다른 타입이고, 데이터셋이 작은 경우가 문제가 될수 있는데, 선학습된 모델로부터 얻은 특징으로 선형 분류기를 사용하거나 미세 조정하는 방법들은 꽤 괜찬게 동작하기는 하지만 잘못될수 있으니 주의하여야 한다.
이런 전이학습이란 방법은 컴퓨터 비전 분야에서 수 많은 문제들을 풀기위해서 수년간 사용되면서 특별한 경우에만 사용한는게 아니라 일반적이며, 주류가 되었다.
오늘날 수 많은 컴퓨터 비전 논문에서 전이 학습을 사용하고 있으며, 이미 객체 인식 문제에서 이미지넷을 선학습한 모델을 사용한 경우를 보았다. 이미지 캡셔닝이라는 분야에서도 이미지넷을 선학습한 모델 일부를 사용하고 있으며,
연구자들이 과감하게 다른 데이터셋으로 선학습된 모델들을 사용해서 다양한 경우의 이미지 캡셔닝 모델을 만들수가 있었는데, 이러한 일부 모델이 이미지넷을 선학습 되고, 다른 일부가 다른 데이터셋으로 선학습시켜 같이 사용해서 학습하고 작업을 수행하는 경우에 대해서 자세히 다루어보자.
최근 몇년간 컴퓨터 비전 분야에서 있었던 중요한 변화 중 하나는 문제를 해결할수 있는 모델을 만들수 있도록 여러번 반복해서 선학습 모델과 미세 조정 과정에 대한 파이프 라인을 찾는 것이 되었다.
컴퓨터 비전 분야에 있었던 이런 변화를 보여주는 좋은 예시로 최근 투고된 논문인데,
첫번째 단계에서 CNN을 이미지넷으로 학습시킨다.
두 번째 단계는 Visual Genome이라고 부르는 데이터셋으로 객체 인식을 하도록 CNN을 미세 조정 시킨다.
세번째 단계에서는 BERT라고 부르는 언어 모델을 학습시키는데 여기에 대한 자세한 설명은 중요치 않으니 넘어가자.
넷째 단계에서는 2, 3번째 단계의 결과를 합치고 결합된 이미지/언어 모델을 미세조정을 시키자.
다섯째 단계에서는 이미지 캡셔닝 혹은 시각 질의응답 혹은 다른 다운스트림 작업에 대해서 미세조정을 시키자.
이 모델에서 전체 과정이 어떻게 돌아가는지는 이해할 필요는 없고 이런 식으로 미세 조정과 선학습 모델들이 사용되고 있으며, 이런 식으로 전이 학습이 컴퓨터 비전 연구에서 주류가 되었고 할수 있겠다.
이전에 본 7개의 단계를 통해서 GPU 자원이 많지 않더라도 좋은 모델을 학습시킬수가 있겠다. 이후에 더 다뤄볼 내용으로 모델을 학습한 이후에 어떤 일들을 할수 있느냐인데,
최종 테스트셋 성능을 약간이라도 좋게 할수 있는 방법들 중 하나로 모델 앙상블이 있는데, 어떤 문제를 다루던지 간에 상관없이 성능을 개선 시킬수가 있다. 이 방법은 독립적으로 여러개의 모델을 여유 되는 만큼 학습시키고, 그들 중 가장 테스트 성능이 좋으걸 사용하는게 아니라 각 모델들의 예측 결과를 모아서 평균을 사용한다.
이미지 분류 같은 문제의 경우에는 각 모델이 출력한 각 카테고리별 예측 확률을 평균을 구해서 사용하면 되겠다. 이런 식으로 여러개의 서로 다른 모델들의 조합, 앙상블을 사용해서 기존의 최종 테스트 성능에서 1 ~ 2 % 성능 개선을 할수 있다.
그래서 이 방법은 꽤 일반적으로 사용할수 있어, 어떤 모델 아키텍처인지, 모델이 얼마나 많은지, 어떤 문제를 풀고자하는지 상관없이 더 좋은 성능을 얻을수가 있어서 사람들이 자주 사용하는 방법이겠다.
정리
여러 모델을 이용한 모델 앙상블 기법
1. 여러 모델들을 학습 후 예측 결과의 평균을 최종 예측 값으로 사용한다.
2. 어떤 문제이던 간에, 어떤 모델이던 간에 상관없이 유용하게 사용할 수 있다.
독립적인 여러 모델들을 학습시키는것 대신 사용할수 있는 다른 방법으로는 한 모델을 학습하는 동안 여러 체크 포인트를 저장하고, 해당 체크포인트 당시 모델의 결과들을 평균을 구해서 성능을 개선시킬수가 있다.
이 방법의 트릭은 주기를 보이는 효과적인 학습률 스케줄링 방법이라고 할수 있는데, 학습률 스케줄링이 주기적으로 동작하다보니 처음에는 높게 시작하다가 떨어지고, 다시 높게 시작하다가 떨어지고, 이 과정을 여러 차례 반복한다. 그렇게 하면 각 체크포인트들에서 모델의 가중치 값들은 학습률 스케줄링에서 해당 지점이 가장 낮을때의 것을 사용하는게 되겠다.
정리
한 모델 여러 스냅샷을 이용한 모델 앙상블 기법
1. 주기를 보이는 학습률 스케줄링 방법을 사용한다.
2. (해당 주기에서) 훈련 비용이 최저가 되는 = 학습률이 최저가 되는 시점의/체크 포인트 모델을 저장한다.
3. 각 체크 포인트 모델로 예측한 결과의 평균치를 저장한다.
다른 방법으로는 학습 하는 동안의 모델 가중치들의 이동 평균을 구하여 사용하는 것으로 이걸 폴리야크 평균 Polyak이라고 부른다. 이 방법은 배치 정규화 같은 큰 생성 모델들에서 흔하게 사용되어왔는데, 가지고 있는 데이터들의 평균과 분산의 평균들을 지속적으로 계속 구하고, 테스트 때 (배치 정규화 때 처럼) 이렇게 구한 평균과 표준 편차를 사용하는 방법이다.
모델 가중치를 갱신할때 한 에폭에서 경사 하강법으로 구한 가중치 갱신치를 사용하는게 아니라 그동한 지속적으로 구한 모델의 가중치 평균을 사용한다고 할수 있겠다.
이 방법을 통해서 훈련 과정에서 매 반복때마다 발생하는 변동을 스무딩시킬수가 있겠다. 지금까지 모델을 학습시키는 동안 매 반복때마다 비용의 변동이 크게 나오지만, 매 반복 마다 발생하는 노이즈를 평균을 통해서 줄일수가 있었다.
정리
가중치 이동 평균 사용하기
1. 폴리 야크 평균 : 훈련 과정에서 이동 평균을 계속 계산하고, 테스트 과정에서 사용.
2. 폴리 야크 평균으로 학습 과정에 발생하는 노이즈를 제거할수가 있다.
지금까지 모델 앙상블에 대한 다양한 방법들을 살펴봤는데, 이 방법을 기존에 사용하려고 했던 작업에서 더 나아가서 학습 시킨 모델가지고 다른 작업을 해야할 경우도 있는데, 이런 방법들이 최근 몇년간 컴퓨터 비전 분야에서 메인스트림이 된 효괴적인 방법들로 전이 학습 transfer learning의 기반이 되었다.
전이 학습에 대해서 시작하기 위해서 우선 CNN에 대한 미신으로 사람들이 모델을 학습시켜서 잘 쓰려면 아주 큰 훈련셋이 필요하다고 말하곤한다.
하지만 이 생각은 잘못된 것인데, 이 잘못된 생각을 깨야 하며 전이 학습을 통해서 수 많은 문제들을 딥러닝으로 풀수 있다. 아주 큰 훈련셋을 사용할수 없는 경우가 많이 있으며, 이런 이유로 전이 학습이 컴퓨터 비전 분야에서 메인 스트림이 되었다.
기본 개념은 위 그림과 같은데, 우선 첫 번째 단계에서는 이미지넷 이나 다른 큰 이미지 분류 데이터 셋으로 합성곱 신경망 모델을 학습 시키자. 이 과정에서 우리가 지금까지 봐왔던 다양한 기법들을 활용해도 좋다. 두 번째 단계에서는 이미지넷 데이터셋의 분류 성능 보다는 더 작은 데이터셋을 이용한 분류 문제나 아예 다른 문제를 다루고자 할 수도 있겠다.
이 그림을 보면 이미지넷 데이터로 학습 시킨 모델을 가지고 와서 마지막 완전 연결 계층을 제거하였는데, 이 계층은 알렉스 넷이라고 한다면 4096 차원 특징들을 받아 1000 차원의 클래스 스코어에 대한 벡터를 출력하는 계층으로 어느 카테고리에 속하는지를 판별하는데 사용되었었다.
하지만 이 마지막 계층을 신경망에서 제거 하고 나면 뒤에서 두 번째 계층의 출력인 4096 차원의 벡터를 입력된 이미지들의 특징 표현같은걸로 사용할 수 있다. 다시 말하면 이 학습된 모델을 통해서 이미지에 대한 특징 벡터를 추출할수가 있다.
2013 ~ 2014년 당시 사람들은 이런 간단한 방법을 통해서 아주 많은 컴퓨터 비전 문제들을 더 좋은 성능으로 풀수 있게 되었다. 예를 들자면 칼텍 101이라고 부르는 데이터셋을 사용한 경우인데 이 데이터셋은 101 카테고리 뿐이며, 이미지넷보다 훨신 작은 크기로 이루어져 있다.
우측 그림에서 x축은 하나의 카테고리를 학습하는데 사용한 데이터 개수, y축은 칼텍 101 데이터셋에서 분류 성능을 보여주고 있다. 여기서 빨간색 커브는 딥러닝 방법 이전에 사용되던 특징 추출 파이프 라인을 통한 방법을 이용한 결과이다.
파란색과 녹색 커브는 이미지넷을 학습한 알렉스넷을 가지고 와서 알렉스넷 마지막 두번째 계층으로 구한 특징 벡터로 로지스틱 회귀와 SVM으로 학습 시킨 결과를 보여주고 있다. 선학습된 모델로부터 얻은 4096 차원 특징 벡터로 로지스틱 회귀와 서포트 벡터 머신 같은 단순 선형 모델을 학습 시켰다고 할수 있겠다.
미리 학습 시킨 모델로 추출한 특징 벡터로 선형 모델을 학습 시킨 덕분에, 성능을 크게 향상 시킬수 있었으며 각 클래스당 데이터가 5 ~ 10개 뿐인 경우에도 꽤 높은 성능을 얻을수가 있었다.
그래서 이 방법이 흔하게 사용되고 있고, 이미지넷 선 학습된 모델을 특징 추출기로 사용한다면, 훈련 데이터가 많지 않은 경우라 해도 다양한 문제들을 좋은 성능으로 풀수 있다.
이런 결과가 나오는건 칼텍 101 뿐만 그런게 아니며, 새 분류 데이터 셋을 사용한 경우에도 그런데 우측 그림에세 DPD와 POOF라는 새 종류를 잘 인식할 수 있도록 튜닝한 모델과, 알렉스넷으로 얻은 특징으로 간단하게 로지스틱 회귀로 학습한 경우를 보여주고 있다.
비교한 결과 알렉스넷 특징 + 로지스틱 회귀이 이전에 새를 잘 분류할수 있도록 튜닝된 방법들보다 더 좋은 성능을 보이고 있고,
알렉스넷 특징과 이전의 방법을 같이 사용 한 경우 훨씬 뛰어난 성능을 얻을 수가 있었다. 전이 학습은 칼텍 101 이미지 나 새 데이터 뿐만 아니라
수 많은 이미지 분류 문제에 관한 데이터셋에도 사용할수가 있다. 이 그림에 이미지넷 추출 특징을 다양한 선형 모델들로 학습한 벤치마크, 성능 평가치들이 있는데, 객체, 장면, 새, 꽃, 사람 특징, 물체 특징에 관한 모든 데이터셋에서 이전 방법들보다 더 좋은 성능을 보이고 있다.
여기서 놀라운 건 파란색 막대, 각 데이터셋의 이전에 사용되던 방법들이 독립적으로 특정 데이터 셋에 맞게 튜닝되었지만, 간단하게 선학습 모델로부터 얻은 특징들을 사용하여 단순 선형 회귀 모델로 학습시키기만 해도 알아서 미세 조정 되고 이전의 다른 방법들 보다 더 좋은 결과를 얻을수 있다는 점이다.
선학습모델으로 특징을 추출해 사용하는건 이미지 분류 뿐만이 아니라 컴퓨터 비전 관련 수많은 분야에서 사용할수가 있는데, 동일 논문에서 이미지 검색 작업을 위한 데이터셋에 대해서도 성능 평가를 했었다. 이 방법들이 어떻게 동작하는지는 중요하지 않지만, 예를 들어 옥스포드에 있는 한 건물 이미지가 주어지면 데이터셋에서 시간이나 촬영 각도가 다르더라도 같은 건물의 이미지를 찾는 문제이다.
이런 이미지 탐색은 구글에 이미지 업로드 해서 비슷한 이미지를 탐색하는것과 비슷한것이기도한데, 여기에도 선학습모델로 특징을 추출해서 간단하게 최근접 이웃 같은 방법을 이용해서 이미지 검색 문제를 수행할수가 있다. 특징 추출 층 위에다가 단순 최근접 이웃을 사용함으로서 이전의 방법들보다 훨씬 개선된 성능을 얻을수가 있었다.
간단하게 특징 벡터를 추출해서 사용하는 이런 방법들이 전이 학습의 간단한 예시들이고, 선형 모델이나 다른 탐색 베이스라인들을 사용할수도 있다.
중간 질문
이 논문에서는 원본 이미지를 데이터 증강을 사용해서 특징 벡터를 추출을 하였는데, 이 파이프라인에서 상당히 중요하다는걸 알아냈다. 데이터 증강 방법으로 랜덤 스케일로 자르거나 뒤집거나 하는건 이전 장에서 이야기 했으니 넘어가자.
지금까지 선학습된 신경망을 사용하는 간단한 방법들을 보았고, 특징 벡터를 추출해서 다른 알고리즘에 입력시켜 사용했다. 하지만 우리가 가진 데이터셋이 약간 더 크지만, 더 나은 성능을 얻고자 한다면 미세 조정 fine tuning을 해야 한다.